








1. 前言
牛课网在组织一个编程之美的活动, 这次的题目是 http://www.nowcoder.com/discuss/18223?type=0&order=0&pos=2&page=1
正好是使用爬虫进行操作的。就想到使用pyspider写一下了。
pyspider的相关资料:
http://docs.pyspider.org/en/latest/tutorial/
2. 实现流程
2.1 分析网页
我们的目标站点是 https://chi.taobao.com
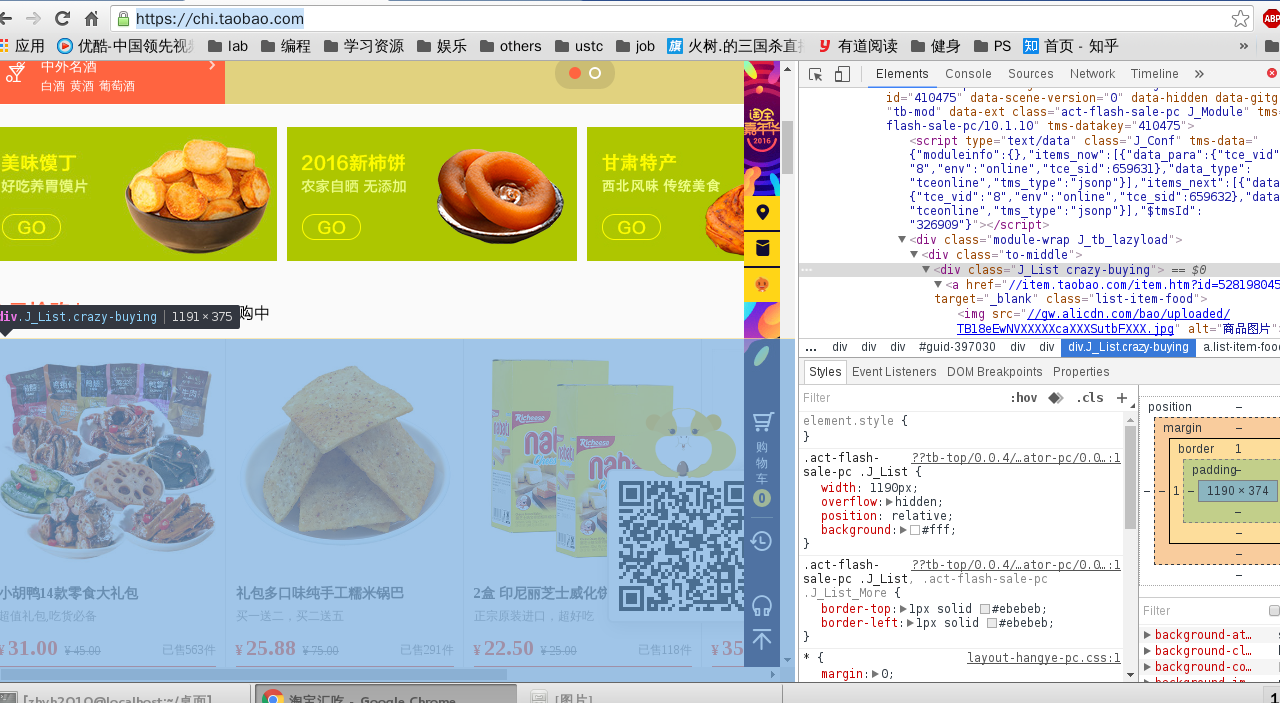
根据这个信息,我们可以非常方便的解析出相应商品的各种信息, 然而并不是这样, 商品的数据都是通过json异步加载出来的。

从网页源码来看, 根本提取不到任何有用信息
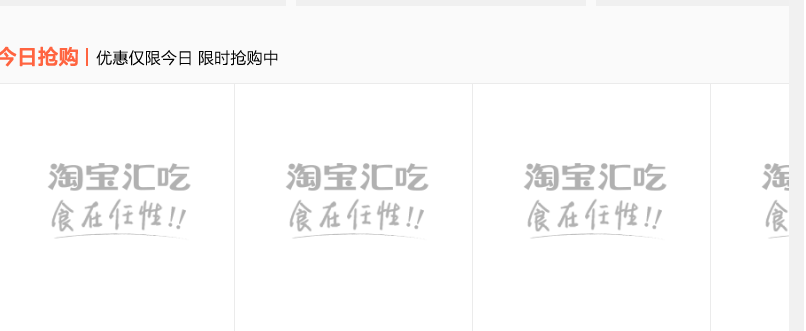
这个是没有加载上json数据时候的基本情况
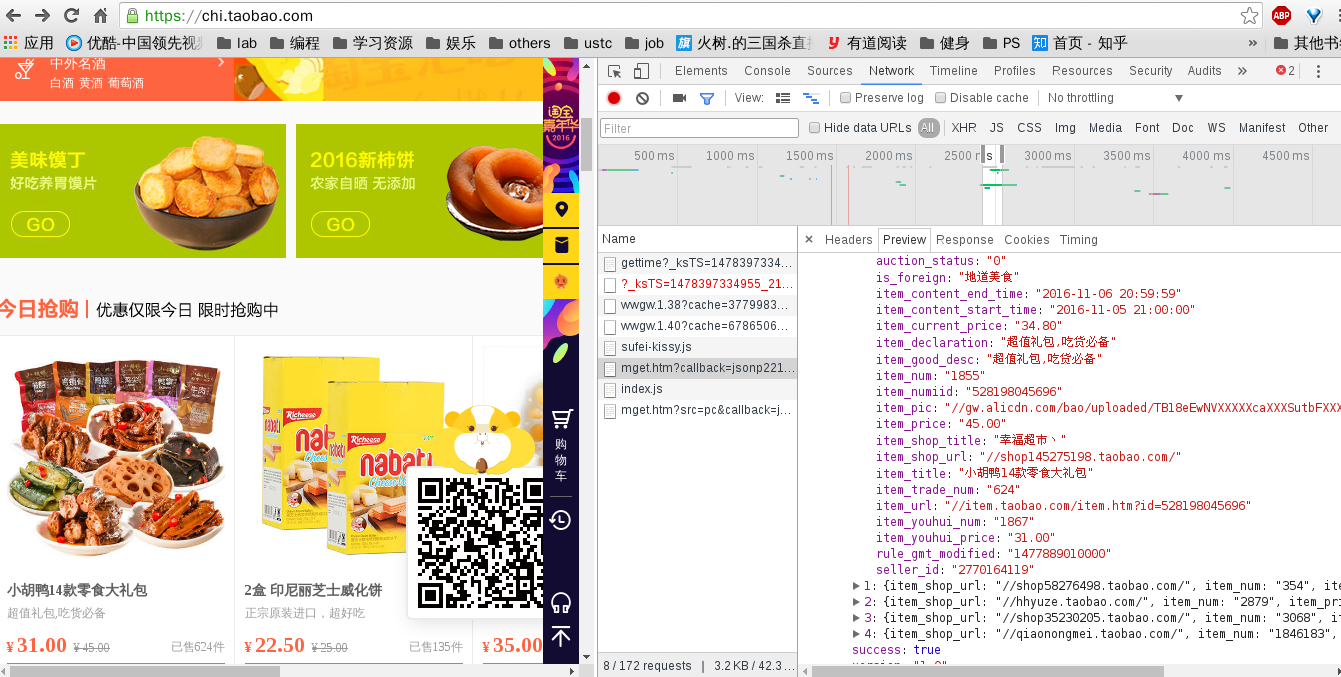
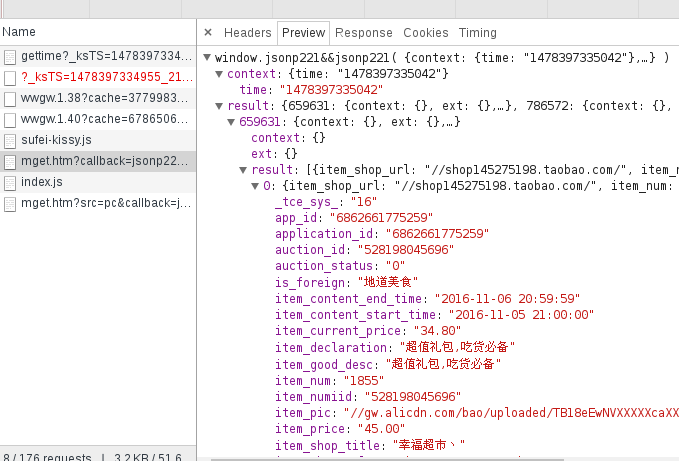
通过chrome强大的监控功能,我们找到了请求的数据
得到数据源之后, 处理就比较方便了
2.2 参考资料及其记录
- windows 上 pyspider 出现各种莫名其妙的问题, 建议使用 linux
- Python Objects与String之间转换 : http://blog.sina.com.cn/s/blog_4ddef8f80102v8af.html
- mysqldb 使用 http://blog.csdn.net/zhyh1435589631/article/details/51544903
- pyspider 属性 https://pythonhosted.org/pyquery/attributes.html
- mysqldb 安装出错: http://stackoverflow.com/questions/5178292/pip-install-mysql-python-fails-with-environmenterror-mysql-config-not-found
