






hadoop安装过程
这篇文档是关于hadoop高可用安装的过程。
中途遇到了很多问题,比如在node01上启动yarn失败,通过错误的显示是在配置之前的java的路径写错了,一个一个修改才可以启动;node01启动集群多了一个DataNode,是因为之前配置vi slaves出现了问题;老师给的eclipse打不开,因为没装jdk,jdk安装了很多次都无法打开,最后通过查找jdk的位数和eclipse的位数不符,找到了相同位数的jdk才打开了eclipse…
我对hadoop知识的理解是,
hadoop开启集群后,通常有两台不同的机器作为NameNode,有一台处于Active状态,另一台则处于Standby状态,Active NN负责集群中所有客户端的操作,而Standby NN用于备用。两台机子可以同步数据,两个Namenode都与一组Journal Node进行通信。
安装过程:
- 首先,准备好4台机子能连上Xshell。

- 将jdk-7u67-linux-x64.rpm上传到xftp4里node01的/root里,检查node01里是否成功收到文件。
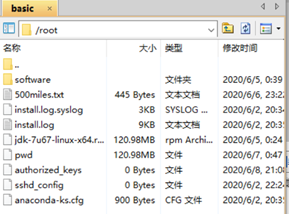
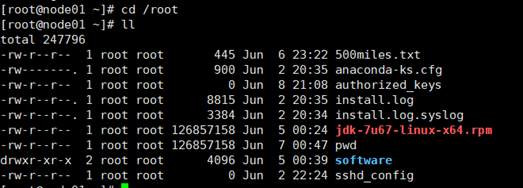
- 将jdk从node01分发到其余的三台机子,并在Xshell的全部会话栏里ll,检查jdk是否发送成功。
-scp jdk-7u67-linux-x64.rpm node02:pwd
-scp jdk-7u67-linux-x64.rpm node03:pwd
-scp jdk-7u67-linux-x64.rpm node04:pwd

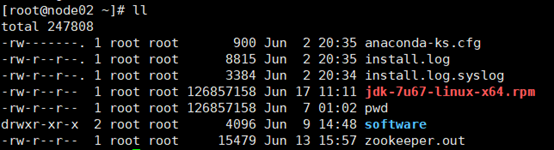
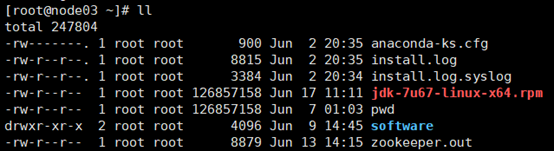
4. 在node02、03、04上执行rpm安装命令: -rpm -i jdk-7u67-linux-x64.rpm



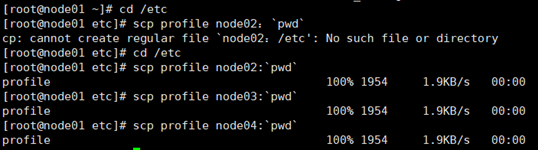
5. 在node01上cd /etc 在此目录下把profile文件分发到node02、03、04上
scp profile node02:pwd
scp profile node03:pwd
scp profile node04:pwd
6. 用Xshell全部会话栏,source /etc/profile,再在全部会话栏里输入jps,查看02,03,04的jdk是否安装好。




7. 同步所有服务器的时间。输入-date 查看机子当前时间
当时间不同步时
1)yum进行时间同步器的安装 -yum -y install ntp
2) 执行同步命令 -ntpdate time1.aliyun.com 和阿里云服务器时间同步




8. 查看配置文件是否正确
1)-cat /etc/sysconfig/network 查看HOSTNAME是否正确
2)-cat /etc/hosts 查看IP映射是否正确
不正确就更改文件,或者通过scp分发过去。
3)-cat /etc/sysconfig/selinux
SELINUX=disabled
4)service iptables status 查看防火墙是否关闭




