







诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
官方GitHub项目:https://github.com/google-research/text-to-text-transfer-transformer
README看起来介绍得还蛮详细的。但是现在一般都是用transformers包来调用T5吧,应该不会用TensorFlow和谷歌原生t5包了。
实践相关的代码我以后应该也会发的。
本文是谷歌2020年JMLR(Journal of Machine Learning Research)的论文,本文提出了seq2seq预训练模型T5。
T5(Text-to-Text Transfer Transformer)的特点是将各种NLP任务都视为seq2seq任务(之前有工作将各种任务统一视为QA、LM或span extraction任务,但是关注重点不太一样,见论文第9页的分析,略。LM就是指GPT-21),在一个巨大的模型上进行预训练(在当时已经很大了),这样就能用同样的模型架构来实现各种任务了。
T5的范式也是预训练+微调,属于迁移学习领域的工作。
输入文本格式是prefix input_text,prefix用来区别不同的任务,格式↓
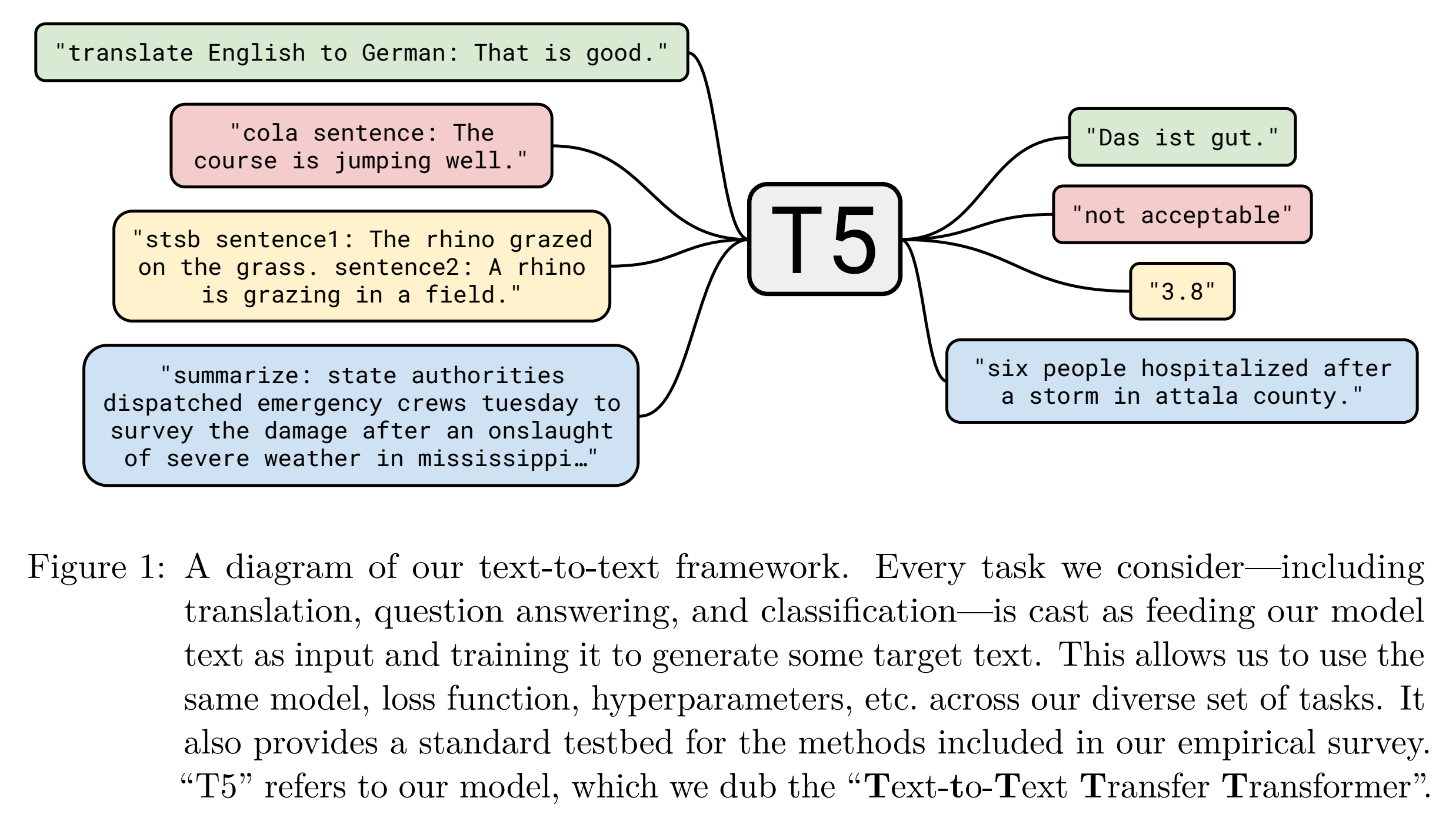
