







https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
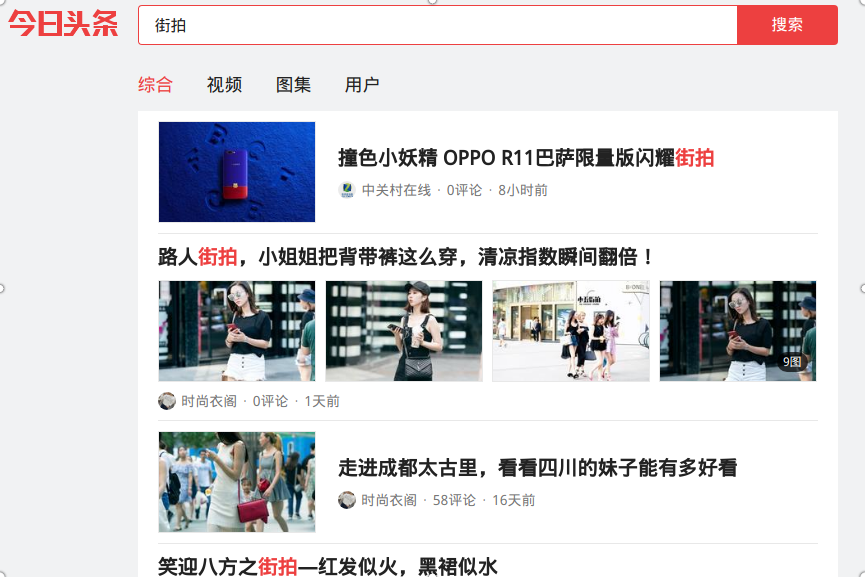
由于是动态网站了,

这是刚打开时候的情况,我下拉至最底下的时候,

原来这就是传说中的Ajax动态网页技术,敲黑板:
Ajax 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新。就是如打开某个网页,鼠标下拉,网页又多了一部分内容,在这个过程之中只加载了多出来的那部分内容,并没有重新加载整个页面内容,这样的一项技术就是Ajax创建快速动态网页的技术。
然后就可以修改offset的值来获取任意索引页,
第一页索引页 offset = 0
第二页索引页 offset = 20
第N页索引页 offset = (N-1)*10

keyword = "街拍",此处不是上次见过的‘GBK’格式了,
综上我们就可以访问网站:
https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1
改变offset的值来确定访问页面数量。
1.确定框架,获取到正确的页面内容
#!/usr/bin/env python
# coding=utf-8
import os
import re
import json
import requests
import bs4
from urllib.parse import urlencode
def get_html(offset):
# search=input("请输入关键字:")
search = '街拍'
print('搜索...{}'.format(search))
data = {
'offset': offset,
'format': 'json',
'keyword': search,
'autoload': 'true',
'count': '20',
'cur_tab': 1 # 下拉刷新
}#Ajax请求参数
url = 'https://www.toutiao.com/search_content/?'+urlencode(data)# 把data键值对转换成a=1&b=2这样的字符串,衔接在主体链接后面。新技能get
try:
r = requests.get(url,timeout = 30)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
print("Open Error")
def get_page_index(offset):
html = get_html(offset)
print(html)
def main(offset):
html = get_page_index(offset)
print(html)
if __name__ == '__main__':
main(0) # 先访问一页数据跑起来
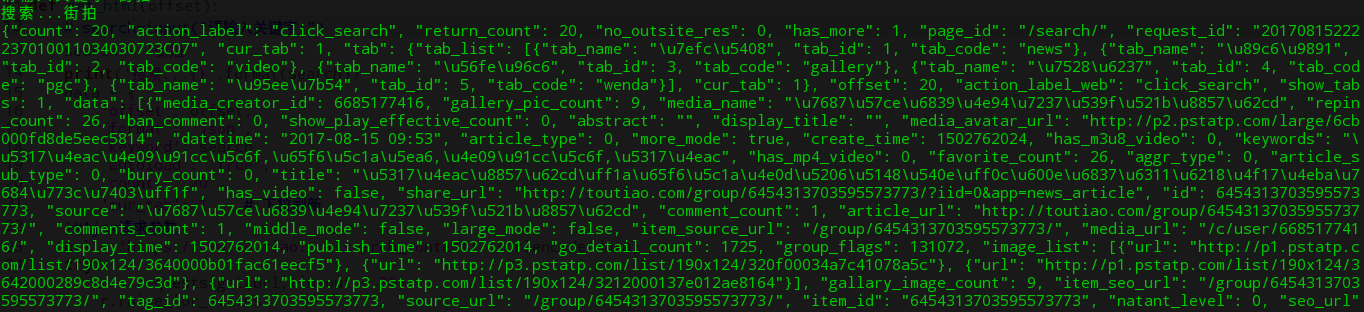
其实后来发现,这个网站不同于以往的网站,因为以往的网站我们可以通过链接到期望的页面内,这次逗逼了,出来一堆鬼东西,我打开页面发现,的确是页面发生变化才导致get访问到的东西全是密密麻麻的恐惧。其实,慢慢来,刨根问底,刨个稀巴烂。哈哈

2.页面内获取各个文章链接
爬虫,就是在一摞乌漆墨黑的里面找到想要的数据,所以找吧......怎么找呢?黔驴技穷了
好了,我们下来要干嘛呢?
