







 文章探讨了GPT-3的架构升级、数据增强和训练方法,强调了模型的少样本学习能力。作者还关注了模型的公平性、资源消耗以及防止数据泄露的问题。
文章探讨了GPT-3的架构升级、数据增强和训练方法,强调了模型的少样本学习能力。作者还关注了模型的公平性、资源消耗以及防止数据泄露的问题。
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:Language Models are Few-Shot Learners
ArXiv网址:https://arxiv.org/abs/2005.14165
2020 NeurIPS:https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html
官方GitHub项目:openai/gpt-3: GPT-3: Language Models are Few-Shot Learners(模型没开源,但是如果对人造数据集感兴趣可以看看)
GPT-3没有开源,只能通过API调用。OpenAI官方没有明确说现在哪些API是GPT-3的,我猜测https://platform.openai.com/docs/models/gpt-base这两个文本生成模型应该是GPT-3的,但是官方也不建议继续使用GPT-3的API了,建议大家用3.5和4。因此GPT-3的主要价值就是承前启后、了解GPT系列模型的发展史了。
Re45:读论文 GPT-1 Improving Language Understanding by Generative Pre-Training
Re62:读论文 GPT-2 Language Models are Unsupervised Multitask Learners
GPT-3的框架跟GPT-1、2的差不多,但是扩大了网络参数规模,使用了更多的高质量训练数据,就使得其模型效果实现了显著提升,可以不用微调,直接通过少样本学习/上下文学习的方式,在prompt中给出任务示例,就能在新的预测样例上得到想要的结果。有些少样本学习效果比微调的SOTA模型还好。
模型越大越好(scaling laws1)
是谓大力出奇迹。
文中有很多验证不同规模模型上效果的图。
本文没有做GPT-3微调效果的实验。
我觉得前置知识我已经写够多了,本文就只写一些值得在意的点了。
文章目录
1. 上下文学习
优势是不用大规模微调数据集。效果随模型尺寸增长而变好(但是不如微调)。而且模型不会产生微调导致的分布局限问题,在通用任务上表现能力不会下降。
示意图:
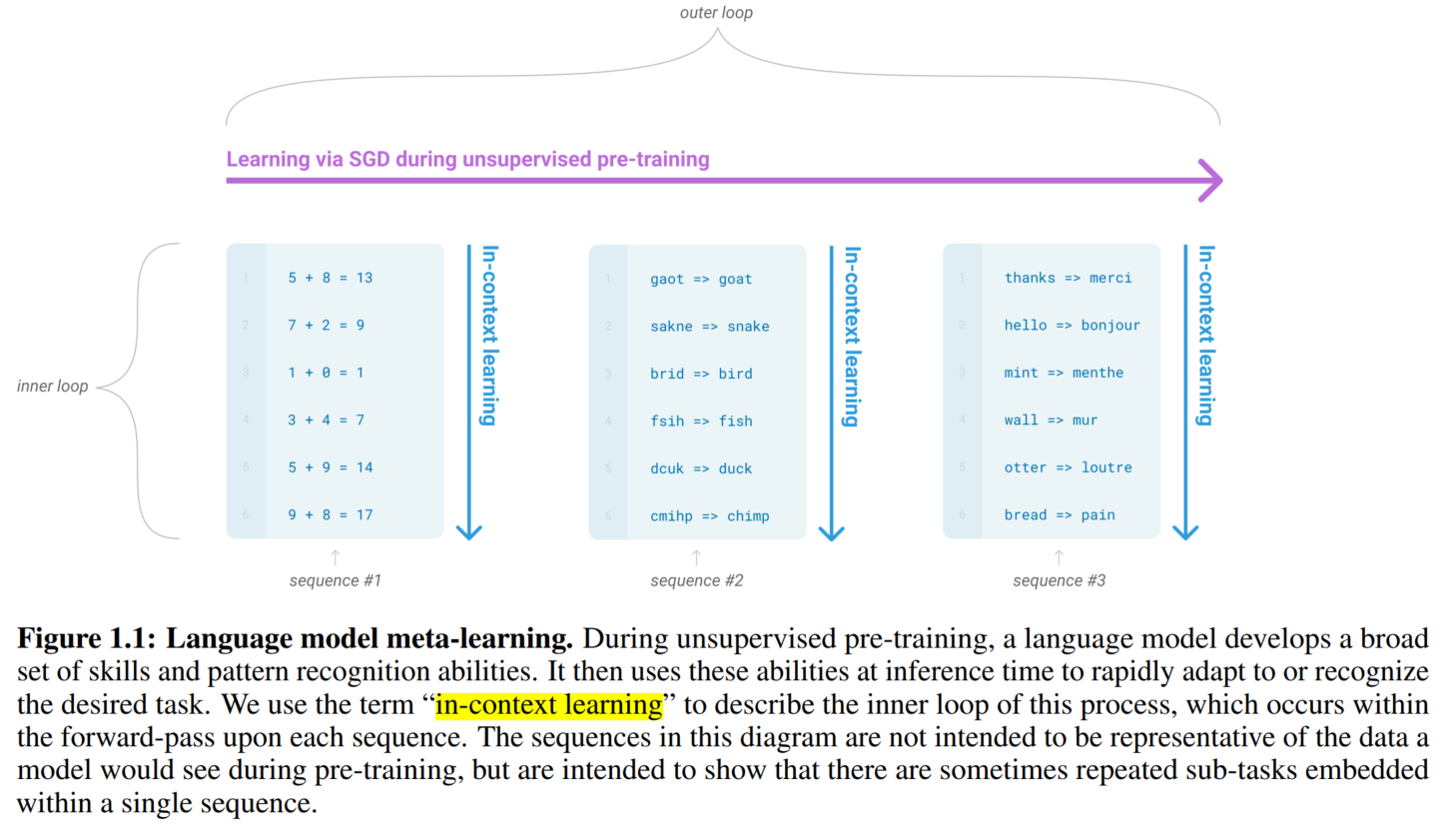
instruction
术语“demonstration”就是上下文中的样例(输入+输出 a context and a desired completion)
给出新输入,让模型给出输出
few-shot learning(10-100个)
