







1.线程崩溃为什么不会引起JVM崩溃?
线程非法操作或访问内存会导致进程崩溃(进程下的多个线程共享代码段,文件,数据,内存等)
那进程是如何崩溃的? -信号量机制
kill pid -9 就是向目标进程发送了一个信号量 SIGKILL-对应9
如果自定义了信号量函数,可以再kill掉进程之前执行一些自定义方法
jvm正是自定义了信号量函数,如发生NPE或者stackoverflow时,JMV做了额外的内部处理,并将日志写入特定文件比如hs_err.log中
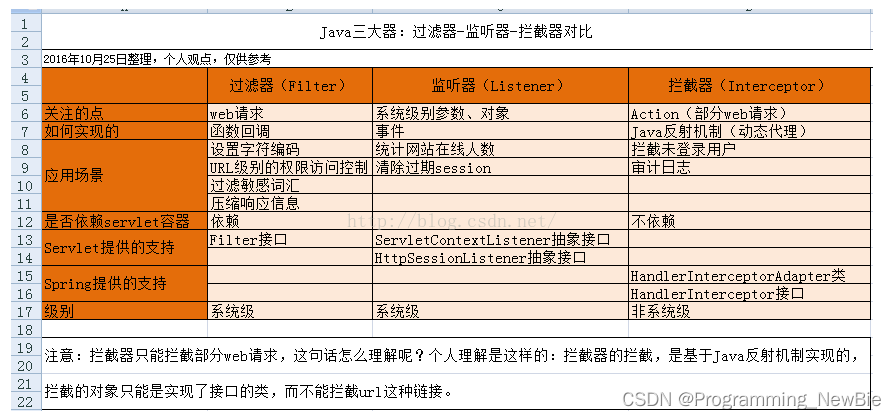
2.Java三大器
1.过滤器(基于函数回调):一般用于资源访问权限控制(比如部分静态资源请求可以过滤不做验证)、敏感词汇过滤
2.拦截器(基于java反射机制,动态代理):实现HandlerInterceptor接口或者继承HandlerInterceptorAdapter方法
应用:用户登录认证、权限验证等
过滤器与拦截器、切面执行顺序验证
-> 过滤器doFilter -> 前置拦截器preHandle
-> 环绕通知@Around开始 -> 前置通知@Before
-> UserController
-> 环绕通知@Around执行 ->环绕通知@Around结束
-> 后置通知@After -> 后置返回通知@AfterReturning
-> 处理拦截器postHandle -> 后置拦截器afterCompletion
3.监听器(基于事件):依赖于servletContextListener接口或HttpSessionListener抽象依赖接口
应用场景:清除过期session、统计网站在线人数
区别:
1.在Action的生命周期中,拦截器可以多次调用,而过滤器只能在容器初始化时调用一次。
2.拦截器是基于java反射机制来实现的,而过滤器是基于函数回调来实现的。
3.数据库慢查询原因 转载地址:盘点数据库慢查询的12个原因_倾听铃的声的博客-CSDN博客_慢查询。
第一类SQL写法原因原因:
1.没有用到索引(隐式类型转换、使用or、使用< >等符号、未遵守索引最左匹配原则、使用“%”开头的like通配符、索引列上使用内置聚合函数(加上聚合函数会导致mysql不知道如何搜索)、对索引列使用运算符号 +-*\ (和使用聚合函数同理)、左右连接的字符编码不一致),或者字段未创建索引
第二类MySql数据库原因:
1.被表锁、行锁锁住了
2.limit深分页问题
例子:
select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;
上述语句中limit 10000,10执行步骤:首先通过create_time索引字段查询到id后回表查询得到100010个数据后抛弃前10000行去最后10行。
limit深分页,导致SQL变慢原因有两个:
limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。也就是说limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。
