









写在前面
主要由于最近在重学c/c++以及摸索视觉这一块基础知识,其中产生了很多问题,特别是在看了一个log4z的源码后瞬间产生了18个问题然后记录下来问了做c++的朋友。这18个问题在别人看来肯定觉得很菜,都是很基本的东西,但它们难在我对c++开发者每天的工作内容的不了解,所以才会有看了面试宝典找个公司进去就知道了这样的回答。所以反过来,我想那些转战android的朋友肯定最初也会有类似的问题。比如说我其中几个问题:
- 宏定义中,有很多代码IDE无法识别,所以如果当中的代码有错误,怎么识别呢?
- 宏定义穿插在代码的任意地方,是不是不规范?
- 类的构造器重载不放在一起是不是不规范?
- 一个cpp文件里面一两千行代码是不是常态?
- wchar_t一般的使用场景是什么?
- ##_VA_ARGS_,”##”这样的命名方式的场景是什么?
如果有初学者问的是android开发相关的内容呢或者说网上的代码和工作中的代码有多少区别呢?所以我依照过去写过的一些项目代码,利用开源的api做了一个应用,里面的不少东西都可以展现android开发者在项目里面每天都在苦逼的干一些什么事情,以及哪些招聘上面没有写的知识需要重点掌握。
与此同时在尝试一些新东西,也算是学习的一种方式,因为先前看到知乎客户端用fragment打造整个app的文章,的确快很多,而恰巧fragment的坑着实又很多,因此看能不能用view来代替。当然,这种方式只是一种尝试而且还在研究当中,并非是android开发每天的工作内容。再加上前端时间看奇异博士,壮哉我大漫威啊~~果断找到它的开源api,做一个尽量好看的东西,没有ui的情况下,已经尽力。
最后,个人认为,这篇文章对其他领域希望学习android的朋友益处不少。
MarvelComic
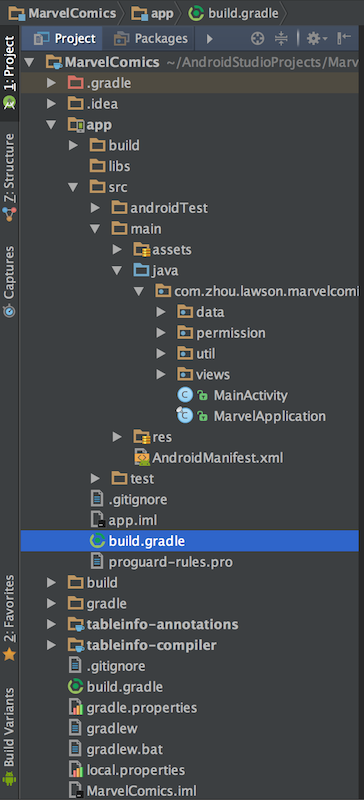
这基本上就是最近每天都面对的项目结构,因为有很多零碎知识网上都有,所以我只能把重点放在结构和流程上。包里面分为data,util,views,以及permission,activity和application单独拿出来放到平级。一般情况下,只需要把application单独拿出来,原因在于,application是我们在开发过程中参与业务相对较少或者最少,而起到一个总管职责的类,可以把它看成是程序的入口,进入你应用的大门。而activity的放置情况有很多种,因为它与业务联系最密切,而多人协调开发又要根据模块来进行划分,所以一般它会单独存放。
当然几乎每个项目的分包都会不一样,但相同的地方肯定都会存在,为何首先要说包结构?因为它很重要,对于android开发来说,头脑里一定要有比较清晰的认识,一说到android项目结构,立马要浮现application,网络,util,特殊view,activity,fragment等等对应的常用包名称以及它们可能会存在的位置。有什么样的作用呢?最重要的就是能够让人迅速的熟悉整个项目结构,公司项目如此,开源项目尤为如此,阅读源码就更是如此了。比如说U2020,如果想要找它的接口地址的用法,不要犹豫直接点击data,或者你希望找到某个界面的动画肯定就是ui。而你又发现多了一个U2020Module.java文件,熟悉点的人一看就知道,肯定是用了dagger2框架,相应的逻辑处理多半在module里面。而这又有一个前提条件,那就是对application,activity以及其他类之间的关系的熟悉。
在这个项目里其结构如下:
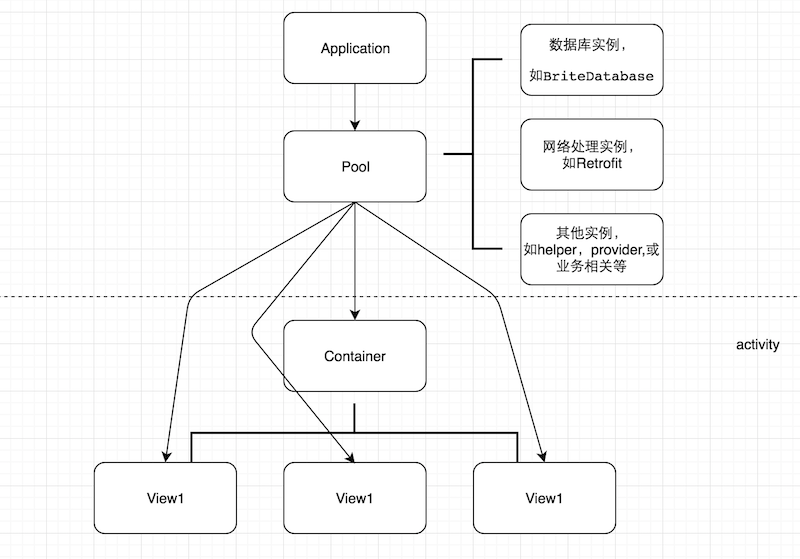
一般情况项目中是没有Pool这个节点的,但隐隐约约从很多项目里也能看出它的存在。很多人都熟悉,在添加地图sdk或者统计sdk等等很多类似的东西的时候,它们往往要求我们在application的onCreate里面加上这样一句代码XXSDK.initialize(this),为什么不加在activity里或是其他什么地方?原因自然不少,但从意图上来说,主要目的就是为了让自己的功能从一开始就完全独立,这也是设计一个库的基本原则,作为一个独立的个体而存在就在于进了application的门,就得各顾各的事,尽量不要互相影响。比如地图初始化启动服务等等跟其他代码没有任何关系,所以只需要把最大的生命周期交给我,我自己玩自己的就行,数据库是否初始化不关我的事,ui是否开始渲染也不关我的事。这样做的好处非常多,比如它与业务完全分开。而这也体现了application的特殊存在。