- pyspider 解析json https://segmentfault.com/a/1190000002477870
2.3 数据库相关
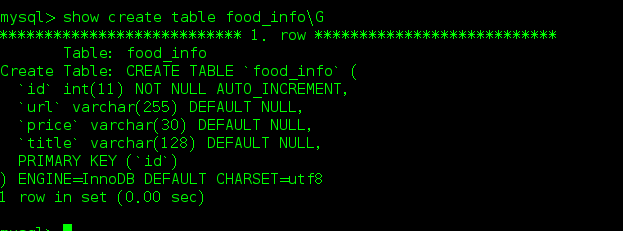
2.4 实现代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2016-11-05 23:18:55
# Project: taobao_food
from pyspider.libs.base_handler import *
import re
import json
import MySQLdb
class Handler(BaseHandler):
# 数据库链接配置
def __init__(self):
db_host= "127.0.0.1"
user= "root"
passwd="zhyh2010"
db="taobao_food"
charset="utf8"
conn = MySQLdb.connect(host=db_host, user = user, passwd=passwd, db=db, charset=charset)
conn.autocommit(True)
self.db=conn.cursor()
# 爬虫的起始url
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://tce.taobao.com/api/mget.htm?callback=jsonp221&tce_sid=659631&tce_vid=8,2&tid=,&tab=,&topic=,&count=,&env=online,online',
callback=self.json_parser)
# 解析相应的 json 数据
@config(age=24 * 60 * 60)
def select_json(self, response):
