






在这篇文章中,我们将开发一个应用程序来检测垃圾邮件。将使用的算法是从SPARK MLib实现的逻辑回归。对这个领域不需要深入的了解,因为这些主题是从高层次的角度来描述的。完整的工作代码将与一个正在运行的应用程序一起提供,以供您选择电子邮件的进一步实验。
Logistic回归
逻辑回归是一种用于分类问题的算法。在分类问题中,我们给了很多标签化的数据(垃圾邮件,非垃圾邮件),当一个新的例子来临时,我们想知道它属于哪个类别。由于它是一种机器学习算法,Logistic回归用标记数据进行训练,并基于训练给出了关于新的例子的预测。
应用程序
一般来说,当大量数据可用时,我们需要检测一个例子属于哪个类别,可以使用逻辑回归(即使结果并不总是令人满意)。
医疗保健
例如,当分析数百万患者的健康状况以预测患者是否有心肌梗塞时,可以使用逻辑回归。同样的逻辑可以用来预测患者是否会患上特定的癌症,是否会受到抑郁症等的影响。在这个应用程序中,我们有相当数量的数据,所以逻辑回归通常会给出很好的提示。
图像分类
基于图像密度的颜色,我们可以分类,比如说,图像是否包含人或包含汽车。此外,由于这是一个分类问题,我们也可能使用逻辑回归来检测图片是否有字符,甚至是检测手写。
消息和电子邮件垃圾分类
逻辑回归最常见的应用之一是分类垃圾邮件。在这个应用程序中,算法确定传入的电子邮件或消息是否是垃圾邮件。当建立一个非个性化的算法时,需要大量的数据。个性化过滤器通常表现更好,因为垃圾邮件分类器在某种程度上取决于个人的兴趣和背景。
它是怎么运行的
我们有很多标记的例子,并且想要训练我们的算法足够聪明,可以说出新的例子是否属于其中一个类别。为了简化,我们将首先参考二进制分类(1或0)。算法也容易扩展到多分类。
深入了解(Insight)
通常情况下,我们有多维数据或具有许多特征的数据。这些功能中的每一个都以某种方式有助于最终决定新范例属于哪个范畴。例如,在癌症分类问题中,我们可以具有年龄、吸烟与否、体重、身高、家族基因组等特征。这些功能中的每一个都有助于最终的类别决定。特征并不等于决定权,而是在确定最终状态时有不同的影响。例如,在癌症预测中,体重比家族基因组的影响更小。在逻辑回归中,这正是我们试图找出的结果:数据特征的权重/影响。一旦我们有了大量的数据例子,我们就可以确定每个特征的权重,当新的例子出现时,我们使用权重来看看这个例子是如何分类的。在癌症预测的例子中,我们可以这样写:
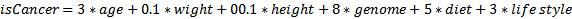
更正式地说:
n =例子的数量
k =特征的数量
θj=特征j的权重
Xji =具有特征j的第i个例子X
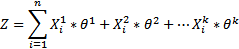
模型表达
为了将数据分类,我们需要一个函数(假设),根据示例、值和特征,可以将数据放入两个类别之一。我们使用的函数被称为Sigmoid函数,如下图所示:
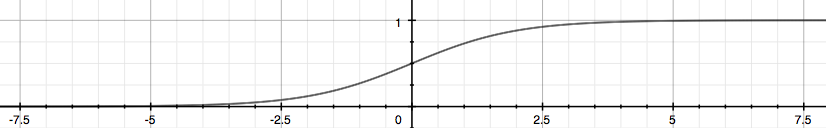
正如我们所看到的那样,当X轴上的值是正值时,Sigmoid函数值往往趋于1;当X轴上的值为负值时,趋向于0。基本上,我们有一个模型来表示两个类别和数学,功能如下所示:
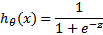
Z是在“Insight”下解释的功能。
要获得离散值(1或0),可以说当一个函数值(Y轴)大于0.5时,我们将其归类为1;当函数值(Y轴)小于0.5时,我们将其归类为0。如下所述:
- Y> 0.5 = 1(垃圾邮件/癌症)
- Y< 0.5 = 0(不是垃圾邮件/不是癌症)
- Z> 0 = 1(垃圾邮件/癌症)
- Z< 0 = 0(不是垃圾邮件/不是癌症)
成本函数(Cost Function)
我们不希望仅仅找到任何权重,而是要求实际数据的最佳权重。为了找到最好的权重,我们需要另一个函数来计算我们找到的特定权重的解决方案。有了这个功能,我们可以比较不同解决方案与不同的权重,找到最好的一个。这个功能被称为成本函数(Cost Function)。它将假设(Sigmoid)函数值与实际数据值进行比较。由于我们用于培训的数据被标记(垃圾邮件,非垃圾邮件),我们将假设(Sigmoid)预测与实际值进行比较,我们知道这是肯定的。我们希望假设和实际价值之间的差距越小越好, 理想情况下,我们希望成本函数为零。更正式地说,成本函数被定义为:
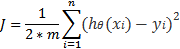
其中yi是真正的价值/类别,如垃圾邮件/不是垃圾邮件或1/0,h(x)是假设。
基本上,这个公式计算我们的预测与实际标记数据(y)的比较(平均)有多好。因为我们有两个情况(1和0),所以我们有两个Hs(假设):h1和h0。我们将log用于假设,使得函数是凸的,找到全局最小值更安全。
我们来看看h1,这是与类别1的成本函数有关的假设。
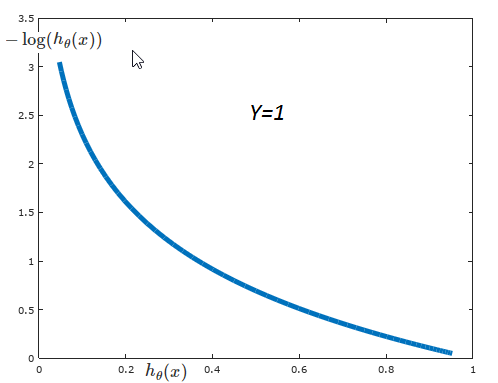
