







数组
移动0
283.Move Zeroes
Given an array nums, write a function to move all 0’s to the end of it while maintaining the relative order of the non-zero
elements.Example:
Input: [0,1,0,3,12] Output: [1,3,12,0,0] Note:
You must do this in-place without making a copy of the array. Minimize
the total number of operations.来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/move-zeroes
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这个题我没做出来,分析下一个巧妙的解法:
void moveZeroes(vector<int>& nums) {
int j = 0;
for (int i = 0; i < nums.size(); i++) {
if (nums[i] != 0) {
swap(nums[i],nums[j++]);
}
}
}
这里用了双指针,i作为遍历指针,j始终指向第一个0出现的地方(每次i指向元素为不为0时j就自加,为0时j不变)。
- 没有0的情况:【1,2,3,4,5】:每次都会进入swap函数,由于初始时ij相等,swap不执行。于是j加1,i由于在for循环里也加一,所以ij在每次循环中是同步加一的,直到他们走到最后,数组不会变。
- 有一个0 的情况:【1,0,2,3,4】:j指向0,i指向2,此时sawp函数运行,0与2换位,数组变为12034。j自加后还是指向0,i进行下一轮循环指向3,于是又将0与3换位、0与4换位,结束。
- 有多个连续0的情况:【1,0,0,0,2,3】:j指向第一个0,i指向2,于是将02对换得120003,注意中间两个0是没有变的。如此再将03对换,结束
- 有多个不连续0的情况:【1,0,4,2,0,3】:经过上面的分析知1042会变为1420,此时i指向后一个0,而j指向前一个0。142003就和连续0 的情况一样。
这个方法太强了!
链表
说明:第一个算法是迭代,第二个是递归
链表反转
Reverse a singly linked list.
Example:
Input: 1->2->3->4->5->NULL Output: 5->4->3->2->1->NULL Follow up:
A linked list can be reversed either iteratively or recursively. Could
you implement both?
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList1(struct ListNode* head) {//迭代 4ms 时间复杂度o(n)空间复杂度o(1)
if (!head||!head->next) return head;
struct ListNode* cur = head;
struct ListNode* prev = NULL;
struct ListNode* next = cur->next;
while (next) {
//翻转
cur->next = prev;
//先后移动三指针
prev = cur;
cur = next;
next = next->next;
}
cur->next = prev;
return cur;
}
struct ListNode* reverseList2(struct ListNode* head) {
//递归 0ms 时间复杂度o(n)
if (!head||!head->next) return head;//记head->next为二结点
struct ListNode *p = reverseList2(head->next);//认为二节点后已经排序完毕,返回新的头节点p
head->next->next = head;//让二结点的后继等于head,完成链表反转
head->next = NULL;//头节点变为现在的尾节点,后继应该为空
return p;
}
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
cur = head
prev = None
while cur:
cur.next,cur,prev=prev,cur.next,cur
return prev#想清楚这里返回的是哪个结点
链表两两反转
Given a linked list, swap every two adjacent nodes and return its
head.You may not modify the values in the list’s nodes, only nodes itself
may be changed.Example:
Given 1->2->3->4, you should return the list as 2->1->4->3.
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* swapPair1(struct ListNode* head) {
//执行用时 :4 ms
if(head==NULL||head->next==NULL) return head;
struct ListNode* thead =(struct ListNode*)malloc(sizeof(struct ListNode));
thead->val = -1;
thead->next = head;
struct ListNode* s = thead;
struct ListNode* a,*b;
while((s->next) && (s->next->next)){
a = s->next;
b = s->next->next;
s->next = b;
a->next = b->next;
b->next = a;
s = a;//关键一步
}
return thead->next;
}
struct ListNode* swapPair2(struct ListNode* head) {
if(!head||!head->next) return head;
struct ListNode *t = head->next;
struct ListNode *p = head->next->next;
t->next = head;
//以上已经实现了翻转相邻链表
head->next = swapPair2(p);
//head的后继节点显然要链接到每次递归后的开头节点,也就是返回的t节点【重点理解】
return t;
//这里只能return t,因为t是链表的开头节点,也是每次递归链表的开头节点
}
迭代算法说一下,参见某大佬的讲解

链表判环※
Given a linked list, determine if it has a cycle in it.