此外本文还提出了英语大规模无监督预训练数据集C4数据集(Colossal Clean Crawled Corpus)。除了C4外,T5还用了有监督数据来进行预训练,数据混合技术是example-proportional mixing
由于谷歌is so fucking有钱,所以本文事实上概括性地调研和对比了几乎所有当时的LM方案……可以当综述看。
STS-B是回归任务,所以对输出进行了recast(以0.2为单位进行分箱,将1-5范围之外的输出都视作错误输出)
指代消歧任务在需要消歧的代词前后加了*
因为C4数据集我感觉用不着,所以就不写那部分的笔记了。总之C4是一个清洗得很干净的数据集(去重标准是三句连续重复),实验也证明清洗干净对LM效果提升有好处。
还有很多理论和实验细节我就也不写了,如果需要用到我再来详补。
1. T5模型
相比原始Transformer模型,主要修改之处:
- 简化layer normalization:仅rescale激活函数,不应用additive bias
- 在layer normalization后增加residual skip connection,即将输入加到输出
- 在FFN、skip connection、注意力权重、每一stack的输入和输出上都加dropout
- 位置编码为relative position embeddings2:编码的不是绝对位置而是自注意力中K和Q的相对偏移
T5中仅用标量来编码,在计算注意力权重时加到logit上
位置编码权重在层间共享