为了让代码的组织形式更清晰,好懂好理解,扩展性更强。对象池Pool就作为一个组织者放在application里面,有任何相关的业务只需要在Pool里面找就是了。另外,基于dagger1,它有一个叫ObjectGraph的类,是专门用于在application创建时负责一口气创建所需的实例,并在需要的时候拿出来即可。Pool就是其类似的存在,只不过我们不用构建对象图,也不用一一对应,因为散养在这里更加适合,每个view都有极大的可能性会下载图片,或者作数据库操作。这也是我对dagger在这一点上所持的一些怀疑,限制是需要相应代码作处理的,而且也是与业务有关联的,而为了实质性的实现反转,为何不仅仅在思想上进行反转呢?当然dagger2作为dagger1的编译时版本,它更是在原有基础上加强了更多的限制。这点上,我并没有对对象之间的关系进行任何限制,而该对pool用get的时候还得用get,但观念上已经向控制反转靠拢了。
其实这里面的内容说多并不多,说少也可不少,主要分为这样几个部分:
- 网络
Retrofit- 数据库
Database- View
网络
对于网络,先说下题外的,一般招聘要求网络编程,这个词可是个超级大词。但如果单纯要求你会使用sdk自带的UrlConnection/HttpClient却是不行的,尽管很多人会发现进入公司后,基本操作的就是它根本就没有什么可说的。问题在于,当你遇到其他问题的时候会束手无策,多数人会对只会用开源库的人嗤之以鼻的原因也不是不可理喻。
比如,Retrofit很多人都知道这个库,其普及率也是相当高。只要配置配置就可以完美运行,这是jack他们写这个库的初衷,这一点是肯定值得推崇的。但如果因为这个就不去理解它的原理,很难应付各种各样的需求,如在其基础上进行数据加密,怎么实现?这个在其github上可找不到具体的东西,又如一套自定义错误码管理又如何实现?当遇到类似的问题时,大概除了jack这样的工作狂,其他人基本不会回答你提的issue。
要了解这一块内容,一定要深入理解这几个方面的内容:
URL和URI
长连接和短连接
HTTP和HTTPS
Restful
注解
代理等各种比较常见的设计模式
线程池
这只是其中几个比较重要的部分,这些部分仅仅是帮助理解Retrofit的,或许这样的列表太多人提,看起来根本没有动力,如同大一的时候学数据结构一样提不起劲。那么说说它们的实际作用和目的,为什么要了解它们:
URL和URI,理解这两者的区别,你会明白为何Retrofit会出现。而且在以后可能会用到的本地数据库也会经常用到。好像看上去相当重量级,是的,就是如此重要,很多思想就是这样一步一步得以发扬光大。
长连接和短连接,理解这两者的区别,主要是为了帮助理解Http。后面你会遇到推送,聊天等等需求,也会遇到。
HTTP和HTTPS,Retrofit是个网络库,不理解http是不行的,而且相关的知识也能够用来解答为什么选择okhttp。不光如此,一定要去看一次请求和返回的具体数据,看看都是些什么样子的数据。而https需要加密解密的知识,理解它会让你对协议的安全有一定了解,比如实实在在的项目需求,token如何设计,sharedpreference里数据的保护如何设计等等。
Restful,有了前面几个知识,要了解这个不难,Retrofit之所以如此普及,并非它有什么黑科技,最主要的原因在于规范,规范,规范。重要的事情说三遍。在网络交互中,规范的重要性不言而喻。
注解,设计模式,线程池,这几个方面的基本知识可以让你了解Retrofit是如何实现的,当然这三个方面是很大的知识块,循序渐进。
花了很多时间在这个上面,因为网上的教程基本不会提及这些内容学来有什么具体的实际作用。有目标才会有动力。
回到MarvelComic上来,
尝试着画一个流程图,但很难将其尽量画得简单好懂,当然这也归功于里面的确有些很绕的地方。个人觉得可以参考
 ,
,