To represent a cycle in the given linked list, we use an integer pos
which represents the position (0-indexed) in the linked list where
tail connects to. If pos is -1, then there is no cycle in the linked
list.Example 1:
Input: head = [3,2,0,-4], pos = 1 Output: true Explanation: There is a
cycle in the linked list, where tail connects to the second node.
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
if(!head||!head->next) return 0;
struct ListNode *p = head;
struct ListNode *fast = head;
struct ListNode *slow = head;
while (1){
fast = fast->next->next;
slow = slow->next;//快慢指针
if(!fast||!fast->next) return 0;
if(fast == slow) return 1;
}
//接下来的代码表示如何找到入环节点
//定理:ptr1 指向链表的头, ptr2 指向相遇点。每次将它们往前移动一步,直到它们相遇,它们相遇的点就是环的入口。
while(p != slow){
p = p->next;
slow = slow->next;
}
return p;
}
//C++使用set(最佳)
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
unordered_set<ListNode *> st;
while(!head){
//count方法统计head出现多少次,次数大于1则返回入环节点
if(st.count(head)) return head;
st.insert(head);
head=head->next;
}
return NULL;
}
};
另:
- 解法一:如果可破坏数据,将元素都修改为某指定值,从头遍历链表,如果遍历到顶说明无环,遍历到指定值说明有环;
- 解法二:如果已知链表长度为N,从头遍历链表N次,如果遍历到顶说明无环,遍历顺利完成,说明未到顶,有环。或设定遍历时间为1s,1s内仍未遍历完说明有环。
删除链表重复结点
栈&队列
有效括号
Given a string containing just the characters ‘(’, ‘)’, ‘{’, ‘}’, ‘[’
and ‘]’, determine if the input string is valid.An input string is valid if:
Open brackets must be closed by the same type of brackets. Open
brackets must be closed in the correct order. Note that an empty
string is also considered valid.Example 1:
Input: “()” Output: true
// 执行用时 :0 ms, 在所有 C++ 提交中击败了100.00%的用户
// 内存消耗 :8.4 MB, 在所有 C++ 提交中击败了86.49%的用户
class Solution {
public:
bool isValid(string s) {
if(!s.length()) return 1;
stack<char> st;
for(char &i : s){//重点
switch (i){
case '(':
case '{':
case '[':
st.push(i);
break;
case ')':
if(!st.size()||st.top() != '(') return 0;
st.pop();
break;
case ']':
if(!st.size()||st.top() != '[') return 0;
st.pop();
break;
case '}':
if(!st.size()||st.top() != '{') return 0;
st.pop();
}//代码还能优化吗
}
if(!st.size()) return 1;
return 0;
}
};
#python解法 时间复杂度O(n2)
class Solution:
def isValid(self, s):
while '{}' in s or '()' in s or '[]' in s:
s = s.replace('{}', '')
s = s.replace('[]', '')
s = s.replace('()', '')
return s == ''
栈实现队列
class MyQueue {
public:
/** Initialize your data structure here. */
MyQueue() {
}
/** Push element x to the back of queue. */
void push(int x) {
s1.push(x);
}
/** Removes the element from in front of queue and returns that element. */
int pop() {
if(!s2.size()){
while(s1.size()){
s2.push(s1.top());
s1.pop();弹出栈顶元素, 但不返回其值
}
}
int val = s2.top();
s2.pop();
return val;
}
/** Get the front element. */
int peek() {
if(!s2.size()){
while(s1.size()){
s2.push(s1.top());
s1.pop();
}
}
return s2.top();
}
/** Returns whether the queue is empty. */
bool empty() {
