






前言
在【数据结构】二叉树的遍历中,我们学习了二叉树的遍历,并通过动图演示加深了印象。在文章最后,我提到了二叉树的其他操作,列如求二叉树的节点个数等,这些操作采用的算法思想并非遍历,而是分治。本文将为你介绍二叉树的分治。
一、分治与遍历的区别
分治和遍历都是算法设计中常见的策略,但它们的思想和应用方式略有不同。
分治算法将一个大问题划分为若干个相似但规模更小的子问题,递归求解这些子问题,然后再将子问题的解合并起来得到原问题的解。分治算法通常适用于可分割、可并行、可复用的问题,如排序、查找、图像处理等。在分治中,我们将原问题分成若干个子问题,可以通过子问题的解来解决原问题。在二叉树中,我们可以将一个大的二叉树拆分为两个子树,然后将这些子树分别递归处理,最后将它们的结果合并起来。
遍历是一种数据结构上的操作,通常用于访问树中的所有节点。遍历适用于需要遍历整个数据结构的问题,如打印树中所有节点、对树中的所有节点进行操作等。遍历有多种不同的方式,比如前序遍历、中序遍历和后序遍历等。在二叉树中,我们可以通过遍历方式来访问所有节点,对每个节点进行必要的操作,比如寻找最大节点或计算节点的深度等。遍历在处理问题时通常需要遍历所有节点,效率可能会比分治算法低,但对于某些问题,我们必须遍历整个数据结构来获得所需的信息。
总结:
- 分治的核心是将一个大问题划分为若干个相似但规模更小的子问题。
- 遍历的核心是按照某种顺序访问数据结构中的每个元素。
二者容易弄浑的地方是分治通常也要访问到每个元素,这往往让人分辨不清。
下面我们在实践运用中予以解释。
二、二叉树其他操作的实现
这是一颗手动创建的树,以它为例进行演示
typedef int BTDataType;
typedef struct BinaryTreeNode//Binary 意思为 二叉,二进制
{
BTDataType val;
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
}BTNode;
BTNode* BuyNode(int x) {
BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));
assert(newnode);
newnode->val = x;
newnode->left = NULL;
newnode->right = NULL;
return newnode;
}
BTNode* CreatBinaryTree()
{
BTNode* node1 = BuyNode(1);
BTNode* node2 = BuyNode(2);
BTNode* node3 = BuyNode(3);
BTNode* node4 = BuyNode(4);
BTNode* node5 = BuyNode(5);
BTNode* node6 = BuyNode(6);
node1->left = node2;
node1->right = node4;
node2->left = node3;
node4->left = node5;
node4->right = node6;
return node1;
}
int main(void) {
BTNode* root = CreatBinaryTree();
}
// 二叉树节点个数
int TreeSize(BTNode* root);
// 二叉树第k层节点个数
int TreeLevelKSize(BTNode* root, int k);
// 二叉树查找值为x的节点
BTNode* TreeFind(BTNode* root, BTDataType x);
2.1 二叉树的节点个数
要想知道二叉树的节点个数,我们需要访问二叉树的每个节点。
- 遇到非NULL,size+1;
- 遇到NULL,返回0;
看到访问二叉树的每个节点,不要想当然的认为就是遍历,对于这个问题,我们采用的是分治的算法思想。上文提到,分治的核心在于将大问题分解成若干个小问题,那我们该如何进行分解呢?