one-shot learning
zero-shot learning

随着模型参数和数据集规模增长而效果越来越好:
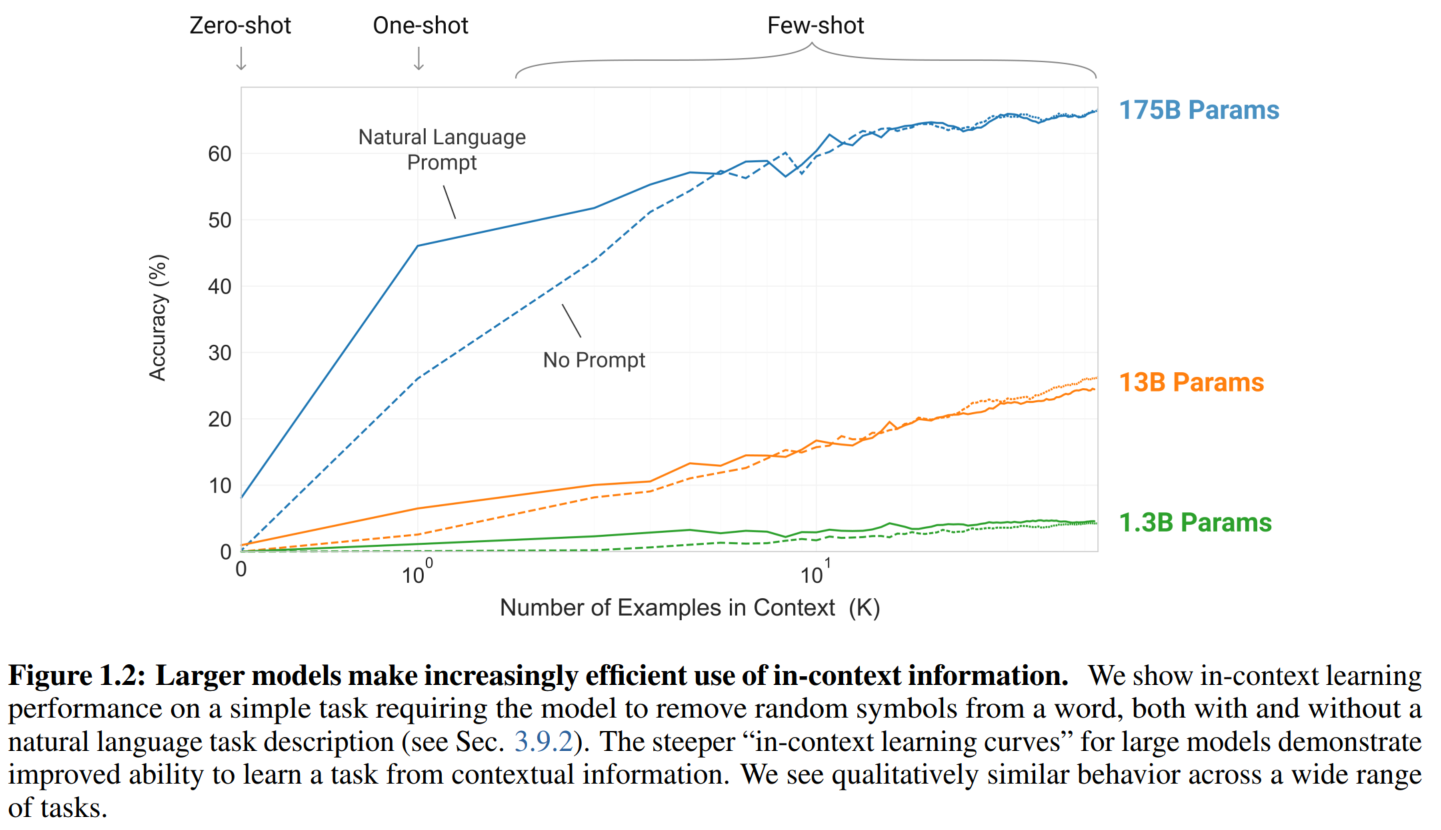
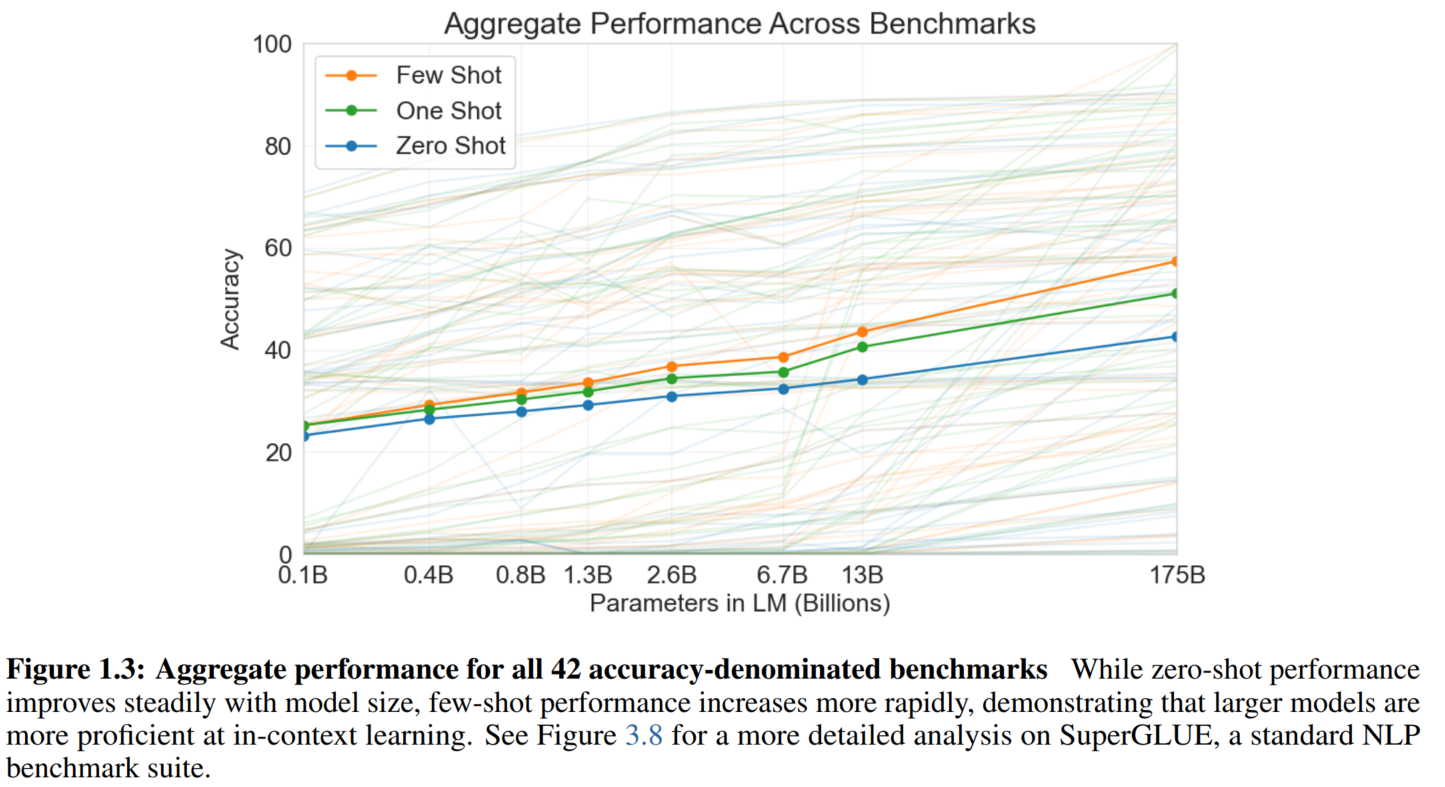
前人的工作已经证明了log loss随模型变大而下降,交叉熵损失下降也会带来在下游任务上效果的提升。
2. GPT-3
模型在GPT-2的基础上增加了alternating dense and locally banded sparse attention patterns(sparse transformer2)
最大的GPT-3是175B
模型越大,batch size应该越大,学习率越小1 3,用gradient noise scale来选择batch size3(我也不知道这是啥玩意儿,以后看)↓
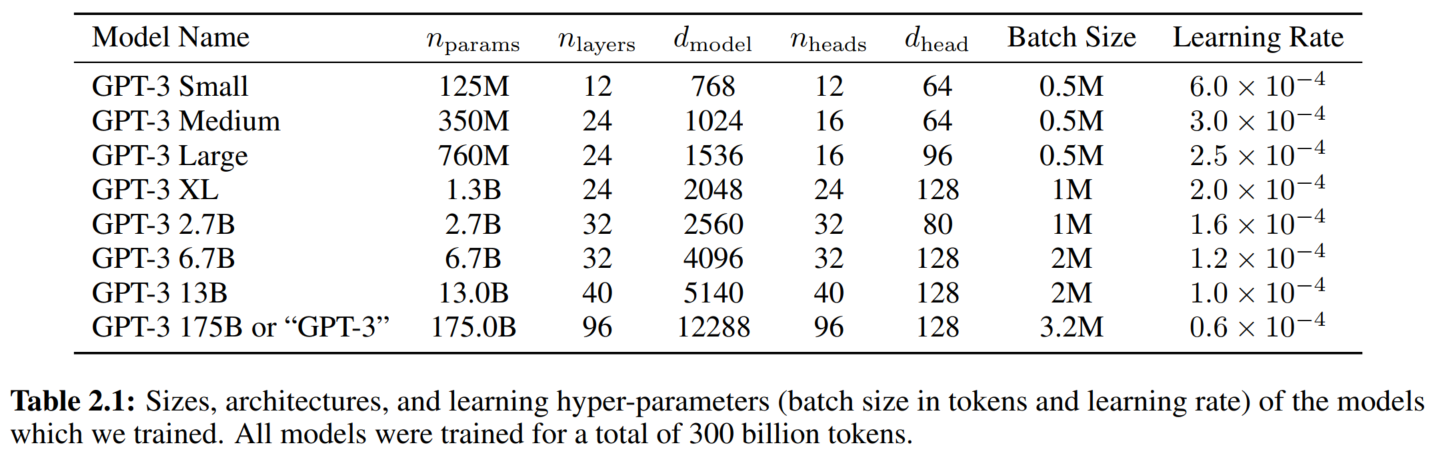
context window:2048
在Common Crawl数据集上预训练1个epoch
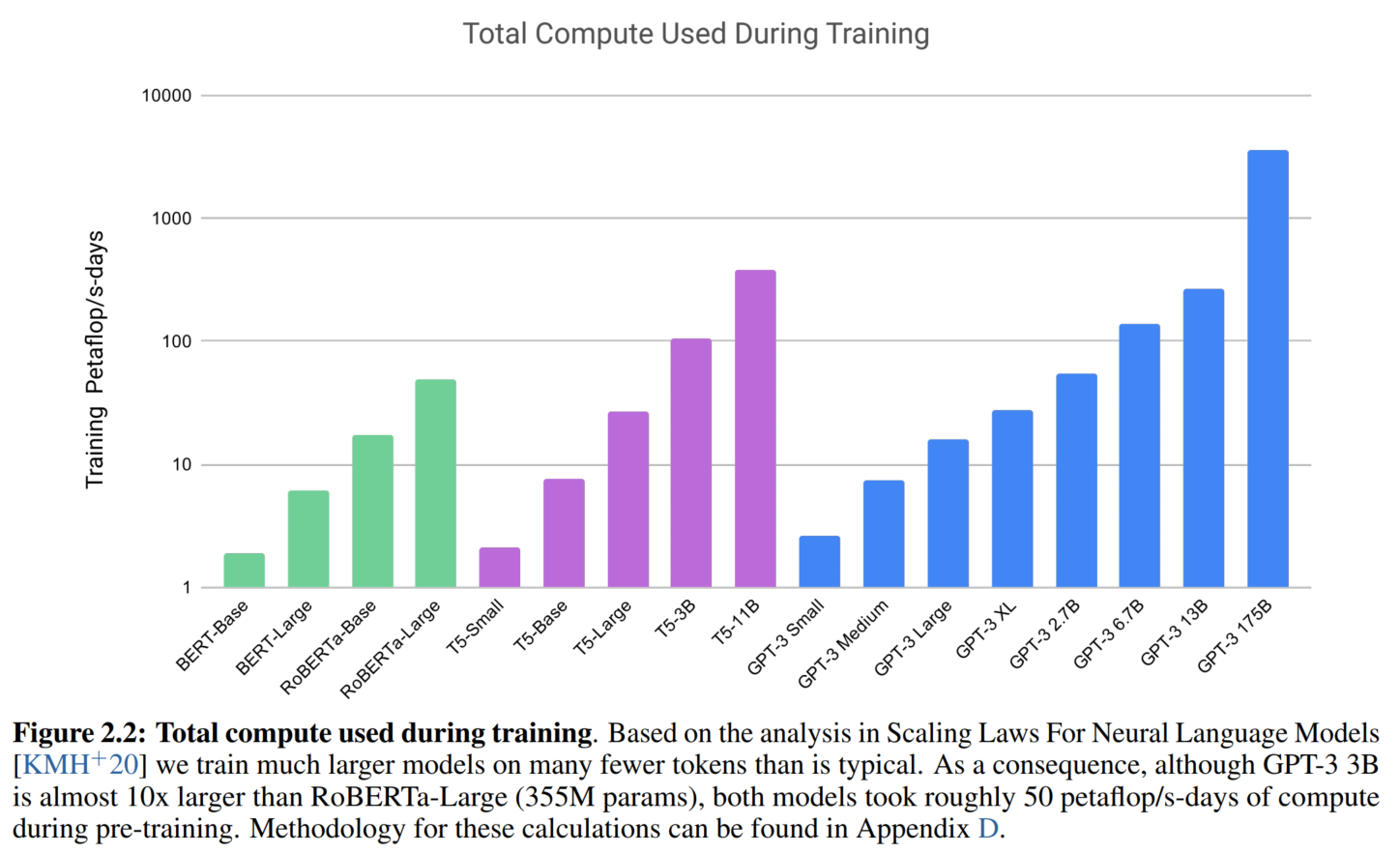
↑这个纵轴应该大概类似于训练算力的评估指标
model parallelism
训练过程中的scale loss:
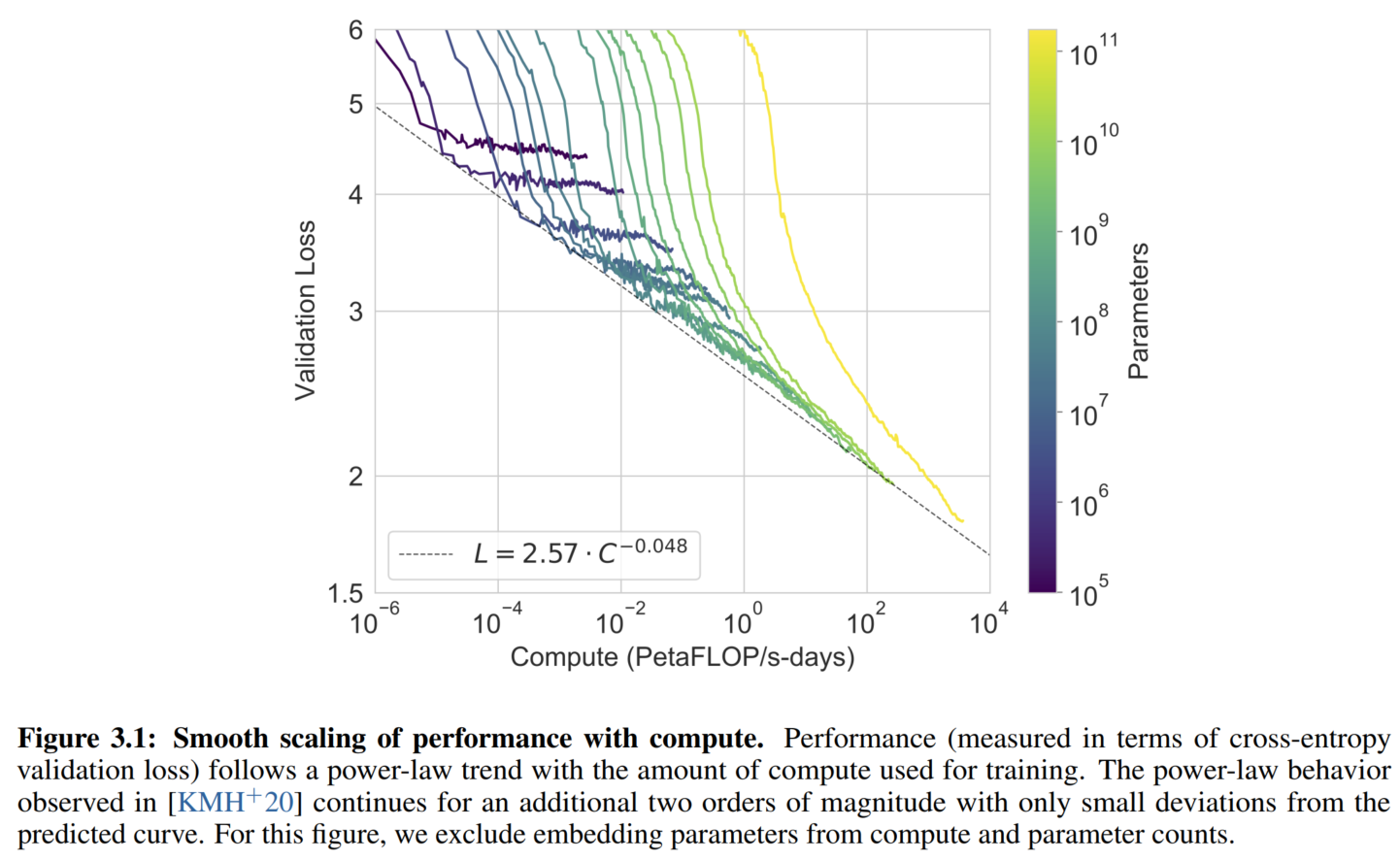
具体训练细节在附录,我没看。
1. 数据集
