







 支持向量机(SVM)是一种基于统计学习理论的机器学习方法,用于找到最佳分隔超平面,最大化样本间间隔。OpenCV 3.1.0提供了SVM的支持,包括线性核、多项式核、高斯核和Sigmoid核等。在实际应用中,由于数据可能线性不可分,核函数的作用是将数据映射到高维空间使其变得可分。本文介绍了如何使用OpenCV 3.1.0建立训练样本、训练SVM模型以及进行预测,通过实例展示了对水果图像的分类。
支持向量机(SVM)是一种基于统计学习理论的机器学习方法,用于找到最佳分隔超平面,最大化样本间间隔。OpenCV 3.1.0提供了SVM的支持,包括线性核、多项式核、高斯核和Sigmoid核等。在实际应用中,由于数据可能线性不可分,核函数的作用是将数据映射到高维空间使其变得可分。本文介绍了如何使用OpenCV 3.1.0建立训练样本、训练SVM模型以及进行预测,通过实例展示了对水果图像的分类。
什么是支持向量机SVM
支持向量机是20世纪90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,也能获得良好统计规律的目的。它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
通俗来说,支持向量机是一个能够将不同类样本在样本空间分隔的超平面。 换句话说,给定一些标记(label)好的训练样本 (监督式学习), SVM算法输出一个最优化的分隔超平面。
- 如何评判最优的超平面?
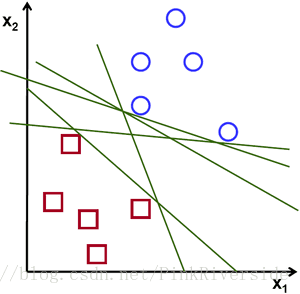
给定分别属于两类(圆形和正方形)的二维点,这些点可以通过直线分割。
可以看出,能将两类样本分开的直线有无数条。如何定义一条直线好坏的标准?
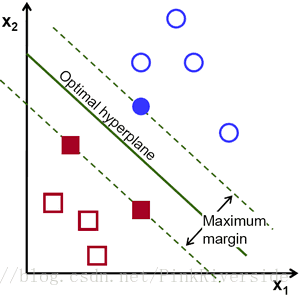
距离样本太近的直线不是最优的,因为这样的直线对噪声敏感度高,泛化性较差。 因此我们的目标是找到一条直线,离所有点的距离最远。
由此, SVM算法的实质是找出一个能够将某个值最大化的超平面,这个值就是超平面离所有训练样本的最小距离。这个最小距离用SVM术语来说叫做间隔(margin) 。 概括一下,最优分割超平面最大化训练数据的间隔。
SVM的核心——核函数
