







1-1.批量梯度下降(Batch gradient descent) - 训练集较小
对整个训练集执行梯度下降法,然后才能进行一步梯度下降法。即一次遍历训练集只做一个梯度下降。
优点:
对于凸目标函数,可以保证全局最优; 对于非凸目标函数,可以保证一个局部最优。
缺点:
速度慢;数据量大时不可行;计算机内存问题
1-2.随机梯度下降(SGD) -训练集较大
仅计算某个样本的梯度,即针对某一个训练样本及其更新参数
优点:
更新频次快,优化速度更快; 一定的随机性导致有几率跳出局部最优(随机性来自于用一个样本的梯度去代替整体样本的梯度)
缺点:
随机性可能导致收敛复杂化,即使到达最优点仍然会进行过度优化,因此SGD得优化过程相比BGD充满动荡
1-3.Mini-batch 梯度下降(Mini-batch gradient descent)
一个训练集分为多个batch,每次训练传入一个batch,每个batch进行一次梯度下降。 是训练神经网络最常用的优化方法。
优点:
参数更新时的动荡变小,收敛过程更稳定,降低收敛难度。
带有噪声的梯度估计, 哪怕我们位于梯度为0的点,也经常在某个mini-batch下的估计把它估计偏了,导致往前或者往后挪了一步摔下马鞍,也就是mini-batch的梯度下降法使得模型很容易逃离特征空间中的鞍点
总结:
理论上只有严格的凸函数才可以通过梯度下降获得全局最优解。 但是,神经网络所面临的基本上都是严重非凸的目标函数,这也意味着优化容易陷入局部最优。 事实上,我们的困难往往来自 “鞍点” 而非局部极小点, 鞍点周围通常拥有相同的损失函数值,这导致SGD很难发挥作用,因为每个方向的梯度都接近于0.
2-1.动量梯度下降法(Gradient descent with Momentum)
动量的引入是为了加速SGD的优化过程
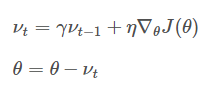
分析上式就会明白动量的作用原理:利用惯性,即当前梯度与上次梯度进行加权,如果方向一致,则累加导致更新步长变大;如果方向不同,则相互抵消中和导致更新趋向平衡。
动量 γ 常被设定为0.9或者一个相近的值。
2-2.Adam 优化算法(Adam optimization algorithm)
Adam算法结合了Momentum和RMSprop梯度下降法。















 9716
9716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