return !(s1.size()+s2.size());
}
private:
stack<int> s1,s2;
};
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue* obj = new MyQueue();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->peek();
* bool param_4 = obj->empty();
*/
队列实现栈
class MyStack {
public:
/** Initialize your data structure here. */
MyStack() {
}
/** Push element x onto stack. */
void push(int x) {
q1.push(x);
}
/** Removes the element on top of the stack and returns that element. */
int pop() {
while(q1.size() != 1){
q2.push(q1.front());
q1.pop();
}
int num = q1.front();
q1.pop();
while(q2.size()){
q1.push(q2.front());
q2.pop();
}
return num;
}
/** Get the top element. */
int top() {
return q1.back();
}
/** Returns whether the stack is empty. */
bool empty() {
return !(q1.size()+q2.size());
}
private:
queue<int> q1,q2;
};
/**
* Your MyStack object will be instantiated and called as such:
* MyStack* obj = new MyStack();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->top();
* bool param_4 = obj->empty();
*/
返回数据流中第k大的元素(小顶堆)
在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。通常采用堆或二叉搜索树来实现。
Design a class to find the kth largest element in a stream. Note that
it is the kth largest element in the sorted order, not the kth
distinct element.Your KthLargest class will have a constructor which accepts an integer
k and an integer array nums, which contains initial elements from the
stream. For each call to the method KthLargest.add, return the element
representing the kth largest element in the stream.Example:
int k = 3; int[] arr = [4,5,8,2]; KthLargest kthLargest = new
KthLargest(3, arr); kthLargest.add(3); // returns 4
kthLargest.add(5); // returns 5 kthLargest.add(10); // returns 5
kthLargest.add(9); // returns 8 kthLargest.add(4); // returns 8
- 算法一:维护一个自动排序的数组,保存整个数组中k个较大值:插入新数并自动排序后,若有k个以上的元素,则去除最小的那个即开头元素。时间复杂度N*klog(k) (插入N个数据,每次都排序)
class KthLargest {
public:
//维护一个新数组st,是数组nums中的k个较大值
KthLargest(int k, vector<int>& nums) {
for(int i : nums){
st.insert(i);
if(st.size() > k){
//如果st有k+1个元素,那么去除最小的元素,也就是开头那个
st.erase(st.begin());
}
}
K = k;//需要把k保存起来
}
int add(int val) {
st.insert(val);
//如果元素超过k个,去除最小的那个
if(st.size() > K){
st.erase(st.begin());
}
return *st.begin();
}
private:
int K;
multiset<int> st;//自动排序 允许重复
};
/**
* Your KthLargest object will be instantiated and called as such:
* KthLargest* obj = new KthLargest(k, nums);
* int param_1 = obj->add(val);
*/
- 算法二:维护一个大小为k的小顶堆。每次插入数据时,如果比堆顶元素小,则不用插入;如果大,则插入并调整堆。输出堆底最后一个元素即为第k个最大元素。时间复杂度:最好N*1,最坏N*log(2k)=N*logk(取后者)。
一般stl都是降序,需要实现升序时,加上greater<>:
set<int,greater<int>> st;
class KthLargest {
int K;
priority_queue<int, vector<int>, greater<int>> pq;
/*
priority_queue<Type, Container, Functional>
Type为数据类型, Container为保存数据的容器,Functional为元素比较方式。
如果不写后两个参数,那么容器默认用的是vector,比较方式默认用operator<,
也就是优先队列是大顶堆,队头元素最大,本题为小顶堆。
*/
public:
KthLargest(int k, vector<int>& nums) {
for (int n : nums) {
pq.push(n);
if (pq.size() > k) pq.pop();
}
K = k;
}
int add(int val) {
pq.push(val);
if (pq.size() > K) pq.pop();
return pq.top();
}
};
/*作者:guohaoding
链接:https://leetcode-cn.com/problems/kth-largest-element-in-a-stream/solution/703-shu-ju-liu-zhong-de-di-kda-yuan-su-liang-chong/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
*/
滑动窗口最大值(优先队列)
Given an array nums, there is a sliding window of size k which is
moving from the very left of the array to the very right. You can only
see the k numbers in the window. Each time the sliding window moves
right by one position. Return the max sliding window.Example:
Input: nums = [1,3,-1,-3,5,3,6,7], and k = 3 Output: [3,3,5,5,6,7]
Explanation:
| Window position | Max |
|---|---|
| [1 3 -1] -3 5 3 6 7 | 3 |
| 1 [3 -1 -3] 5 3 6 7 | 3 |
| 1 3 [-1 -3 5] 3 6 7 | 5 |
| 1 3 -1 [-3 5 3] 6 7 | 5 |
| 1 3 -1 -3 [5 3 6] 7 | 6 |
| 1 3 -1 -3 5 [3 6 7] | 7 |
- 算法一:multiset保存当前的窗口,每次将当前窗口最大值传入answer数组中。pos指针从nums数组第一个元素指向最后一个元素,每次移动过程中向集合中插入所指元素。以k=3为例,pos = 3,4…时,窗口内元素个数大于3个,需要删除最左边的数据;pos=2,3,4…时,窗口元素个数大于等于3个,可以向ans数组写入当前窗口最大值。时间复杂度n*klog(k)
注意C++中,end()不是指向最后一个元素,而是最后一个元素的后一个元素,所以返回最后一个元素时不能用*st.end()而要用*st.rbegin()
// 执行用时 :92 ms, 在所有 C++ 提交中击败了37.34%的用户
class Solution {
multiset<int> st;
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
vector<int> ans;
for(int pos = 0;pos < nums.size();pos++){
if(pos >= k) st.erase(st.find(nums[pos-k]));//删除左边数据
st.insert(nums[pos]);
if(pos >= k-1) ans.push_back(*st.rbegin());
}
return ans;
}
};
- 算法二:优先队列(大顶堆)
思想同算法一,维护一个多重集合变为维护一个大顶堆,但是我不会C++优先队列中删除某特定值的元素,即删除窗口最左边的数据,挖坑。时间复杂度n*logk - 算法三:双端队列
进新元素时,干掉比自己小的元素,时间复杂度n
class Solution {
vector<int> ans;
deque<int> dequ;
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
for (int pos = 0; pos < nums.size(); pos++) {
if (!dequ.empty() && dequ.front() == pos-k) {
dequ.pop_front();
}
while (!dequ.empty() && nums[pos] > nums[dequ.back()]){
dequ.pop_back();
}
dequ.push_back(pos);
if (pos >= k-1) ans.push_back(nums[dequ.front()]);
}
return ans;
}
};
Map&Set
有效的字母异位词
Given two strings s and t , write a function to determine if t is an
anagram of s.Example 1:
Input: s = “anagram”, t = “nagaram” Output: true Example 2:
Input: s = “rat”, t = “car” Output: false
STL 容器比较:
| 模板 | key | 排序 |
|---|---|---|
| set | 不允许重复 | 自动排序 |
| map | 不允许重复 | 自动排序 |
| multimap | 允许重复 | 自动排序 |
| unordered_map | 不允许重复 | 无序 |
| unordered_multimap | 允许重复 | 无序 |
总结:set和map都是不允许重复自动排序的,加multi表示允许重复,加unordered表示无序。
unordered_map:
在cplusplus的解释:
无序映射是关联容器,用于存储由键值和映射值组合而成的元素,并允许基于键快速检索各个元素。
在unordered_map中,键值通常用于唯一标识元素,而映射值是与该键关联的内容的对象。键和映射值的类型可能不同。
在内部,unordered_map中的元素没有按照它们的键值或映射值的任何顺序排序,而是根据它们的散列值组织成桶以允许通过它们的键值直接快速访问单个元素(具有常数平均时间复杂度)。
unordered_map容器比映射容器更快地通过它们的键来访问各个元素,尽管它们通过其元素的子集进行范围迭代通常效率较低。