数据集清洗3步走(有噪音的效果不够好):① 靠近高质量语料 ② 去重 ③ 添加高质量语料(高质量语料抽样频率更高)
构建了一个预测高质量文本的分类器。
为了测试,删除了数据泄露的训练集数据。(文中有很大篇幅分析数据泄露问题)
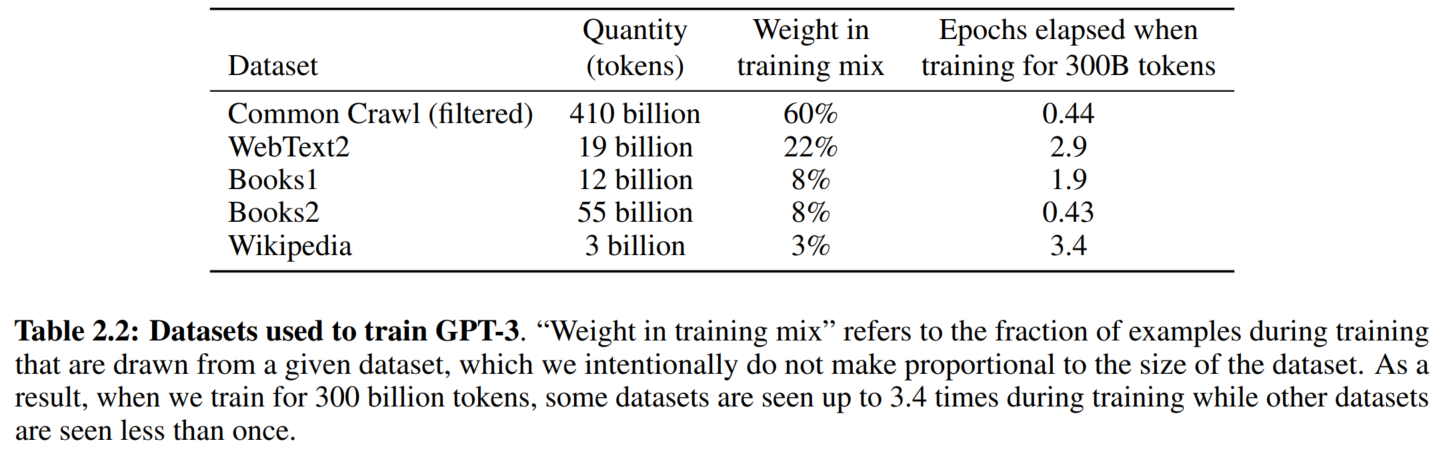
数据集比例:
2. 实验结果
评估指标略。
因为看到FLAN论文里提及了,所以简单补充一点:
选择题(包括多选和判断题)大多是用生成结果的LM似然来评估的,有些任务参考了T5的评估思路。
1. 语言模型

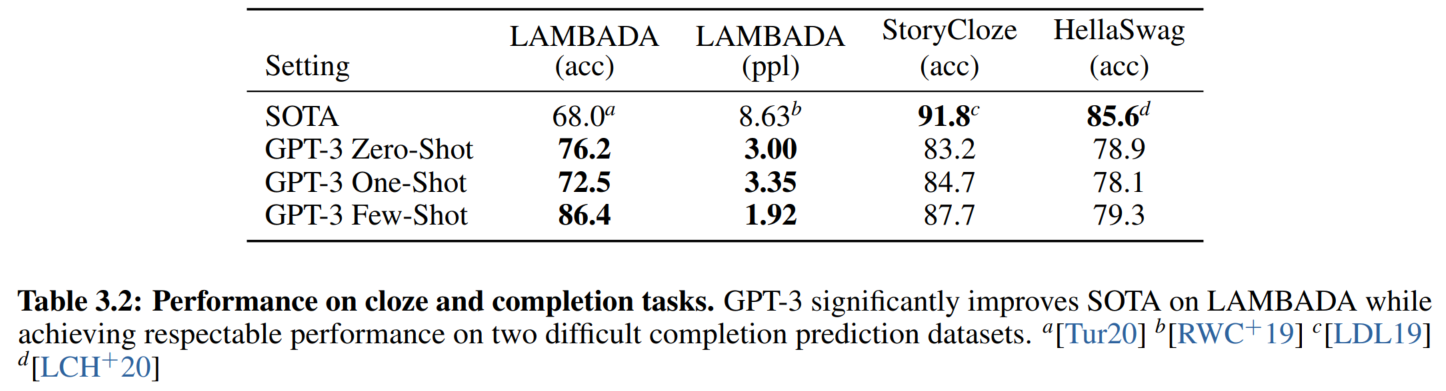
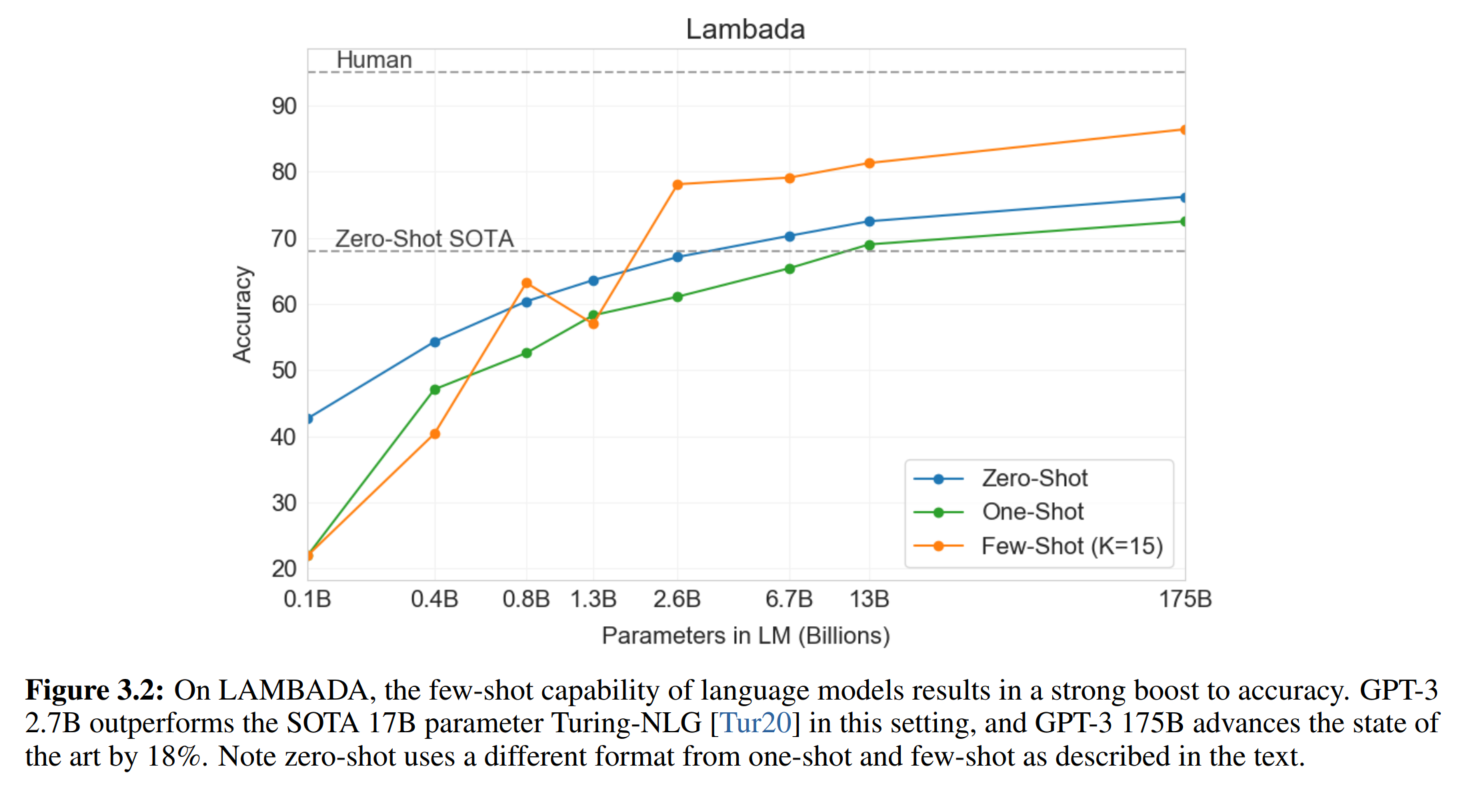
2. 文本补全和完形填空任务
类似语言模型训练任务
3. 开放域QA
Closed Book Question Answering
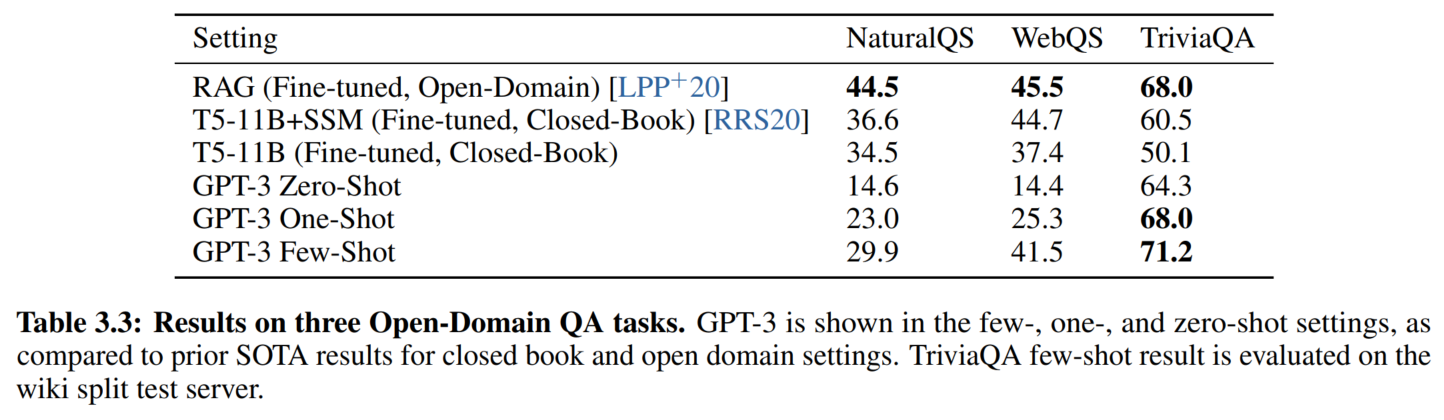
开卷(open-book)QA一般用的是信息检索方案。
↑ SSM指的是Q&A-specific pre-training procedure
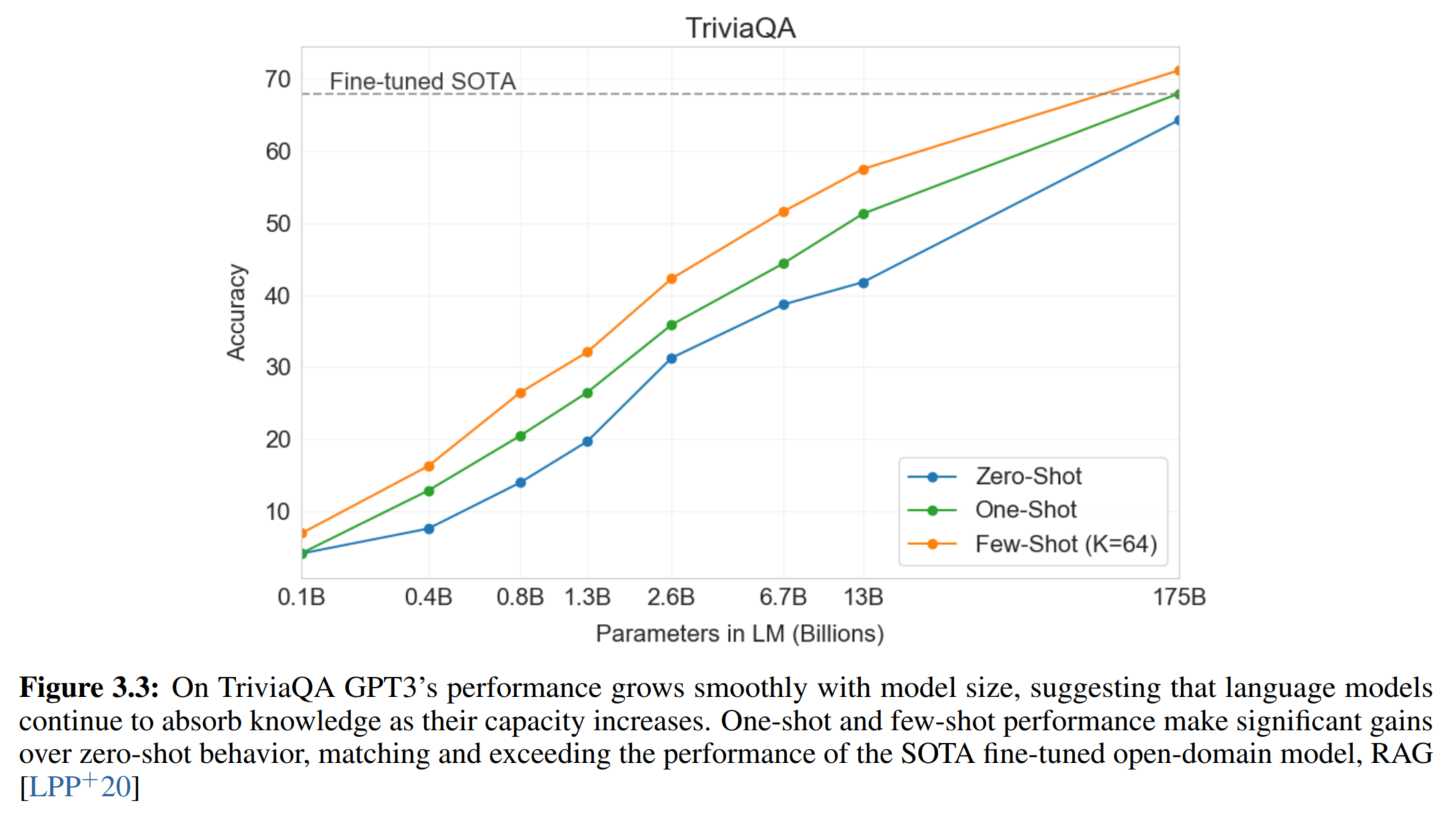
↑ 模型越大,知识越多
4. 翻译
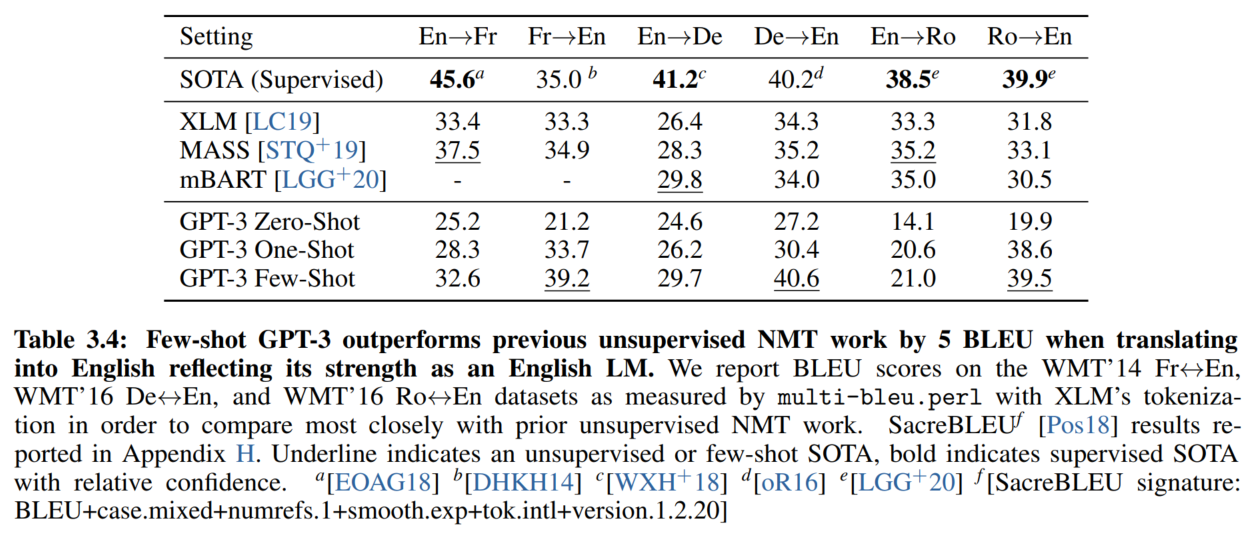

翻译到英文的效果比较好。
5. Winograd-Style Tasks