在页面内找文章链接,然后打开,找图片,下载
吼吼,说起来好像就是挺简单啊!!!
找吧,文章链接!呢肯定是http://波拉波拉拨拉一串串哦东西
那就是这个了:

根据四级飘过的水平来看,article_url,那就是文章链接了。
打开一看,吼,居然是女神诶!!!那就好好写代码,把女神装电脑上,^O^
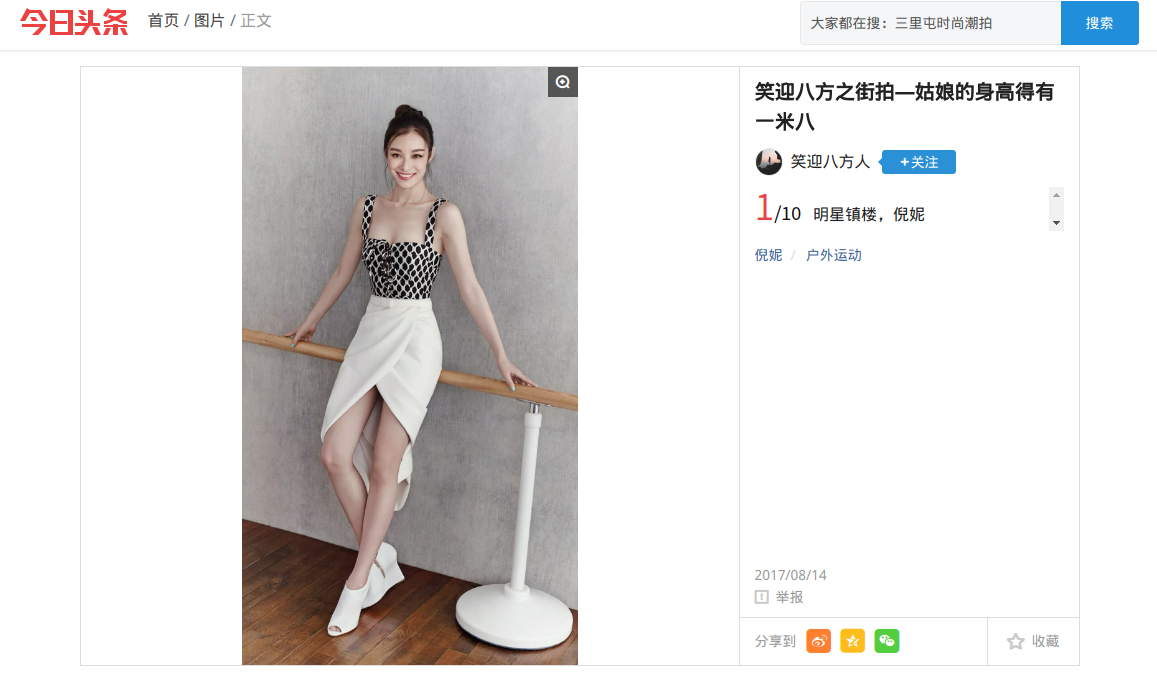
但是,这么密密麻麻的字,哪个程序员搞得网站?算了,是自己技术太渣了,好好学艺吧!
