







系列文章目录
HBase基础理解
什么是HBase
HBase是一个非关系型的分布式数据库, 非关系型是因为其存储的数据为Key-Value的格式, 且多半不支持SQL语句, 分布式则是其能够在多个节点上存储数据, 数据库则是其具有一套自己的增删改查以及数据读写服务的数据管理系统.
HBase与Hive的区别
HBase与Hive有三个重要的区别:
- 是否支持数据细粒度实时在线的增删改查操作
- HBase其支持对字段中的记录进行修改操作, 但是Hive不支持, 如果要对字段进行修改只能进行批量操作
- 是否有自己特定的数据存储组织结构(文件格式)
- HBase有自己的数据结构存储方式, 即HFile, 但是Hive则可以读取不同种格式的内容(orc, parquet, sequence)
- 是否有特定的数据读写服务
- HBase其通过自己进行数据读写, 但是Hive通过配置来进行数据读写(MR, Spark, Flink)
总的来说, 两者本质上就是并不相同的两个东西, 所以并不能进行比较.
HBase的使用场景
-
数据分析的底层存储: HBase可以将数据存储在其内部, 然后通过使用一套API实现数据的分析与计算, 但是整体分析操作过于笨重, 因此可以做但是并不适合, 这种情况下Hive的适用性就比较高.
-
业务的底层数据库: 由于HBase可以进行分布式布置, 因此其可以支持高并发低延迟的随机点查, 因此可以用作用户画像场景.
HBase基础要点
HBase的集群架构
HBase本身的架构比较简单, 仅仅有两个角色一个是Master, 另一个是Region Server.
Master主要用于对元数据进行管理以及统筹RegionServer, 实现负载均衡
Region Server主要用于对具体的数据进行增删改查操作
Region Server的内部具有HAL Log, 多个Region, 其中每个Region中有多个Store, 每个Store中有一个memstore以及多个StoreFile, 而StoreFile达到阈值时就会变成HFile写入到HDFS中
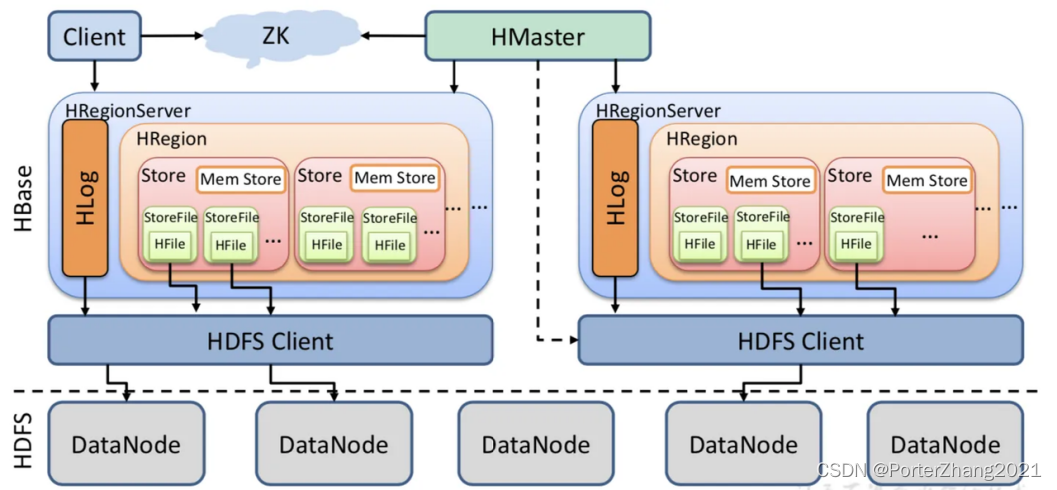
HBase的基本存储结构
HBase的数据种类
HBase的数据有四类:
- 元数据
- WAL预写日志
- 状态数据
- 表数据(用户表以及系统表)
HBase表数据的存储结构
HBase表数据的物理存储结构是:数据库根目录/名称空间目录/表目录/Region目录/列族目录/HFile文件
最小的负载服务单元: Region
最小的物理存储单元:一个Region中的列族
HBase表的微观存储结构
HBase的微观存储结构由Key-Value构成, 其中Key是由rowkey, family , quilifer 三部分构成, 并按照字典顺序排序, value则是存储数据的值
HFlie的构成
HFile是HBase的底层数据存储文件, 其内部最主要的部分就是三个不同的block, 分别是
- data block: 这个部分存储的是数据文件
- index block: 这个部分存储的是数据索引, 其中数据索引具有三级(根索引, 中间索引以及叶子索引)
- tariliter block: 这个部分则是记录其他block在文件当中的偏移量
HBase的数据API的操作方式
bulkload数据导入与客户端put数据
在HBase中, 如果我们需要写入数据有两种办法, 一种是put数据, 一种是bulkloader数据导入
- put数据操作
put数据操作将数据先发送到RegionServer上, RegionServer收到数据将数据写入到内存的memstore中, 到达阈值后, 将数据以Hfile的格式写入到HDFS中 - bulkload数据导入操作
将源数据通过其他计算引擎读取加工输出成hfile文件后, 将hfile文件通过bulkloader导入到HBase对应表的目中当中, 然后由HBase通知Master更新相关的元数据信息, 读取到我们需要的数据.