我们将log用于我们的假设,而不是直接使用它,因为我们希望实现一种关系,当假设接近1时,成本函数为零。请记住,我们希望我们的成本函数为零,以便在假设预测和标记数据之间没有差异。如果假设要预测0,我们的成本函数增长很大,所以我们知道这不属于第一类;如果假设要预测1,则成本函数变为0,表明该例子属于类别1。
我们来看看h2,这是关于类别0的成本函数的假设。
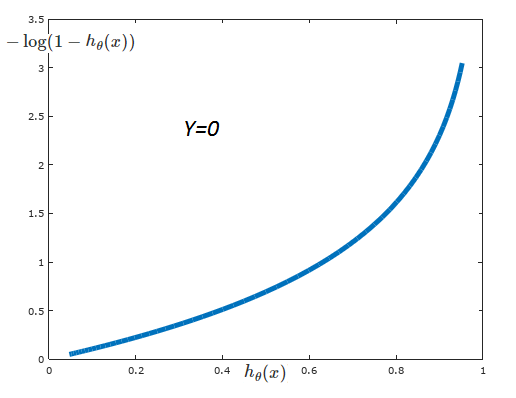
在这种情况下,我们再次应用log,但是当假设还要预测零时,使成本函数变为零。如果假设要预测1,我们的成本函数就会变大,所以我们知道这不属于0类;如果假设要预测0,则成本函数变为0,表示该例子属于0类。
现在,我们有两个成本函数,我们需要把它们合并成一个。在这之后,等式变得有些杂乱,但原则上,这只是我们上面解释的两个成本函数的合并:
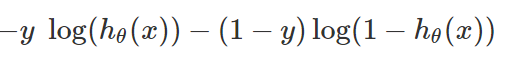
注意,第一项是h1的成本函数,第二项是h0的成本函数。所以,如果y = 1,那么第二项被消除,如果y = 0,则第一项被消除。
最小化成本函数
正如我们上面看到的,我们希望我们的成本函数为零,以便我们的预测尽可能接近真实值(标记)。幸运的是,已经有一个算法来最小化成本函数:梯度下降(gradient descent)。一旦我们有成本函数(基本上将我们的假设与真实值相比较),我们可以把我们的权重(θ)同样尽可能降低成本函数。首先,我们选择θ的随机值只是为了获得一些值。然后,我们计算成本函数。根据结果,我们可以减少或增加我们的θ值,使成本函数优化为零。我们重复这一点,直到成本函数几乎为零(0.0001),或从迭代到迭代没有太大改善。
梯度下降原则上是这样做的;它只是成本函数的一个导数,以决定是减小还是增加θ值。它还使用系数α来定义改变θ值的数量。改变θ值太大(大α)会使梯度下降在优化成本函数为零时失败,因为大的增加可能会克服实际值或远离期望值。虽然θ(小α)的小变化意味着我们是安全的,但是算法需要大量的时间才能达到成本函数的最小值(几乎为零),因为我们正朝着想要的或实际值进展太慢(为更多的可视化解释,请看这里)。更正式的,我们有:
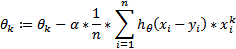
右边的项是成本函数的导数(仅针对特征k改变X的倍数)。由于我们的数据是多维的(k个特征),我们对每个特征权重(θk)都做了这个。
算法执行
让我们看看准备数据、转换数据、执行和结果。
准备数据
在执行数据之前,我们需要做一些数据预处理来清理不需要的信息。数据后处理的主要思想是从这个Coursera作业。我们做以下工作:
- Lower-casing:整个电子邮件被转换成小写字母,忽略大小写(即IndIcaTE被视为与指示相同)。
- 剥离HTML:从电子邮件中删除所有的HTML标签。许多电子邮件通常带有HTML格式。我们删除所有的HTML标签,只保留内容。
- 规范化网址:所有网址均替换为文字“XURLX”。
- 正常化电子邮件地址:所有电子邮件地址都被替换为文本“XEMAILX”。
- 正常化数字:所有数字都被替换为文本“XNUMBERX”。
- 正常化美元:所有美元符号($)被替换为文本“XMONEYX”。
- 词干分析:词汇被归结为词干形式。例如,“discount”、“discounts”、“discounted”和“discounting”全部替换为“discount”。有时候,Stemmer实际上从最后剥去附加字符,因此“include”、“includes”、“included”和“including”全部替换为“includ”。
- 删除非单词:删除非单词和标点符号。所有的空格(即制表符、换行符、空格)都被修剪为一个空格字符。
代码实现将如下所示:
private List<string> filesToWords(String fileName) throws Exception {
URI uri = this.getClass().getResource("/" + fileName).toURI();
Path start = getPath(uri);
List< String > collect = Files.walk(start).parallel()
.filter(Files::isRegularFile)
.flatMap(file -> {
try {
return Stream.of(new String(Files.readAllBytes(file)).toLowerCase());
} catch (IOException e) {
e.printStackTrace();
}
return null;
}).collect(Collectors.toList());
