






目录
前言
Hadoop是一个分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop有三大核心框架设计,分别是HDFS、MapReduce以及YARN。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 ,YARN则提供统一的资源管理和调度。
安装环境
- 虚拟机
VMware Workstation Pro17
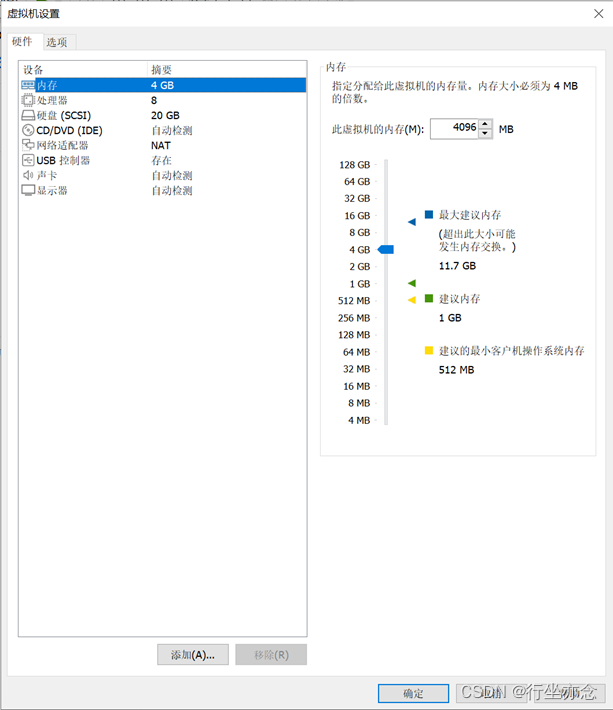
CentOS 7 64 位(此次演示所用环境)配置如下:
Hadoop安装包以及jdk分享:
链接:https://pan.baidu.com/s/1uv333OAcWgYD5DKucs9vHg?pwd=4t85
提取码:4t85
一、安装JDK
1. 下载JDK软件:https://www.oracle.com/java/technologies/downloads 在页面下方找到:
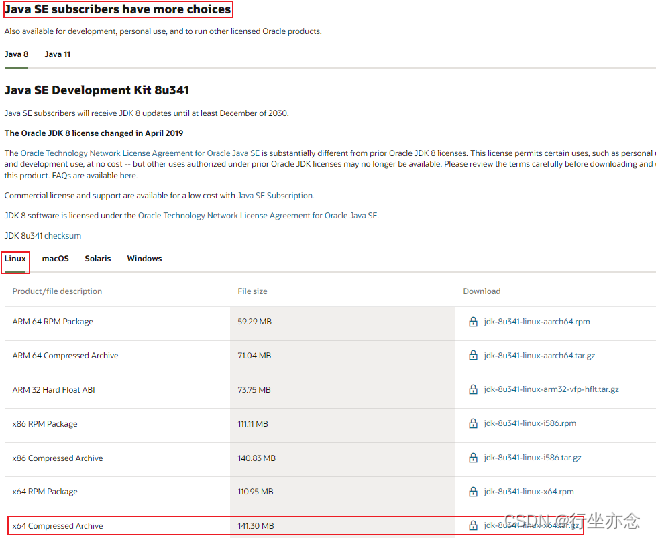
下载jdk-8u361-linux-x64.tar.gz

1.打开linux终端切换root用户
su root
输入密码回车:(防止文件权限不足要开启root用户来解压文件)
2. 创建文件夹,用来部署JDK,将JDK安装部署到:/export/server 内:
mkdir -p /export/server
3.解压缩JDK安装文件到server文件夹内:
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/server/
4. 配置JDK的软链接
ln -s /export/server/jdk-8u361-linux-x64.tar.gz /export/server/jdk
5. 配置JAVA_HOME环境变量,以及将$JAVA_HOME/bin文件夹加入PATH环境变量中
# 编辑/etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
6. 生效环境变量
source /etc/profile
7. 配置java执行程序的软链接
#删除系统自带的java程序
rm -f /usr/bin/java
#软链接我们自己安装的java程序
ln -s /export/server/jdk/bin/java /usr/bin/java
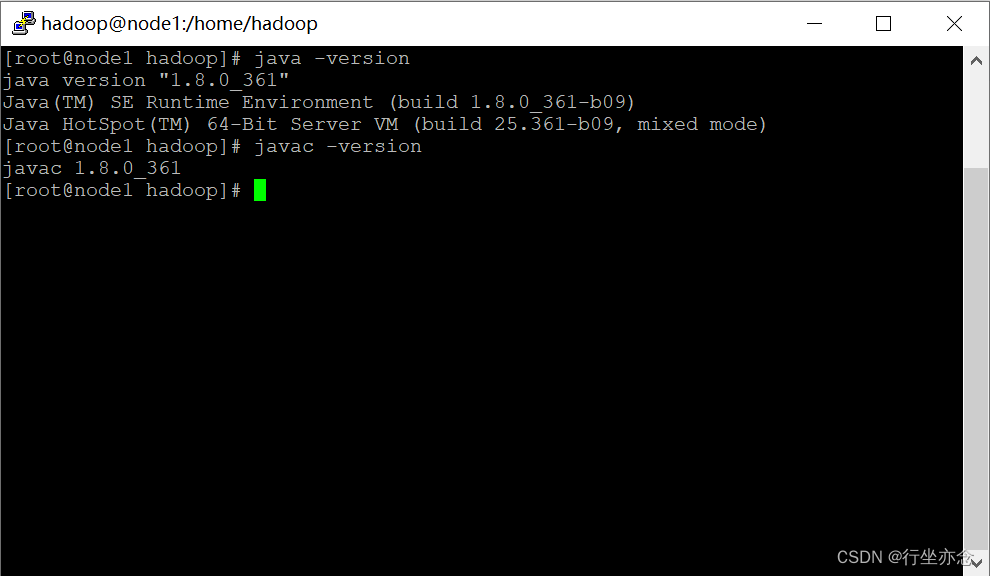
8. 执行验证
java -version
javac -version
输出如下:
9.打开windows cmd命令输入
notepad C:\Windows\System32\drivers\etc\hosts
找到hosts文件配置主机映射:
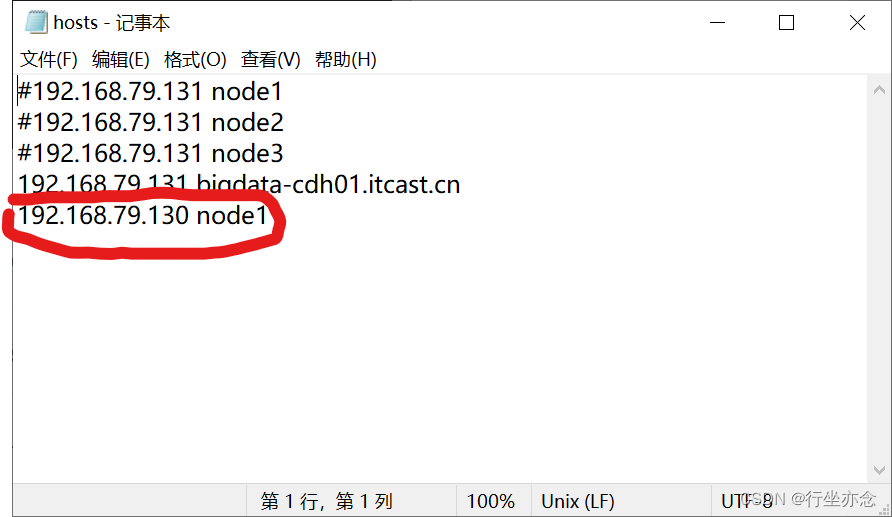
打开虚拟机终端使用hostname以及ifconfig检查自己的ip地址跟对应的主机名
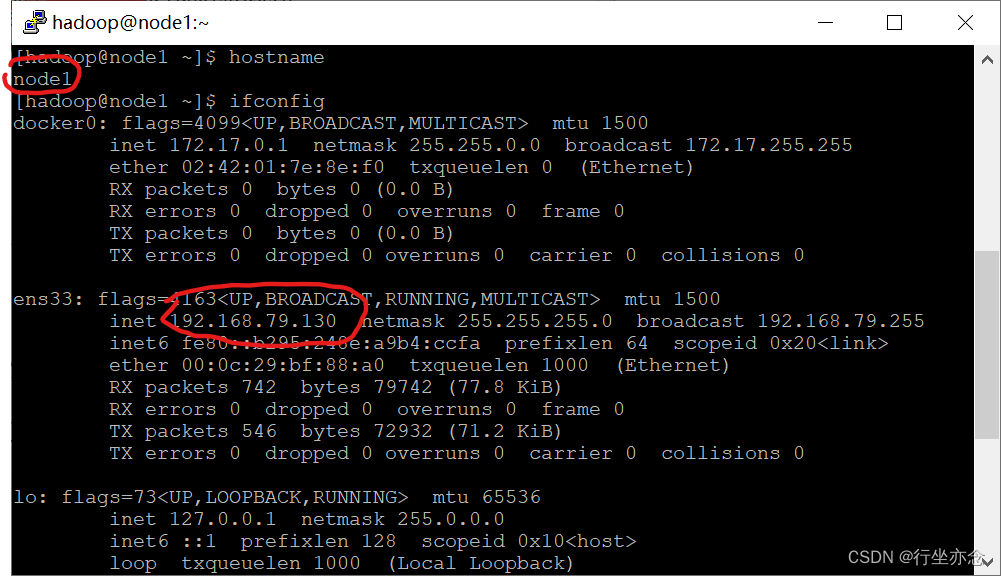