无序映射实现直接访问操作符(operator []),该操作符允许使用其键值作为参数直接访问映射值。
容器中的迭代器至少是前向迭代器。
关键词:无序的 快速的检索 达到的是更快的访问 但是子集的范围迭代效率低
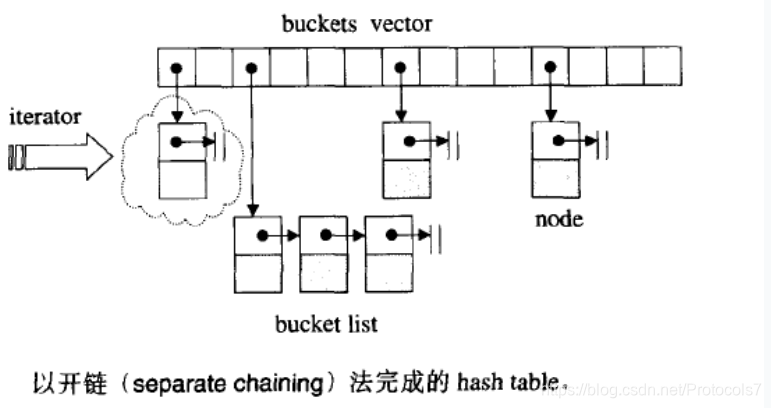
//时间复杂度 N
class Solution {
unordered_map<char,int> counts;
//对每个字母出现次数计数。如counts['a']=3表示a出现了3次
public:
bool isAnagram(string s, string t) {
if(s.length() != t.length()) return false;
for(int i = 0;i < s.length();i++){
counts[s[i]]++;//串1中的字母出现时加一
counts[t[i]]--;//串2中的字母出现时减一
}
//如果串1和串2字母全相同,counts中的计数应为0
for(auto count:counts)
if(count.second) return false;
return true;
}
};
//另有将两个字符串数组排序后再比较的算法,Nlog(N)(快排)
两数之和
Given an array of integers, return indices of the two numbers such
that they add up to a specific target.You may assume that each input would have exactly one solution, and
you may not use the same element twice.Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9, return [0, 1].
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/two-sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
- 算法一:暴力法 O(n2)
- 算法二:set记录
这道题有个巨坑,就是C++的set是自动排序的。我一开始用set,放入3,2,4后,再找2的时候,返回的下标是1,而答案应该是2,也就是set给我排序了,下标变了。花了好久时间想为什么返回下标是1。。所以改用vector解决问题。还有个坑,distance函数我不知道,为什么C++find不能直接返回下标,要返回迭代器,还得distance函数找距离。。
class Solution {
vector<int> record;
//set自动排序 不能用set做本题,只能用map/vector
vector<int> res;
public:
vector<int> twoSum(vector<int>& nums, int target) {
for(int i = 0;i < nums.size();i++){
//vector的find方法要用stl的,它没有自己的
auto p = find(record.begin(),record.end(),target - nums[i]);
if( p == record.end()){
record.push_back(nums[i]);
}else{
res.push_back(i);
res.push_back(distance(record.begin(),p));
break;//找到即可返回
}
}
return res;
}
};
算法三:map
在算法二我们知道set是一维的,由下标确定值。而map是二维的,可以存元素以及下标,就这样省去了找下标的时间。
class Solution {
unordered_map<int,int> record;
vector<int> res;
public:
vector<int> twoSum(vector<int>& nums, int target) {
for(int i=0;i<nums.size();i++){
int tmp=target-nums[i];
if(record.find(tmp)==record.end()){
record[nums[i]]=i;
}else
res.push_back(i);
res.push_back(record[tmp]);
//无须distance函数找下标
break;
}
return res;
}
};
算法三只是换成map,时间变为12ms,而算法二是56ms,(消耗内存都差不多),时间复杂度相同,为什么时间上差这么多?可能是distance函数慢了。
三数之和
- 算法一:暴力O(n3)
- 算法二:两层循环,在循环内部找target-a-b,找到了就结束,没找到就把a和b插入set中,O(n2),空间O(n)
- 算法三:先排序(快排nlogn),b和c作为双指针,a+b+c值大于0,说明大了,左移c;小于0,说明小了右移b。时间O(n2),空间无。
二叉树&二叉搜索树
二叉树遍历
typedef struct TreeNode
{
int data;
TreeNode * left;
TreeNode * right;
TreeNode * parent;
}TreeNode;
void pre_order(TreeNode * Node)
{
if(Node != NULL)
{
printf("%d ", Node->data);
pre_order(Node->left);
pre_order(Node->right);
}
}
void middle_order(TreeNode *Node) {
if(Node != NULL) {
middle_order(Node->left);
printf("%d ", Node->data);
middle_order(Node->right);
}
}
void after_order(TreeNode *Node) {
if(Node != NULL) {
after_order(Node->left);
after_order(Node->right);
printf("%d ", Node->data);
}
}
验证二叉搜索树
Given a binary tree, determine if it is a valid binary search tree
