







前言
为了方便公司业务排查问题,要求打印执行的sql,以及执行时间。编写了一个Mybatis的拦截器,此前从未看过mybatis的源码,在调试的过程中不断阅读源码,后边想更深刻了解一下,看了鲁班大叔的视频,想做一下记录以及学习过程。
JDBC执行流程回顾
MyBatis是一个基于JDBC的数据库访问组件。首先回顾一下JDBC执行流程:
//1、导入jar包
//2、注册驱动
Class.forName("com.mysql.jdbc.Driver");
//3、获取连接
Connection connection = DriverManager.getConnection(JDBC.URL, JDBC.USERNAME, JDBC.PASSWORD);
//4、获取执行者对象
Statement stat = conn.createStatement();
//5、预编译SQL,并接收返回结果
PreparedStatement statement = connection.prepareStatement("select * from users ");
//6、执行查询
ResultSet resultSet = statement.executeQuery();
//7、处理结果
readResultSet(resultSet);
//8、释放资源,关闭连接等
现在这些操作Mybatis都帮我们完成了!
Mybatis执行流程
MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息。
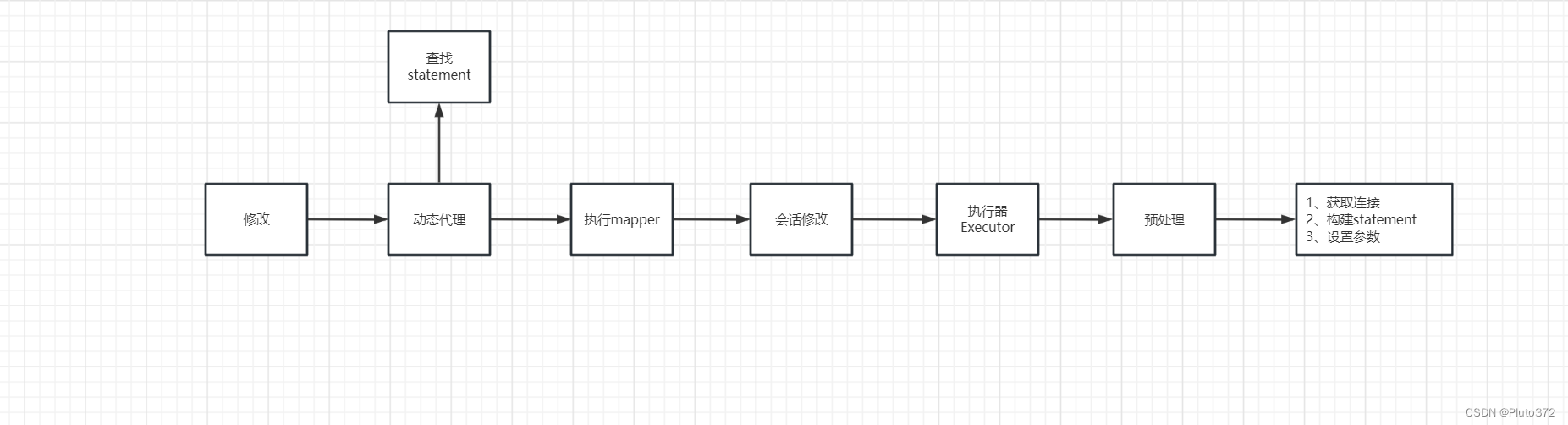
本文主要介绍MyBatis 的核心 Executor,后续会详细介绍Mybatis执行一个sql的流程。
Executor
Executor位于executor包,Mybatis中所有的SQL命令都由它来调度执行,他主要用于连接 SqlSession与JDBC,所有与JDBC相关的操作都要通过它。图中展示了Executor在核心对象中所处位置。
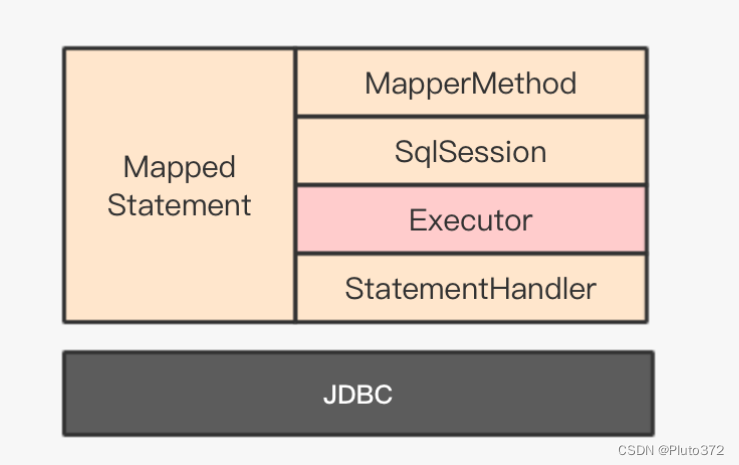
Executor定义了查询、更新、事务、缓存操作相关的接口方法,Executor接口对外暴露,由SqlSession依赖,并受其调度与管理。
Executor家族:
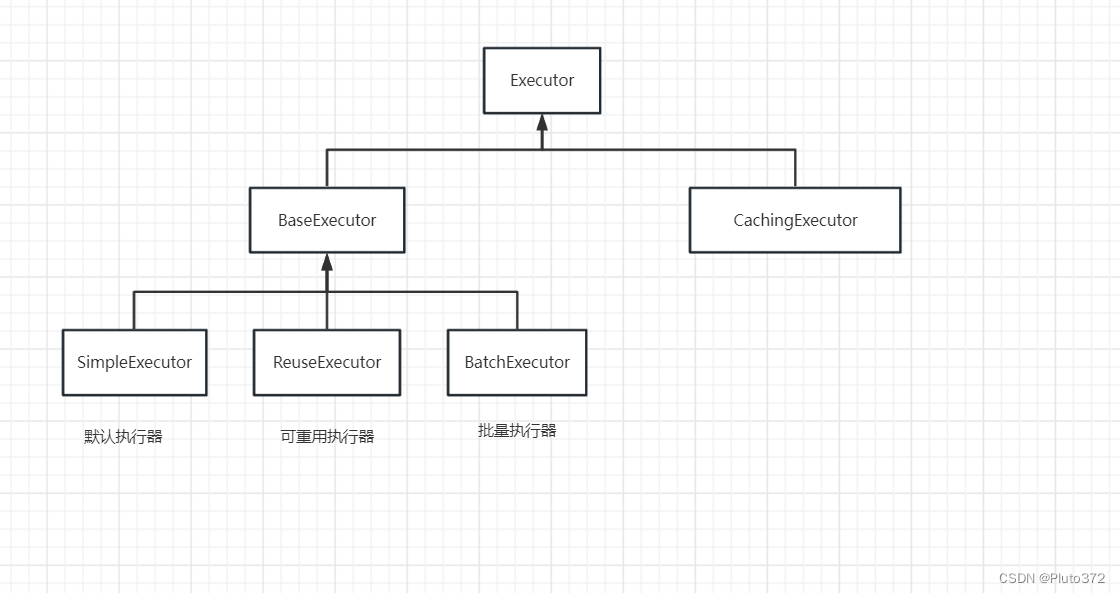
- BaseExecutor,它是一个抽象类,实现了大部分Executor的接口。它有三个子类,分别是SimpleExecutor、ReuseExecutor、BatchExecutor。BaseExecutor及其子类完成了一级缓存管理和与数据库交互有关的操作。
- CachingExecutor,缓存执行器,Mybatis二级缓存的核心处理类。CachingExecutor持有一个BaseExecutor的实现类(SimpleExecutor、ReuseExecutor或BatchExecutor)实例作为委托执行器。它主要完成Mybatis二级缓存处理逻辑,当缓存查询中不存在或查询不到结果时,会通过委托执行器查询数据库。