配置好Ctrl+s保存hosts文件。
二、安装Hadoop
1.解压缩安装包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
2.构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
3.进入hadoop安装包内
cd hadoop
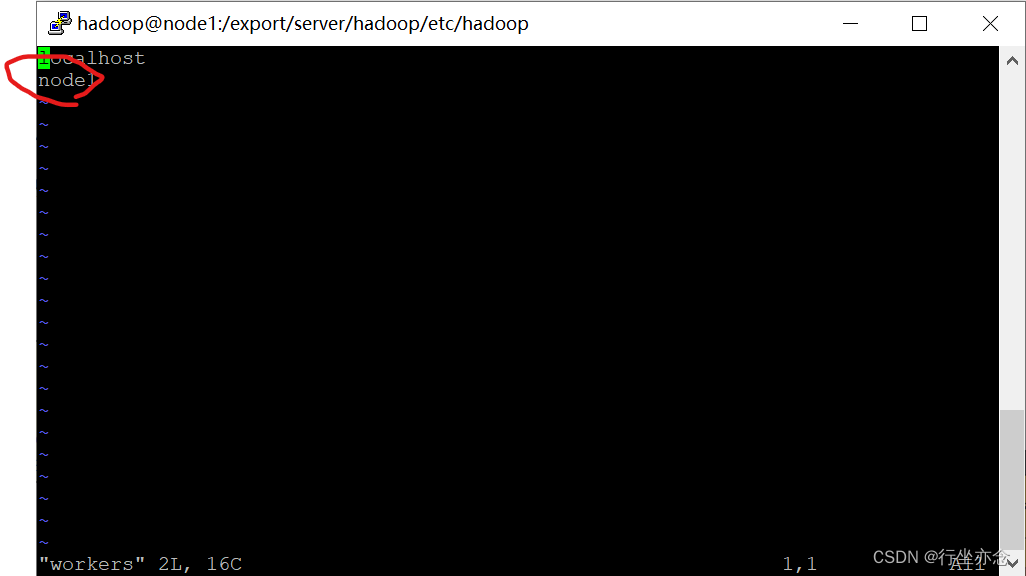
4.配置workers文件
cd etc/hadoop
vim workers
添加自己的节点:
5.配置hadoop-env.sh文件
#编写hadoop-env.sh文件
vim hadoop-env.sh
# 填入如下内容:
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_
HOME/logs
6.配置core-site.xml文件,在文件内部填入如下内容(node1更换成自己节点的名字):
#编写core-site.xml文件
vim core-site.xml
# 填入如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
7.配置hdfs-site.xml文件
#编写hdfs-site.xml文件
vim hdfs-site.xml
# 填入如下内容:
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
8.准备数据目录
mkdir -p /data/nn
mkdir /data/dn
9.配置环境变量
#编辑profile文件
vim /etc/profile
# 在/etc/profile文件底部追加如下内容:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
10.格式化
# 格式化namenode
hadoop namenode -format
11.启动
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
12.查看Web UI
启动完成后,可以在浏览器打开:http://node1:9870,即可查看到hdfs文件系统的管理网页。
(node1即为你的主机映射名)

在虚拟机终端使用jps命令可以看到DataNode、NameNode、SecondaryNameNode表明Hadoop的服务已经启动。

后续:
书接上回,我们安装好了Hadoop的HDFS,以及成功运行,但是我发现有一些遗漏,所以写了第二部分,这回我们讲一讲YARN搭建已经后面集群的部署。
YARN部署
在 export/server/hadoop/etc/hadoop 文件夹内,修改:
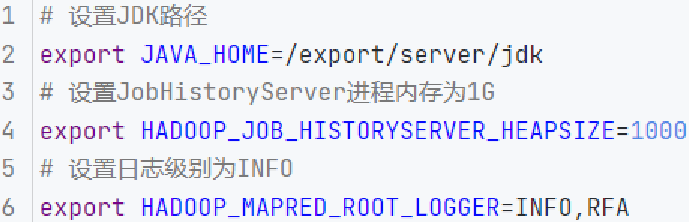
mapred-env.sh文件,添加如下环境变量:
![]() 编辑
编辑
export JAVA_HOME=/export/server/jdk export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000 export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
