# 导包
import torch
from torch import nn
from d2l import torch as d2l
import torchvision
from torchvision import transforms
from torch.utils import data
# 定义丢弃法函数
def dropout_layer(x,dropout):
#assert是断定函数,就是在这里告诉dropout_layer这个输入一定是在0到1之间
assert 0 <= dropout <= 1
# 先dropout进行判断是否为零或一,因为如果为一表示丢弃的概率唯一,所以对应的隐层输出会被全部抛弃,就直接输出形状相同的全零张量
# 隐层:神经网络除了传入和传出以外的层,就是多层感知机当中的那些层
if dropout == 1:
#输出形状相同的全零张量
return torch.zeros_like(x)
if dropout == 0:
return x
# 创建一个mask,torch.rand是生成0到1之间的均匀分布,参数x.shape代表生成的形状
mask = (torch.rand(x.shape) > dropout).float()
# 保持输出总体的均值,推导过程就不写了,看沐神即可
return mask * x / (1.0 - dropout)
def dropout_layer2(x,dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(x)
if dropout == 0:
return x
mask = (torch.rand(x.shape) > dropout).float()
return mask
#我们来看一下输出还有mask的值
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer2(X, 0.))
print(dropout_layer2(X, 0.5))
print(dropout_layer2(X, 1.))
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
# 赋值传入的维度,输出维度,隐层1维度,隐层2维度
num_inputs ,num_outputs,num_hiddens1,num_hiddens2 = 784,10,256,256
# 赋值第一层每个输出值丢弃的概率,第二个层每个值丢弃的概率
dropout1,dropout2 = 0.2,0.5
"""
创建模型类
"""
class Net(nn.Module):
# 这里用的是python中的魔术构造方法,可以方便我们直接传入各个维度,num_inputs ,num_outputs,num_hiddens1,num_hiddens2
# is_training这个参数用来控制是否在训练,如果在测试就额外传入参数is_training = FALSE就可以防止隐层的输出被丢弃
def __init__(self,num_inputs ,num_outputs,num_hiddens1,num_hiddens2,
is_training = True):
#super()函数用来调用父类,这里的Net继承的父类是nn.Module,不使用该语句后续不方便给Net传参,就是一种固定写法
super(Net,self).__init__()
#给Net传参
self.num_inputs = num_inputs
self.training = is_training
self.line1 = nn.Linear(num_inputs,num_hiddens1)
self.line2 = nn.Linear(num_hiddens1,num_hiddens2)
self.line3 = nn.Linear(num_hiddens2,num_outputs)
self.relu = nn.ReLU()
#定义前馈,加一个参数x用来传入数据集
def forward(self,x):
#获取第一个隐层输出,先对x改变形状,使其维度变成num_inputs的维度否则无法放入line1,-1代表让机器自动帮我们调整
#再放入line1得到输出,用激活函数relu获得隐层的一个输出
h1 = self.relu(self.line1(x.reshape((-1,self.num_inputs))))
#先判断是否在训练
if self.training == True:
#将好h1的输出放入dropout_layer中让其按概率丢弃输出
h1 = dropout_layer(h1,dropout1)
h2 = self.relu(self.line2(h1))
if self.training == True:
h2 = dropout_layer(h2, dropout2)
output = self.relu(self.line3(h2))
return output
#实例化net
net = Net(num_inputs=num_inputs,num_outputs=num_outputs,
num_hiddens1=num_hiddens1,num_hiddens2=num_hiddens2)
#设定训练轮数和学习率,样本数量
num_epoch,lr,batch_size = 10,0.5,256
#创建损失和优化器
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(),lr=lr)
#获取数据
#trans类型
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="D:/torchvision_data",train=True,transform=trans,download=False)
mnist_test = torchvision.datasets.FashionMNIST(root="D:/torchvision_data",train=False,transform=trans,download=False)
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True)
test_iter = data.DataLoader(mnist_test, batch_size, shuffle=True)
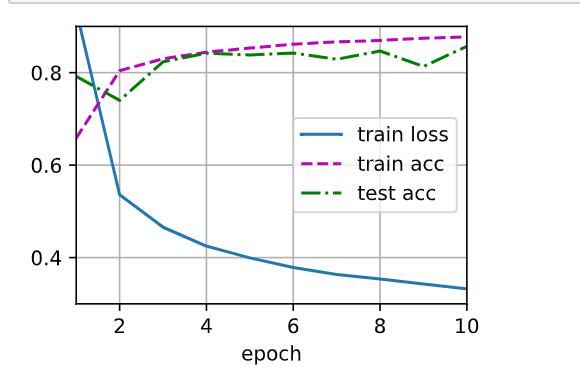
d2l.train_ch3(net,train_iter,test_iter,loss,num_epoch,updater=trainer)
#直接创建net,先用nn.Flatten将输入变成2维
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
#定义权重函数,net传入权重w
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epoch, trainer)























 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