content = response.text
pattern = re.compile('window.jsonp.*?\((.*?)\)', re.S)
content_select = re.findall(pattern, content)
return content_select[0].strip()
# 提取相应数据 插入数据库表中
def product_info(self, response):
for data in response["result"]:
res = {
"item_pic": "https:" + data["item_pic"],
"item_youhui_price": data["item_youhui_price"],
"item_title": data["item_title"]
}
sql ="insert into food_info(url, price, title) values (%s,%s,%s)"
values = [(res["item_pic"], res["item_youhui_price"], res["item_title"])]
self.db.executemany(sql, values)
# 解析 json
@config(age=24 * 60 * 60)
def json_parser(self, response):
content = self.select_json(response)
contents = json.loads(content)
subres = contents["result"]
for each in contents["result"]:
info = self.product_info(subres[each])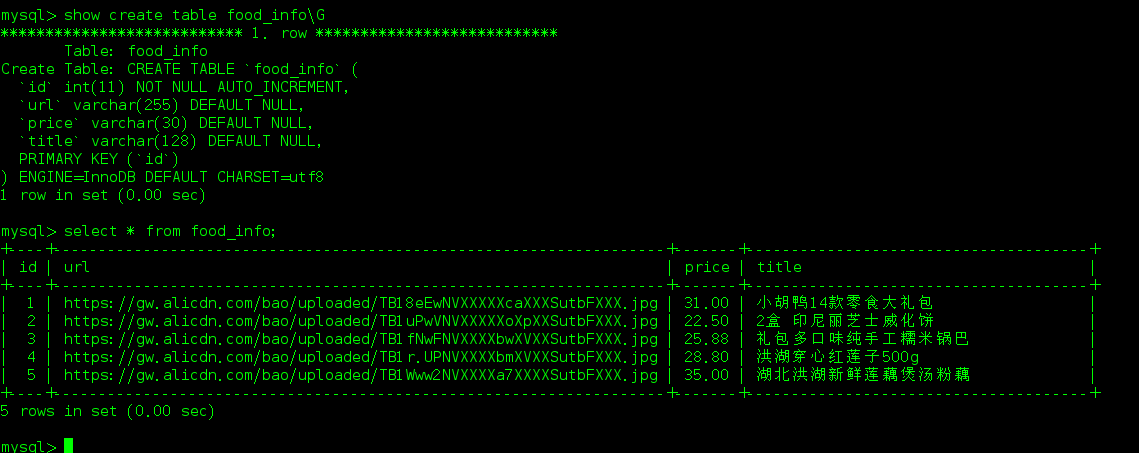















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









