







(本文是和ChatGPT一起写的,引用部分都是直接复制自ChatGPT。呃代码其实我还没有跑过,所以可能是有bug的哦。
但是感觉ChatGPT比我聪明,感觉我的博客事业要遭遇大滑铁卢了)
文章目录
1. 什么是序列标注任务
写了一篇新博客,可以直接参考:序列标注/信息抽取任务(持续更新ing…)
2. 序列标注中的BIO是什么
在序列标注任务中,BIO 是一种常用的标记方案,用于标记文本中的实体。BIO 指的是三种标记,分别是 Beginning(开始)、Inside(内部)和 Outside(外部)。B 表示一个实体的开始,I 表示实体的内部,O 表示没有实体。
BIO 标记的应用通常是在命名实体识别(NER)任务中。例如,在一个句子中,识别出人名“John Smith”,则可以将“John”标记为“B-PER”,“Smith”标记为“I-PER”,而句子中其他的单词则标记为“O”。这样的标记方案可以帮助机器学习模型更好地理解文本中的实体,从而提高命名实体识别的准确率。
3. 序列标注模型中的标签不协调问题
如B-singer followed by I-song(表述方式来自GL-GIN: Fast and Accurate Non-Autoregressive Model for Joint Multiple Intent Detection and Slot Filling一文)
4. 发生问题的场景
TLDR:多发于NAR模型
详情:
autoregressive的序列标注模型(如基于Transformer的模型)通常不会出现这种问题。这是因为在这些模型中,标签的预测是基于先前标签的预测结果进行的,因此当前预测的标签会受到之前预测的标签的约束。
例如,在NER任务中,如果一个实体以B-开始,那么下一个标记必须是I-,而不能是B-。因此,基于Transformer的自回归模型会根据之前预测的标签生成下一个标签,而很少会出现不协调的标签。
然而,一些非自回归的序列标注模型,如标准的CRF模型,则可能会出现uncoordinated slot problem的问题,因为它们不能利用上下文中的信息来约束当前标签的预测。为了解决这个问题,可以采用一些后处理方法,例如基于规则的方法或者是在模型训练时采用约束条件等。
5. 解决方案1:在模型训练时采用约束条件
一是在损失函数中添加约束项,二是在解码过程中添加约束
5.1 损失函数版
大概逻辑是在损失函数中增加一个对BIO标签顺序的约束项。(这个代码应该算是NAR的实现逻辑)
在序列标注任务中,我们希望模型预测的标记序列遵循BIO的规则。也就是说,如果标记以"B-"开头,那么接下来的标记必须以"I-"开头,否则序列是不合法的。在模型训练时,我们可以在损失函数中加入一个约束项,来确保模型预测的标记序列是合法的。
下面是一个简单的例子,展示了如何使用Python实现一个基于自回归的序列标注模型,并在损失函数中加入BIO约束:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MyModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MyModel, self).__init__()
self.hidden_dim = hidden_dim
self.rnn = nn.LSTM(input_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(1, x.size(0), self.hidden_dim)
c0 = torch.zeros(1, x.size(0), self.hidden_dim)
out, _ = self.rnn(x, (h0, c0))
out = self.fc(out)
return out
def loss_function(output, target):
# 计算交叉熵损失
ce_loss = F.cross_entropy(output.view(-1, output.size(-1)), target.view(-1), reduction='none')
ce_loss = ce_loss.view(output.size()[:-1])
# 计算BIO约束损失
b_loss = torch.zeros_like(ce_loss)
for i in range(target.size(0)):
for j in range(target.size(1)):
if target[i][j] == 0:
continue
if target[i][j].item() == 1: # "B-"标记
if j+1 < target.size(1) and target[i][j+1].item() != 2: # 接下来不是"I-"标记
b_loss[i][j] = 1
elif target[i][j].item() == 2: # "I-"标记
if j+1 >= target.size(1) or target[i][j+1].item() == 1 or target[i][j+1].item() == 0: # 接下来是"B-"标记或者"O"标记
b_loss[i][j] = 1
# 将交叉熵损失和BIO约束损失加权求和
loss = torch.mean(ce_loss + b_loss)
return loss
在这个例子中,我们使用了一个简单的LSTM模型来进行序列标注任务。在损失函数loss_function()中,我们首先计算了交叉熵损失,然后计算了BIO约束损失。在计算BIO约束损失
5.2 在解码过程中用BIO标签矩阵限制标签生成顺序
大致来说就是直接在模型里显式定义标签矩阵,然后通过AR的方式解码,在每一时间步上直接显式约束标签的选择