指代消歧
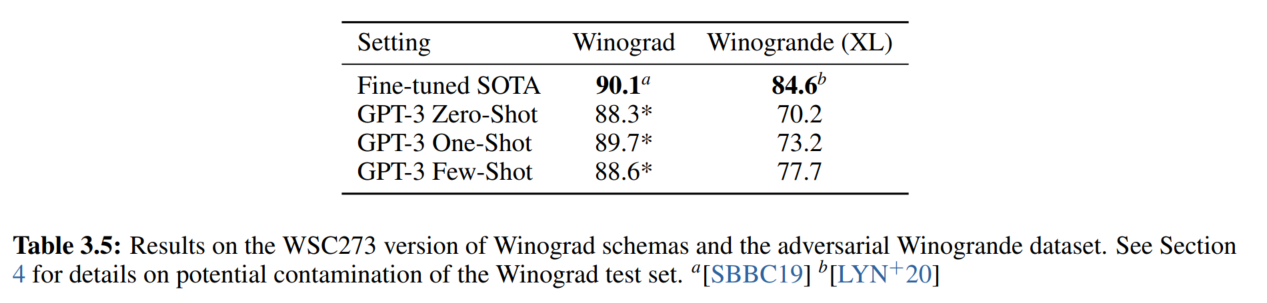
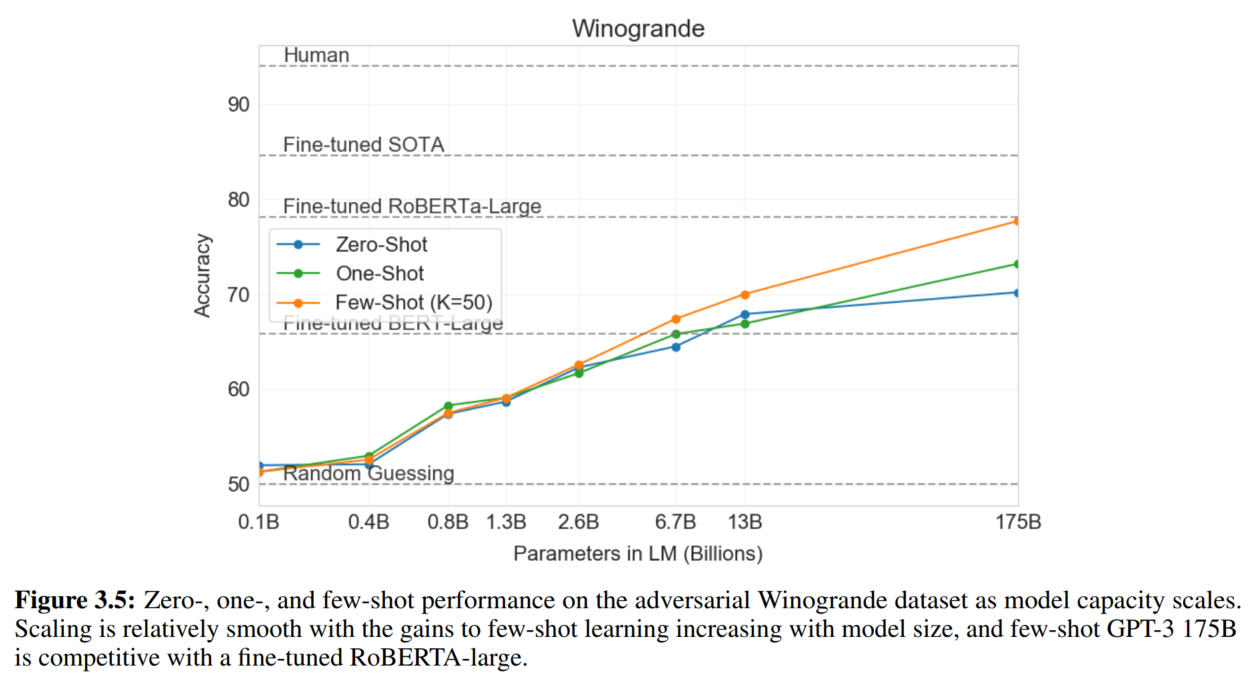
6. 常识推理
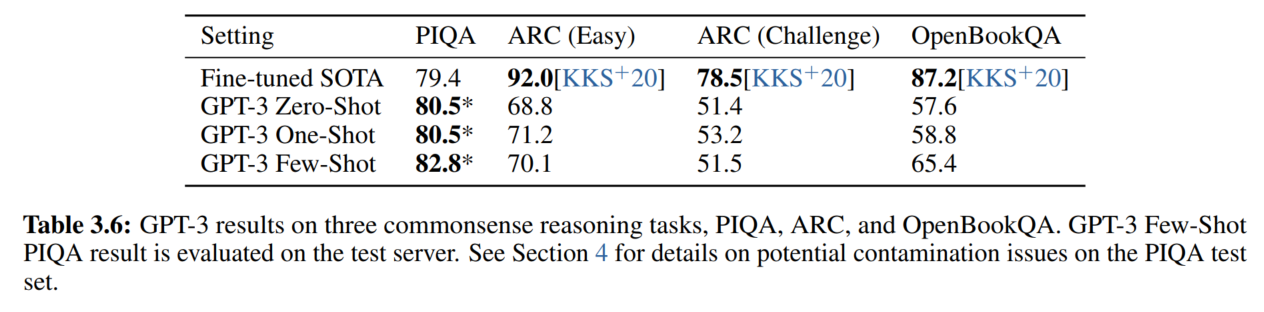
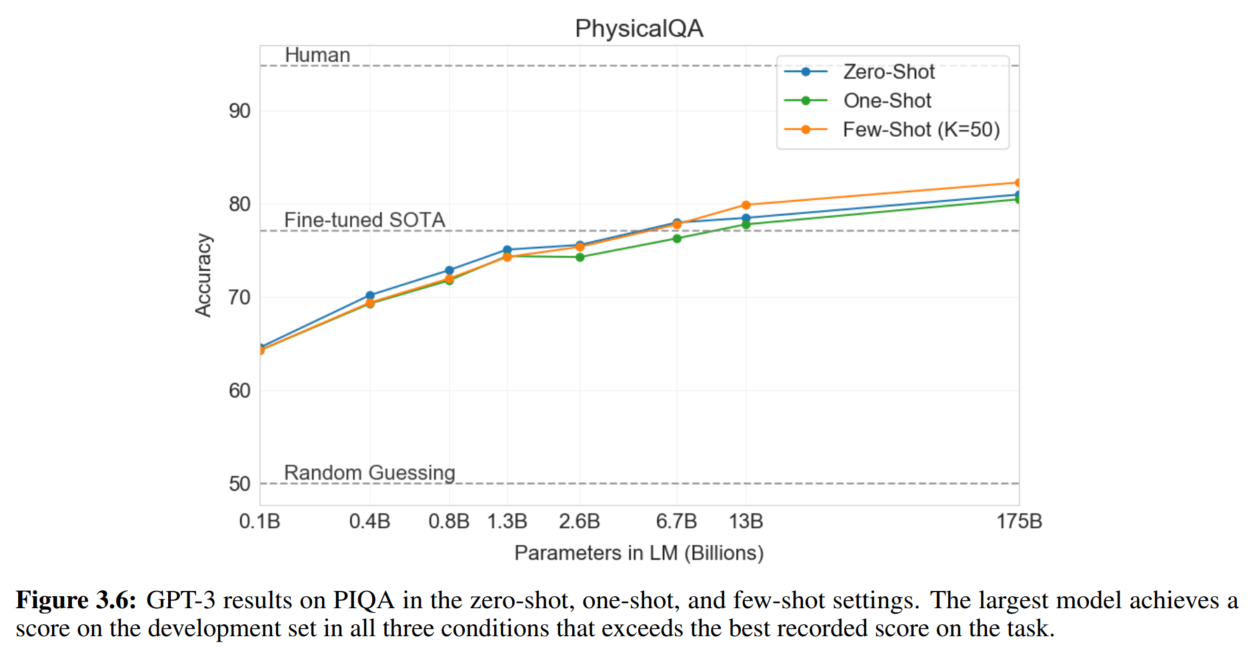
7. 阅读理解
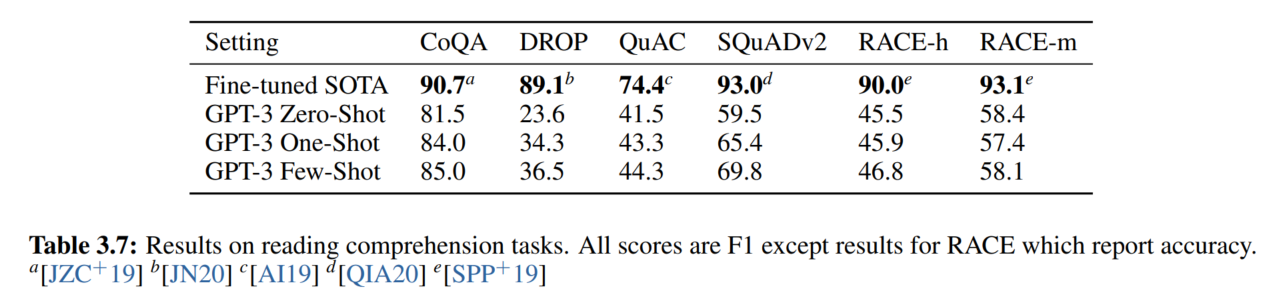
在要求严格回答格式的数据集上表现最差
8. SuperGLUE
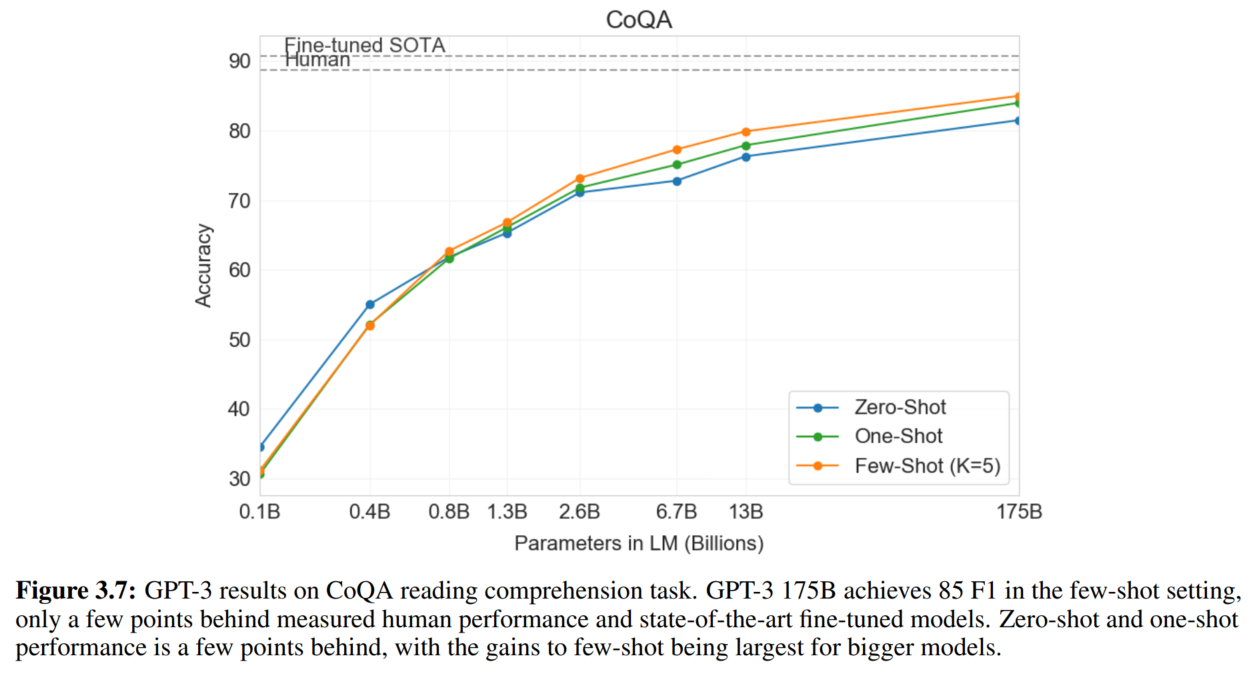
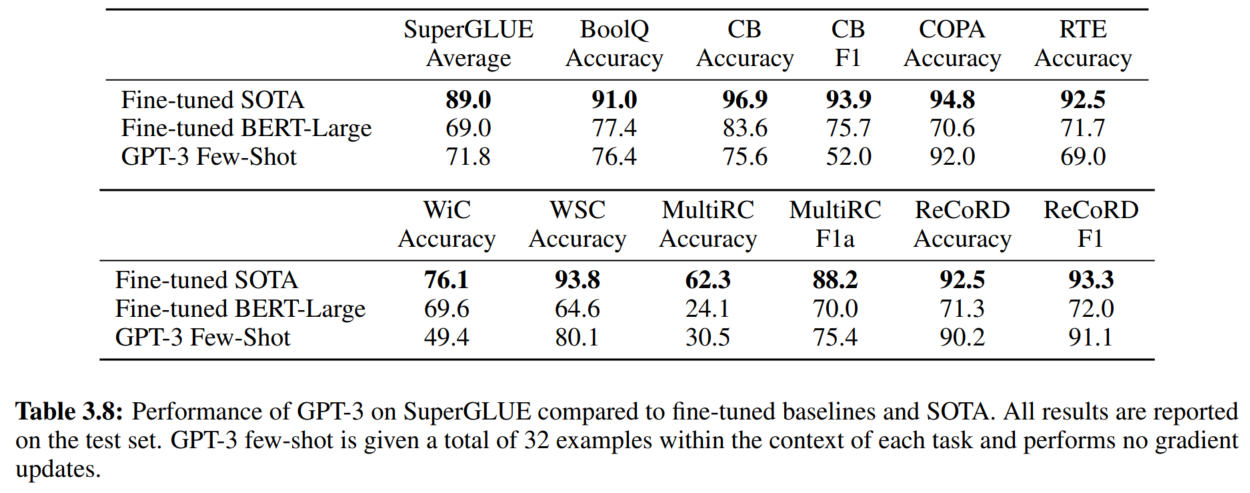
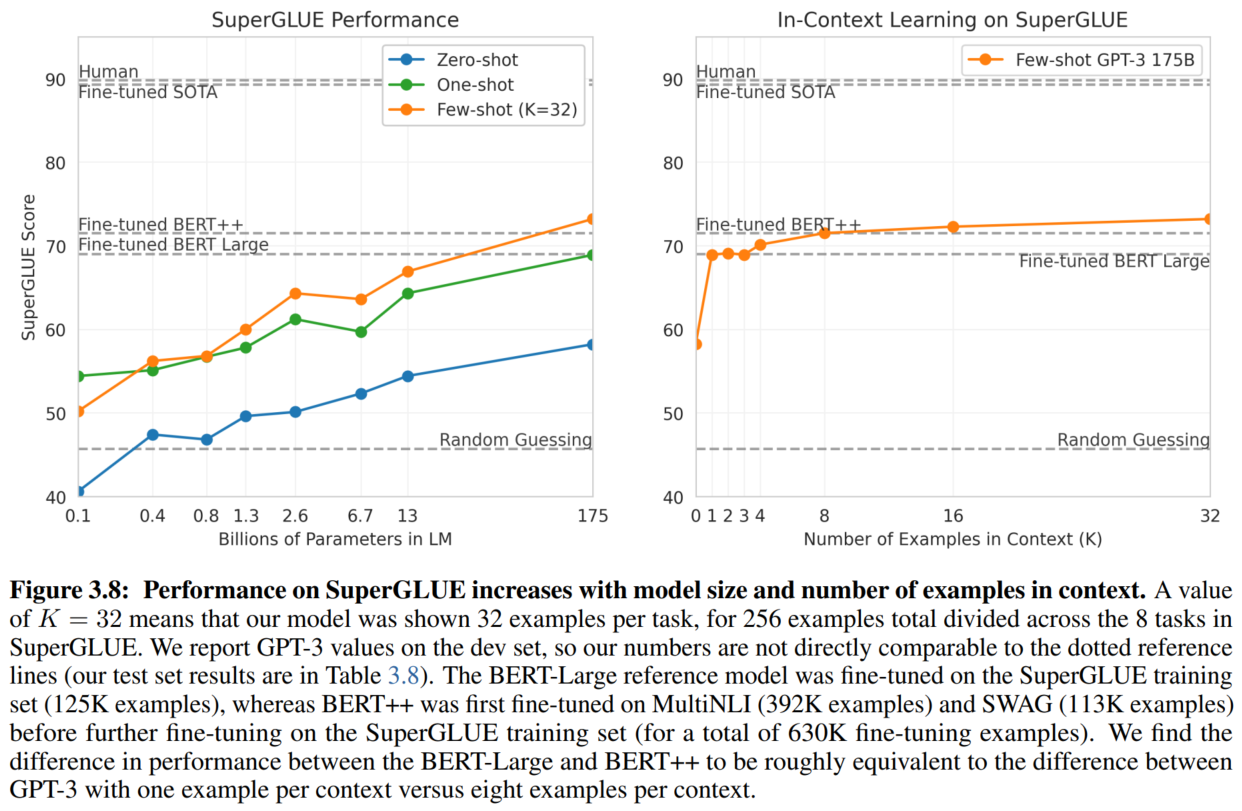
9. NLI
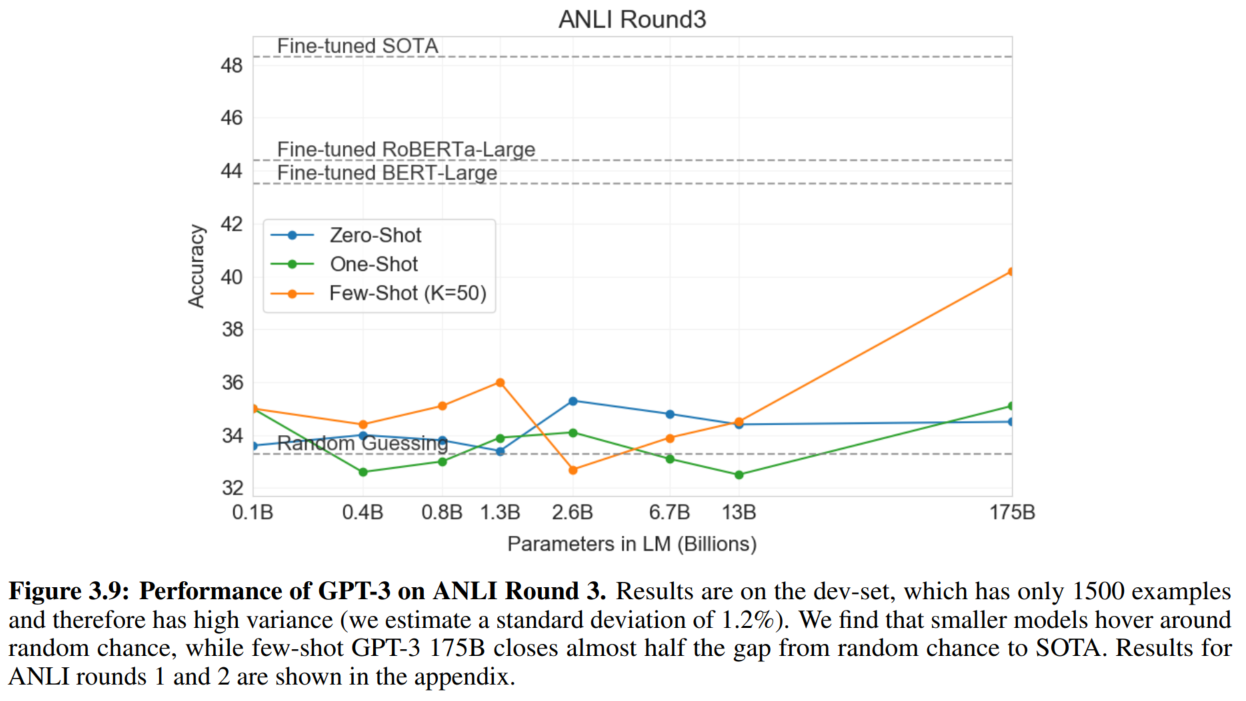
10. Synthetic and Qualitative Tasks
-
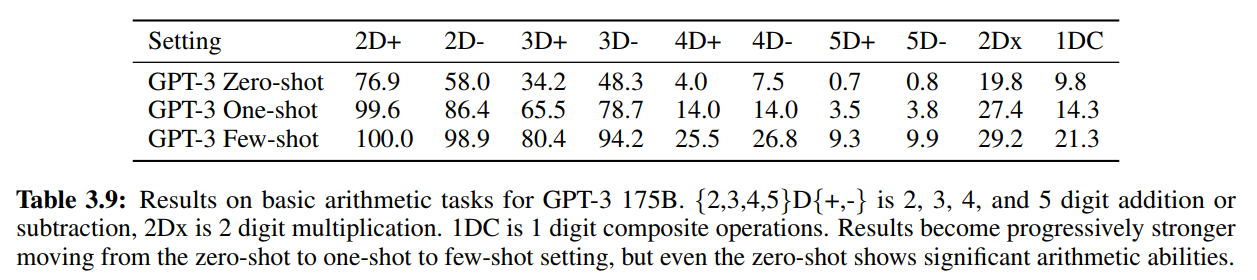
算术
少样本:
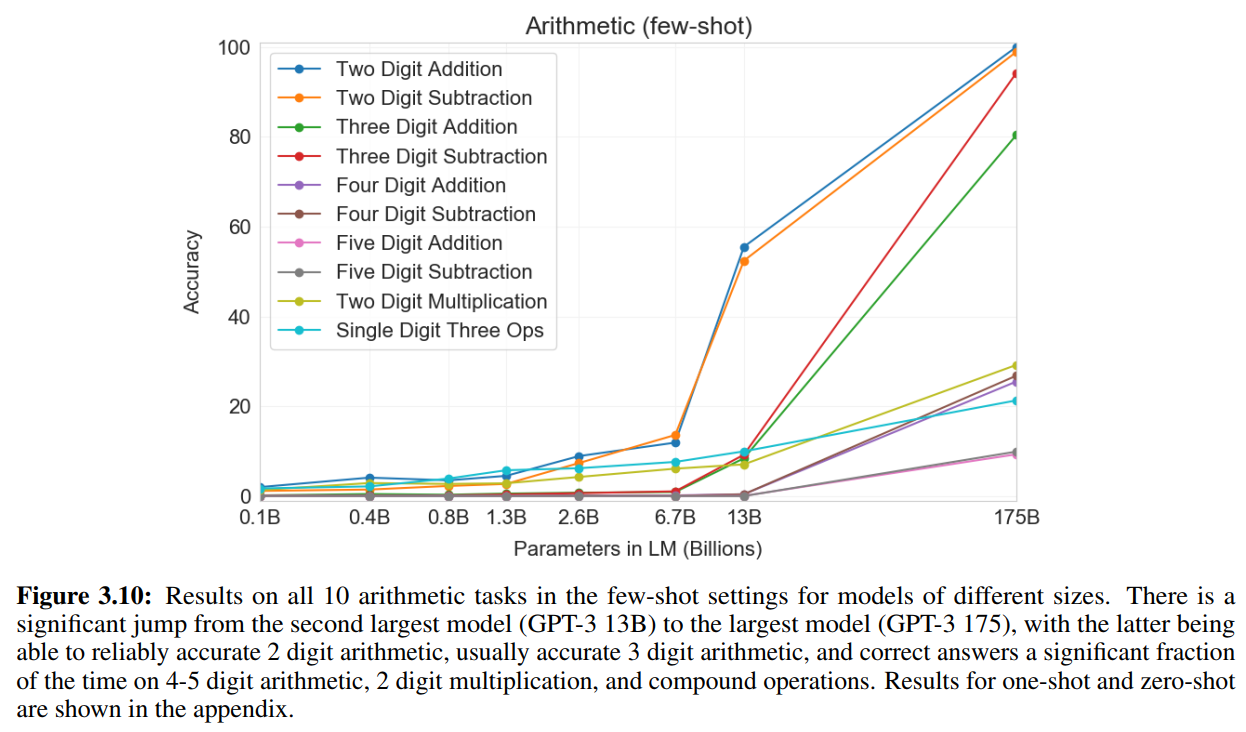
↑ N-digit指的是数字的最高位数
composite是带运算符的(如Q: What is 6+(4*8)? A: 38)
所有setting:
-