为了方便理解,我们为一颗树的节点赋予身份,如下。
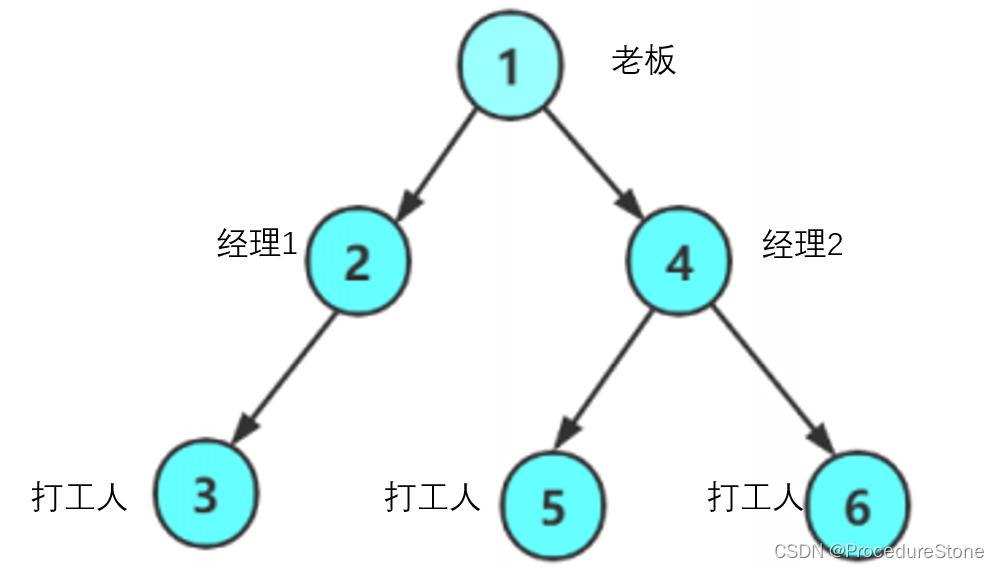
现在老板想知道自家公司有多少人(即求节点个数),他会怎么做?自己一个个去数?当然不会,身为老板,他会选择让经理去数。经理会自己一个个去数?当然也不会,他会让打工人去数。难到打工人会自己一个个去数?是的,他只能自己去数,然后将结果报给经理,经理再将结果报给老板。
看到这,我想你已经知道如何去分割问题了。老板要想知道公司人数,只需知道自己下面有多少经理,再让经理汇报各经理下面的人数就ok了。于是我们采用递归这种编程技巧,就可以写出以下代码:
int TreeSize(BTNode* root) {
return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
//节点为NULL,返回0,不为空,返回左子树的节点个数 + 右子树的节点个数 + 自己
}
同理,下面的函数也可以这样去理解。
2.2 求数的高度
根节点要求左子树报告自身高度记为leftheight, 要求右子树报告自身高度记为rightheight,找出二者的最大值 + 1(根节点的高度)就是二叉树的高度了。至于左子树如何知道自身高度,根节点不用关心,递归会给出答案。
int TreeHeight(BTNode* root) {
if (root == NULL) {
return 0;
}
int leftheight = TreeHeight(root->left);
int rightheight = TreeHeight(root->right);
return leftheight > rightheight ? leftheight + 1 : rightheight + 1;
}
2.3 返回节点值为x
看根节点的值是否等于x
不等于,让根节点的左子树去找
左子树没有,让根节点的右子树去找
右子树也没有,返回NULL
至于左子树,右子树如何去找,根节点需要关心吗?不需要。这就将一个大问题划为了几个小问题。
BTNode* TreeNode(BTNode* root, BTDataType x) {
if (root == NULL) {
return NULL;
}
if (root->val == x) {
return root;
}
BTNode* lret = TreeNode(root->left, 3);
if (lret) {
return lret;
}
BTNode* rret = TreeNode(root->right, 3);
if (rret) {
return rret;
}
return NULL;
}
总结
二叉树的分治是一种常用的算法思想,它利用二叉树的递归结构,将复杂的问题分解为两个或多个相同或相似的子问题,然后递归地求解子问题,最后合并子问题的解得到原问题的解。二叉树的分治可以有效地降低时间复杂度和空间复杂度,提高算法的效率和可读性。二叉树的分治在许多领域都有广泛的应用,例如排序、搜索、动态规划、数据结构等。本文介绍了二叉树的分治的基本概念、原理和步骤,并通过几个典型的例题来展示二叉树的分治的应用和实现。希望本文能够对读者有所帮助和启发,也欢迎读者提出宝贵的意见和建议。















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