T5一共学32个位置表征,最远偏移为128。这意味着某一层token是感觉不到距离超过128的token的,但是在随后就可以间接感应到(因为局部信息加上前层信息,就扩散开了)
这部分改动没做消融实验(就算是土豪谷歌也不可能真的全做吧)
在预训练和微调时,数据输入输出格式都是文本到文本,是统一的。为了标明任务,在输入文本前会加上task-specific (text) prefix(在别的论文里也会叫成prompt。反正大家应该都知道这些词是什么了,我觉得混用也无所谓,应该不会引起很大的歧义吧)
预训练的denoising目标:输入和输出是同一句话的不同部分。用sentinel tokens(<X><Y><Z>)隔开每一个连续块3(<X><Y><Z>分别是不同的表征,不像BERT的<MASK>是一样的)

(最终用的是长度为3的span)
在预训练时,损失函数是最大似然,用teacher forcing4+交叉熵损失函数,优化器是AdaFactor5,使用“inverse square root” learning rate schedule(详情略),最长序列长度为512,batch size为128
微调时学习率为0.001,每5000个step保留一次checkpoint,最终使用验证集上指标最高的checkpoint来汇报结果(在多任务上微调的模型,就分别汇报每个任务上指标最高的checkpoint)
测试时用greedy decoding。但是输出序列长时,用beam search效果更好