这么乱的排版让我怎么结构起来呢?呀,心塞,好吧,我再去摸索摸索......ok
我在这里发现了一丝端倪:
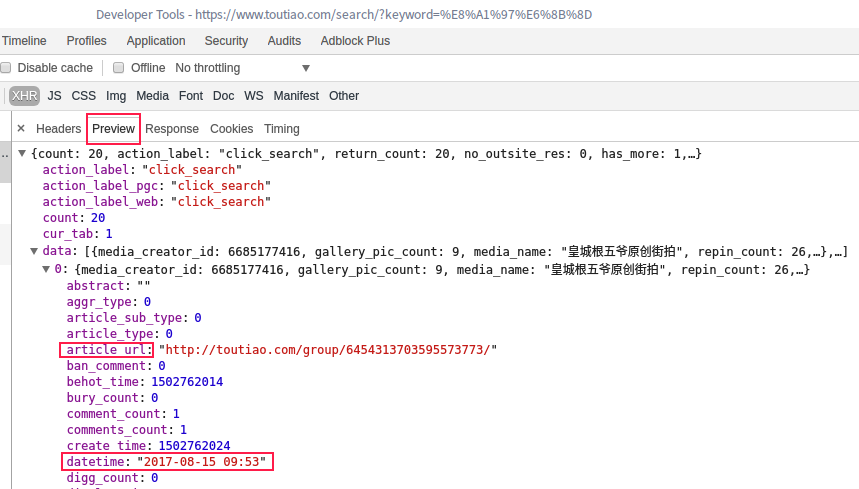
这样看起来是不是清晰了好多,我们把文章链接拿出来就好了。然后代码就更新一点点哈
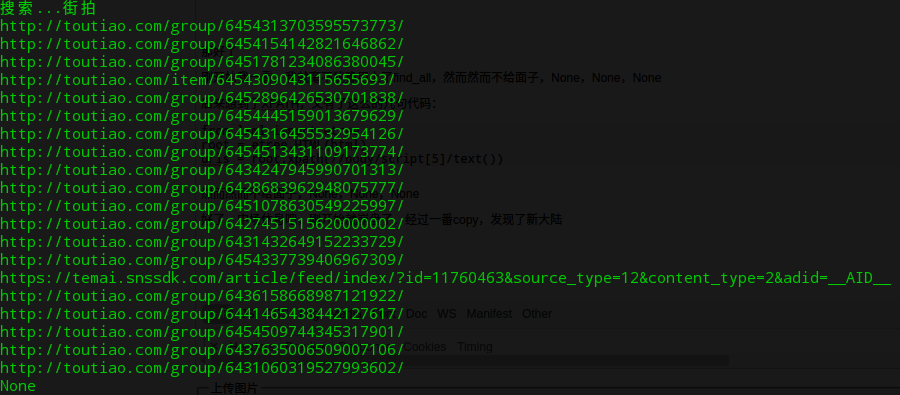
那好了,共21个链接,中间哪个乱入的应该是个广告吧!不用管它
文章链接有了,下来要做的就是打开文章,找到图片链接,下载,那就开始下一步!
3.打开文章,分析网页,获取图片链接
def get_page_html(url):
try:
r = requests.get(url)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
print("请求详情页失败!")