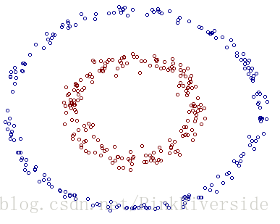
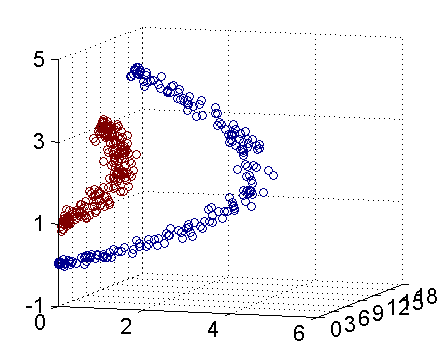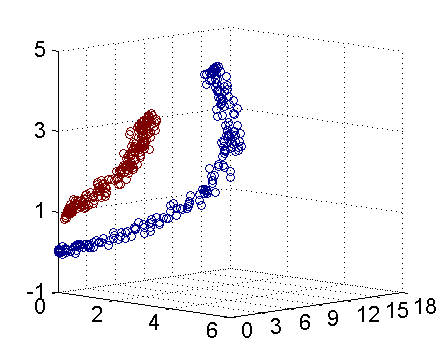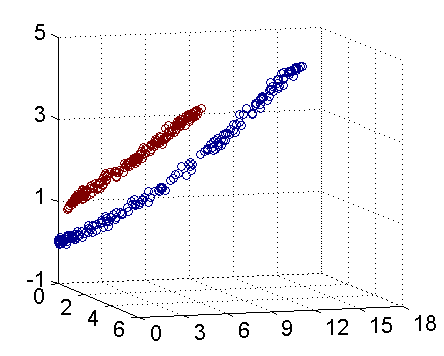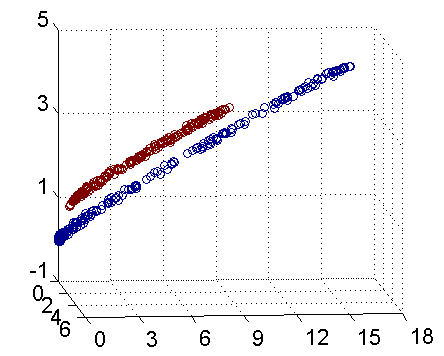
很多情况下需要分类的数据都是线性不可分数据。一种解决方法是选择一个核函数(Kernel)K,将原始数据映射到高维空间,使原始数据线性可分问题变为在高维空间线性可分的问题。如图所示。
常用核函数:
①线性核:K(x,y)=x·y
②多项式核:K(x,y)=[(x·y)+1]^d
③高斯核:K(x,y)=exp(-|x-y|^2/d^2)
④Sigmoid內积核:K(x,y)=tanh(a(x·y)+b)
OpenCV在很久以前就集成了SVM功能,然而升级到3.0和3.1版本后发生了很大的变化。这里只对3.1版本进行考虑。
建立训练样本
一开始训练数据用的是int类型,即
int colors[8][3];
Mat trainingDataMat(8, 3, CV_32SC1, colors);
结果报错:
OpenCV Error: Assertion failed (_samples.type() == CV_32F) in cv::ml::SVMImpl::do_train, file C:\buildslave64\win64_amdocl\master_PackSlave-win64-vc14-shared\opencv\modules\ml\src\svm.cpp, line 1370
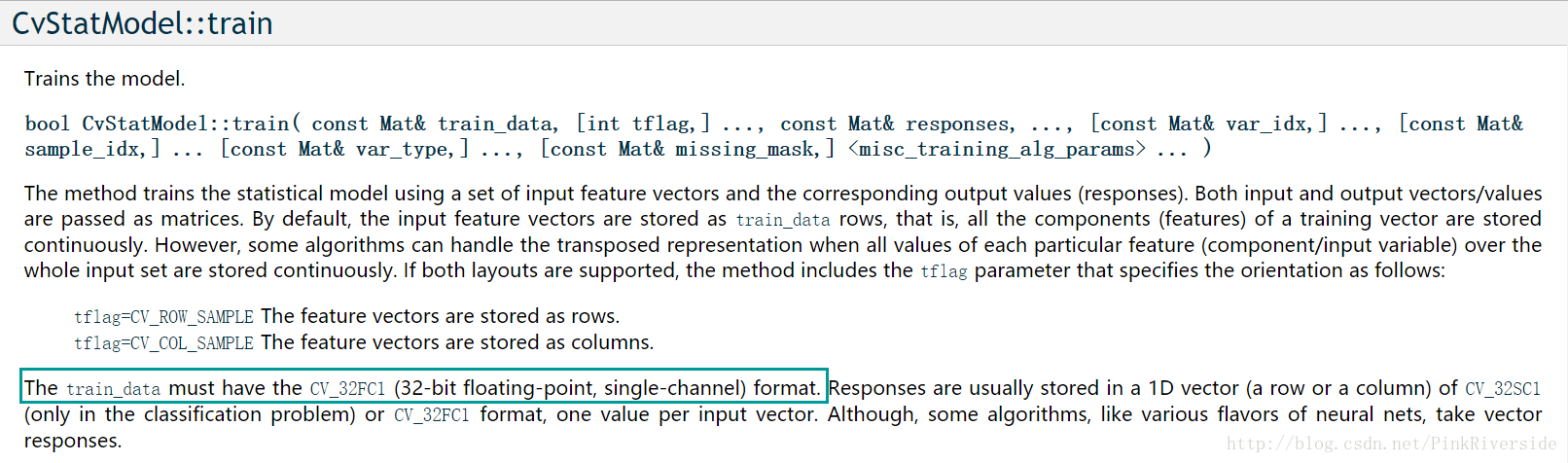
查询官方API发现:训练数据必须为CV_32FC1格式。
训练支持向量机
//初始化SVM
Ptr<SVM> svm = SVM::create();
svm->setType(SVM::Types::C_SVC);
svm->setKernel(SVM::KernelTypes::LINEAR 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