HBase关键要点
HBase的数据多版本机制
HBase数据库对于其数据底层并不进行实时的删除修改操作, 其对数据的增删改查操作使用的是增量插入的操作, 对每一次新的操作都会有一个版本以及操作标记, 因此当我们进行数据查询的时候, HBase会查询现在数据信息以及其邻近的版本信息, 通过这个机制让其在底层能够很好的在HDFS上进行数据的保存, 满足HDFS设计的(一次写多次读操作).
Region的分裂机制
Region分裂机制的产生背景是为了减轻RegionServer的负载压力, 具体来说就是HBase随着时间不断产生大量的增量数据, 而一个Region只能由一个RegionServer进行管理, 此时单个Region大量的读写操作, 给此RegionServer造成了负载压力, 因此为了减轻此RegionServer的负载压力, 就需要将Region分成多个Region, 交给不同的RegionServer管理, 来减少负载压力, 形成新一轮的负载均衡.
如何进行Region的分裂
- 创建两个新的Region, 通过RegionServer将信息报给Master进行元数据信息的注册
- 此时在HDFS中生成两个新的Region目录, 对原来老的Region当中的文件链接到两个新的Region中
- 当链接完成后, RegionServer将信息报给Master, 此时两个新的Region会标记为上线状态, 而老的Region则标记为下线状态
- 当触发Region Compact操作时, 此时会将老Region当中内容转移重写到新的Region当中, 并彻底删除老Region的目录
预分区
预分区的目的是为了避免初期表的读写操作产生热点问题以及降低Region分裂频率的一种手段, 当我们创建一张表如果没有对其进行预分区操作, 此时该表就只有一个Region, 也就是会说所有的数据都只会交给一个RegionServer进行管理, 随着时间的增加, 该表的数据会越来越多, 而此RegionServer承载的压力也会越来越大产生热点问题, 同时这个时候也会触发Region的分裂机制, 但是如果初期我们就对其做好预分区, 那么多个Region就可以由多个RegionServer进行管理, 避免了初期表读写操作可能会产生的热点问题, 并且也降低了Region分裂的频率.
Region Compact机制
Region Compact机制的主要目的是为了解决HBase的数据冗余问题, 随着时间的增加, HBase内部会拥有越来越多的HFile文件以及多版本的数据记录造成大量的冗余, 这个时候就需要进行合并, 将一些冗余数据清除,以及一些标记删除的数据删除, 重写新的HFile.
对于Region Compact, HBase有两种Compact机制:
- minor Compact
minor Compact又称小合并, 其主要是讲一些小的HFile文件合并成一个大的Hfile文件, 其并不会对HFile文件进行重写, 属于轻量级的操作, 可以让HBase自己进行执行. - major Compact
major Compact又称大合并, 其会将HFile文件逐一放入到内存中, 对无用数据进行清理, 然后重写一个HFile文件, 这种操作通常非常耗时, 也很占用资源, 因此一般需要手动操作.
RowKey的设计要点
RowKey的设计主要是与其使用场景有关, 如果我们需要避免热点问题, 那么此时的RowKey设计就需要能够尽可能打散, 而如果我们需要大量的过滤查询, 那么此时RowKey的设计就需要我们能够尽可能设置的比较连续.
热点问题是什么?