恢复单词中的字母顺序
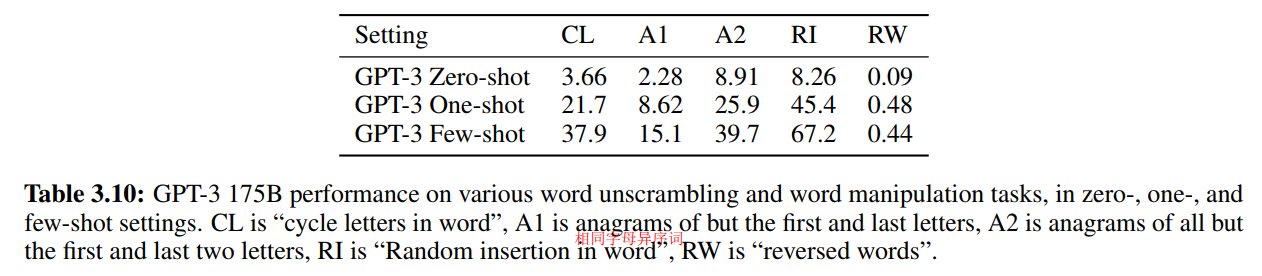
少样本:
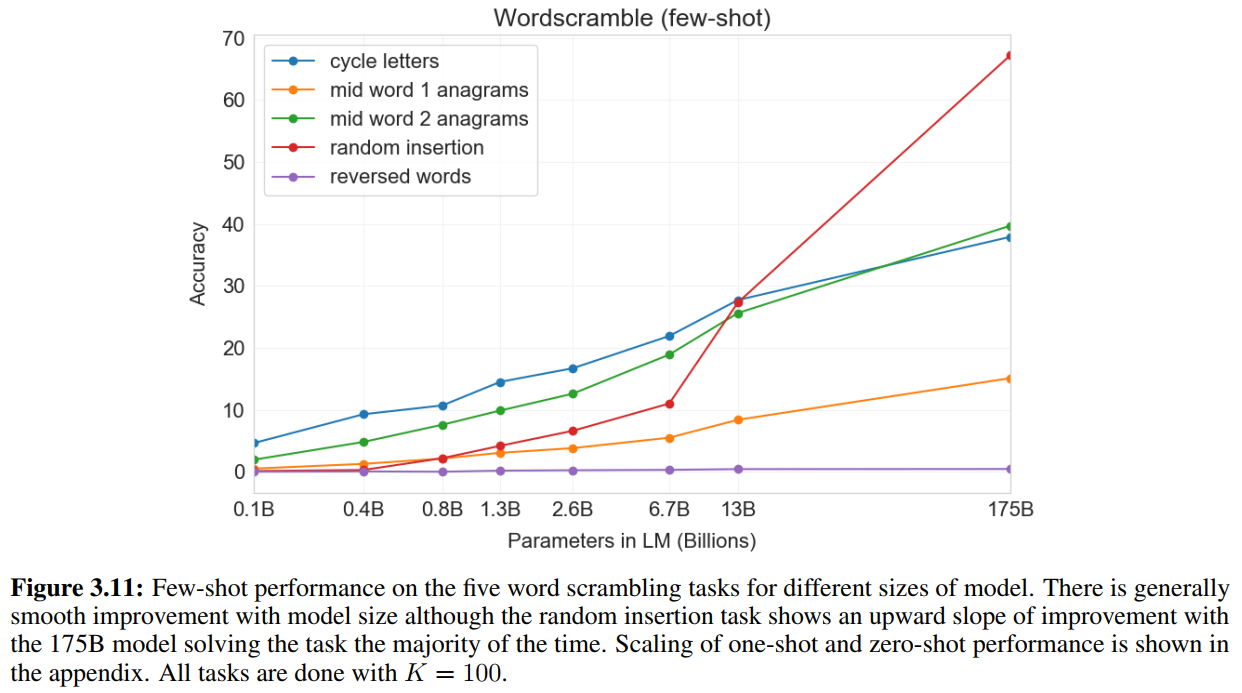
-
SAT-style analogy
示例:audacious is to boldness as (a) sanctimonious is to hypocrisy, (b) anonymous is to identity, (c) remorseful is to misdeed, (d) deleterious is to result, (e) impressionable is to temptation
感觉算是一种英语词汇量考试题?
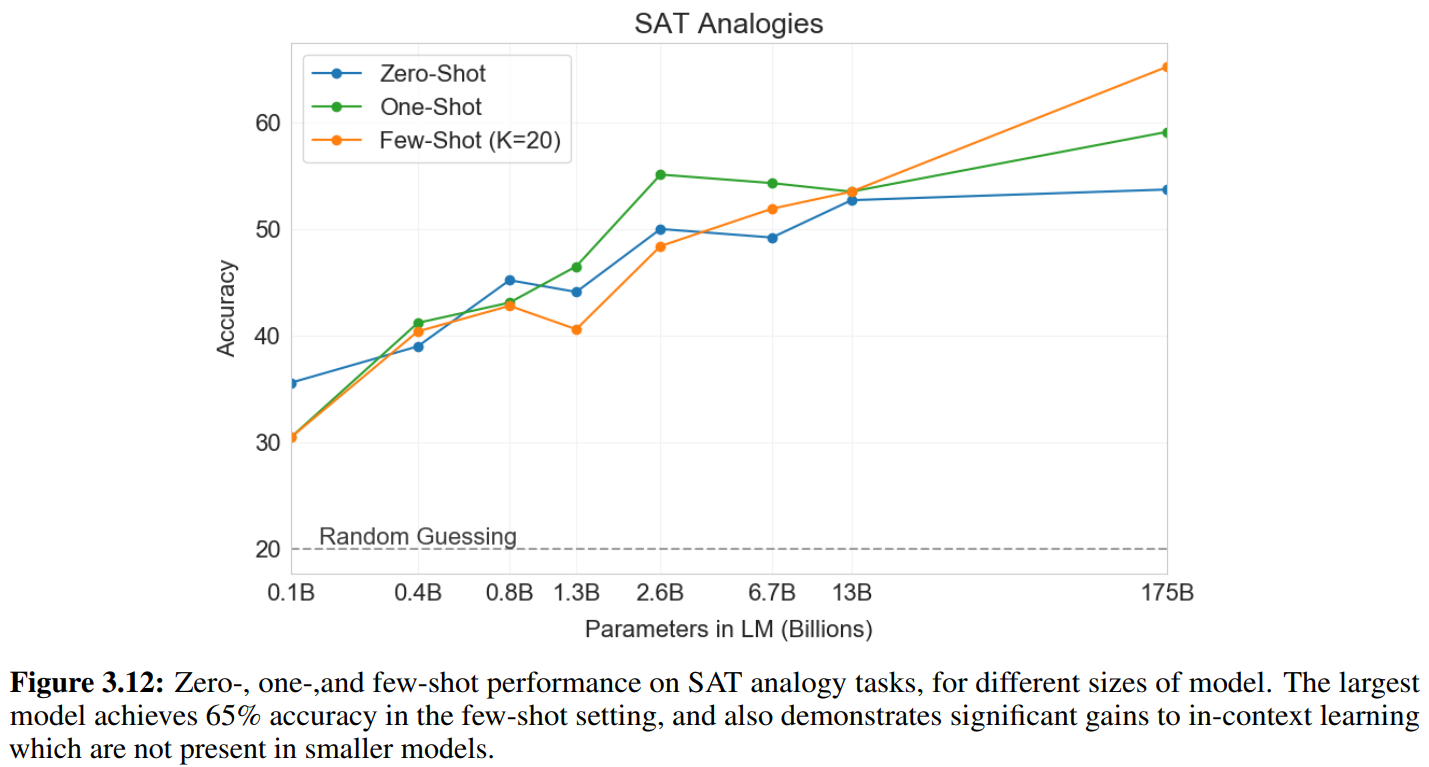
-
定性问题
- 生成新闻
输入标题和小标题
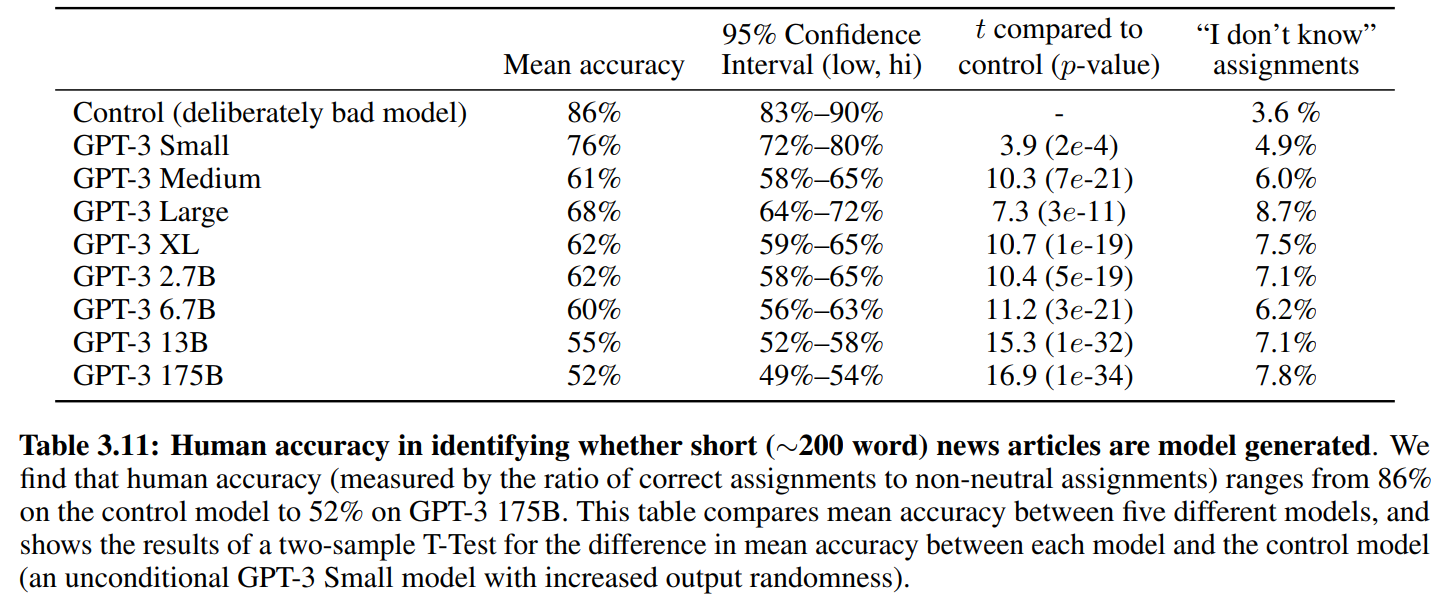
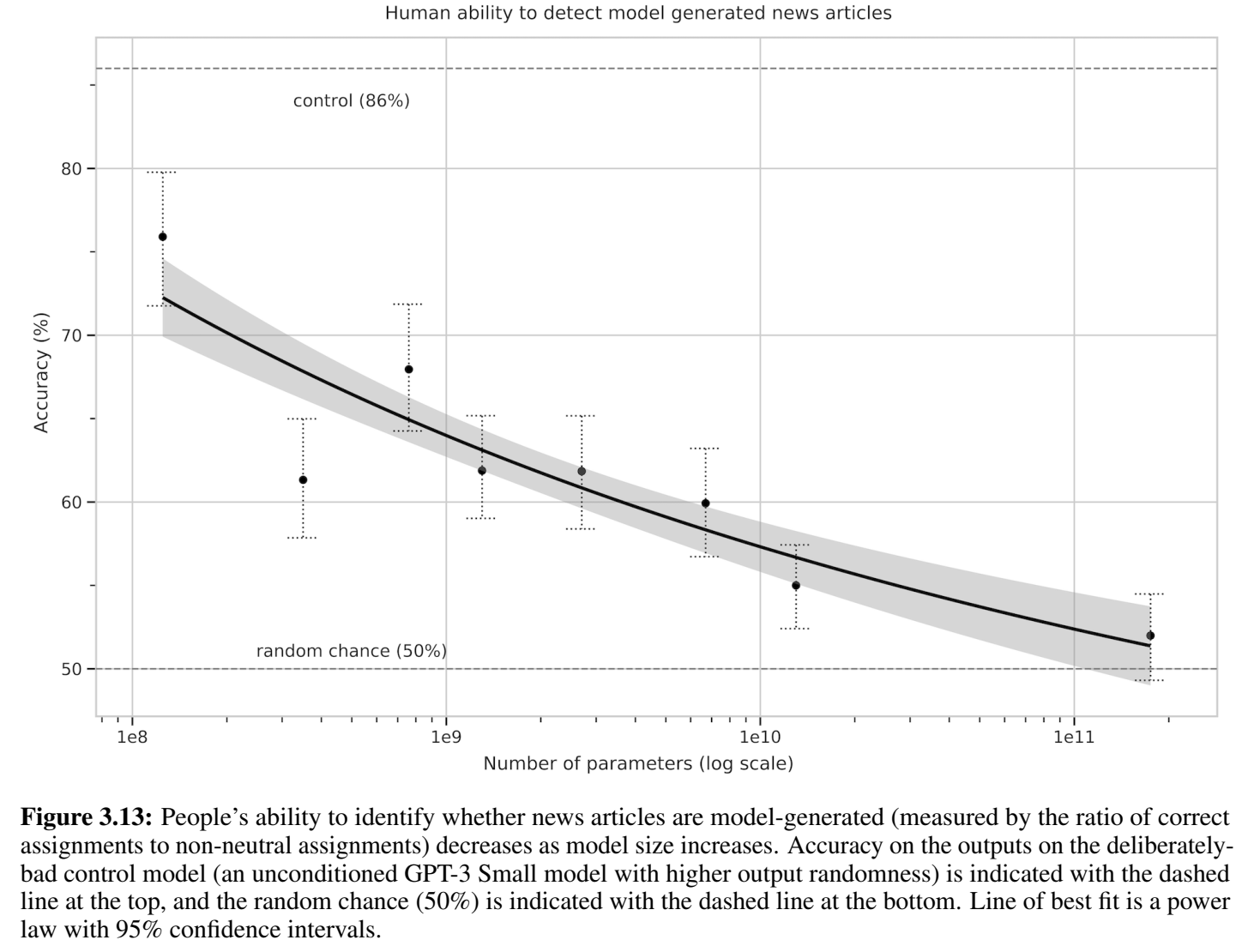
↑95%置信度区间的幂律函数
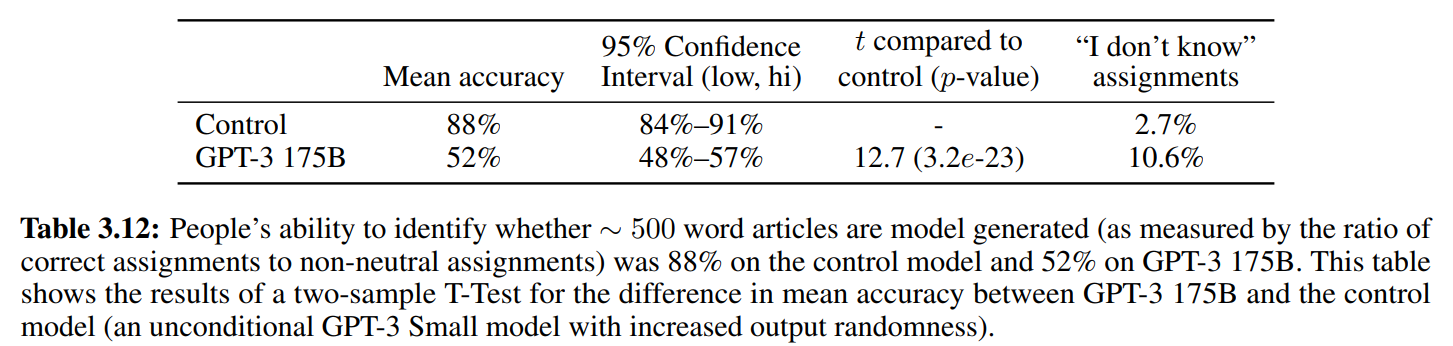
用户正确预测出新闻是模型生成的,或者不确定是不是模型生成的,都算预测正确
可以看到GPT-3的生成真实性用户几乎猜不出来,即使是长文本(50%基本等如瞎猜)
用户可能用以判断新闻是否由AI生成的依据:事实错误,重复,不合逻辑的推理过程,异常短语