遗憾的是它是从源码分析的角度来画的,而且博主,也没有尽量以设计者的角度来进行描述(这方面当然只能是去YouTube上找jack关于retrofit2的演讲视频),不过已经是相当详尽了。看完可以以自己的理解仔细读读源码,并且站在设计者的角度思考比如设计者如何将Retrofit和Okhttp两个框架进行结合的(个人觉得这其实是比较难的地方,哪个地方稍微设计得不好就会有很大的影响),以及它是如何支持Rxjava或其他方式的,因为CallAdapter可以很好的让我们理解为何会有retrofit的从1到2的变化。不建议初学者仔细看,但请求流程要了解。
看完这位博主的描述,需要得到一些基本认识,比如一次请求,从发起到请求前操作,进行请求,返回后操作,数据返回给开发者。了解了这些就可以理解helper包里面这些类的作用,以及他们会在何时被调用和其存在的意义。由于这两个框架写得非常规范,因此仔细理解源码中的命名肯定会有很大的帮助。
/**
* return {@link Retrofit} instance
*/
private static Retrofit createRetrofit(OkHttpClient client, Gson gson) {
return new Retrofit.Builder().baseUrl(EndPoint.endPoint())
.client(client)
.addCallAdapterFactory(RxErrorHandlingCallAdapterFactory.create())
.addConverterFactory(BaseConverterFactory.create(gson))
.build();
}
/**
* return {@link OkHttpClient} instance
*/
private static OkHttpClient createOkHttpClient(MarvelApplication app,
HashMap<String, String> tagsRef) {
HttpLoggingInterceptor interceptor =
new HttpLoggingInterceptor(new HttpLoggingInterceptor.Logger() {
@Override public void log(String message) {
if (BuildConfig.DEBUG) Timber.tag("OkHttp").d(message);
}
});
interceptor.setLevel(
BuildConfig.DEBUG ? HttpLoggingInterceptor.Level.BODY : HttpLoggingInterceptor.Level.NONE);
return new OkHttpClient.Builder().addInterceptor(interceptor)
.addNetworkInterceptor(new CacheInterceptor(app, tagsRef))
.cache(new Cache(new File(app.getCacheDir(), "HttpResponseCache"), MAX_DISK_CACHE_SIZE))
.retryOnConnectionFailure(true)
.readTimeout(20, TimeUnit.SECONDS)
.connectTimeout(20, TimeUnit.SECONDS)
.build();
}上面两个在Pool中,分别初始化获取Retrofit和OkHttpClient实例的代码,算是比较标准化的代码,可以想象成Retrofit将okhttp包裹进自身,由于两者都是builder方式,因此可以点进去看每个方法的作用。他们的作用总结下来,主要是用来统一处理请求当中的不同需求,这一点和以前一样,不然每个请求都添加头信息就惨了。OkHttpClient的初始化设置插入了好几个其他对象,主要用来解决:
1 请求日志(这是正常项目所必须且能在debug和release环境切换)