def get_content(html,url):
soup = bs4.BeautifulSoup(html,'lxml')
print(soup)
def get_page_index(offset):
html = get_html(offset)
#print(html)
urls = parse_index_page(html)
for url in urls:
html = get_page_html(url)
result = get_content(html,url)访问文章链接后,老规矩:
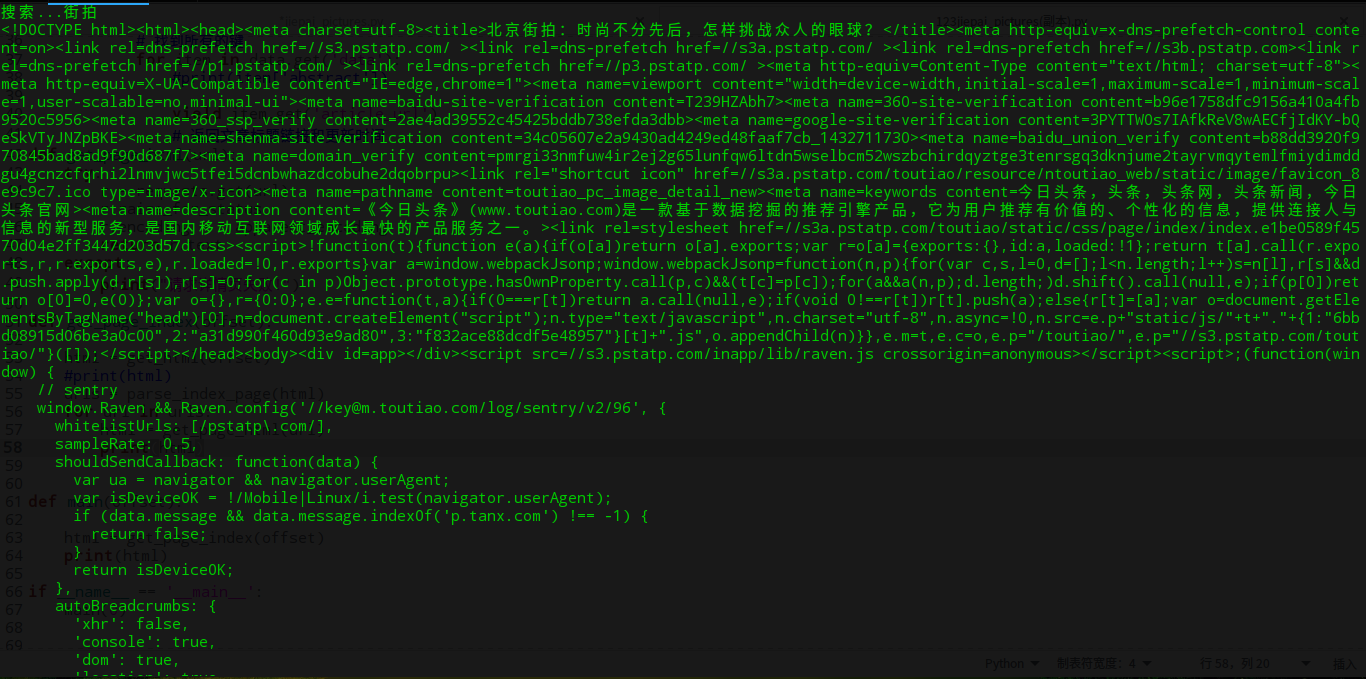
老天啊!我想要一个这么个样子的:
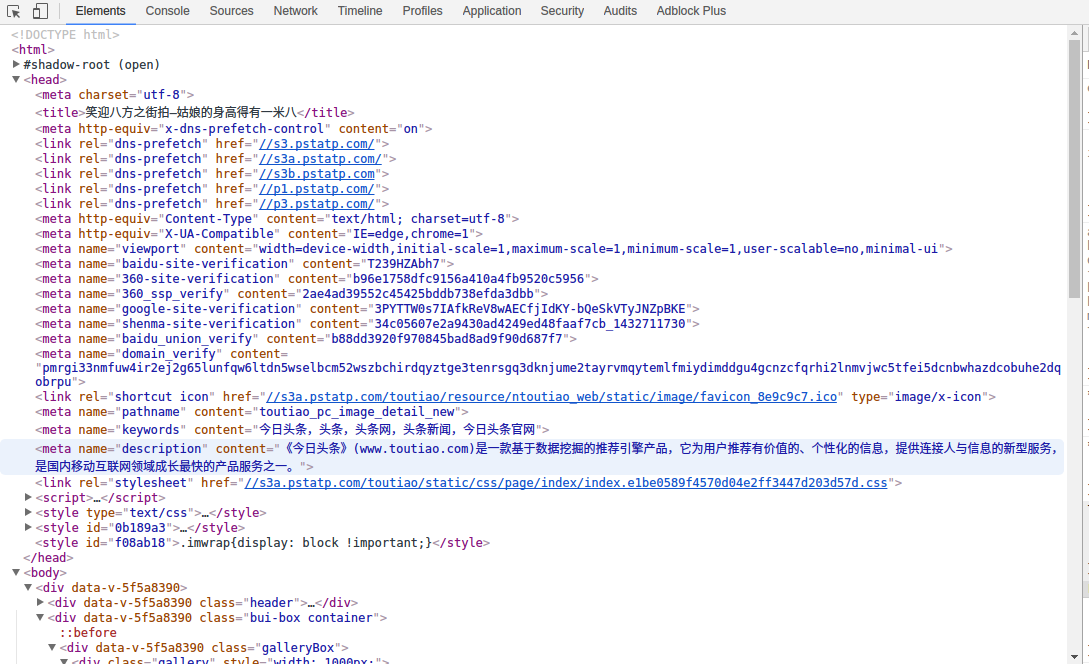
天公不作美,不碍事,那就老套路吧。毫不犹豫煮汤用上了find_all,然而然而不给面子,None,None,None