return collect.stream().parallel().flatMap(e -> tokenizeIntoWords(prepareEmail(e)).stream()).collect(Collectors.toList());
}
</string>private String prepareEmail(String email) {
int beginIndex = email.indexOf("\n\n");
String withoutHeader = email;
if (beginIndex > 0) {
withoutHeader = email.substring(beginIndex, email.length());
}
String tagsRemoved = withoutHeader.replaceAll("< [^< >]+>", "");
String numberedReplaced = tagsRemoved.replaceAll("[0-9]+", "XNUMBERX ");
String urlReplaced = numberedReplaced.replaceAll("(http|https)://[^\\s]*", "XURLX ");
String emailReplaced = urlReplaced.replaceAll("[^\\s]+@[^\\s]+", "XEMAILX ");
String dollarReplaced = emailReplaced.replaceAll("[$]+", "XMONEYX ");
return dollarReplaced;
} private List< String > tokenizeIntoWords(String dollarReplaced) {
String delim = "[' @$/#.-:&*+=[]?!(){},''\\\">_<;%'\t\n\r\f";
StringTokenizer stringTokenizer = new StringTokenizer(dollarReplaced, delim);
List< String > wordsList = new ArrayList<>();
while (stringTokenizer.hasMoreElements()) {
String word = (String) stringTokenizer.nextElement();
String nonAlphaNumericRemoved = word.replaceAll("[^a-zA-Z0-9]", "");
PorterStemmer stemmer = new PorterStemmer();
stemmer.setCurrent(nonAlphaNumericRemoved);
stemmer.stem();
String stemmed = stemmer.getCurrent();
wordsList.add(stemmed);
}
return wordsList;
}
转换数据
private List< String > tokenizeIntoWords(String dollarReplaced) {
String delim = "[' @$/#.-:&*+=[]?!(){},''\\\">_<;%'\t\n\r\f";
StringTokenizer stringTokenizer = new StringTokenizer(dollarReplaced, delim);
List< String > wordsList = new ArrayList<>();
while (stringTokenizer.hasMoreElements()) {
String word = (String) stringTokenizer.nextElement();
String nonAlphaNumericRemoved = word.replaceAll("[^a-zA-Z0-9]", "");
PorterStemmer stemmer = new PorterStemmer();
stemmer.setCurrent(nonAlphaNumericRemoved);
stemmer.stem();
String stemmed = stemmer.getCurrent();
wordsList.add(stemmed);
}
return wordsList;
}一旦电子邮件准备好了,我们需要将数据转换成算法理解的结构,如矩阵和特征。
第一步是建立一个“垃圾邮件词汇(spam vocabulary)”,通过阅读所有的垃圾邮件的词汇和计数。例如,我们计算了使用“transaction”、“XMONEYX”、“finance”、“win”和“free”的次数,然后拿出10个(featureSize)最常见的单词,此时我们有地图的大小为10(featureSize),其中的关键是单词,值是从0到9.999的索引。这将作为可能的垃圾邮件词的参考。请参阅下面的代码:
public Map< String, Integer > createVocabulary() throws Exception {
String first = "allInOneSpamBase/spam";
String second = "allInOneSpamBase/spam_2";
List< String > collect1 = filesToWords(first);
List< String > collect2 = filesToWords(second);
ArrayList< String > all = new ArrayList<>(collect1);
all.addAll(collect2);
HashMap< String, Integer > countWords = countWords(all);
List< Map.Entry< String, Integer >> sortedVocabulary = countWords.entrySet().stream().parallel().sorted((o1, o2) -> o2.getValue().compareTo(o1.getValue())).collect(Collectors.toList());
final int[] index = {0};
return sortedVocabulary.stream().limit(featureSIze).collect(Collectors.toMap(e -> e.getKey(), e -> index[0]++));
}HashMap< String, Integer > countWords(List<string> all) {
HashMap< String, Integer > countWords = new HashMap<>();
for (String s : all) {
if (countWords.get(s) == null) {
countWords.put(s, 1);
} else {
countWords.put(s, countWords.get(s) + 1);
}
}
return countWords;
}
</string>下一步是统计这些词在我们的垃圾邮件和非垃圾邮件中的词频。然后,我们查看垃圾邮件词汇表中的每个单词,看它是否在那里。如果是(表示电子邮件有可能是垃圾邮件词),我们把这个词放在垃圾邮件词汇表中包含的同一个索引中,并且把这个词放在频率上。最后,我们建立一个矩阵Nx10.000,其中N是所考虑的电子邮件的数量,10.000是包含电子邮件中的垃圾邮件词汇映射词的频率的向量(如果在电子邮件中没有发现垃圾邮件词,我们设为0)。
例如,假设我们有如下的垃圾邮件词汇表:
- aa
- how
- bil
- anyon
- know
- zero
- zip
还有一个像下面这样的电子邮件:
anyon know how much it cost to host a web portal well it depend on how mani visitor your expect thi can be anywher from less than number buck a month to a coupl of dollarnumb you should checkout XURLX or perhap amazon ecnumb if your run someth big to unsubscrib yourself from thi mail list send an email to XEMAILX
转型后,我们将有:
0 2 0 1 1 1 0 0所以我们有0 aa、2 how、0 abil、1 anyon、1 know、0 zero、0 zip。这是一个1X7的矩阵,因为我们有一个电子邮件和7个字的垃圾邮件词汇。代码如下所示:
private Vector transformToFeatureVector(Email email, Map< String, Integer > vocabulary) {
List< String > words = email.getWords();
HashMap< String, Integer > countWords = prepareData.countWords(words);
double[] features = new double[featureSIze];//featureSIze==10.000
for (Map.Entry< String, Integer > word : countWords.entrySet()) {
Integer index = vocabulary.get(word.getKey());//see if it is in //spam vocabulary