2 拦截器用于处理请求前和请求后的操作(比如Marvel的api强制要求要统一添加apikey,而如果返回与服务端约定好的错误code则需要自己在这个地方进行处理),关于intercept和networkIntercept的区别可以参看这里。
3 连接失败重试。
4 超时时间(正常15秒,此处由于Marvel网站请求很卡,所以改成20s),请注意服务端也有超时时间,客户端也有,如果两者不一致的处理就需要自己写逻辑了。
5 CacheOkHttp是严格按照web标准进行缓存处理的。由于图片框架用的Picasso,因此设置图片的缓存也在这里,都是通过okhttp的缓存策略进行处理的。
对于helper包里那几个具体的类,我就不讲他们的具体实现而着重于它们的用途以及理解。
首先,上面说过,retrofit这个框架重点在于对网络请求的规范和统一。它将一次请求分为了如下几个步骤:
1 请求前转换
helper中,实际上没有在请求前对请求数据进行特殊转换,何时需要统一处理呢?比如文件上传,或者以对象流的形式作为参数传递时,而这也需要设置适当的注解。
--- 拦截整体代码
@Override public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
HttpUrl original = request.url();
String tag = getETag(original);
Request.Builder requestBuilder = request.newBuilder();
if (!isActiveNetwork(application)) {
//dead network force cache
requestBuilder = requestBuilder.cacheControl(CacheControl.FORCE_CACHE).url(original);
}
request = requestBuilder.url(original.newBuilder()
.addQueryParameter(EndPoint.key(), EndPoint.publicKeyValue())
.addQueryParameter(EndPoint.hash(),
Utils.hash(EndPoint.publicKeyValue(), EndPoint.privateKeyValue()))
.addQueryParameter(EndPoint.timeStamp(), Utils.getUnixTimeStamp())
.build()).addHeader("If-None-Match", tag).addHeader("ETag", tag).build();
Response response = chain.proceed(request);
if (isActiveNetwork(application)) {
// read from cache for 1 minute
response = response.newBuilder()
.removeHeader("Pragma")
.header("Cache-Control", "public, max-age=" + MAX_AGE)
.build();
} else {
// tolerate 4-weeks stale
response.newBuilder()
.removeHeader("Pragma")
.header("Cache-Control", "public, only-if-cached, max-stale=" + MAX_STALE)
.build();
}
setETag(original, response.header("ETag"));
return response;
}--- end (以"Response response = chain.proceed(request);"这句代码为分界线分为拦截前,请求和拦截后)
2 请求前拦截
拦截这一块内容现在都转到了okhttp里面去设置拦截器,方法不变,网上有不少代码讲解这一块内容就不赘述。大概就是对url进行重新处理,无论是重造还是添加参数都可以,请求头添加键值对也可以,对于每次请求都会作一样的这样的处理。