9. 与其他机子的免秘钥设置
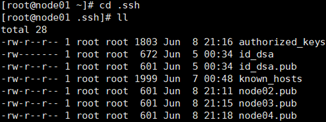
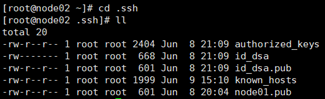
1)在家目录下 ll -a 检查是否有.ssh文件,如果没有就ssh localhost(结束之后exit)。




2)-cd .ssh ,ll查看
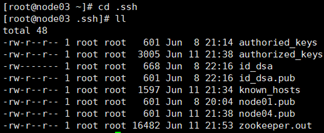
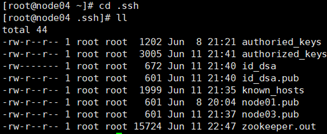
3)把node01的公钥发给其他三台机子,
-scp id_dsa.pub node02:pwd/node01.pub
-scp id_dsa.pub node03:pwd/node01.pub
-scp id_dsa.pub node04:pwd/node01.pub
4)在node01上分别ssh node02,ssh node03,ssh node04,看是否能免秘钥登录,每次ssh都别忘了exit。

10. 在node02的.ssh目录下查看是否有node01.pub,如果有,那就追加到authoried_keys
cat node01.pub >> authorized_keys
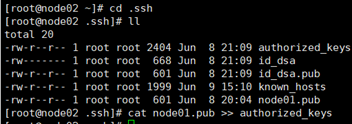
并且在node01上ssh node02看是否能免秘钥,记住exit。
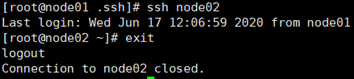
给node03、04都追加node01.pub。就是在node03、04的.ssh目录下执行cat node01.pub >> authorized_keys。


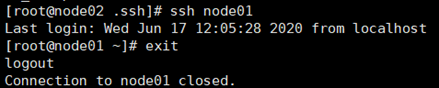
11. 两个NN间互相免秘钥。
node01与node02间互相免秘钥:node01可免秘钥登录node02,现需要node02能免秘钥登录node01所以在node02上:
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh localhost验证一下
分发到node01上:scp id_dsa.pub node01:pwd/node02.pub

在node01的.ssh目录下,cat node02.pub >> authorized_keys

在node02上ssh node01验证一下是否可以免秘钥登录
12. 修改nodenode的一些配置信息
1) cd /opt/wk/Hadoop-2.6.5/etc/hadoop

vi hdfs-site.xml 将里面的内容修改为:
< configuration >
< property>
< name>dfs.replication< /name>
< value>3< /value>
</ property>
< property>
< name>dfs.nameservices< /name>
< value>mycluster< /value>
< /property>
< property>
< name>dfs.ha.namenodes.mycluster< /name>
< value>nn1,nn2< /value>
< /property>
< property>
< name>dfs.namenode.rpc-address.mycluster.nn1< /name>
< value>node01:8020< /value>
< /property>
< property>
< name>dfs.namenode.rpc-address.mycluster.nn2< /name>
< value>node02:8020< /value>
< /property>
< property>
< name>dfs.namenode.http-address.mycluster.nn1< /name>
< value>node01:50070< /value>
< /property>
< property>
< name>dfs.namenode.http-address.mycluster.nn2< /name>
< value>node02:50070< /value>
< /property>
< property>
dfs.namenode.shared.edits.dir
< value>qjournal://node01:8485;node02:8485;node03:8485/mycluster< /value>
< /property>
< property>
< name>dfs.journalnode.edits.dir< /name>
< value>/var/wk/hadoop/ha/jn< /value>
< /property>
< property>
< name>dfs.client.failover.proxy.provider.mycluster< /name>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</ value>
</ property>
< property>
< name>dfs.ha.fencing.methods</ name>
< value>sshfence</ value>
< /property>
< property>
< name>dfs.ha.fencing.ssh.private-key-files< /name>
< value>/root/.ssh/id_dsa< /value>
< /property>
< property>
< name>dfs.ha.automatic-failover.enabled< /name>
< value>true< /value>
</ property>
- vi core-site.xml
 < configuration>
< configuration>
< property>
< name>fs.defaultFS< /name>
< value>hdfs://mycluster< /value>
< /property>
< property>
< name>ha.zookeeper.quorum< /name>
< value>node02:2181,node03:2181,node04:2181</ value>
< /property>
< /configuration>
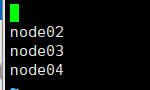
3)vi slaves

