







论文名称:Summarizing Legal Regulatory Documents using Transformers
论文下载地址:https://dl.acm.org/doi/10.1145/3477495.3531872
数据集EUR-LexSum下载地址:svea-klaus/Legal-Document-Summarization
本文是2022年SIGIR论文,关注使用transformers模型来做法律规范文件 (legal regulatory documents) 的抽取式摘要。
这篇文章提出了一个英文法律规范文件摘要数据集。模型就是很简单地把抽取式摘要建模成每一句的二分类任务,还测试了在此之前用TextRank先抽取一遍的效果。(这个指标甚至没有做人工的)
看起来非常简单,这样就能发SIGIR吗,那我怎么不行……
所以可能本文的贡献重点在数据集上吧!
文章目录
1. Background & Motivation
法律文本的重要问题在于外行看不懂,本文关注提取文中的重点(即实现文本摘要任务)。
现有的文本摘要工作关注于短文本和生成式摘要。
本文提出基于transformers的模型,实现抽取式摘要,效果超过了TextRank。超过TextRank是什么值得写出来的事情吗?结合TextRank以预先过滤候选句子,然后再使用基于transformer的模型,效果可能会更好。(先抽取,然后再抽取?)
2. EUR-LexSum数据集

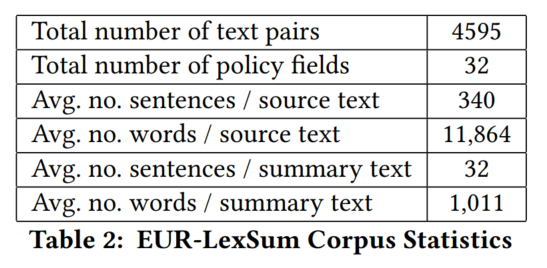
3. 基于transformer的抽取式摘要模型
本文基于类似Bert的结构,生成句子表征,对每个句子用二元分类的范式,决定最终选出哪些句子。
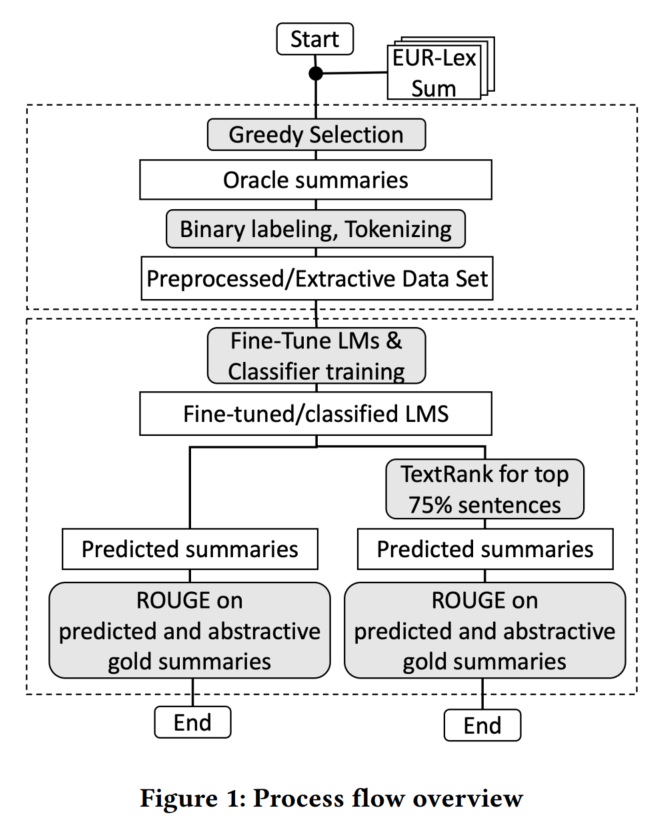
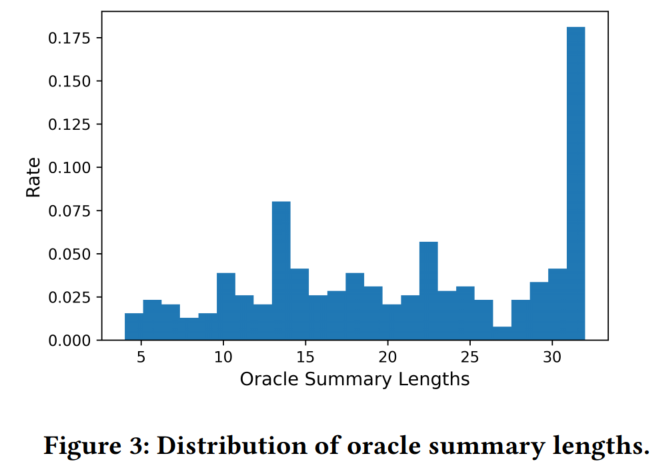
(本文提及了一下,具体的通过生成式摘要结果来抽取oracle抽取式摘要标签的方法也是值得探索的。我也觉得!!!!!)