Marvel由于服务端强行要求将apikey和时间戳的hash值放在url后面传递,导致了url每一次都会发生变化,而这将导致本地无法实现etag缓存。
因此这里简单作了处理,其生命周期为application的周期。所以规范很重要。
3 请求
Response response = chain.proceed(request);
仔细理解chain.proceed这两个单词,你会感叹这代码真的写得很舒服。
4 请求后拦截
如果debug你会发现,这里的执行已经是在另外的线程上面了,因此可以明显感受到等待服务器返回数据。
请求后没有进行特殊处理,只是简单根据网络判断要不要从缓存拉数据重新构建response,当然实际的操作是okhttp拿到我们返回的response,根据我们设置的头信息自行选择缓存策略。
5 请求后转换
接下来就是请求后转换,由于用的gson,因此需要自己定义gson对数据的转换过程。
要提的是错误处理,这里是套用的retrofit1源码里面的错误处理代码,对错误进行大致区分。
在实际项目当中,由于有的后端并不会坚持规范的返回格式,在存在自定义错误code时,其处理转换是重点。
需要注意的是,尽管okhttp是以builder模式构建不应当会存在设置参数的顺序问题,但由于其内是以List作为容器保存我们的拦截器,因此如果有多个拦截器的话,业务需要时应当注意顺序是否会出现逻辑错误。
关于eTag,它只是web缓存的很小的一块,这里有很详尽的web缓存的解释,这个在实际操作中是很重要的知识点。
数据库
移动端的数据库的使用是家常便饭,对于使用过SqlServer,mysql等等的人来说它的使用应该没有什么问题,注意一些细节就可以了。
一般情况下,用到数据库的地方多数是缓存,也就是对请求数据以某种方式进行缓存,而且一般也没有需要对数据库实现共享的需求,否则contentprovider就要出场了,对,它是四大组件之一,这里就是在实际项目中可能会用到这个组件的场景之一。要理解它的使用,网上有很多介绍,需要的基础知识就是restful,为什么?用一用就知道了。Marvel对于数据库的操作只是curd,需要了解的知识点有这样三个,注解,sqlbrite框架,页面缓存机制。
注解
对于注解这一块知识,其实比较暧昧,一般来说了解和熟悉其实都是可以的。但自从butterknife,dagger2之后,大家都开始关注起编译时注解了,因为它避免了运行时的开销,这对手机这样的环境来说是大利好。网上对这一块内容的介绍有很多,但多数都只是参照butterknife,没有实际的运用场景,的确这样的场景比较难找。这里之所以用到它最主要的原因是,数据库表的建立。
在使用gson之后,我们请求的数据都会被映射到一个对象中去,而这个对象需要我们自己创建,并且对它的字段成员进行命名,这是手动coding第一次,当需要建表的时候,我们需要根据gson映射的对象里的成员再一次手动写成对应的数据库表的列名组成sql语句。尤其是使用contentprovider时需要填充一个参数(什么参数忘了),就需要第三次手动写一遍。如果字段有很多的话,就是件很苦逼的差事了。
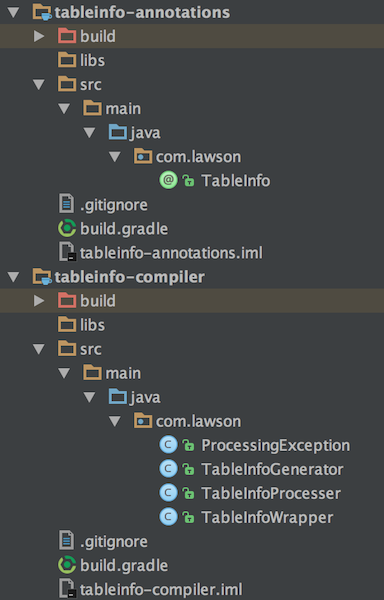
建立两个module的库,一个是注解,一个编译器,最后依赖到主module上。至于具体的创建方式,我强烈建议有兴趣的朋友看这个,这位大神挺强大,YouTube上也有他关于这一块的视频讲解。关于调试。
@TableInfo(ComicModel.class) public class ComicModel {
/**
* id : 42882
* digitalId : 26110
* title : Lorna the Jungle Girl (1954) #6
* modified : 2015-10-15T11:13:52-0400
* format : Comic
* pageCount : 32
* urls :
* [
* {"type":"detail","url":"http://marvel.com/comics/issue/42882/lorna_the_jungle_girl_1954_6?
