






突然想到这个,然后想模拟做个实验,代码写得多了些不够简洁,多包涵。
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.rcParams["axes.unicode_minus"]=False
# 生成随机列表, 1表示选对的跑车, 0表示羊
def create_random_array(doors=3):
array = np.zeros(doors)
random_index = np.random.randint(0, len(array))
array[random_index] = 1
return array
# 从随机列表中选择一个随机的数, choice表示随机选的值是多少例如0或1, random_chice_index表示选的是第几个
def choice(random_array):
random_choice_index = np.random.randint(0, len(random_array))
choice = random_array[random_choice_index]
return choice, random_choice_index
# 从原先随机产生的列表中排除两个值, 由于主持人不能排除跑车, 还有原先嘉宾选的门, 因此要先获取能排除哪些
def excluded(choice_index, random_array):
# 做一次遍历用于装填能排除哪些, 条件是不能是原先的选择和得是山羊,所以索引不能等于choice_index,也不能是1
# can_excluded装填的是索引
can_excluded = []
for i in range(len(random_array)):
if (i != choice_index) and (random_array[i] != 1):
can_excluded.append(i)
# 如果情况是嘉宾选择了的是山羊, 那么意味着主持人只有一个选项能用来给他排除, 就直接返回去除后的列表和去除项的索引
if len(can_excluded) == 1:
excluded_array = np.delete(random_array, can_excluded)
return excluded_array, can_excluded
# 如果能排除的选项有多个, 那么会随机从能排除的选项中抽取一个用于排除, 注意这时候排除的索引是excluded
else:
excluded_index = np.random.randint(0, len(can_excluded))
excluded = can_excluded[excluded_index]
excluded_array = np.delete(random_array, excluded)
return excluded_array, excluded
# 用于模拟测试, epoch是轮数, change_select表示是否要跟换
def test(epoch=10000, change_select=False, doors=3):
choice_list = []
for _ in range(epoch):
random_array = create_random_array(doors)
choice_value, choice_index = choice(random_array)
excluded_array, excluded_index = excluded(choice_index, random_array)
# 如果要更换, 就相当于不要原先的choice_index, 也不可能选被主持人排除的excluded_index,所以选剩下的随机来一个
if change_select:
mask = np.ones(len(random_array), dtype=bool)
mask[excluded_index] = False
mask[choice_index] = False
choice_list.append(np.random.choice(random_array[mask]))
# 如果不更换, 就拿原先的值
else:
choice_list.append(choice_value)
return choice_list
# 用于计算多轮选择下选对的次数和占比
def calculate_accuracy(choice_list):
total_count = len(choice_list) # 列表中总数的个数
ones_count = choice_list.count(1) # 列表中值为1的数值的个数
accuracy = ones_count / total_count # 值为1的数值占总数的比例
return accuracy, ones_count
def plotbar(x_labels, values, colors):
x = np.arange(len(x_labels))
fig, ax = plt.subplots()
rects = ax.bar(x, values, color=colors)
ax.set_xticks(x)
ax.set_xticklabels(x_labels)
ax.set_title("选中次数")
plt.show()
experiment = test(change_select=True)
control = test(change_select=False)
experiment_acc_1, experiment_count_1 = calculate_accuracy(experiment)
control_acc_1, control_count_1 = calculate_accuracy(control)
print('实验组:', experiment_acc_1, '%')
print('对照组:', control_acc_1, '%')
labels = ['对照组', '实验组']
values = [experiment_count_1, control_count_1]
colors = ['orange', 'c']
plotbar(labels, values, colors)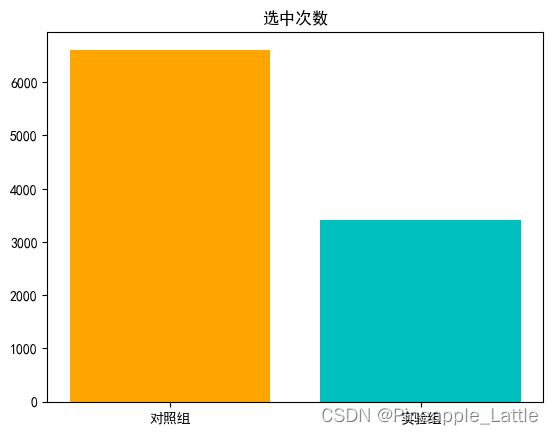
实验组: 0.6611 % 对照组: 0.341 %
experiment = test(change_select=True, doors=4)
control = test(change_select=False, doors=4)
experiment_acc, experiment_count = calculate_accuracy(experiment)
control_acc, control_count = calculate_accuracy(control)
print('实验组:', experiment_acc, '%')
print('对照组:', control_acc, '%')
labels = ['对照组', '实验组']
values = [experiment_count, control_count]
colors = ['orange', 'c']
plotbar(labels, values, colors)实验组: 0.3826 % 对照组: 0.2525 %
experiment_acc_l, experiment_count_l = [], []
control_acc_l, control_count_l = [], []
for doors in range(3,10):
experiment = test(change_select=True, doors=doors)
control = test(change_select=False, doors=doors)
experiment_acc, experiment_count = calculate_accuracy(experiment)
control_acc, control_count = calculate_accuracy(control)
experiment_acc_l.append(experiment_acc)
experiment_count_l.append(experiment_count)
control_acc_l.append(control_acc)
control_count_l.append(control_count)
fig, ax = plt.subplots()
ax.plot(range(3, 10), experiment_acc_l, 'b-', label='实验组')
ax.set_ylabel('准确率')
ax.set_title('不同门数下两组对照')
ax.plot(range(3, 10), control_acc_l, 'r-', label='对照组')
ax.set_xlabel('门数')
plt.legend()
plt.show() 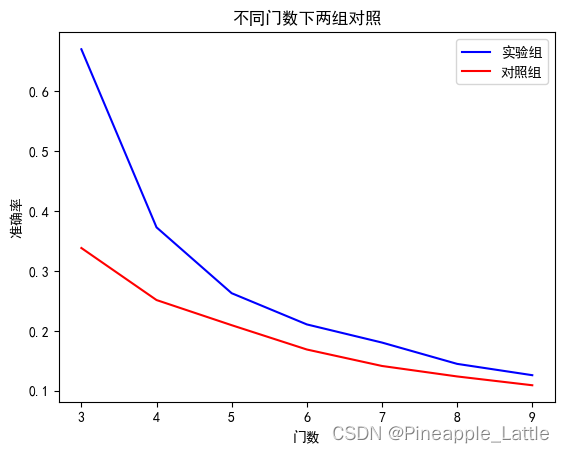















 6710
6710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