- 第三层是BaseExecutor的三个子类。简单执行器为默认执行器,具备执行器的所有能力;可重用执行器,是相对简单执行器而言的,它具备MappedStatement的缓存与复用能力,即在一个SqlSession会话内重复执行同一个命令,可以直接复用已缓存的MappedStatement;批量执行器,即一次可以执行多个命令。
Executor的核心功能是调度执行SQL,参与了全过程;为了提高查询性能,Mybatis在Executor中设计了一级缓存和二级缓存,一级缓存由BaseExecutor及其子类实现,二级缓存由CachingExecutor实现。一级缓存是默认开启的,二级缓存需要启用配置。由于CachingExecutor负责缓存管理,真正的数据库查询是由BaseExecutor完成的,所以对外来看,Executor有三种类型SIMPLE、REUSE、BATCH,默认是SIMPLE,我们可以在配置文件或创建SqlSession时指定参数修改默认执行器类型。以下为Mybatis中ExecutorType定义:
public enum ExecutorType {
// 简单执行器
SIMPLE,
// 可重用的执行器
REUSE,
// 批处理执行器
BATCH
}
执行过程
以查询为例,默认情况下会使用CachingExecutor,首先判断是否开启二级缓存,
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取缓存对象,启用二级缓存才会有
Cache cache = ms.getCache();
// 缓存不空
if (cache != null) {
// 刷新缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 从缓存中查询
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 缓存中没有,通过委托查询
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//默认情况没有开启二级缓存,会直接走到这里
//delegate即BaseExecutor三个子类的其中一个
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
进入CachingExecutor#query,首先通过MappedStatement获取BoundSql,创建缓存key,然后调用了重载的query方法。重载query查询在不考虑缓存的情况下,会直接通过委托执行器的query方法进行查询。
这里的委托执行器为BaseExecutor的子类,而BaseExecutor实现了query方法,所以我们先进入BaseExecutor#query()(同样先忽略一级缓存部分的逻辑):
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//从一级缓存(本地缓存)中查询
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//缓存中不存在,从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