* utm_campaign=apiRef&utm_source=37425d749b0301ff752ffcb8f996acc5"},
* {"type":"reader","url":"http://marvel.com/digitalcomics/view.htm?
* iid=26110&utm_campaign=apiRef&utm_source=37425d749b0301ff752ffcb8f996acc5"}]
* prices : [{"type":"printPrice","price":0}
* ]
* thumbnail : {"path":"http://i.annihil.us/u/prod/marvel/i/mg/9/40/50b4fc783d30f","extension":"jpg"}
* images : [{"path":"http://i.annihil.us/u/prod/marvel/i/mg/9/40/50b4fc783d30f","extension":"jpg"}]
*/
public int id;
public int digitalId;
public String title;
public String modified;
public String format;
public int pageCount;
public Thumbnail thumbnail;
public List<Link> urls;
public List<Images> images;
}这个过程很清晰,首先根据服务端返回的数据,创建成一个类并利用gson把json数据映射成一个对象,我把请求返回的数据模型写到了注释里面。创建好这个类后,在需要存入数据库的Class前面添加一个@TableInfo这个注解:
@Retention(RetentionPolicy.CLASS) @Target(ElementType.TYPE) public @interface TableInfo {
Class<?> value();
}该注解会获取到该类的一切信息并将这些信息在编译的时候,拿到我们自己写的编译器库进行编译,编译的结果如下:
public final class ComicModel_TABLE {
public static final String ID_COL = "ID";
public static final String DIGITALID_COL = "DIGITALID";
public static final String TITLE_COL = "TITLE";
public static final String MODIFIED_COL = "MODIFIED";
public static final String FORMAT_COL = "FORMAT";
public static final String PAGECOUNT_COL = "PAGECOUNT";
public static final String THUMBNAIL_COL = "THUMBNAIL";
public static final String URLS_COL = "URLS";
public static final String IMAGES_COL = "IMAGES";
public static final String TABLE_CREATE = "CREATE TABLE COMICMODEL_TABLE (_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,ID TEXT,DIGITALID TEXT,TITLE TEXT,MODIFIED TEXT,FORMAT TEXT,PAGECOUNT TEXT,THUMBNAIL TEXT,URLS TEXT,IMAGES TEXT,UNIQUE (_id) ON CONFLICT REPLACE)";
public static final String TABLE_NAME = "COMICMODEL_TABLE";
public static final String TABLE_DROP = "DROP TABLE IF EXISTS COMICMODEL_TABLE";
public static final String TABLE_BASE_QUERY = "SELECT * FROM COMICMODEL_TABLE";
public static final String TABLE_DELETE = "DELETE FROM COMICMODEL_TABLE";
}上面就是我们编译出来的,包含表名,列名,增删改查等等信息的字符串,拿到它们,在sqliteHelper中就可以这样写了:
public final class DatabaseHelper extends SQLiteOpenHelper {
public static final String DATABASE_NAME = "marvel.db";
/**
* warning : every release should check version, if <bold>database<bold/> has change, version
* code should change
*/
public static final int DATABASE_VERSION = 3;
public DatabaseHelper(Context context) {
super(context, DATABASE_NAME, null, DATABASE_VERSION);
}
@Override public void onCreate(SQLiteDatabase db) {
db.execSQL(ComicModel_TABLE.TABLE_CREATE);
db.execSQL(CharacterModel_TABLE.TABLE_CREATE);
db.execSQL(ComicDetailModel_TABLE.TABLE_CREATE);
}
@Override public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
if (oldVersion != DATABASE_VERSION) {
db.execSQL(ComicModel_TABLE.TABLE_DROP);
db.execSQL(CharacterModel_TABLE.TABLE_DROP);
db.execSQL(ComicDetailModel_TABLE.TABLE_DROP);
onCreate(db);
}
}
}当然这仅仅是简化了一个很小的步骤,其他该写的操作数据库的代码该写的还是要写:
/**
* Created by lawson on 16/7/25.