后来想到了XPATH,又有了这么的几句代码:
from lxml import etree
root = etree.HTML(html)
urls = root.xpath(//body/script[5]/text())
然而然而不给面子,None,None,None
好了,中场休息吧,刚开始就崩盘了,经过一番copy,发现了新大陆
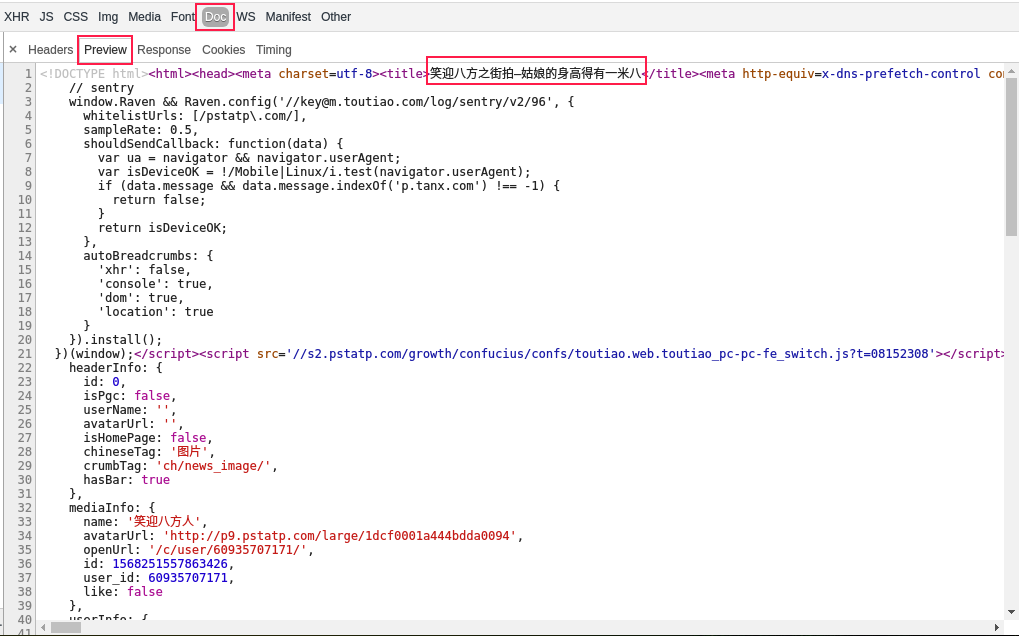
咦,貌似有点神似了,再瞅瞅!
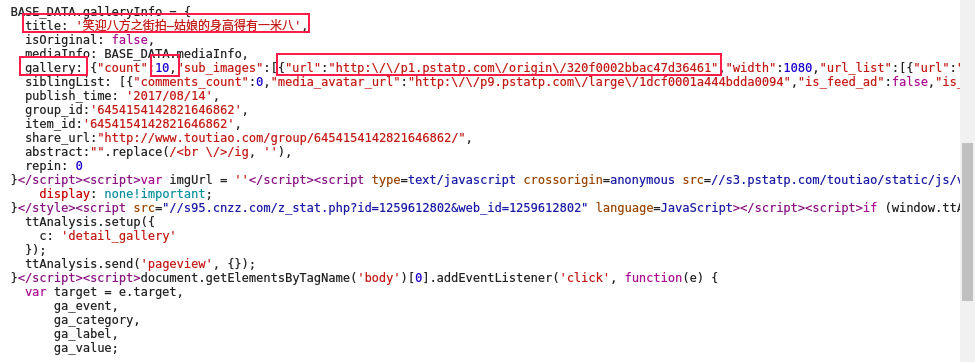
这几个又是嘛玩意,回原网页瞅瞅,

难道哪个10就是10幅图吗?哪个链接就是图片地址吗?打开看看啊

我的天呐,还是原图,哈哈,发现新大陆,那就麻利嗖嗖的开始咯!停,怎么扣图片链接呢?lxml,XPATH都不行啊,咋办?