node02
node03
node04
4)source /etc/profile

5) 安装hadoop
cd /opt,将wk目录分发到node02、03、04
scp -r wk/ node02:pwd
scp -r wk/ node03:pwd
scp -r wk/ node04:pwd



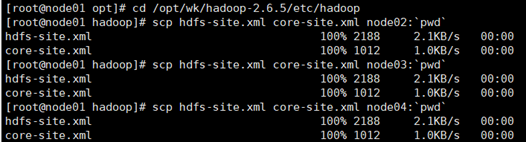
- 将hdfs-site.xml和core-site.xml分发到node02、03、04
scp hdfs-site.xml core-site.xml node02:pwd
scp hdfs-site.xml core-site.xml node03:pwd
scp hdfs-site.xml core-site.xml node04:pwd
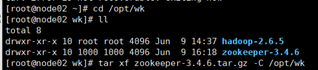
13. 将zookeeper安装包上传到node02的Xftp4上
- 解压安装zookeeper
tar xf zookeeper-3.4.6.tar.gz -C /opt/wk
- 修改zookeeper的配置文件
cd /opt/wk/zookeeper-3.4.6/conf
给zoo_sample.cfg改名
cp zoo_sample.cfg zoo.cfg

vi zoo.cfg
改dataDir=/var/wk/zk
并在末尾追加
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888

- 把zookeeper分发到其他节点
scp -r zookeeper-3.4.6/ node03:pwd
scp -r zookeeper-3.4.6/ node04:pwd


并用 ll /opt/wk 检查下分发是否成功


- 给装有zookeeper的每台机子创建配置文件里的路径
mkdir -p /var/wk/zk

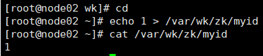
对node02来说:
echo 1 > /var/wk/zk/myid
cat /var/wk/zk/myid
对node03来说:
echo 2 > /var/wk/zk/myid
cat /var/wk/zk/myid

对node04来说:
echo 3 > /var/wk/zk/myid
cat /var/wk/zk/myid

5)在/etc/profile里面配置
export ZOOKEEPER_HOME=/opt/ldy/zookeeper-3.4.6
export PATH= P A T H : / u s r / j a v a / j d k 1.7. 0 6 7 / b i n : PATH:/usr/java/jdk1.7.0_67/bin: PATH:/usr/java/jdk1.7.067/bin:HADOOP_HOME/bin: H A D O O P H O M E / s b i n : HADOOP_HOME/sbin: HADOOPHOME/sbin:ZOOKEEPER_HOME/bin

- 把/etc/profile分发到其他node03、node04
scp /etc/profile node03:/etc
scp /etc/profile node04:/etc

