







最近由于项目要求,需要爬取全球注册公司列表,应该这个是非常庞大的集合,目测有上千万个,加之之前了解过pyspider这个框架,所以用它来练练手,发现十分方便和好用。
一、搭建框架
Pyspider是一款国人开发强大的爬虫系统,其中文网站为:点击打开链接。本项目还需要用到phantomJs,它是一个没有界面的浏览器,因为我们爬虫的时候并不需要浏览什么,它可以提供一个浏览器环境的命令行接口,除了没有界面,和普通浏览器没有什么区别。我们使用它是为了模拟浏览器的访问,避免网站的反爬虫机制限制我们的爬虫。
配置这个框架需要三个步骤:
1、安装pip: 这个接触python 的人应该都知道;
2、安装phantomJs : 下载地址为点击打开链接。里边还有对应不同操作系统的详细安装说明。
3、安装pyspider: 我们熟悉的命令: pip install pyspider
完成之后,命令行输入:
pyspider all
然后用浏览器访问http: // localhost:5000, 就可以看到正常的pyspider界面:

要创建项目的话,点create(右侧的),然后输入项目名和要爬取网站的初始url。我们选用的网站是:https://companylist.org/categories/ 。这个网站包含了全球所有的注册公司列表。![]()
创建好后点进去就是像下图这样的,pyspider已经为你搭建好了大部分框架,然后你需要做的就是一些修修补补。
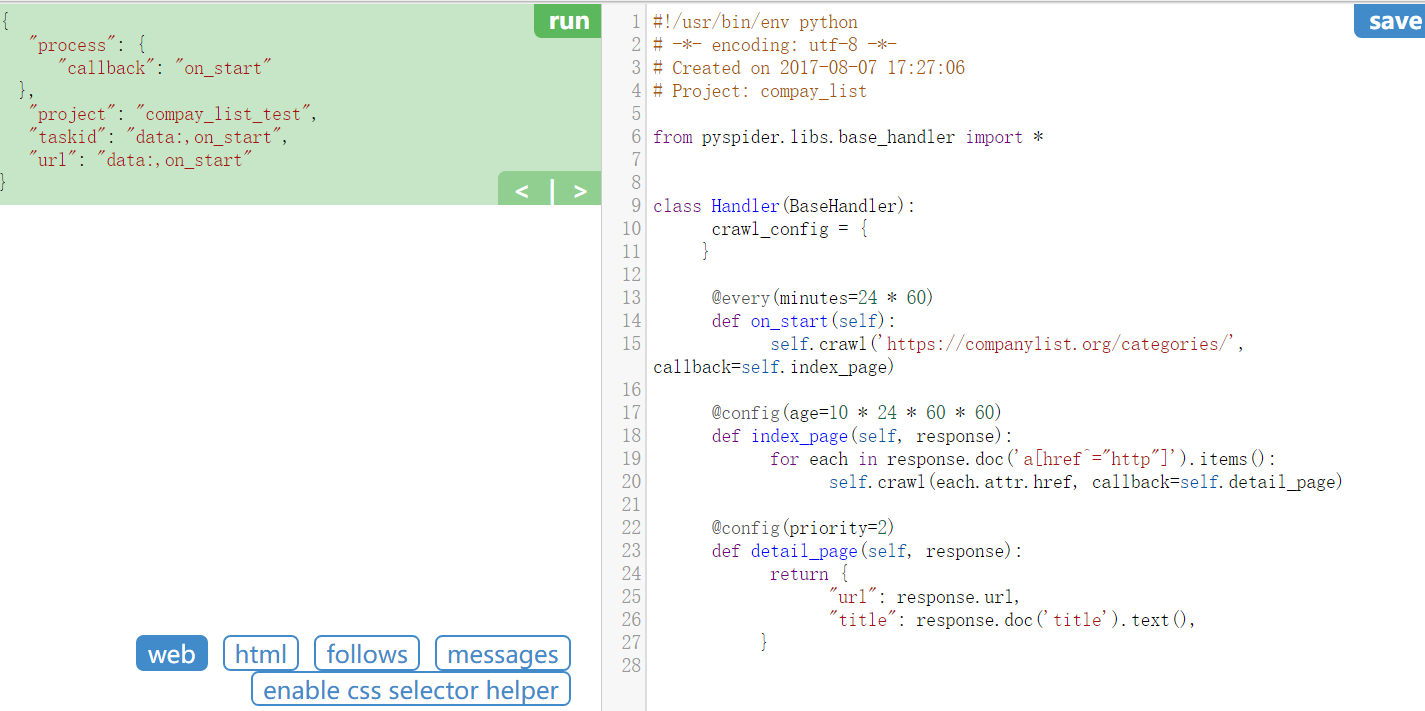
上面的框架的代码有几个部分,第一个部分是on_start函数,这个函数相当于是项目的入口,打开初始网页,将获取的内容传到index_page(callback = self.index_page), index_page 处理之后得到一个按公司类别分类的url集合,然后再依次打开这些网址,获得原始的html,然后传给detail_page, 这个函数负责处理这个html,获取我们想要的公司名称,存到文件中。注意,框架给出的代码没有这些功能,只是它设计好了这几部分,具体的代码需要我们添加。
二、分析网页
这个网站(https://companylist.org/categories/)的公司是分类别的,如下图,我们要获得每个类别的url,然后方便进一步爬取。这个网页是这样的:

我们要获得这些类别的url, 是在index_page里处理,具体的做法很简单,只需要修改如下代码:
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False)
前边说了, response是在on_start函数打开这个页面后获得的内容,doc('a[href^="http"]')是调用了PyQuery里的doc函数,筛选之后得到url列表,然后再分别打开(crawl()函数),获得的内容传到detail_page。里边的validate_cert=False是为了解决HTTP 599这种证书问题。
完成了这一步,我们需要来修改detail_page函数。这个函数需要匹配公司名称,获取下一页的url, 然后递归调用本函数,就获得了所有的公司名称,最后需要存到一个文件中。
公司名称我准备采用正则匹配的方式,获得下一页我准备用PyQuery中的doc函数,具体代码如下:
def detail_page(self, response):
html = response.content
pattern = re.compile('<span class="result-name">.*?<a href=.*?>(.*?)</a>.*?href',re.S)
result = re.findall(pattern, html)
print result
f = open("company_list.txt",'a')
for item in result:
item1 = item + ";"
f.writelines(item1)
f.close
nextUrl = response.doc('a[class="paginator-next"]').attr.href
print nextUrl
if nextUrl:
self.crawl(nextUrl,callback=self.detail_page,validate_cert=False)
return {
"url": response.url,
"title": response.doc('title').text(),
}
完成之后,整个代码如下,可以看到,其实我们也没有做很多的修改。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-07-01 16:47:26
# Project: company_list
from pyspider.libs.base_handler import *
import re
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://companylist.org/categories/', callback=self.index_page,validate_cert = False)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False)
@config(priority=2)
def detail_page(self, response):
html = response.content
pattern = re.compile('<span class="result-name">.*?<a href=.*?>(.*?)</a>.*?href',re.S)
result = re.findall(pattern, html)
print result
f = open("company_list.txt",'a')
for item in result:
item1 = item + ";"
f.writelines(item1)
f.close
nextUrl = response.doc('a[class="paginator-next"]').attr.href
print nextUrl
if nextUrl:
self.crawl(nextUrl,callback=self.detail_page,validate_cert=False)
return {
"url": response.url,
"title": response.doc('title').text(),
}三、调试运行
pyspider是可以在浏览器上调试的,点击save之后,再点击run, 可以看到follow 出现了一个红色的“1”。这是第一个初始页面获得的结果。

点击follows,可以看到

点击那个绿色的三角形按钮,可以看到:
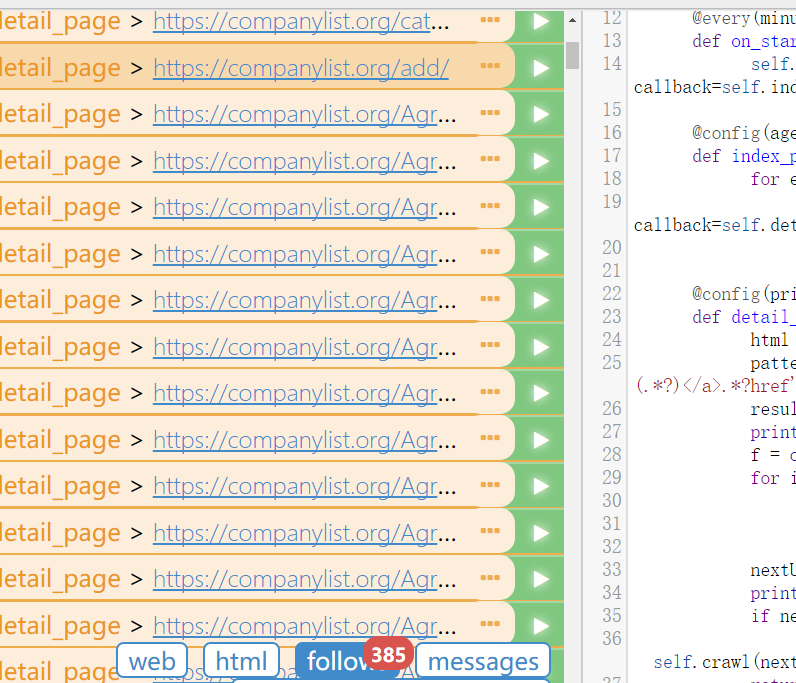
继续点进去,可以看到:

这是某个具体内含公司的页面,中间的黑色窗口是运行结果,可以看到里边有一些公司,自此,调试部分完成。
回到创建项目的地方,将status下的设置为running, 然后点击actions下的run, 就可以运行该爬虫了,你可以看到自己的当前目录下多了一个company_list.txt文件,它的大小随着程序的运行不断增加。

















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