T5模型本来的词表就只有那几个拉丁和罗曼语系的,所以不支持中文。mT5是支持中文的。
综述
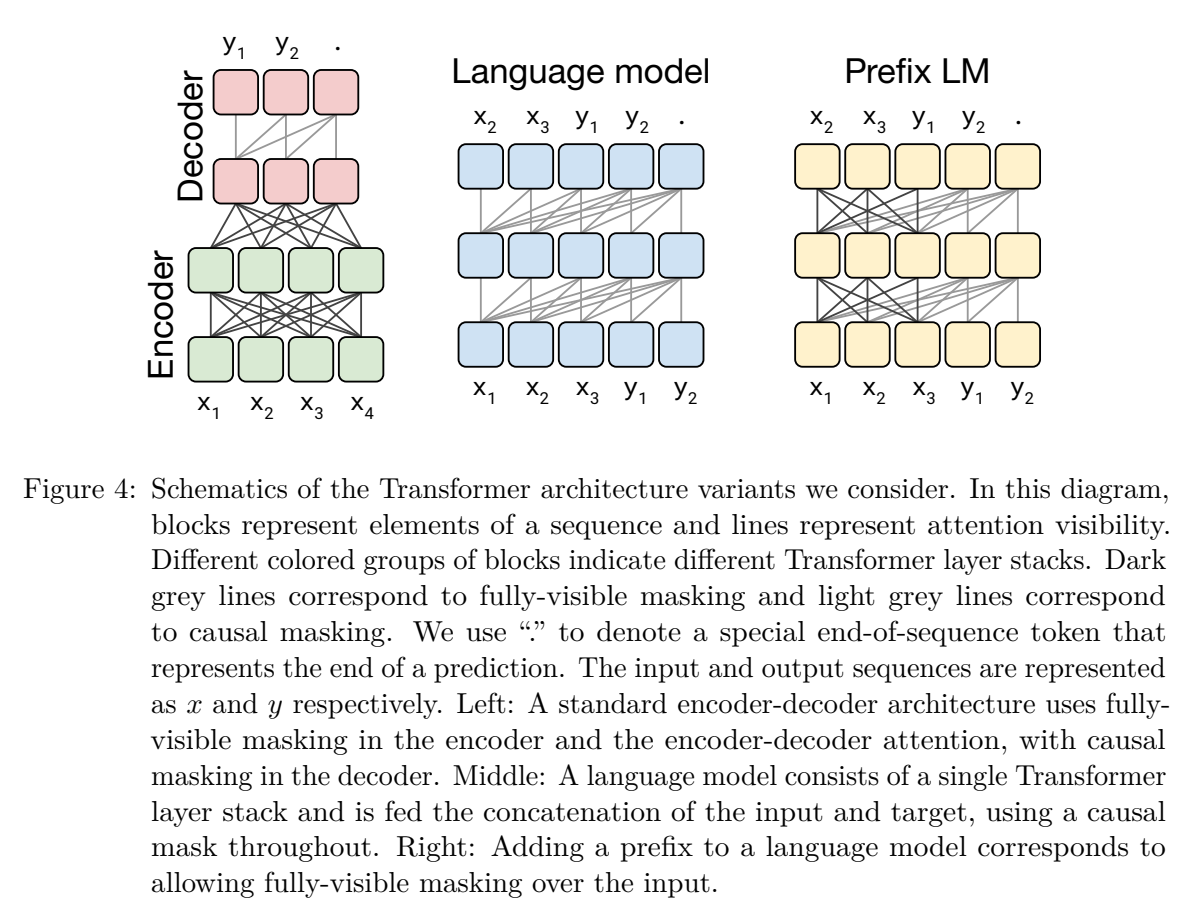
mask patterns:

Transformer架构变体:
2. 有监督数据输入输出格式:用prefix
实验发现修改这个prefix影响较小。(我觉得这正常啊,因为在下游任务上微调过啊,都微调了,这玩意儿还能有啥影响。LLM零样本推理对prompt依赖很强是因为没有微调过吧,所以需要教,需要循循善诱,都微调过了就不需要了吧)
翻译:translate English to German:
文本分类根据标签类型来写prefix,如NLI任务:mnli (如果出现了非标签集中的结果,应该直接判定为预测错误。但本文提到,在训练好的模型中没有遇见过这种情况)
更多详情见附录D。(WNLI数据集的特殊处理方式见附录B)
3. 实验
附录E有所有实验的结果,看起来可炫酷了……
本文通过coordinate ascent方法来实验不同组件的效果,因为combinatorial exploration代价太高了。
coordinate ascent大概就可以理解为控制变量,别的条件不动,只改变某一条件,查看该条件造成的影响。
coordinate ascent坐标上升法比较标准的解释是:每次通过更新函数中的一维,通过多次的迭代以达到优化函数的目的。详情以后再看吧。可参考:优化算法——坐标上升法-CSDN博客
combinatorial exploration大概就是同时优化多个条件的意思。