哦,还有最原始的方法,正则表达式!!!关键时刻---姜还是老的辣
def get_content(html,url):
soup = bs4.BeautifulSoup(html,'lxml')
#print(soup)
title =soup.select('title')[0].get_text() #如果没有text,是何种样子
#print(time)
print(title) #只需要标题
#root = etree.HTML(html)
#images_list = root.xpath('//body/script[5]/text()')
images_pattern = re.compile('gallery: (.*?),\n',re.S)
image_list = re.search(images_pattern, html)
#print(images_pattern)
#urls = image.xpath('.//url')
#images_list = soup.find('gallery')
#/html/body/script[5]/text()
print(image_list)
if image_list:
data = json.loads(image_list.group(1))
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images') # data['sub_images']
images = [image.get('url') for image in sub_images]
if images:
for url in images:
print(url)
else:
pass 完善了get_content函数,得到以下输出:
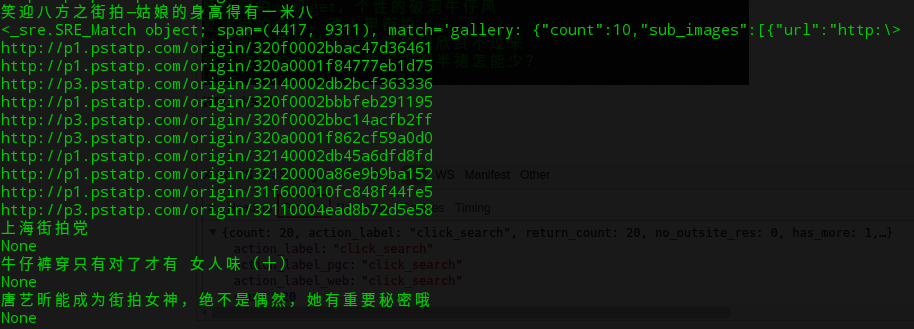
好啦,出来啦!为什么会出现文章内部没有图片链接呢?是因为文章没有图片吗?不是的,因为有的文章的框架不一样导致扣取不到图片链接,或许这也是防爬虫的一种方式吧!等我研制出全版本通用的爬虫再完善吧!处女座绕路吧!哈哈
好啦,接下来那就剩下最后而且是最终的一步;吧小姐姐放到电脑上,我目前是根据文章链接内图片为一个文件夹存储的。因人而异吧!
话不多说,整体代码奉上!
#!/usr/bin/env python
# coding=utf-8
import os
import re
import json
import requests
import bs4
from urllib.parse import urlencode
from multiprocessing.dummy import Pool as ThreadPool
def get_html(offset):
# search=input("请输入关键字:")
search = '街拍'
# print('搜索...{}'.format(search))
data = {
'offset': offset,
'format': 'json',
'keyword': search,
'autoload': 'true',
'count': '20',
'cur_tab': 1 # 下拉刷新
}#Ajax请求参数
url = 'https://www.toutiao.com/search_content/?'+urlencode(data)# 把data键值对转换成a=1&b=2这样的字符串,衔接在主体链接后面。新技能get
try:
r = requests.get(url,timeout = 30)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
print("Open Error")
def parse_index_page(html):
if html:
data = json.loads(html)
if data and 'data' in data.keys():
# 找到所有的键
for item in data.get('data'):
#print(item['abstract'])
yield item.get('article_url')
# 返回文章标题链接和更新时间
def get_page_html(url):
try:
r = requests.get(url)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
print("请求详情页失败!")
def get_content(html,url):
soup = bs4.BeautifulSoup(html,'lxml')
#print(soup)
title =soup.select('title')[0].get_text() #如果没有text,是何种样子
#print(time)
print(title) #只需要标题
#root = etree.HTML(html)
#images_list = root.xpath('//body/script[5]/text()')
images_pattern = re.compile('gallery: (.*?),\n',re.S)
image_list = re.search(images_pattern, html)
#print(images_pattern)
#urls = image.xpath('.//url')
#images_list = soup.find('gallery')
#/html/body/script[5]/text()
#print(image_list)
if image_list:
data = json.loads(image_list.group(1))
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images') # data['sub_images']
images = [image.get('url') for image in sub_images]
if images:
file_path = os.getcwd()
result = {'标题':title,'链接':url,'图片':images}
for url in images:
if not os.path.isdir(file_path+'/街拍/'+title):
os.makedirs(file_path+'/街拍/'+title)
print("正在下载:",url)
with open(file_path+'/街拍/'+title+'/'+str(url)[-8:-1]+'.jpg','wb') as f:
f.write(requests.get(url).content)
else:
pass
def get_page_index(offset):
html = get_html(offset)
#print(html)
urls = parse_index_page(html)
for url in urls:
html = get_page_html(url)
get_content(html,url)
def main(offset):
html = get_page_index(offset)
print(html)
if __name__ == '__main__':
p =ThreadPool(20)
offsets = ([x*20 for x in range(0,6)])
p.map(main,offsets) # 五页数据
p.close()
p.join()















 53万+
53万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