热点问题是数据读写操作总是命中在某一个或者某几个RegionServer上, 导致某几个RegionServer负载过大,而其他RegionServer上负载过小, 出现负载不均匀的问题
出现热点问题的三要素:
- HBase底层的数据存储规律
- RowKey的设计
- 数据读写操作
行键与读写效率问题
如果读写需求是高频小量的随机读写, 此时数据越分散越好, 避免热点问题
如果读写需求是低频按过滤条件进行范围扫描查询, 将数据连续存放在一起, 更好满足需求
行键的设计
设计行键主要还是根据上面说到的使用场景有关系, 不同场景下行键的设计方式是不一样的:
-
避免热点问题的行键设计操作
- 将行键进行翻转
- 为行键进行加盐, 这里需要注意的是如果对行键进行加盐, 我们要考虑到后续数据的读取问题, 因此比较好的加盐方式就是利用行键进行编码, 然后取编码的前n位与行键拼接, 这样我们就能够在后续能够查询到行键的数据.
- 用定值减业务作为行键
-
提高查询效率的行键设计操作
根据查询条件的规律, 将查询字段值按照条件使用频率进行拼接, 形成行键
底层数据的读写流程
读数据流程
客户端到RegionServer
- 客户端到ZooKeeper上查询Meta表所在的RegionServer
- 请求Meta表所在的ReionServer, 查询目标所要读取的数据所在的Region以及Region所在的服务器
- 请求Region服务器读取数据
RegionServer内部操作
- RegionServer内部构建MemStore扫描器以及HFile扫描器准备对数据进行查询
- MemStore扫描器查询Region当中的Memstore获取查询到的数据
- HFile扫描器则是通过对内存中的StoreFile对象获取布隆过滤器, 先进行排除, 将不需要的内容先排除掉
- 然后HFile扫描器通过StoreFile对象中存储的HFile文件当中的三级索引, 先从根索引找到中间索引, 然后由中间索引找到叶子索引, 最后找到data block位置
- 此时查看DataCache中是否由对应的data lock, 如果有那么直接从DataCache中拿去, 如果没有, 就通过data block的位置获取查询数据
- 最终将MemStore扫描器与HFile扫描器获取的数据返回给客户端
写数据流程
客户端请求ZooKeeper找到Meta表并获取Meta表信息, 确定当前要写入数据所对应的RegionServer服务器和Region
客户端将数据写入到对应RegionServer, RegionServer收到请求并响应, 此时RegionServer先将数据写入到预写日志, 防止丢失
同时RegionServer将数据写到对应的memstore当中
当两个部分同时写入完成, 此时一次写入请求就算完成了
当中还有几个异步操作
flush: 其中当memstore达到阈值, 就会写入到HFile然后存入到HDFS中
compact: 当HFile文件过多就会进行触发Region Compact操作
split: 同样当一个Region过大的时候就会触发Region的分裂机制
关于MemCache以及BlockCache的理解
- 读取数据是否需要读取MemCache当中的数据
需要读取当中的数据, 最终读取的数据, 是由多个数据来源当中, 找到最近的几个版本号的数据返回 - 如果MemCache中读到目标行键数据, 是否就不需要从HFile中寻找?
不是, 只是找到了其中行键数据当中的某个版本的数据, 是否是最新数据不清楚 - 最新的数据不都是先写到MemCache中, 然后再flush到HFile中, 怎么会出现HFile中的数据版本比MemCache的还要新
这个问题设计到HBase的数据写入操作, HBase的数据写入有多种方式 , 我们可以通过put命令进行数据的写入, 同样也可以通过api进行数据的写入, 这两种机制是一样的, 但是利用bulkloader进行导入时, 此时是从其他计算引擎当中将数据文件转成HFile后, 通过bulkloader导入到底层的HDFS当中, 然后由HBase获取数据, 这种情况下, HFile文件内的数据, 可能会比MemCache新. - 如果读数据的时候, 从BlockCache中读到了目标数据, 是否还需要去HFile中寻找?
需要, 因为只是再Block Cache中拿到了某一块的DataBlock, 并不是拿到了读取数据所有的DataBlock, 因此对于在范围内的HFile还是需要进行搜索的.
HBase进阶要点
跳表
LSM Tree
其他
参考资料
- 多易教育: 多易教育














 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