3.1 数据爬取和清洗
数据来源:https://eur-lex.europa.eu/browse/summaries.html
具体细节略。
3.2 微调基于transformer的模型
贪心搜索选择32句(生成式摘要的平均长度)。
最小化选出句子之间的相似性:trigram blocking1
4. 实验
对数据集的介绍见本文第二节。
4.1 baseline
TextRank
直接预测VS先抽取再预测
4.2 实验设置
使用TransformerSum包。本文介绍该包及其优越性的内容不赘。
具体的设置比较简单,略。
4.3 主实验结果
评估指标是ROUGE-1、2、L的P、R和F1
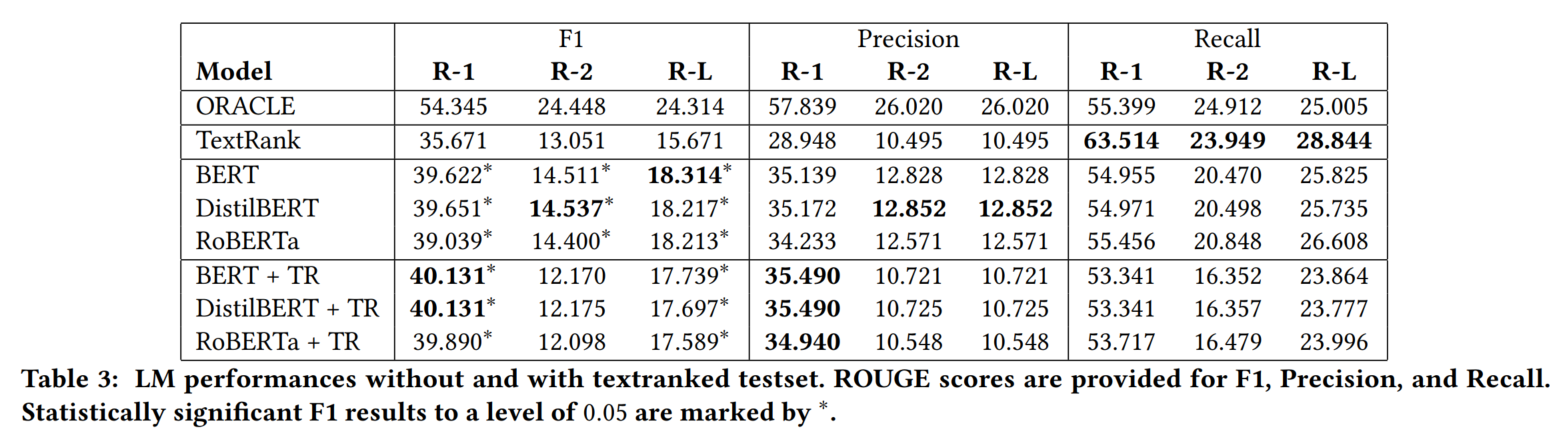
4.4 模型分析
摘要长度对ROUGE值的影响:
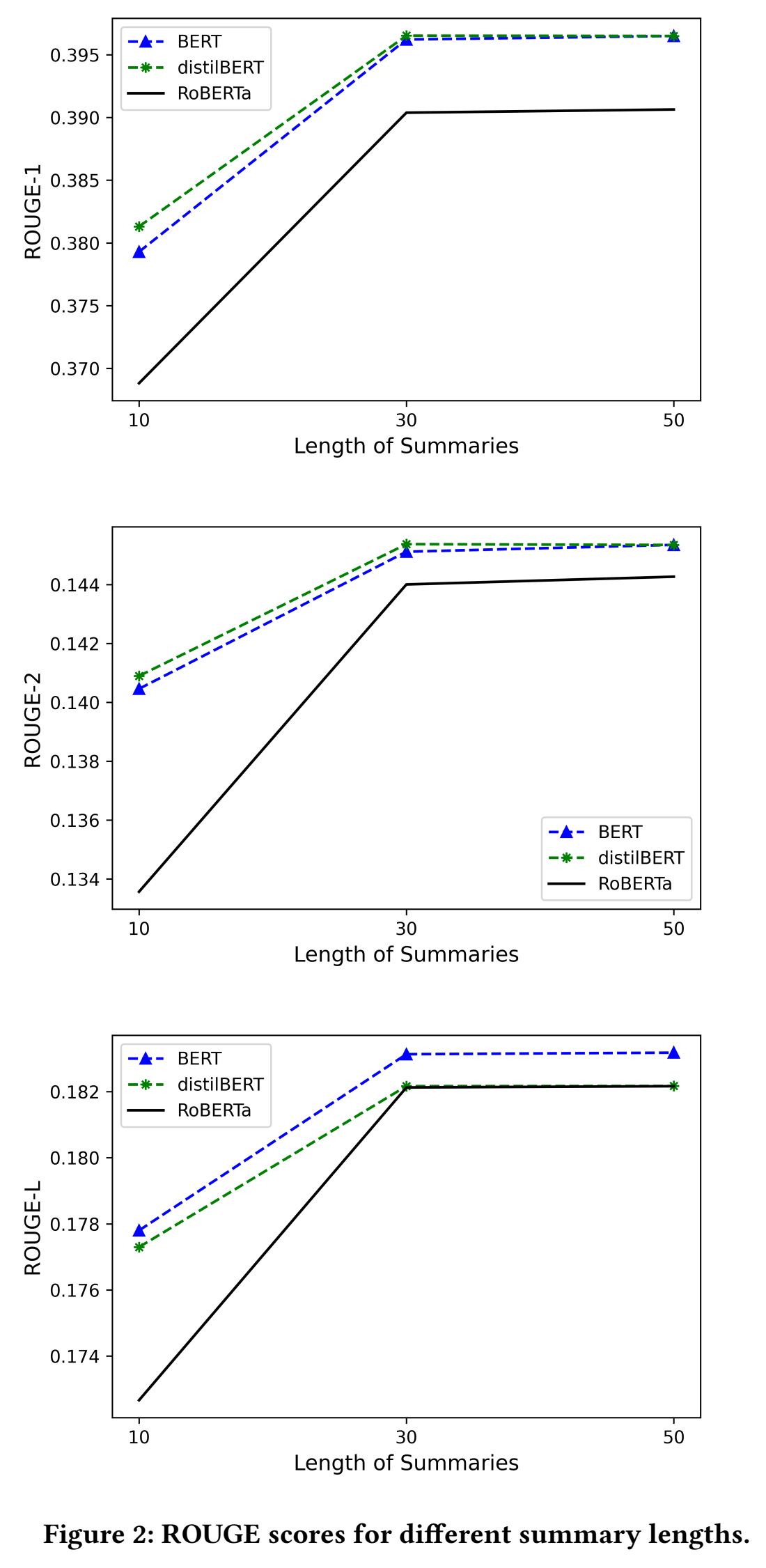
在本文中给出的参考文献是:1. Text Summarization with Pretrained Encoders 2. A Deep Reinforced Model for Abstractive Summarization
我简单百度了一下,指的是“根据句子的分数来排序,并丢弃那些与之前的句子有三字母重叠的句子”(出自2021-06-21ACL2020 Heterogeneous Graph Neural Networks for Extractive Document Summarization) ↩︎


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