In future work, we expect it could be fruitful to more thoroughly consider combinations of the approaches we study. 在新的优化算法出现之前估计都不可能了,谁都不可能有那么多钱摁造啊……
T5 baseline在下游任务上的平均表现:
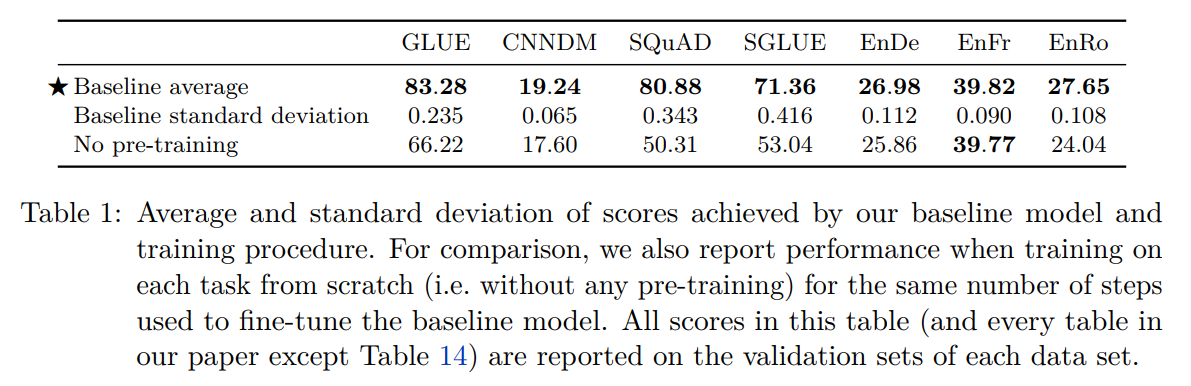
↑ 标准差比较大的都是低资源数据集。在低资源数据集上容易过拟合
不同架构和预训练目标的对比实验结果:
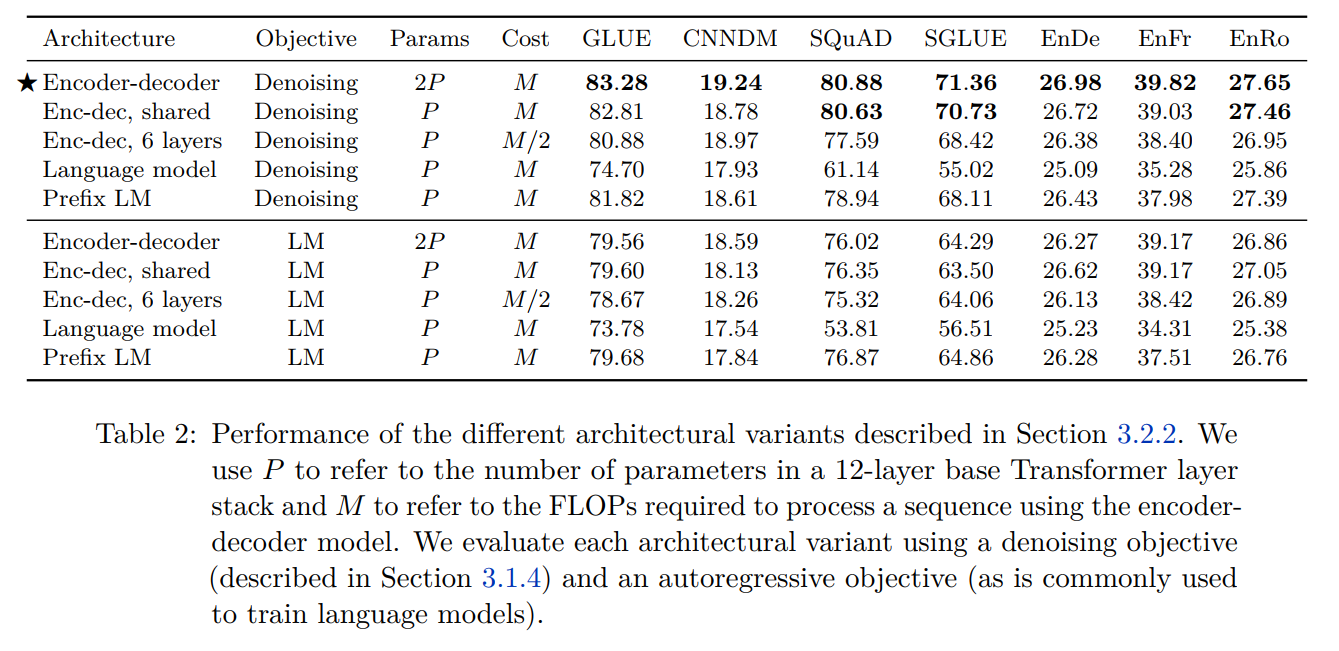
不同预训练目标的形式:
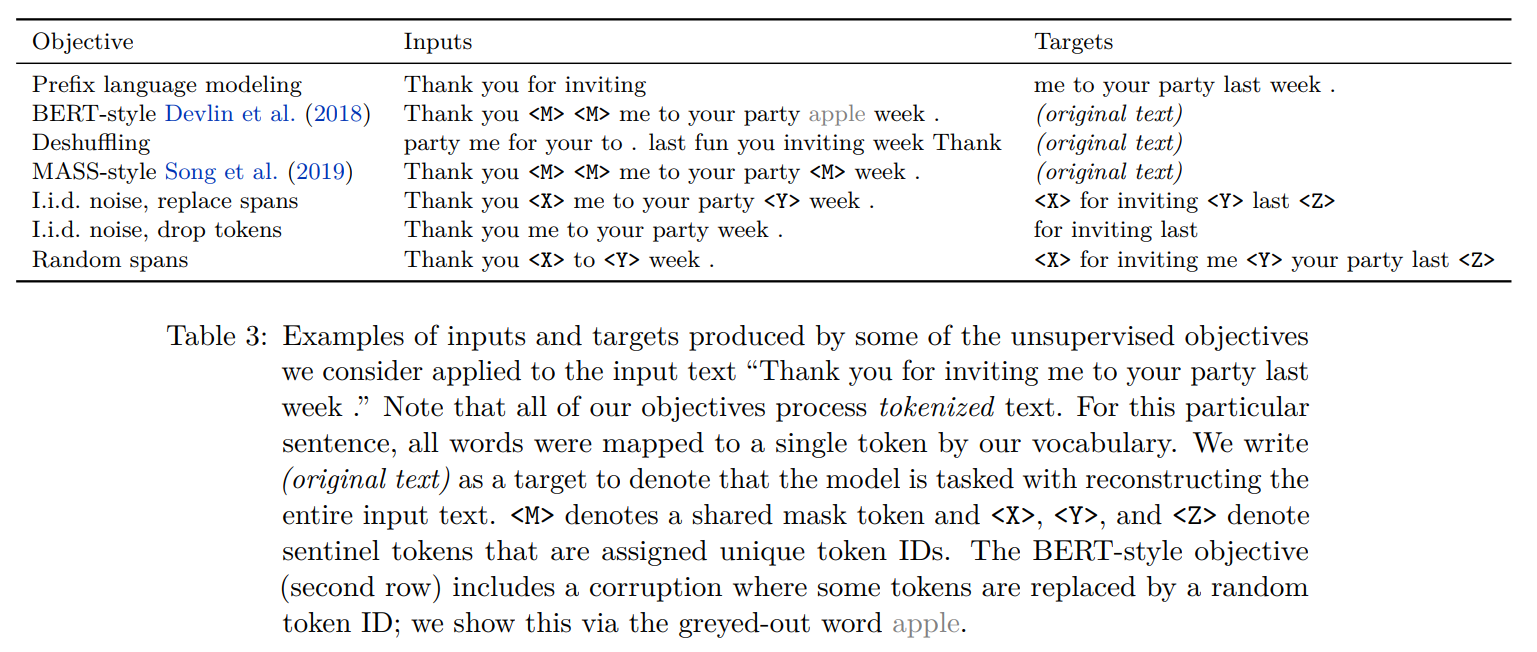
不同预训练目标下的对比实验结果: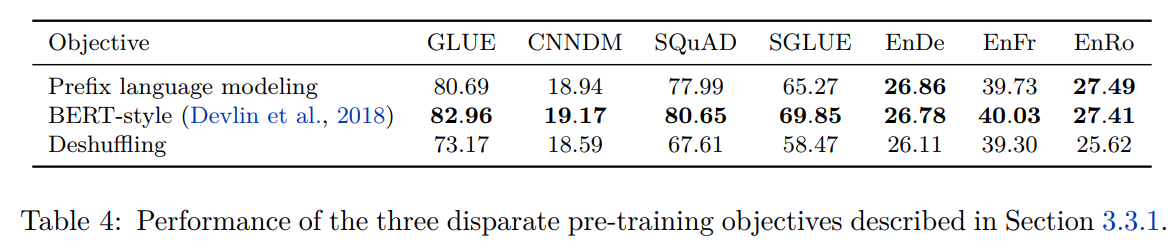
BERT / MASS / 仅预测corrupted tokens 几种变体的结果(目标:通过预测更短的target来加速训练):
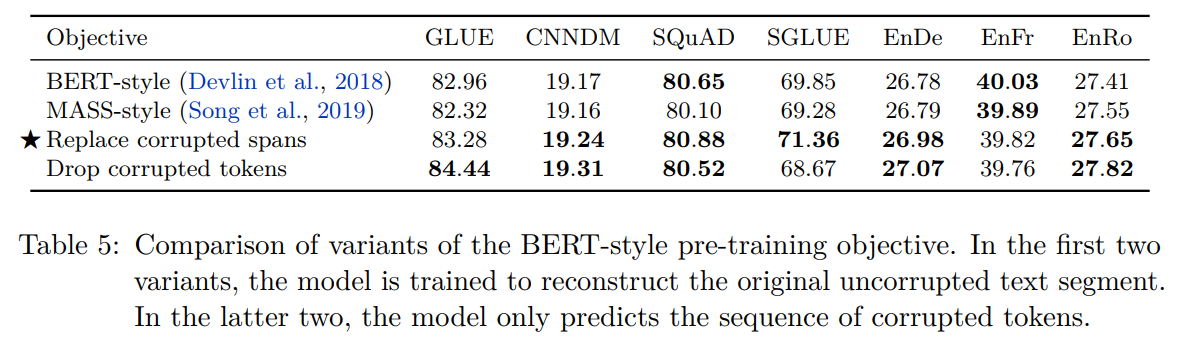
其实replace方法没有明显的优势,但是总之以后就在这个变体上做实验了
测试不同corruption率上的差异:
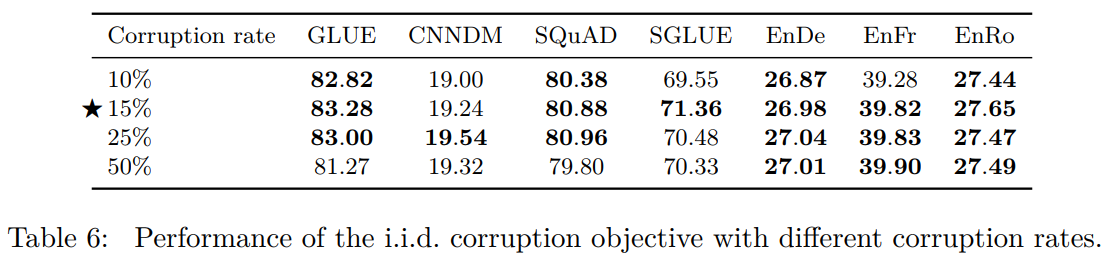