(BST).Assume a BST is defined as follows:
The left subtree of a node contains only nodes with keys less than the
node’s key. The right subtree of a node contains only nodes with keys
greater than the node’s key. Both the left and right subtrees must
also be binary search trees.Example 1:
2
/ \
1 3
Input: [2,1,3] Output: true
- 算法一:中序遍历这棵树,如果是二叉搜索树,结果应该为升序。O(n)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
vector<int> vec;
int flag = 1;
public:
bool isValidBST(TreeNode* root) {
middle_order(root);
return flag;
}
void middle_order(TreeNode *Node) {
if(Node != NULL) {
middle_order(Node->left);
if(vec.size() == 0||Node->val > vec.back()){
vec.push_back(Node->val);
}else {flag = 0;}
middle_order(Node->right);
}
}
};
我这个做法里面有flag,不知道好不好,执行用时 :16 ms, 在所有 C++ 提交中击败了77.06%的用户内存消耗 :21.5 MB, 在所有 C++ 提交中击败了5.16%的用户。内存消耗的有点多。应该有改进的地方。
copy一个更好的写法,24 ms, 20.6 MB ,代码简洁一点。
class Solution {
public:
long x = LONG_MIN;
bool isValidBST(TreeNode* root) {
if(root == NULL){
return true;
}
else{
if(isValidBST(root->left)){
if(x < root->val){
x = root->val;
return isValidBST(root->right);
}
}
}
return false;
}
};
- 算法二:递归(copy的代码)
class Solution {
public:
bool isValidBST(TreeNode* root) {
return helper(root,LONG_MIN,LONG_MAX);
}
bool helper(TreeNode* cur,long lt,long rt){
if(cur==NULL) return true;
if(cur->val<=lt||cur->val>=rt) return false;
if(helper(cur->left,lt,cur->val)&&helper(cur->right,cur->val,rt)) return true;
return false;
}
};
作者:24shi-01fen-_00_01
链接:https://leetcode-cn.com/problems/validate-binary-search-tree/solution/liang-chong-fang-fa-di-gui-zhong-xu-bian-li-by-24s/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最近公共祖先
Given a binary search tree (BST), find the lowest common ancestor
(LCA) of two given nodes in the BST.According to the definition of LCA on Wikipedia: “The lowest common
ancestor is defined between two nodes p and q as the lowest node in T
that has both p and q as descendants (where we allow a node to be a
descendant of itself).”Given binary search tree: root = [6,2,8,0,4,7,9,null,null,3,5]
Example 1:
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 Output: 6
Explanation: The LCA of nodes 2 and 8 is 6.
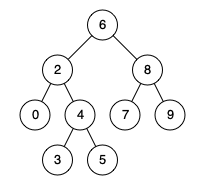
以节点3和0为例
算法一:如果有parent指针,3和0第一个相同的parent节点即为所求- 算法二:从根节点遍历到0和3,记录他们的路径。如620、6243,第一个分叉的节点2即为所求。O(N)
- 算法三:递归O(N):注意这个是二叉搜索树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
struct TreeNode* lowestCommonAncestor(struct TreeNode* root, struct TreeNode* p, struct TreeNode* q) {
if(root==NULL) return NULL;
if(root==p||root==q) return root;//找到了
if(root->val>p->val&&root->val>q->val) return lowestCommonAncestor(root->left,p,q);
if(root->val<p->val&&root->val<q->val) return lowestCommonAncestor(root->right,p,q);
return root;
}















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