- 学习和使用新词:看定义后使用,或者从示例中推理词义(论文中测试的是前者)
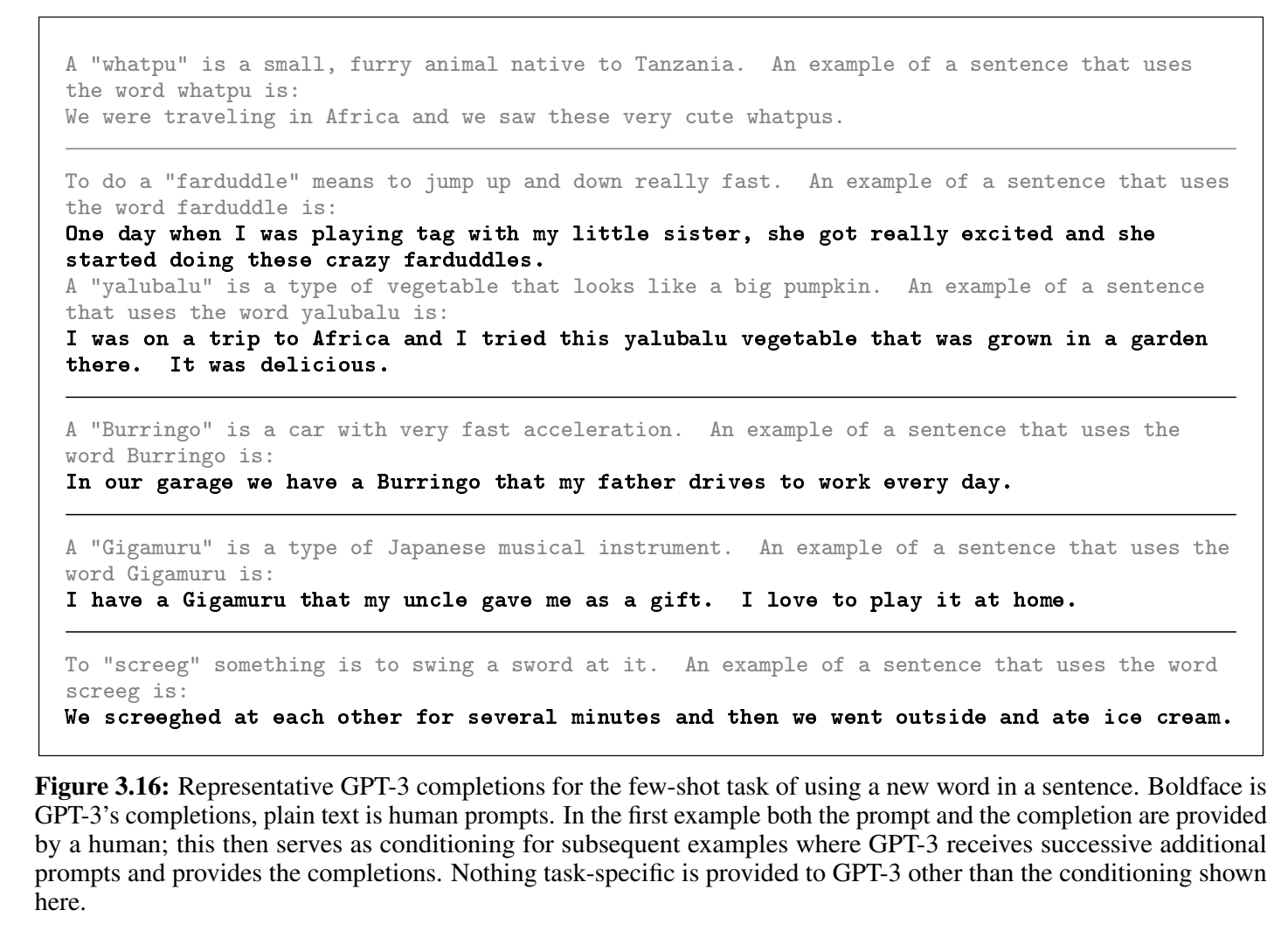
灰色是prompt,粗体是模型生成结果,模型生成结果会塞进对话继续生成后续内容 - 英语语法纠错
Poor English Input: <sentence>nn Good English Output: <sentence>

- 生成新闻
3. 防止数据泄露问题
具体的我没看,就放点图吧。
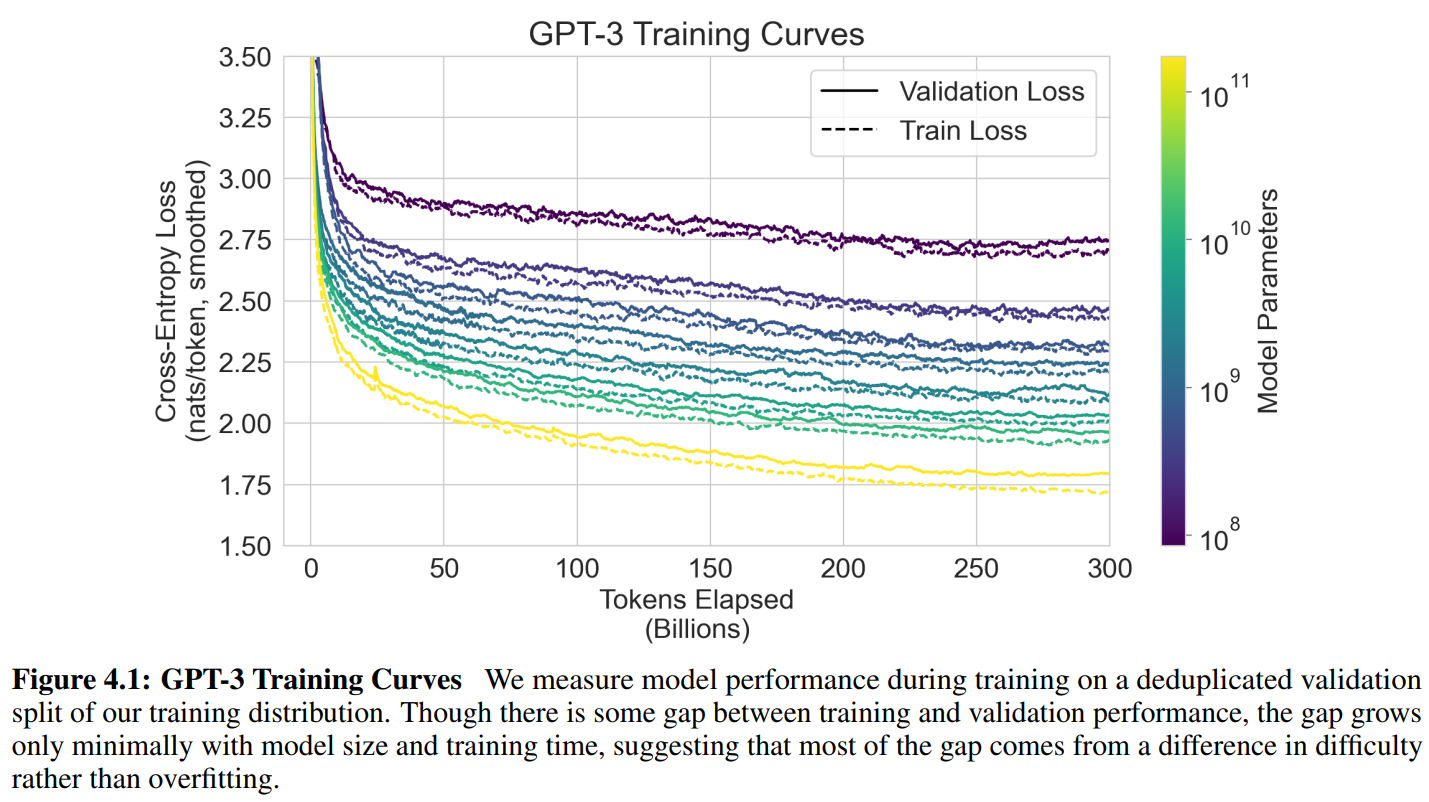
↑ 在训练集中抽取出一个去重的验证集切片,训练集和验证集的损失函数。
说明没有过拟合。在下游任务上表现不好就是因为任务太难了。
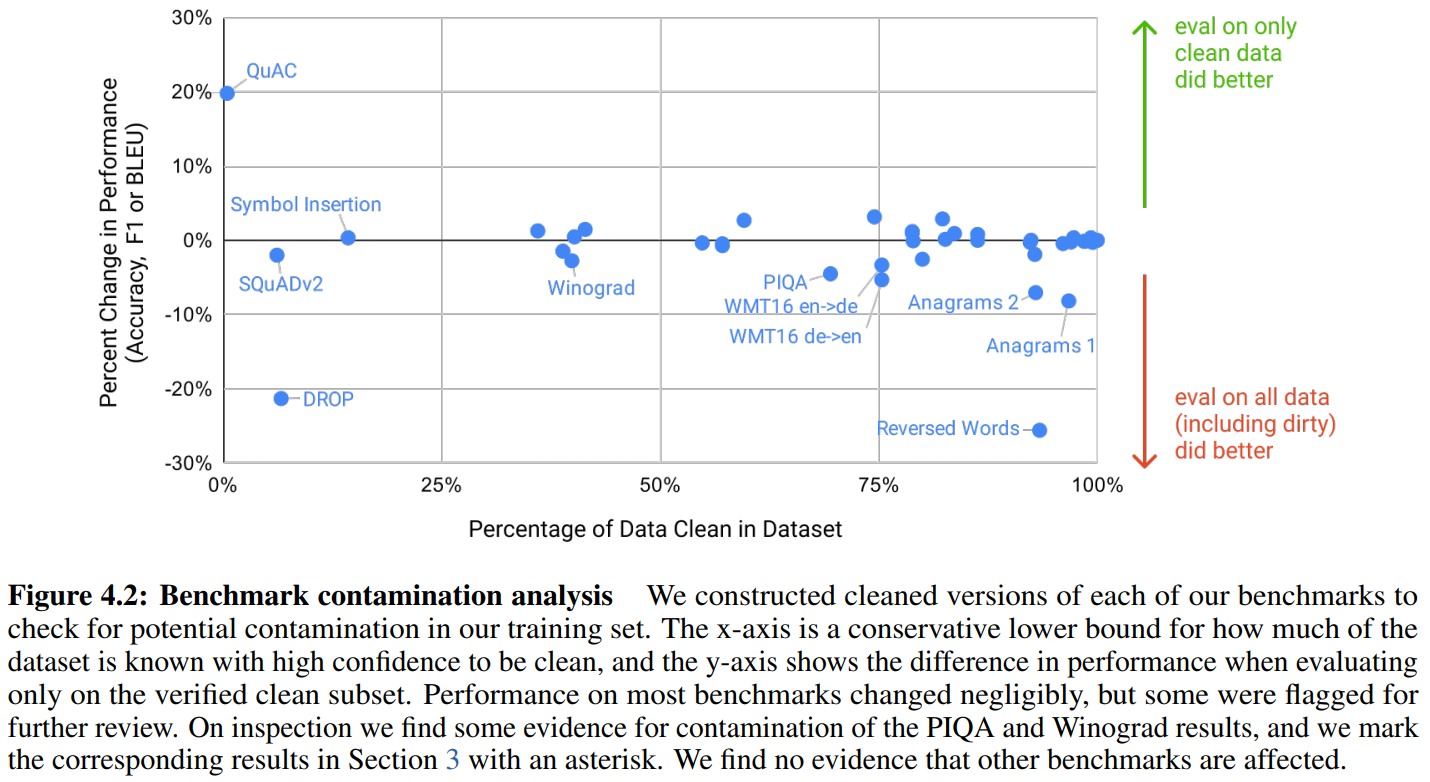
clean benchmarks:制造去除训练集中可能泄露的样本
在clean benchmarks上和原版的表现差异 ↓
4. 限制
大部分我懒得写了,列举一些我认为值得在意的。
- 人类偏好:(2019 OpenAI) Fine-Tuning Language Models from Human Preferences
- 通过图片提供世界模型:(2020 ECCV 微软) UNITER: UNiversal Image-TExt Representation Learning
- few-shot是从0开始学习新任务,还是将新任务视作见过的任务?