- 在node02、03、04里source /etc/profile


最后验证source这句是否完成,输入zkCli.s,按Tab可以把名字补全zkCli.sh

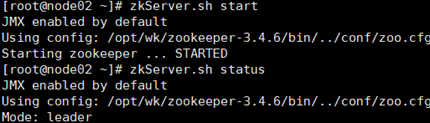
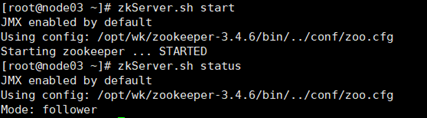
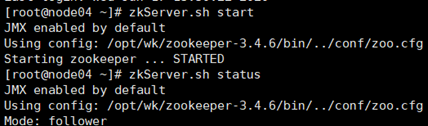
8)启动zookeeper
全部会话:zkServer.sh.start
接着用zkServer.sh status查看每个zookeeper节点的状态
注意:如果启动不起来,请把/etc/profile里的JAVA_HOME改成绝对路径。
- 启动journalnode
使两台NameNode间完成数据同步,在01,02,03三台机子上分别把journalnode启动起来 hadoop-daemon.sh start journalnode 用jps检查进程起来没



- 格式化任一namenode
挑一台namenode上执行hdfs namenode -format 另一台namenode不用执行。
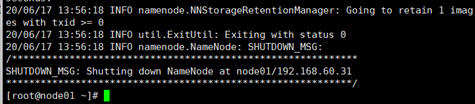
启动刚刚格式化的那台namenode ,hadoop-daemon.sh start namenode
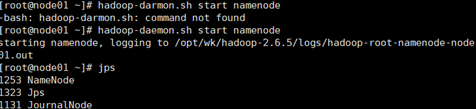
对另一台nodenode同步数据,hdfs namenode -bootstrapStandby

- 格式化 zkfc -formatZK
hdfs zkfc -formatZK
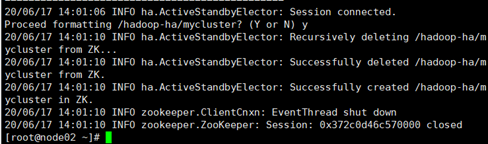
在node02上执行zkCli.sh打开zookeeper客户端看hadoop-ha是否打开

- 在node01上启动hdfs集群:start-dfs.sh

全部会话jps查看起来什么进程
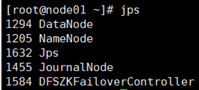
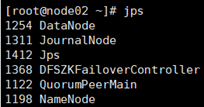
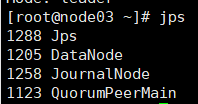
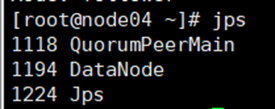
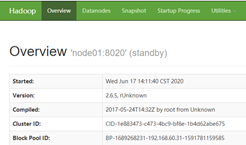
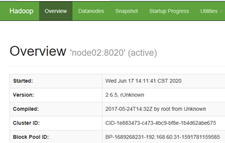
用浏览器访问node01:50070和node02:50070
关闭集群命令stop-dfs.sh
关闭zookeeper命令zkServer.sh stop



- 为MapReduce做准备
把mapred-site.xml.template留个备份并改名cp mapred-site.xml.template mapred-site.xml

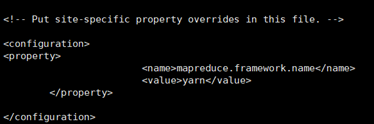
在mapred-site.xml里添加如下property
< property>
< name>mapreduce.framework.name< /name>
< value>yarn< /value>
< /property>
在yarn-site.xml里添加如下Property
< property>
< name>yarn.nodemanager.aux-services< /name>
< value>mapreduce_shuffle< /value>
< /property>
< property>
< name>yarn.resourcemanager.ha.enabled< /name>
< value>true< /value>
< /property>
< property>
< name>yarn.resourcemanager.cluster-id< /name>
< value>cluster1< /value>
< /property>
< property>
< name>yarn.resourcemanager.ha.rm-ids< /name>
< value>rm1,rm2< /value>
< /property>
< property>
< name>yarn.resourcemanager.hostname.rm1< /name>
< value>node03< /value>
< /property>
< property>
< name>yarn.resourcemanager.hostname.rm2< /name>
< value>node04< /value>
< /property>
< property>
< name>yarn.resourcemanager.zk-address < /name>
< value>node02:2181,node03:2181,node04:2181 /value>
</ property>


