







 本文分享如何利用机器学习进行销售预测,以优化供应链中的库存管理。通过数据预处理、时间序列分析、机器学习模型(如Xgboost)构建,以降低资源浪费。实践中发现模型预测偏差较大,提出了改进措施,包括模型融合、超参数调优和特征工程优化。
本文分享如何利用机器学习进行销售预测,以优化供应链中的库存管理。通过数据预处理、时间序列分析、机器学习模型(如Xgboost)构建,以降低资源浪费。实践中发现模型预测偏差较大,提出了改进措施,包括模型融合、超参数调优和特征工程优化。
本次是用机器学习做出未来一定时期内的销售量预测,从而辅助指导销售库存计划的决策分析,以达到合理配置库存,减少资源成本浪费的目的。实操内容有点多,虽然我已经尽量删减了。有兴趣的朋友可以关注+收藏,后面慢慢看哟。如果觉得内容还行,请多多鼓励;如果有啥想法,评论留言or私信。那么我们开始说正事了~
一、数据准备阶段
数据集描述
用于技术验证的数据集来自kaggle上的医药销售预测项目Rossmann Stores Clustering and Forecast,整个数据集包含三张表:训练集、测试集、经销商信息表。测试集只比训练集少销售额Sales和Customers这两个字段,其它字段完全相同,其中训练集和测试集分别有1017209和41088条,训练集和测试集前五条数据如下。
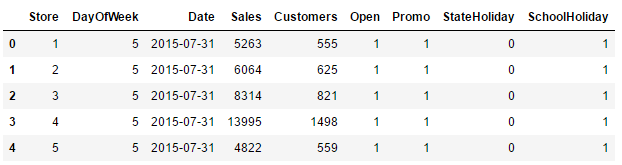
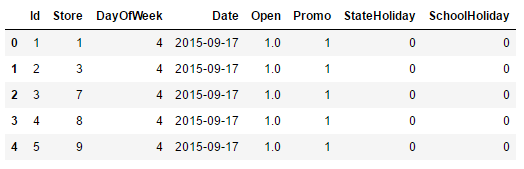
测试集包含未来六周的促销等状况,要求预测指定经销商的销售额或则顾客总数。
经销商信息数据集store.csv有1115条数据,也就是1115家经销商,10个字段。

其中Store字段唯一代表一家经销商,可以将train.csv和test.csv分别与store.csv通过字段Store关联起来。
数据预处理
1. 首先从日期字段Date中提取出年月日以及该日期在所在年的第几周,并将它们作为新的字段,方便之后对数据按时间进行聚合处理。
2. 对三张表中的分类变量进行编码转换,采用sklearn内置的LabelEncoder编码。
3. 查看每张表的字段缺失情况,train.csv,test.csv,store.csv缺失如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 169
169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