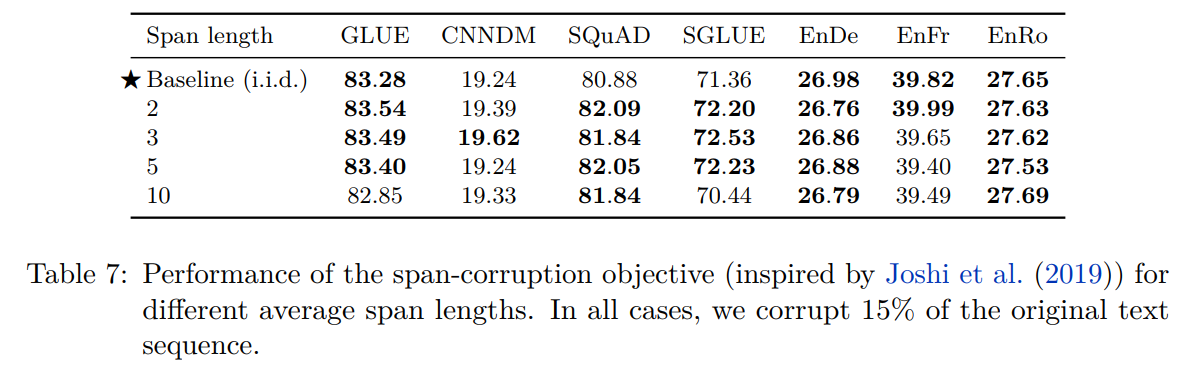
测试不同span长度的影响:
不同数据集上训练T5 baseline的效果:
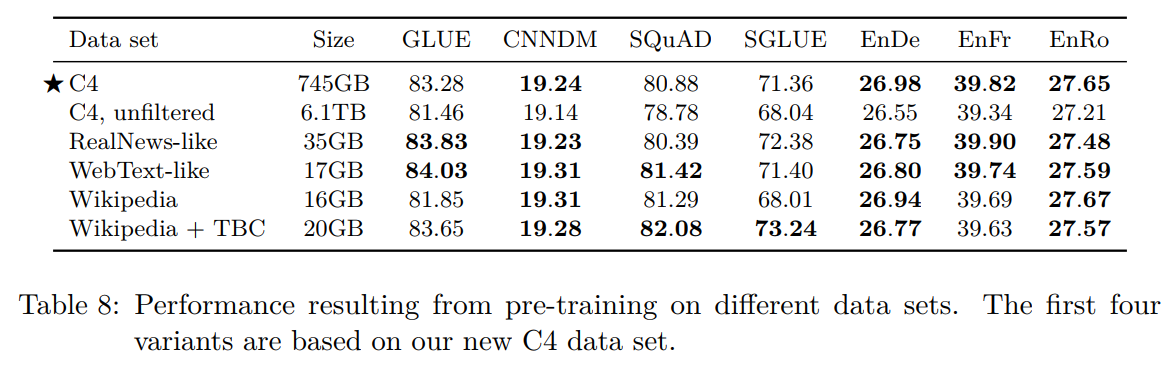
在同领域的数据上预训练可以提高下游任务的指标
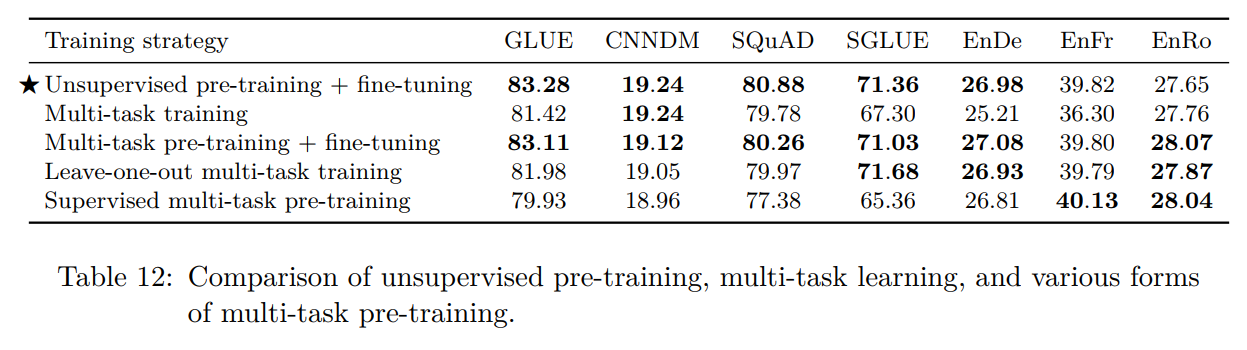
在预训练数据集上重复训练,会不会对结果造成影响:(保证总的训练token数相同,但是训练集和重复次数有改变)
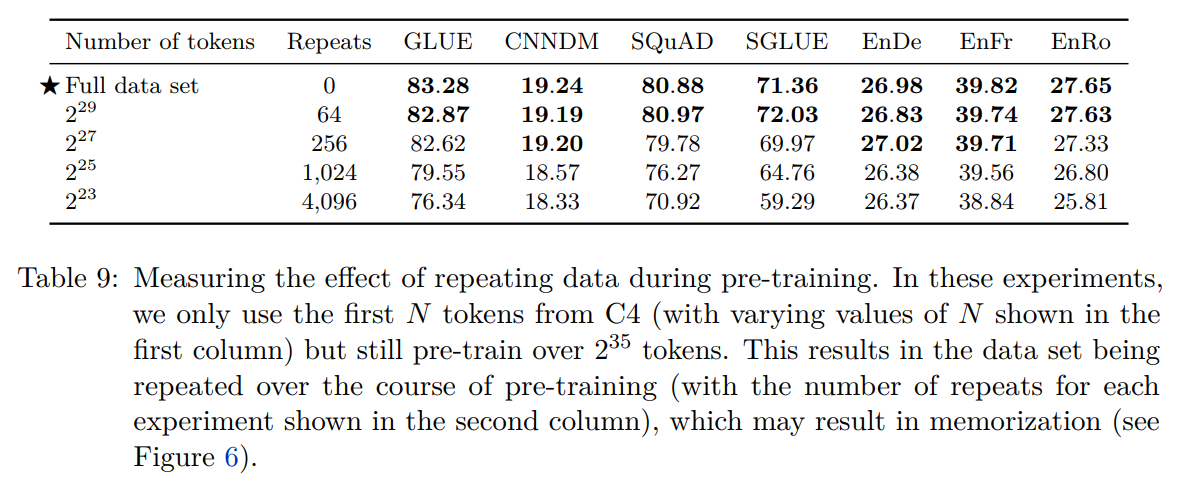
我们怀疑重复太多次会导致模型记住训练集中的信息,可以看到损失函数下降到了特别低的程度:
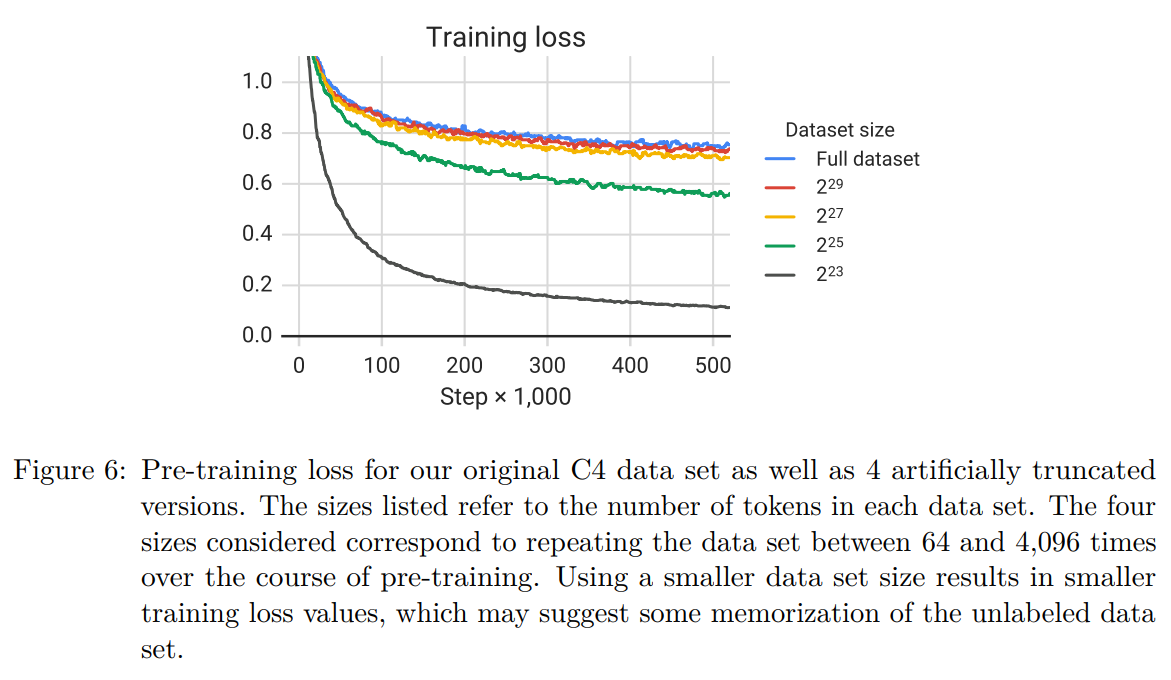
微调部分参数的尝试:① adapter layers ② gradual unfreezing
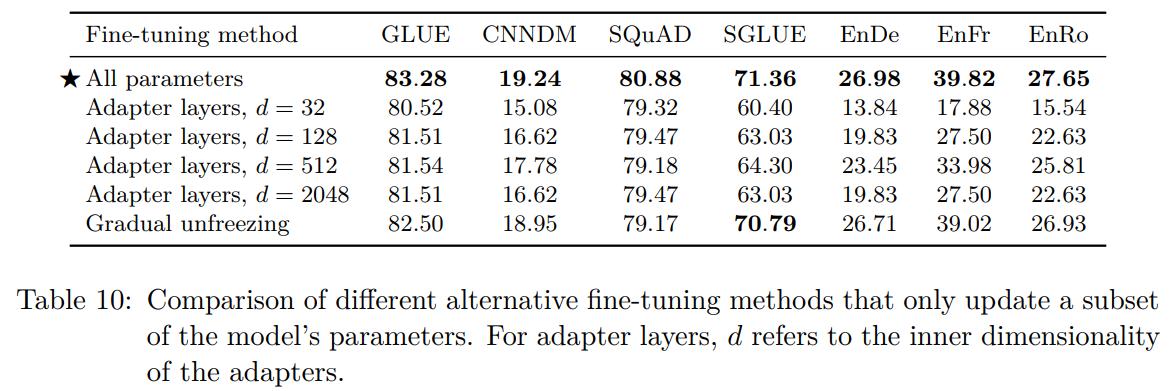
多任务学习(在多个数据集上训练)不如预训练-微调范式:
使用不同数据采样策略的结果:(K是数据集大小上限)
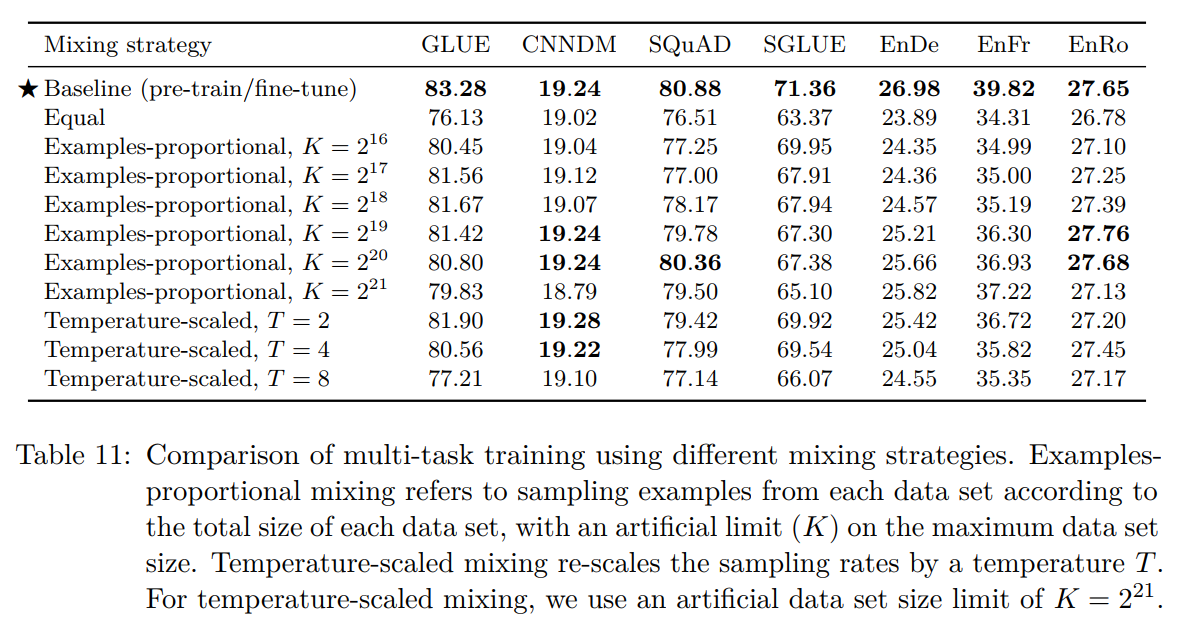
多任务学习范式预训练,单任务微调:
scaling的效果:(效果更好,代价更高)
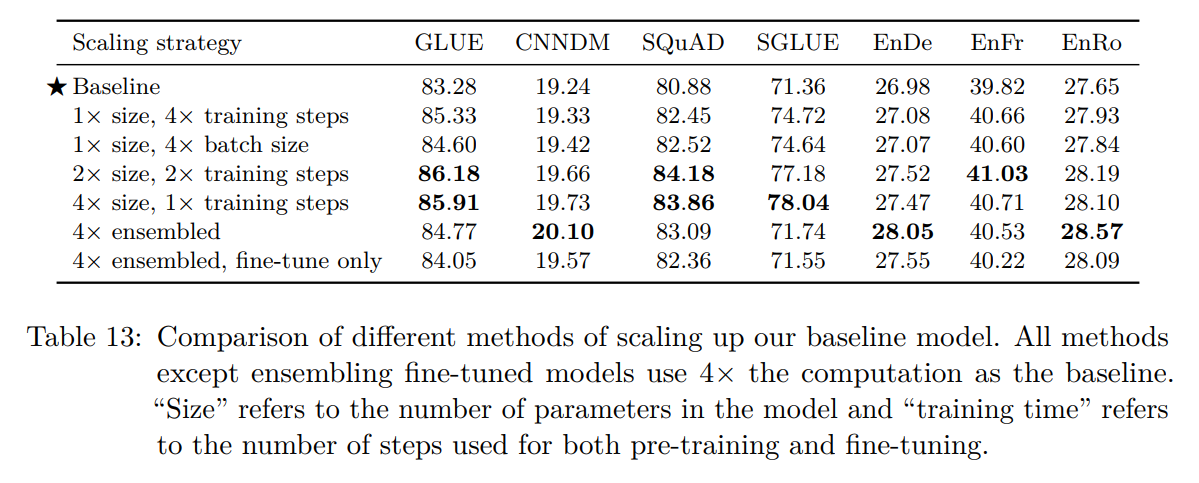
T5最大的变体有11B,其实已经到达随后开始爆发的大模型的入门尺寸了。