if (index != null) {
//put frequency the same index as the vocabulary
features[index] = word.getValue();
}
}
return Vectors.dense(features);
}
执行和结果
private Vector transformToFeatureVector(Email email, Map< String, Integer > vocabulary) {
List< String > words = email.getWords();
HashMap< String, Integer > countWords = prepareData.countWords(words);
double[] features = new double[featureSIze];//featureSIze==10.000
for (Map.Entry< String, Integer > word : countWords.entrySet()) {
Integer index = vocabulary.get(word.getKey());//see if it is in //spam vocabulary
if (index != null) {
//put frequency the same index as the vocabulary
features[index] = word.getValue();
}
}
return Vectors.dense(features);
}尽管Java必须安装在您的计算机上,但应用程序可以在没有任何Java知识的情况下下载和执行。随意用自己的电子邮件测试算法。
我们可以通过执行RUN类来从源代码运行应用程序。或者,如果您不想用IDE打开它,只需运行mvn clean install exec:java。
之后,你应该看到这样的情况:

首先,通过点击使用Train with LR SGD或使用Train with LR LBFGS训练算法。这可能需要一到两分钟的时间。完成后,弹出窗口将显示所达到的精度。不要担心SGD与LBFGS的区别——它们只是使成本函数最小化的不同方法,并且会得到几乎相同的结果。之后,将您选择的电子邮件复制并粘贴到白色区域,然后按“Test”。之后,弹出窗口将显示算法的预测。
在执行过程中达到的精确度大约为97%,使用随机80%的训练数据和20%的测试数据。没有交叉验证测试——在这个例子中只使用了训练和测试(对于准确性)集合。要了解有关划分数据的更多信息,请参阅此处。
训练算法的代码相当简单:
public MulticlassMetrics execute() throws Exception {
vocabulary = prepareData.createVocabulary();
List< LabeledPoint > labeledPoints = convertToLabelPoints();
sparkContext = createSparkContext();
JavaRDD< LabeledPoint > labeledPointJavaRDD = sparkContext.parallelize(labeledPoints);
JavaRDD< LabeledPoint >[] splits = labeledPointJavaRDD.randomSplit(new double[]{0.8, 0.2}, 11L);
JavaRDD< LabeledPoint > training = splits[0].cache();
JavaRDD< LabeledPoint > test = splits[1];
linearModel = model.run(training.rdd());//training with 80% data
//testing with 20% data
JavaRDD< Tuple2< Object, Object >> predictionAndLabels = test.map(
(Function< LabeledPoint, Tuple2< Object, Object >>) p -> {
Double prediction = linearModel.predict(p.features());
return new Tuple2<>(prediction, p.label());
}
);
return new MulticlassMetrics(predictionAndLabels.rdd());
}就是这样!















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