source /etc/profile
然后把mapred-site.xml和yarn-site.xml分发到node02、03、04
scp mapred-site.xml yarn-site.xml node02:pwd
scp mapred-site.xml yarn-site.xml node03:pwd
scp mapred-site.xml yarn-site.xml node04:pwd
node03上免密钥登录node04:
在node03的.ssh目录下生成密钥
ssh-keygen -t dsa -P ‘’ -f ./id_dsa
并追加到自己authorized_keys
cat id_dsa.pub >> authorized_keys
用ssh localhost验证看是否需要密码,别忘了exit
将node03 的公钥分发到node04
scp id_dsa.pub node04:pwd/node03.pub

在node04的.ssh目录下,追加node03.pub
cat node03.pub >> authorized_keys

在node03上ssh node04,看是否免密钥

node04上免秘钥登录node03:
在node04的.ssh目录下生成密钥
ssh-keygen -t dsa -P ‘’ -f ./id_dsa
并追加到自己authorized_keys
cat id_dsa.pub >> authorized_keys
用ssh localhost验证看是否需要密码,别忘了exit
将node04 的公钥分发到node03
scp id_dsa.pub node03:pwd/node04.pub

在node03的.ssh目录下,追加node04.pub
cat node04.pub >> authorized_keys

在node04上ssh node03,看是否免密钥
1)启动zookeeper,全部会话zkServer.sh start
2) node01启动集群,start-dfs.sh
3) node01上启动yarn,start-yarn.sh
4) node03、04上启动resourcemanager,yarn-daemon.sh start resourcemanager
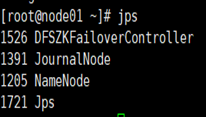
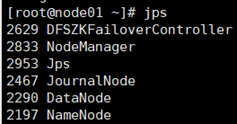
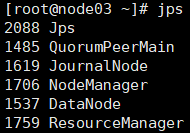
5) 全部会话jps,查看进程全不全
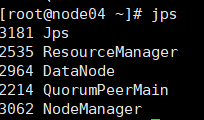
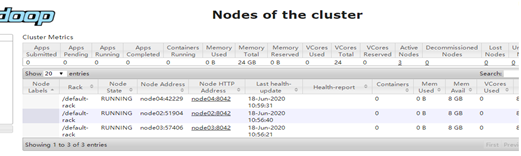
在浏览器访问node03:8088,查看resourcemanager管理的内容
19. 跑一个Wordcount
- cd /opt/wk/hadoop-2.6.5/share/hadoop/mapreduce
- 2.在hdfs里建立输入目录和输出目录
cd /opt/wk/hadoop-2.6.5/etc/hadoop
hdfs dfs -mkdir -p /data/in
hdfs dfs -mkdir -p /data/out - 将要统计数据的文件上传到输入目录并查看
hdfs dfs -put ~/500miles.txt /data/in
hdfs dfs -ls /data/in

4) 运行wordcount(注意:此时的/data/out必须是空目录
cd /opt/wk/hadoop-2.6.5/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/in /data/out/result
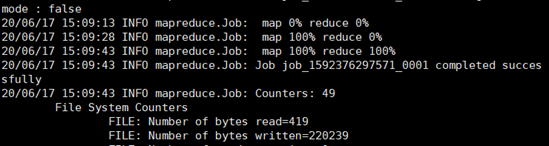
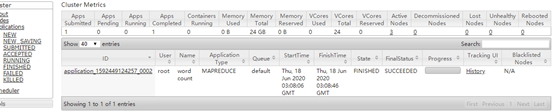
5) 查看运行结果
hdfs dfs -ls /data/out/result
hdfs dfs -cat /data/out/result/part-r-00000