limit 100000,10 扫描更多的行数,也意味着回表更多的次数。
解决办法:延迟关联法(就是把条件转移到主键索引,减少回表。)
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;
3.数据量过大,B+树过深,读取较多次数IO,影响效率
4.刷新脏页
更新语句执行步骤
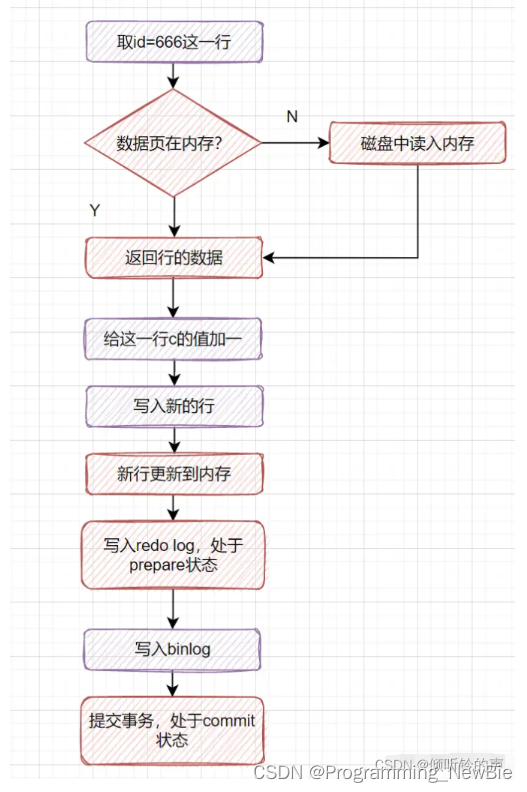
rodo_log:
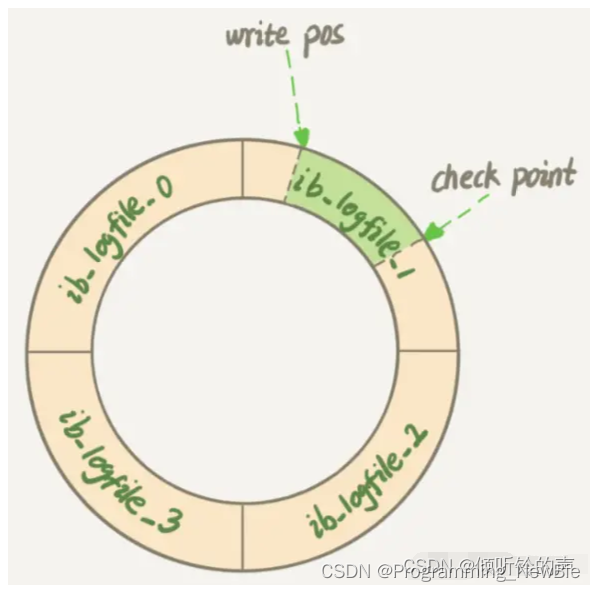
更新语句暂时更新到内存和redo log中,等数据库空闲时再更新到磁盘里,因此会出现脏页(内存和数据库数据不一致)。如果内存不够用,或者redo_log满了,导致数据库刷新脏页(刷新脏页时导致查询和更新性能降低)
扩展:为什么要二阶段提交(将redo_log分成两阶段,一个prepare和commit阶段,中间穿插着写入binglog日志操作)?
未使用二阶段提交,先写redo_log后写binglog:比如数据库在写redo_log日志时crash了,没有及时写入binglog,此时数据库恢复时redo_log会记录保存这个修改,而后续使用binglog备份或者恢复临时库时,这次更新修改不会记录下来,这样就出现了脏数据。
二阶段提交:写redo_log prepare状态->写入binglog日志->写入 redo_log commit状态,此时写入binglog后crash了,数据库恢复时由于不是commit状态,不保存修改,这样后续使用binglog日志恢复时不会出现脏数据。
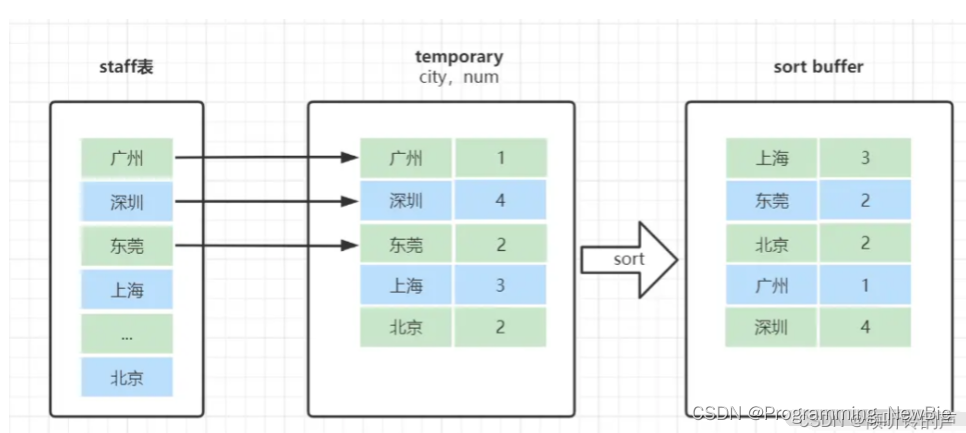
4.order by 文件排序(一般利用到sort_buffer, 首先找到无序结果集,单独将排序的字段和主键放入缓存,进行排序,后回表取出结果集)
rowid排序:当数据行超过排序缓存字段最大值时
全字段排序:和rowid相比,无需排序后的回表(因为未超过排序字段允许的最大值,所以不需要单独对排序字段进行排序)
且sort_buffer_size过小会借助磁盘进行排序
优化方案就是使用合适的sort_buffer_size和max_sort_data字段大小,或者对排序字段建立索引等加快排序速度
5.group by 临时表
group by执行步骤: 创建临时表->取出分组字段并统计,对分组字段进行排序(此时参照上面的order by排序步骤,有可能走rowid排序,有可能走全字段排序)->取结果集
注意group by有会进行排序
解决方案,1.后加 order by null 指定不排序
2.对group by利用索引字段,即可不用临时表(索引是有序的,可以顺序读取或统计)
3.(比较少见):查询数据行有巨量的历史回滚版本,需要一致性读(可以增加读锁,当前读)















 1169
1169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