*
* dealer which deal with detail about something like crud operation between customer and provider
*/
public abstract class SqliteDealer<T> {
/**
* function of dealing with cursor
*/
public Func1<SqlBrite.Query, List<T>> MAP = new Func1<SqlBrite.Query, List<T>>() {
@Override public List<T> call(SqlBrite.Query query) {
Cursor cursor = query.run();
try {
List<T> values = null;
if (cursor != null) {
values = new ArrayList<>(cursor.getCount());
while (cursor.moveToNext()) {
values.add(fromCursor(cursor));
}
}
return values;
} finally {
if (cursor != null) {
cursor.close();
}
}
}
};
/**
* get data from cursor {@link Cursor}
*/
public abstract T fromCursor(Cursor cursor);
/**
* save data to {@link ContentValues}
*/
public abstract ContentValues toContentValues(T model);
}MAP负责从sqlbrite拿数据,如何拿需要自己实现fromCursor方法,toContentValues方法是保存获取的网络数据存到sqlbrite中去。关于sqlbrite,它是以rxjava封装了对数据库的许多操作相当于包了一层,我们不用直接与sqlite交互,对rxjava有兴趣的朋友可以读读其内部的源码,写得很有意思,特别是数据改动的监听(或者Trigger),有了它的存在,我们不用自己去监听数据发生的变化,而可以直接将rx流导入列表的adapter中去。
页面缓存机制
对于这点,其实是很简单的,但往往被很多人所忽略。

后面会说到view的数据填充时会发现,其实我们设计缓存的初衷除了断网时能看到数据,还有就是在数据获取到之前先展示缓存数据。为什么能做到这一点?因为加载本地数据比加载网络数据要快,正因为存在这个时间差,所以才会有页面缓存这样的东西的存在。否则存在网络比加载本地数据更快的情况,那么缓存这个流程该怎么走呢?可能有些许不同的地方,但通用的流程骨架是一样的:同时加载本地和加载网络,由于本地数据加载更快,因此页面很快就能看到数据展现,当网络数据回来时,先将这部分数据进行缓存,然后再走一遍加载本地数据的流程,这样网络,本地和页面上的数据就可以得到统一。
所以任何移动端的缓存,都要考虑考虑这个过程,才能很好的设计,否则会存在同步等难以解决的问题。
可能不少人对于RxJava并不熟悉,MarvelComic里基本是由rxjava贯穿,如果放在两年前,是有必要说一说的,但现在网上关于这一块内容实在不少,可看的也不少,而且比较关键的是,这一块东西着实并不容易靠讲解就能领会,所以多实践吧。
关于view部分,时间关系下次再说。最后需要说的是,篇幅较长,对初学者而言,可以多debug这个项目的流程,除了view部分其余的都是很通用的,很多在职开发者每天都做和考虑的事情;对老司机而言,我想更多的应该关注源码部分,的的确确有不少有趣的地方,比如动态代理的缓存,Call,okio等等,然后实实在在的利用这些知识去解决或优化自己项目中的一些代码,学以致用,比如命名规范,抽象,多人协同开发时模块的划分,代码的限制(比如继承一个空接口等等),或者上面说到的编译时注解的运用等等。
最后,源码地址。















 2986
2986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









