







玩linux的同学在bash里一定经常用下面这一段代码:
rm -rf /*.txt这里其实就是一个非常简单的删除当前目录下所有txt文件的命令, ’*’号其实就一个 ‘通配符’。表示任何形式的数据。 从这里我们就可以引出正则表达式的概念:
正则表达式是用来简洁表达一组字符串的表达式,或者你可以将它理解为高级版的 通配符 表达式
举个例子:
import re
test = 'python is the best language , pretty good !'
p = re.findall('p+',test)
print(p)
'''
OUT:
['p', 'p']
'''正则表达式的语法:
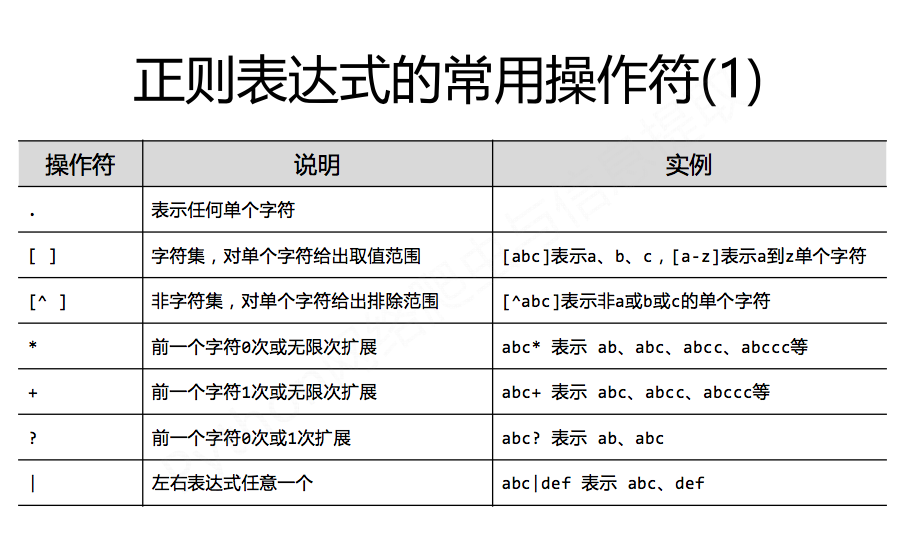
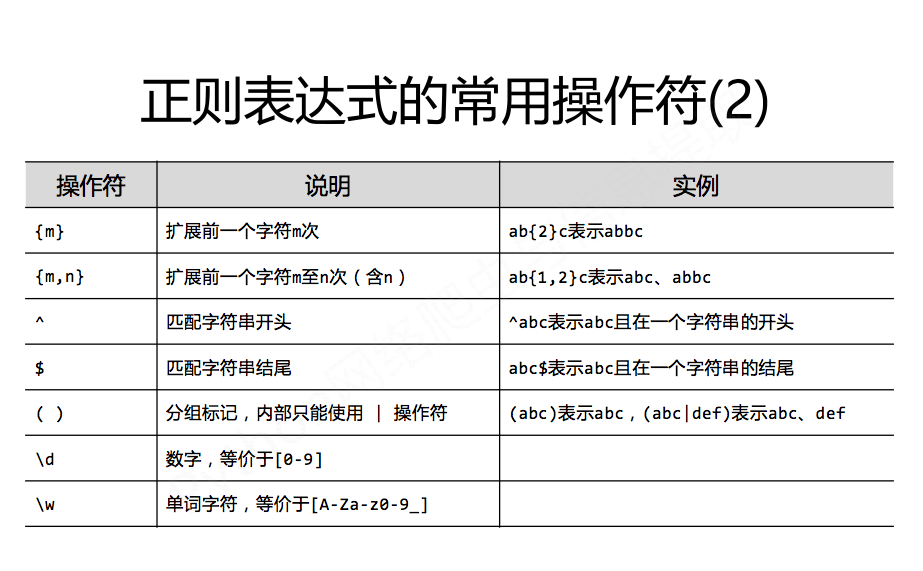
正则表达式: 对应匹配的字符串:
P(Y YT
PYTHON+ 'PYTHON'、'PYTHONN'、'PYTHONNN' ...
PY[TH]ON 'PYTON'、'PYHON'
PY[^TH]?ON 'PYON'、'PYaON'、'PYbON'、'PYcON'...
PY 'PN'、'PYN'、'PYYN'、'PYYYN'...
常用的正则表达实例:
注意一下 : $ 表示结束匹配
正则表达式 匹配的字符串
^[A‐Za‐z]+$ 由26个字母组成的字符串
^[A‐Za‐z0‐9]+$ 由26个字母和数字组成的字符串
^‐?\d+$ 整数形式的字符串
^[0‐9][1‐9][0‐9]$ 正整数形式的字符串
[1-9]\d{5}(?!\d) 中国境内邮政编码,6位
[\u4e00‐\u9fa5] 匹配中文字符
\d \d
\d+\.\d+\.\d+\.\d+ IP地址的表达式
Python的re库的基本使用
re库是Python内置的标准库,所以我们不用安装, 直接import re就能直接使用。re库有着非常强大的功能! 学习好re库对我们爬虫的编写有极大的帮助!
re库 采用了 raw string 类型来表示正则表达式,
例如: re1 = r'[1-9]\d{5}' 这里是表示一个1~9的数字+4个0~9的数字 如:10000就符合re标准
使用raw string 的好处是 我们不用手动去再次写转义字符了。 如果不用raw string 类型, 上面的正则表达式我们就得这么写: re1 = '[1-9]\\d{5}'
re库的主要功能函数:

re.search:
'''
re.search(pattern, string, flags=0)
在一个字符串中搜索匹配正则表达式的第一个位置
返回match对象
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ flags : 正则表达式使用时的控制标记
'''
str1 = 'hello , world ,life is short ,use Python .WHAT? '
a = re.search(r'\w+',str1)
print(a.group()) # hello常用的第三个参数 flags:
re.IGNORECASE:忽略大小写,同 re.I
re.MULTILINE:多行模式,改变^和$的行为,同 re.M
re.DOTALL:点任意匹配模式,让’.’可以匹配包括’\n’在内的任字符,同 re.S
str1 = 'hello , world ,life is short ,use
b = re.search(r'w.+D',str1,re.I)
print(b.group())
# world常用函数re.findall()
'''
re.findall(pattern, string, flags=0)
搜索字符串,以列表类型返回全部能匹配的子串
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ flags : 正则表达式使用时的控制标记
'''
c = re.findall(r'\w+',str1)
print (c)
#['hello', 'world', 'life', 'is', 'short', 'use', 'Python', 'WHAT']
re库的另一种用法
在前面的例子中,我们都是在调用方法时传入一个原生字符串来表示re表达式,但是在多次搜索符合同一规则的数据时,这样做就会使得效率大大降低。相对应的我们有替代的做法。
str2 = 'hssso'
re1 = re.compile(r'h.{3}o')
print(re1.findall(str1))
print(re1.findall(str2))
# ['hello']
# ['hssso']先把正则进行编译,在进行查找,就能大量节省时间,增加效率
关于Match 对象:
match对象是一次匹配的结果,他包含了很多的信息:
'''
match 对象的属性
re.match(pattern, string, flags)
.string : 待匹配的文本
.re : 匹配时使用的patter对象(正则表达式)
.pos : 正则表达式搜索文本的开始位置
.endpos : 正则表达式搜索文本的结束位置
'''
d = re.match(r'e.+d',str1)
print(d.group()) # ello , world
print (d.string) # hello , world ,life is short ,use Python .WHAT?
print (d.re) # re.compile('e.+d')
print (d.pos) # 0
print (d.endpos) # 48其他的高级用法,实战中用到再了解吧!迫不及待想开车,哈哈哈
原作者链接:
每天的学习记录都会 同步更新到: 微信公众号: findyourownway 知乎专栏:https://zhuanlan.zhihu.com/Ehco-python blog : www.ehcoblog.ml















 4328
4328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









