







首先,奉上女神微博词云一张:


在此之前,我一直以为新浪微博的爬取,需要模拟登录等等
偶然之间,在小歪哥那里得知,有一个网站可以免登录爬取:https://m.weibo.cn/u/+oid,这个oid可以从普通新浪微博那里得到。
点击一个关注用户首页,查看其网页源码,源码页搜索用户名,就会看到如下的内容:
<script type="text/javascript">
var $CONFIG = {};
$CONFIG['islogin']='1';
$CONFIG['oid']='1280761142';
$CONFIG['page_id']='1003061280761142';
$CONFIG['onick']='刘雯';
这个oid就是url里面需要的那个,根据url打开微博链接:
打开开发者工具,这个类似于今日头条的页面,具体可参见今日头条的写作过程。
发现请求网页实际是:

打开上述链接,会发现网页内容并非常见的格式,需要来解析一下,推荐一个json格式在线解析网站:http://www.json.cn/,利用这个就可以看到json格式的网页内容:
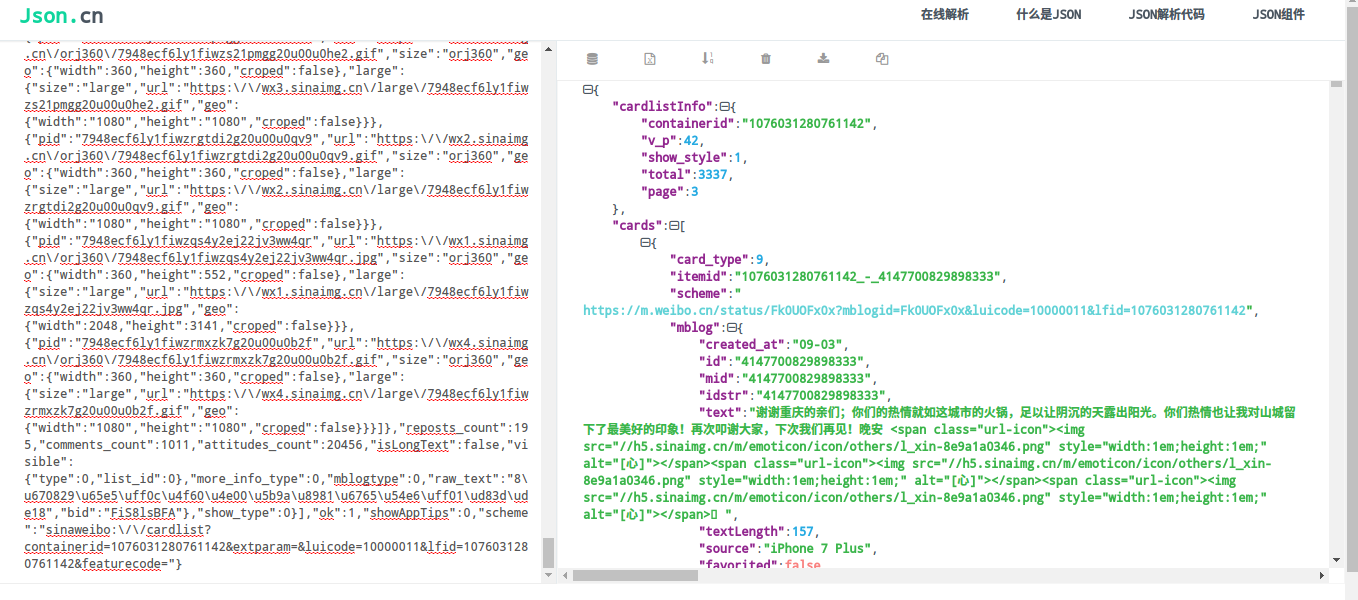
import json,用来解析网页内容。接下来可以访问一个页面,看看我们的思路是否正确。
打开URl
https://m.weibo.cn/api/container/getIndex?type=uid&value=1280761142&containerid=1005051280761142
在XHR里面发现:
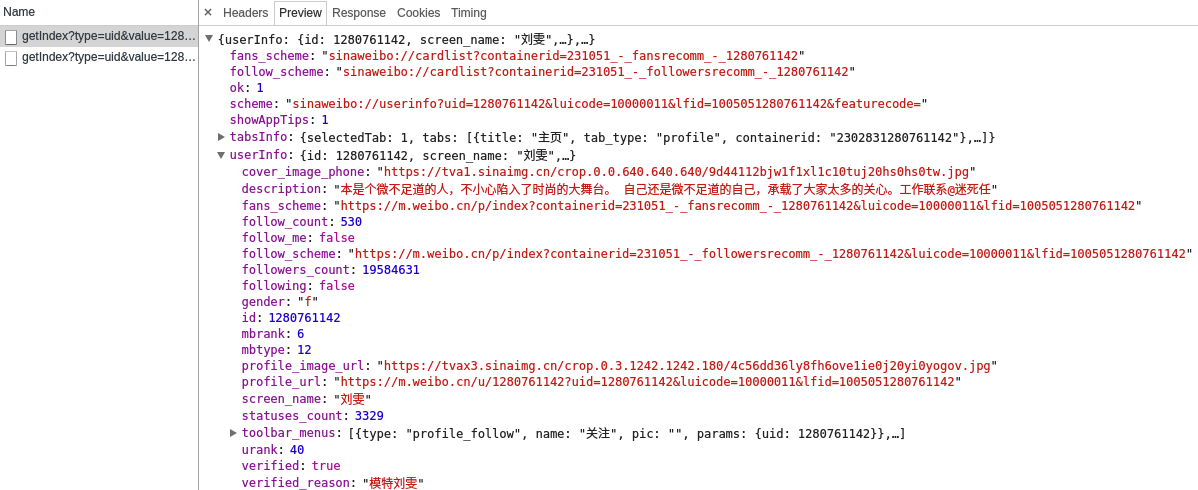
通过对该网页的json格式转换找到微博总数量和微博名称:
#!/usr/bin/env python
# coding=utf-8
import requests
import bs4
import json
import re
import random
import csv
headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'}
total_number = 0
#https://m.weibo.cn/api/container/getIndex?type=uid&value=1280761142&containerid=1076031280761142
#url = 'http://m.weibo.cn/u/1280761142'
num = 0
ip_list = []
save 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