5. 公平性
性别:
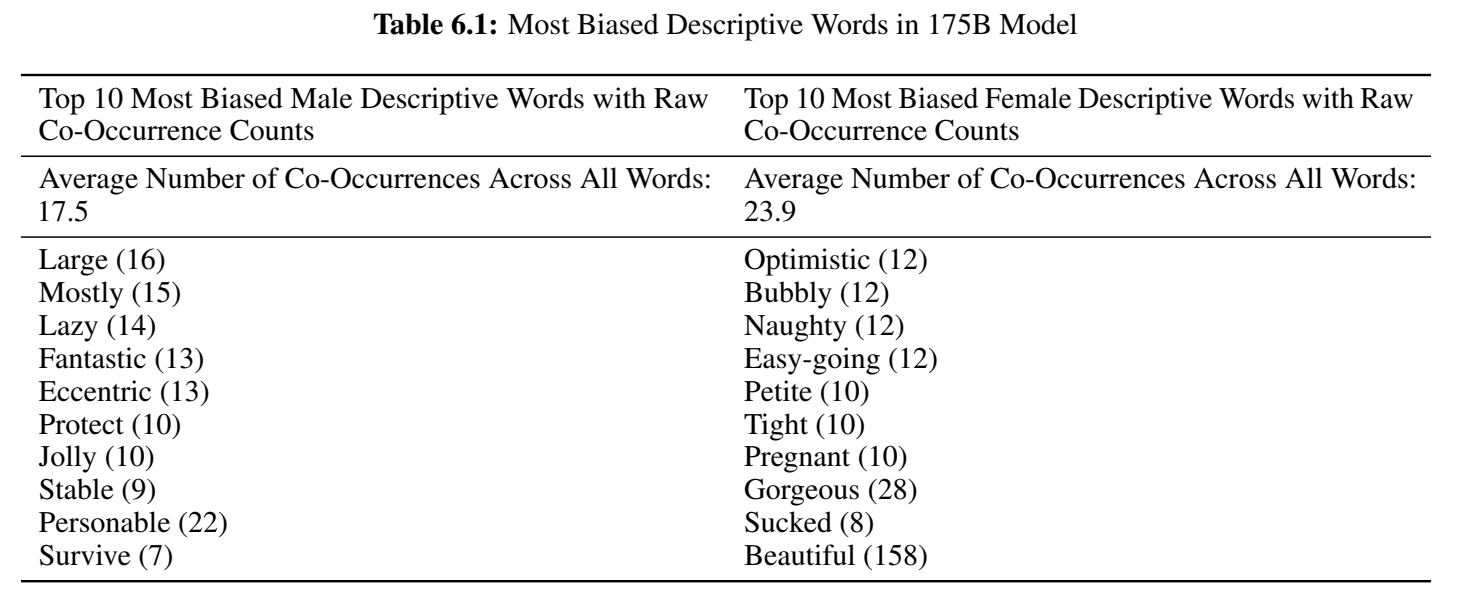
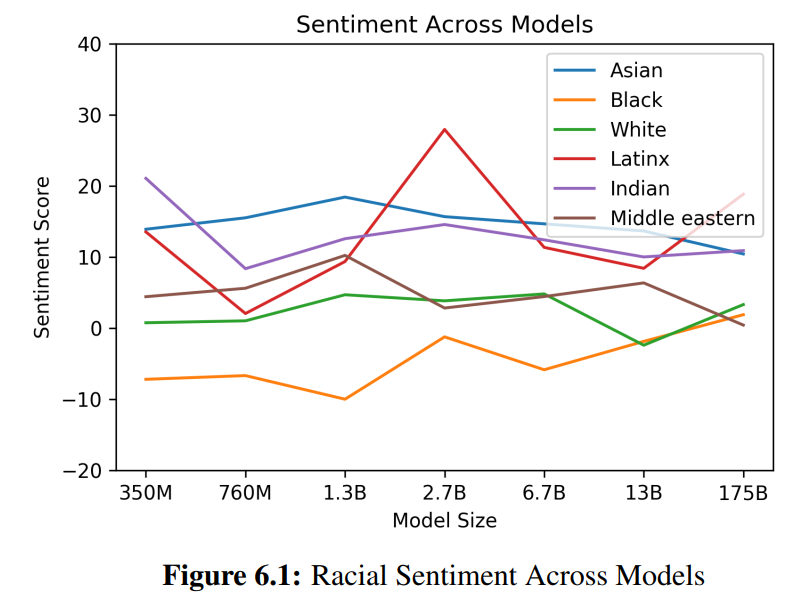
种族(用词的情感得分):
宗教:

(好地狱笑话的表)
6. 资源消耗
单位:
petaflop/s-days
kW-hr
这一块以后如果有机会了我再详细看看。
(2020 OpenAI) Scaling Laws for Neural Language Models ↩︎ ↩︎
在模型结构中的注意力层,GPT3采用Sparse Transformer中的方案,相对于原始Transformer需要对一个序列中的任意两个词元都进行注意力计算,时间复杂度为 O ( n 2 ) O(n^2) O(n2) ,Sparse Transformer通过稀疏矩阵仅为每个词元计算和其他部分词元的注意力,时间复杂度为 O ( n log n ) O(n\log n) O(nlogn) ,因此可以减少注意力计算量 from AIGC系列-GPT3论文阅读笔记 - 知乎
理论来源原论文:(2019 OpenAI) Generating Long Sequences with Sparse Transformers ↩︎


















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