//缓存占位
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//调用抽象方法执行数据库查询,子类实现
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//移除占位
localCache.removeObject(key);
}
//设置缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
在源码中看到do开头的方法一定要注意,这是真正做事的方法。
SimpleExecutor#doQuery
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
//获取配置对象
Configuration configuration = ms.getConfiguration();
//创建StatementHandler
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//准备Statement
stmt = prepareStatement(handler, ms.getStatementLog());
//执行查询
return handler.query(stmt, resultHandler);
} finally {
//关闭Statement
closeStatement(stmt);
}
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
- 从MappedStatement对象获取全局Configuration配置对象;
- 调用Configuration#newStatementHandler创建StatementHandler对象;
- 创建并初始化Statement对象;
- 调用StatementHandler#query执行Statement,并使用resultHandler解析返回值;
- 最后关闭Statement。
ReuseExecutor#doQuery
//Statement缓存
private final Map<String, Statement> statementMap = new HashMap<>();
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
Statement stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
//检查缓存中是否存在当前sql
if (hasStatementFor(sql)) {
//如果有,就直接拿出来用
stmt = getStatement(sql);
applyTransactionTimeout(stmt);
} else {
//如果没有,就新建一个
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
//然后,缓存起来。
putStatement(sql, stmt);
}
handler.parameterize(stmt);
return stmt;
}
ReuseExecutor#doQuery与SimpleExecutor#doQuery的逻辑基本一致,不同点在于prepareStatement方法的实现逻辑。prepareStatement使用statementMap对执行过的sql进行缓存,只有statementMap中不存在当前sql的时候才会执行创建流程,对性能有一定的提升。需要注意的是,Executor对象是SqlSession的组成部分,所以这个缓存与SqlSession的生命周期一致。
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException {
Statement stmt = null;
try {
//批量执行,目前我理解是为了把之前批量更新的语句执行掉
flushStatements();
//获取Configuration对象
Configuration configuration = ms.getConfiguration();
//创建StatementHandler
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameterObject, rowBounds, resultHandler, boundSql);
//创建Statement
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
//设置Statement参数
handler.parameterize(stmt);
//执行并返回结果
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
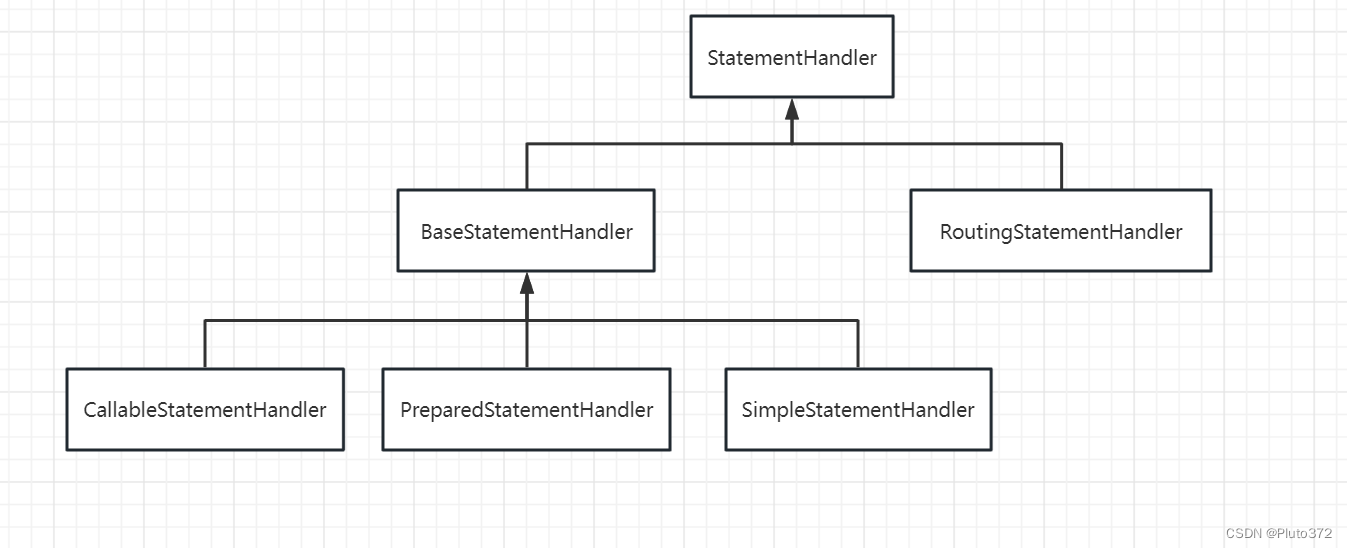
StatementHandler
用于获取预处理器,共有三种类型。通过statementType=“STATEMENT|PREPARED|CALLABLE” 可分别进行指定。
PreparedStatementHandler:带预处理的执行器
CallableStatementHandler:存储过程执行器
SimpleStatementHandler:基于Sql执行器
ResultSetHandler
用于处理和封装返回结果。可在SqlSession中查询时自行定义ResultSetHandler
执行时序
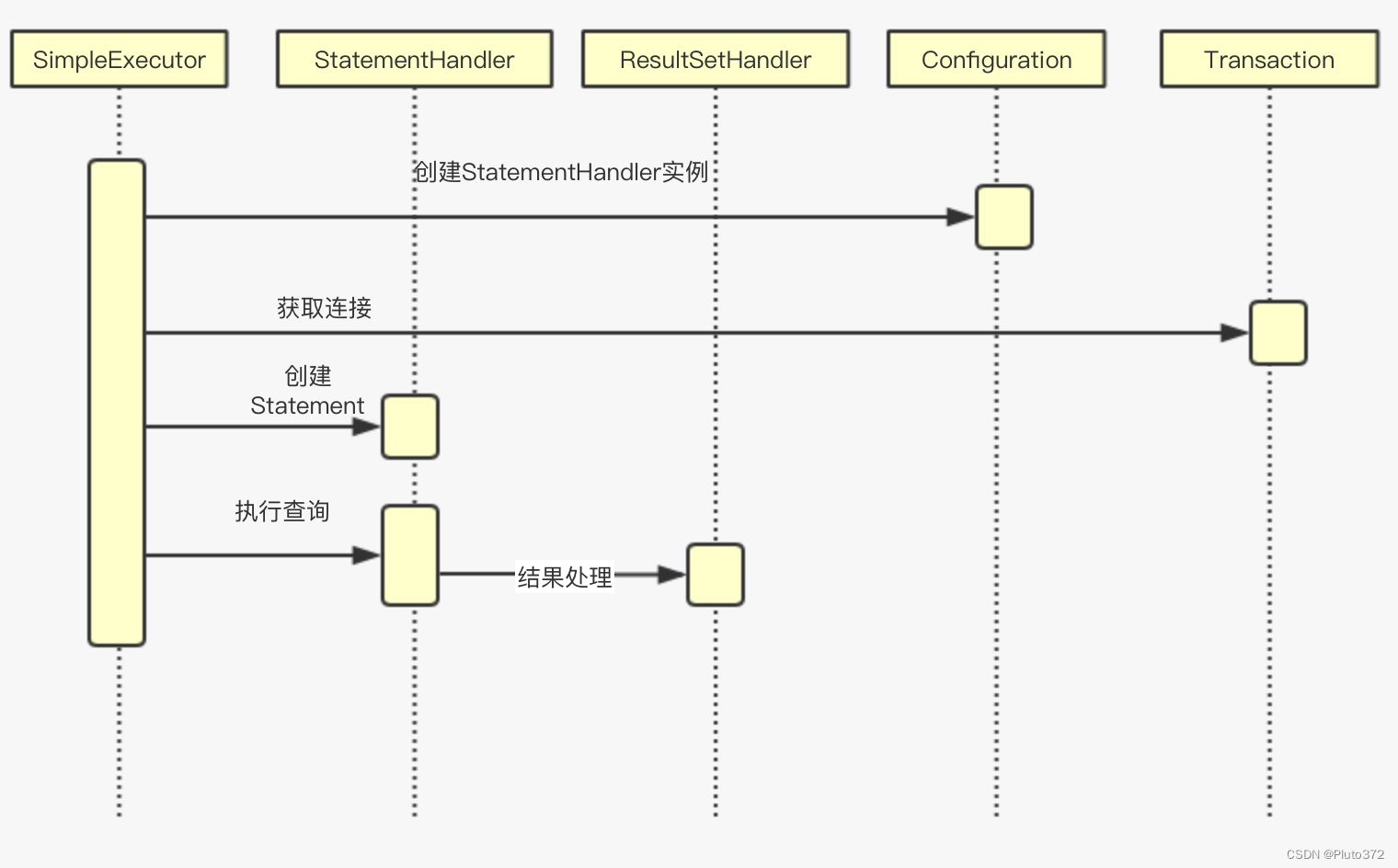
- 通过Configuration获取StatementHandler实例(由statementType 决定)。
- 通过事务获取连接
- 创建JDBC Statement对像
- 执行 JDBC Statement execute
- 处理返回结果















 2027
2027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