对于一个基于自回归的序列标注模型,通常的做法是在生成每个标记时,使用前面已经生成的标记作为上下文。在这种情况下,为了满足BIO的约束,我们可以在每个时间步计算一个BIO的得分,并将其作为生成下一个标记的条件之一。具体而言,我们可以为每个标记的开始(B-)和内部(I-)分别设置得分,用于鼓励模型生成合法的BIO序列。
下面是一个简单的例子,展示了如何在PyTorch中实现一个基于自回归的序列标注模型,并在生成标记时使用BIO得分约束:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MyModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MyModel, self).__init__()
self.hidden_dim = hidden_dim
self.rnn = nn.LSTM(input_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.b_scores = nn.Parameter(torch.randn(output_dim))
self.i_scores = nn.Parameter(torch.randn(output_dim))
def forward(self, x, y):
h0 = torch.zeros(1, x.size(0), self.hidden_dim)
c0 = torch.zeros(1, x.size(0), self.hidden_dim)
out, _ = self.rnn(x, (h0, c0))
out = self.fc(out)
b_scores = self.b_scores.view(1, 1, -1).expand(x.size(0), x.size(1), -1)
i_scores = self.i_scores.view(1, 1, -1).expand(x.size(0), x.size(1), -1)
b_scores = b_scores.masked_fill(y != 1, float('-inf'))
i_scores = i_scores.masked_fill(y != 2, float('-inf'))
scores = out + b_scores + i_scores
return scores
def generate(self, x):
h0 = torch.zeros(1, x.size(0), self.hidden_dim)
c0 = torch.zeros(1, x.size(0), self.hidden_dim)
y = torch.zeros(x.size(0), x.size(1), dtype=torch.long).to(x.device)
for i in range(x.size(1)):
scores = self.forward(x[:, :i+1, :], y[:, :i])
probs = F.softmax(scores[:, -1, :], dim=-1)
y[:, i] = torch.multinomial(probs, 1).squeeze(-1)
return y
在forward()方法中,我们首先计算了每个标记的得分,然后在每个时间步使用了BIO得分约束,通过将B-得分和I-得分与标签序列进行掩码操作来确保生成的标记序列满足BIO约束。
在generate()方法中,我们利用已训练好的模型来生成标记序列。对于每个时间步,我们首先计算当前上下文下每个标记的得分,然后对这些得分进行softmax归一化,得到每个标记的概率分布。最后,我们从每个概率分布中采样一个标记作为生成的标记序列的下一个标记。
6. 解决方式2:基于规则进行后处理
6.1 CRF
(我不知道它为什么要举BII这个错误的例子,但是反正意思大概是这么个意思吧,毕竟我也不太懂CRF)
在序列标注中,一个序列中的标签通常是相互关联的,例如一个标签可能取决于其前面和后面的标签,而这种关系是通过CRF来建模的。CRF是一种概率图模型,它可以对序列中的标签进行联合建模,即在给定序列的输入和标签序列的条件下,计算标签序列的概率。
在序列标注中,通常使用线性链CRF模型,其中每个标签是一个状态,每个状态都有一个特征函数,它考虑了当前标签以及前一个标签的值,用于衡量这个标签是否适合当前位置。特征函数通常表示为形式化的表达式,可以基于各种特征来定义,例如输入单词、标签转移、前缀、后缀等。
使用CRF后处理的主要思想是,在模型生成的标注结果中,通过优化一些准则来调整一些标记的标记,以消除不一致的情况。例如,可以通过定义转移概率和状态特征函数来优化模型生成的标记序列,从而得到一个更加合理的序列。
具体来说,为了解决不协调问题,可以设计一些状态特征函数,这些特征函数可以惩罚不合法的标记序列,例如惩罚出现B-I-I这样的标记序列,从而鼓励模型生成更加合理的标记序列。例如,我们可以设计一个特征函数来惩罚B-I-I序列:
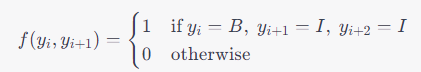
其中 y i y_i yi表示在位置 i i i处的标签, y i + 1 y_{i+1} yi+1表示在位置 i + 1 i+1 i+1处的标签, y i + 2 y_{i+2} yi+2表示在位置 i + 2 i+2 i+2处的标签。这个特征函数的作用是,当模型生成了一个不合法的B-I-I标记序列时,该函数的值为1,否则为0。通过将这样的特征函数添加到CRF模型中,并训练模型以最小化整个序列的负对数似然,可以得到一个更加合理的标记序列,从而解决不协调问题。
总之,CRF后处理可以通过定义状态特征函数来惩罚不合法的标记序列,从而得到一个更加合理的序列。这种方法可以与基于规则的方法相结合,以进一步提高标记序列的准确度。