T5模型最终的实验结果:
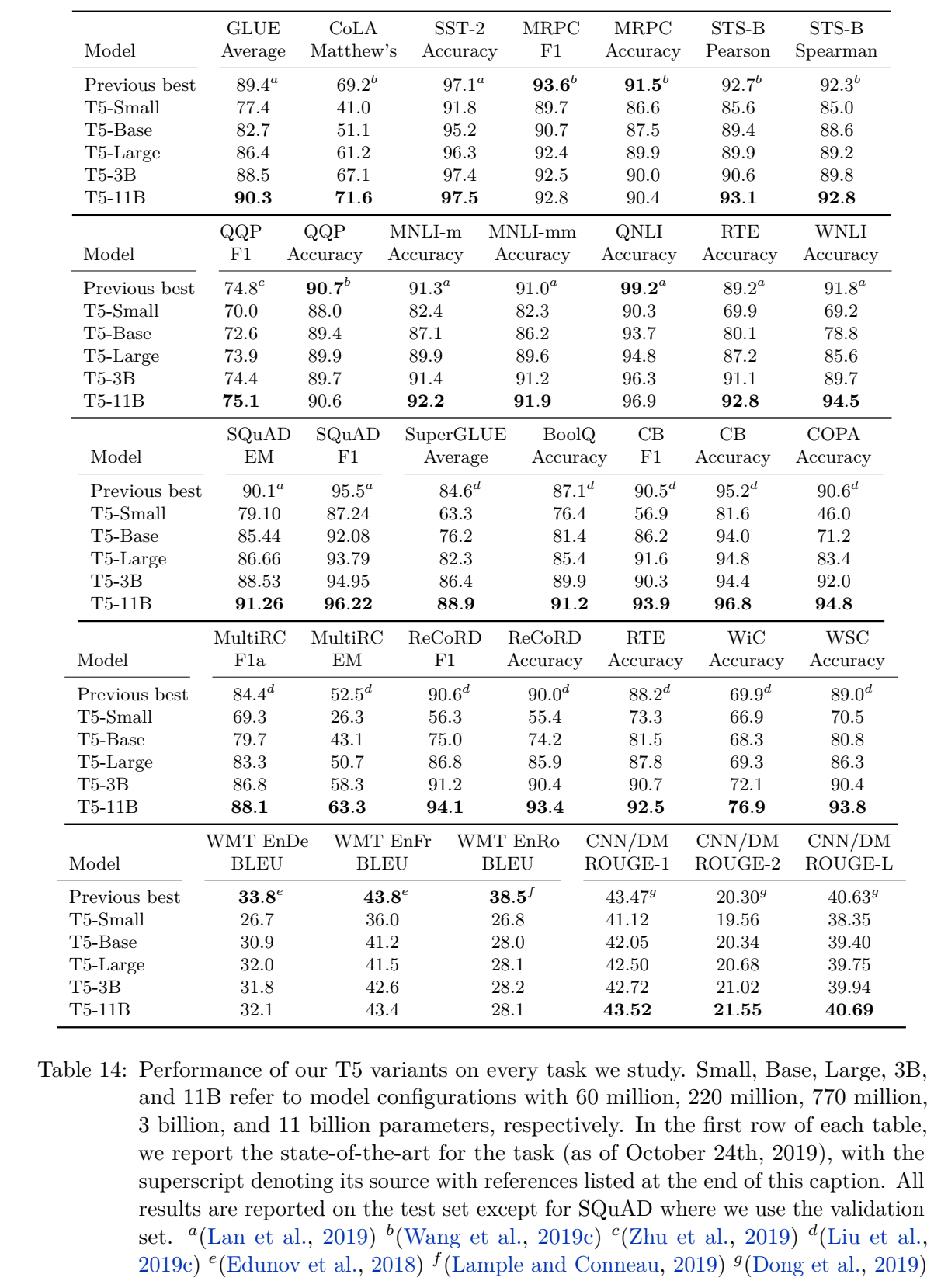
翻译任务上效果差可能是因为T5的无标签数据只有英语。
消融实验:
在T5-Base上扩大baseline预训练时使用的数据量:
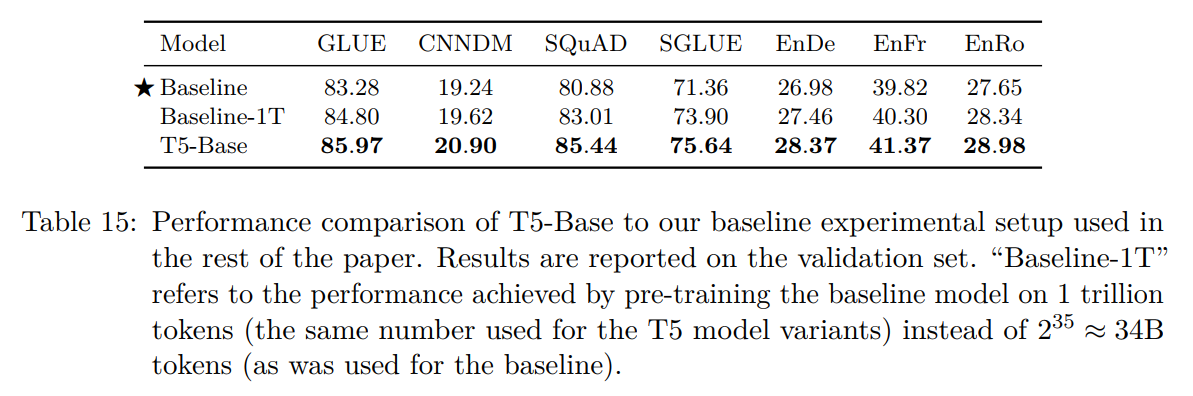
说明模型大更重要
(2019 OpenAI) Re62:读论文 GPT-2 Language Models are Unsupervised Multitask Learners ↩︎
Self-attention with relative position representations
Music transformer: Generating music with long-term structure ↩︎文中在这里说这种技术参考了“word dropout” regularization technique的思路。这一技术的参考文献是(2016 CoNLL) Generating Sentences from a Continuous Space
详情略,这篇论文通过VAE实现句子生成,提出了 Word Dropout和无历史解码(Word Dropout and Historyless Decoding) 的技术:在训练期间,解码器预测每个词,条件是前一个真实的词。通过随机将一些词标记替换为通用的未知词标记“unk”,迫使模型依赖潜在变量 z ⃗ \vec{z} z 来进行良好的预测。这种技术是word dropout的一种变体,它不是应用于特征提取器,而是应用于解码器。参数由保留率 k ∈ [ 0 , 1 ] k \in [0, 1] k∈[0,1] 控制。当 k = 0 k = 0 k=0 时,解码器不依赖任何输入,只能依赖到目前为止产生的词数,从而极大地限制了模型可以建模的分布类型。
Word Dropout技术与机器学习中的dropout正则化技术相似,但专门用于文本生成任务。它通过在训练过程中随机丢弃(即不使用)一部分输入词,迫使模型不能过分依赖于局部的上下文信息,而是更多地利用潜在变量来生成句子。这样,模型学会生成更加多样化和富有信息的句子。
我的理解就是,这差不多就是MLM
其他参考资料:neural network - The meaning of random word dropout in NLP - Data Science Stack Exchange ↩︎A learning algorithm for continually running fully recurrent neural networks ↩︎
Adafactor: Adaptive learning rates with sublinear memory cost ↩︎
















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