20. 关闭集群
node01: stop-dfs.sh
node01: stop-yarn.sh (停止nodemanager)
node03,node04: yarn-daemon.sh stop resourcemanager
node02、03、04:zkServer.sh stop
- 在Windows下配置hadoop的环境
- 把压缩包解压后放在usr文件夹里
- 此电脑-右键-属性-高级系统设置-高级-环境变量
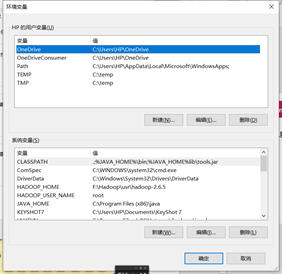
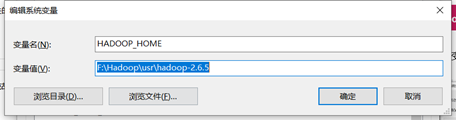
- 更改环境变量,增加HADOOP_HOME
并且给path后追加HADOOP_HOME的bin目录
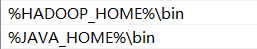
再新建一个变量HADOOP_USER_NAME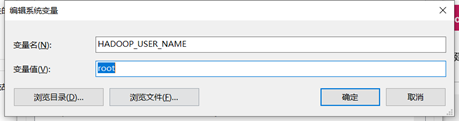
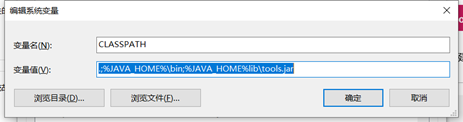
最后添加一个变量CLASSPATH
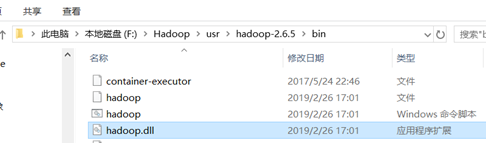
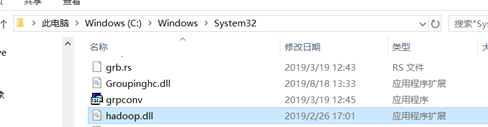
4) 把hadoop.dll拷贝到以下路径
5) 安装eclipse-mars
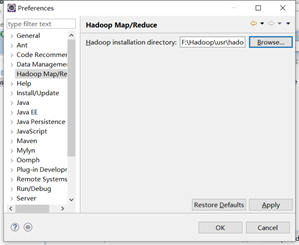
如果eclipse姐妹下方面没有小象图标,做后续三步调出

6) 在eclipse里把hadoop相关信息填一下
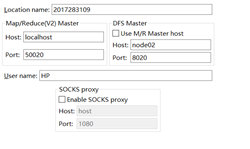
7) 右键New Hadoop Localtion

8) 在eclipse左侧列表的DFS location里新建一个目录,对呀的hdfs就建好了,可以用浏览器查看。
右键create new directory…
9) 在eclipse里导入自己建一个包库
先给自己的包起给名字
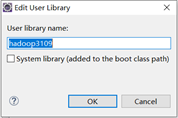
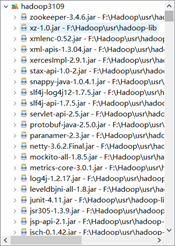
再加入hadoop-lib里的文件。
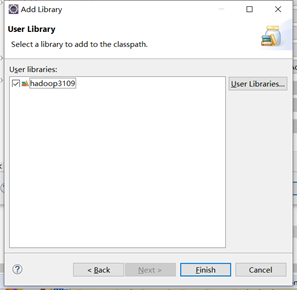
再把刚建的包库引入project里,新建一个Text3109-右键-build path-configure build path,点libraries,addlibrary…,选择User Library

选择刚刚新建的包
10) 把JUnit包库引入到project里
右键Text3109-build path – configure build path…-libraries-add library…-Junit

11) 利用xftp把hdfs-site.xml,core-site.xml等几个xml放到project的src目录
右键Text3109-properties-Resource-复制location路径

打开Xftp4,粘贴复制的路径
















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