除了上述特征函数外,还可以定义其他特征函数来捕捉序列中其他不合法的情况,例如不允许出现O标签之后的I标签,或者不允许出现连续的O标签等等。通过组合这些特征函数,可以得到一个全面的特征集,用于优化模型生成的标记序列。
当然,在使用CRF后处理时,需要保证标记序列已经经过初始模型的预测,这意味着需要首先使用一些基于自回归的序列标注模型(如BERT、LSTM等)生成初始的标记序列,然后使用CRF后处理来调整标记序列,以使其更合理。这种组合方法可以减少不协调问题的发生,并且可以通过适当的特征设计来提高序列标注的性能。
综上所述,CRF后处理是一种有效的方法,可以帮助解决序列标注中的不协调问题。通过定义特征函数来惩罚不合法的标记序列,可以得到一个更加合理的标记序列,从而提高序列标注的准确性和稳定性。
score ( y , x ) = ∑ i = 1 n ( ∑ j = 1 k w j f j ( y i − 1 , y i , x , i ) ) + ∑ i = 1 n ∑ j = 1 k w j g j ( y i , x , i ) + ∑ i = 1 n ( w k + 1 1 y i ∈ B , M , E , W , O ) \begin{aligned} & \operatorname{score}(y, x) \\ = & \sum_{i=1}^{n} \left( \sum_{j=1}^{k} w_j f_j(y_{i-1}, y_i, x, i) \right) \\ & + \sum_{i=1}^{n} \sum_{j=1}^{k} w_j g_j(y_i, x, i) \\ & + \sum_{i=1}^{n} \left( w_{k+1} \mathbf{1}{y_i \in {B, M, E, W, O}} \right) \end{aligned} =score(y,x)i=1∑n(j=1∑kwjfj(yi−1,yi,x,i))+i=1∑nj=1∑kwjgj(yi,x,i)+i=1∑n(wk+11yi∈B,M,E,W,O)
这个公式是条件随机场(Conditional Random Field, CRF)中计算标注序列 y y y 在给定输入序列 x x x 下的得分(score)的公式。它可以用于序列标注问题,如命名实体识别(Named Entity Recognition, NER)和词性标注(Part-of-Speech Tagging, POS)。具体来说,这个公式包含三个部分:
第一个部分是转移特征函数的得分,表示相邻两个标签 y i − 1 y_{i-1} yi−1 和 y i y_i yi 的转移概率。 w j w_j wj 是对应特征函数的权重, f j ( y i − 1 , y i , x , i ) f_j(y_{i-1}, y_i, x, i) fj(yi−1,yi,x,i) 是特征函数,表示在位置 i i i 上,从标签 y i − 1 y_{i-1} yi−1 转移到标签 y i y_i yi 的概率。这里使用了求和符号来表示所有的转移特征函数。
第二个部分是状态特征函数的得分,表示当前位置 i i i 上标签 y i y_i yi 的概率。 w j w_j wj 是对应特征函数的权重, g j ( y i , x , i ) g_j(y_i, x, i) gj(yi,x,i) 是特征函数,表示在位置 i i i 上,标签 y i y_i yi 出现的概率。这里使用了两个求和符号来表示所有的状态特征函数。
第三个部分是约束函数,用于约束标签序列必须满足 B/M/E/W/O 格式。 w k + 1 w_{k+1} wk+1 是约束函数的权重, 1 y i ∈ B , M , E , W , O \mathbf{1}{y_i \in {B, M, E, W, O}} 1yi∈B,M,E,W,O 是指示函数,如果标签 y i y_i yi 是 B/M/E/W/O 中的一个,则取值为1,否则取值为0。这里使用了一个求和符号来表示所有的约束函数。
通过计算标注序列在给定输入序列下的得分,我们可以选择得分最高的标注序列作为最终的预测结果。这就是 CRF 在序列标注问题中的应用。
6.2 规则
(呃原话其实是错误的,但是大约来说是这么个意思:自定义规则。具体的规则还是得另外自己写或者上网找资料。下面这个回复我懒得自己改了)
通过规则实现后处理可以用一些规则来纠正序列标注结果中的不合法序列,例如 B-I-I 和 B-E 等。这些规则可以基于领域知识或人工经验进行设计,也可以根据具体的数据集和任务来制定。下面是一个简单的例子:
假设我们有一个 NER 任务,标注类别包括 PERSON、LOCATION 和 ORGANIZATION。如果我们使用了 BMEWO 格式来编码标注序列,那么我们可以通过一些规则来纠正一些不合法的序列,例如:
B-I-I 规则:如果出现 B-I-I 的序列,我们可以将第二个 I 改为 O,即认为这个实体已经结束了。例如,B-PERSON、I-PERSON、I-PERSON 序列可以被纠正为 B-PERSON、O、O。
B-E 规则:如果出现 B-E 的序列,我们可以将 E 改为 I,即认为这个实体没有结束。例如,B-PERSON、E-PERSON 序列可以被纠正为 B-PERSON、I-PERSON。
其他规则:还有许多其他规则可以被用来纠正标注序列中的不合法序列,例如将单个的 B 标签转换为 O 标签,将单个的 I 标签转换为 B 标签等。
需要注意的是,基于规则的后处理方法可能无法处理所有的不合法序列,并且可能会引入一些新的错误。因此,在使用这种方法时,我们需要谨慎地设计规则,并在训练集和开发集上进行充分的实验和验证,以确保它对性能的影响是积极的。
















 6424
6424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