![]()
mapred-site.xml文件,添加如下配置信息:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description></description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> <description></description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> <description></description> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/data/mr-history/tmp</value> <description></description> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/data/mr-history/done</value> <description></description> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> </configuration>
![]()
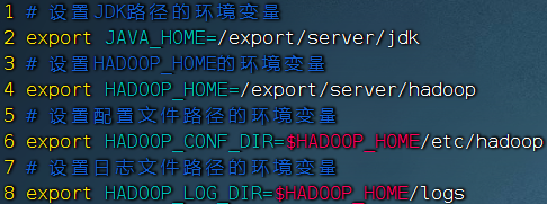
yarn-env.sh文件,添加如下4行环境变量内容:
![]() 编辑
编辑
export JAVA_HOME=/export/server/jdk export HADOOP_HOME=/export/server/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_LOG_DIR=$HADOOP_HOME/logs
![]()
yarn-site.xml文件,添加如下4行环境变量内容:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> <description></description> </property> <property> <name>yarn.web-proxy.address</name> <value>node1:8089</value> <description>proxy server hostname and port</description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description>Configuration to enable or disable log aggregation</description> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/tmp/logs</value> <description>Configuration to enable or disable log aggregation</description> </property> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> <description></description> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description></description> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/data/nm-local</value> <description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/data/nm-log</value> <description>Comma-separated list of paths on the local filesystem where logs are written.</description> </property> <property> <name>yarn.nodemanager.log.retain-seconds</name> <value>10800</value> <description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>Shuffle service that needs to be set for Map Reduce applications.</description> </property> </configuration>
![]()
配置完成之后就是启动啦:
start-yarn.sh
![]()
使用jps命令看看有没有两个Manager以及一个代理Server
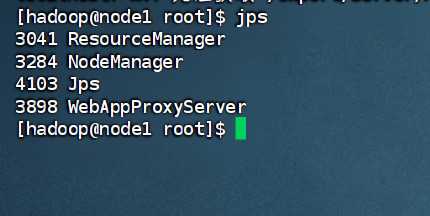
![]() 编辑
编辑
有的话打开浏览器输入http://node1:8088看看自己能否看到YARN集群的监控页面,可以看到就是成功啦。

![]() 编辑
编辑
集群
单单只是单节点部署的话,虽然是可以使用的,单这只是相当于你只有一台服务器呀,没有小弟的话就不能分布式存储以及计算啦,所以我们要创建几个小弟服务器来部署集群。
我们要创建另外两个虚拟机
![]() 编辑
编辑
![]() 编辑
编辑
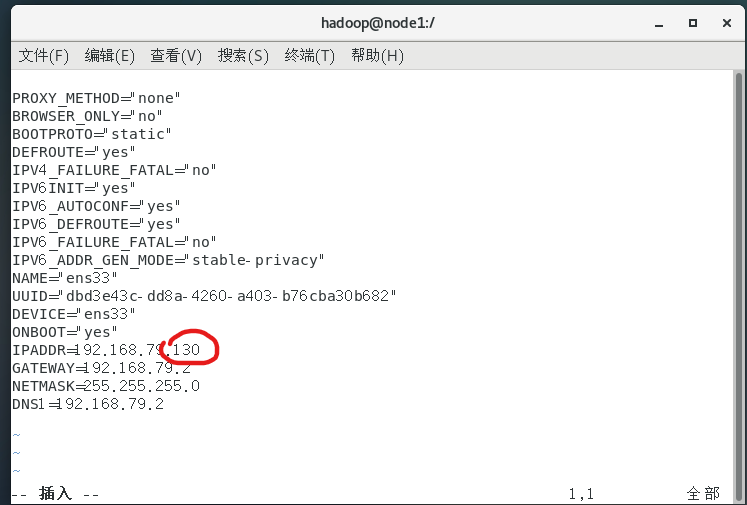
首先改ip,打开linux终端(Centos7)root用户下修改:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
![]()
![]() 编辑
编辑
改成同一子网的地址就好了这里我改成131
重启网络:
service network restart
![]()
修改主机名成新的主机名(我这里改成node2)
sudo hostname 新主机名
![]()
然后就是打开windows的cmd修改hosts主机映射:
notepad C:\Windows\System32\drivers\etc\hosts
![]()
加上node2保存
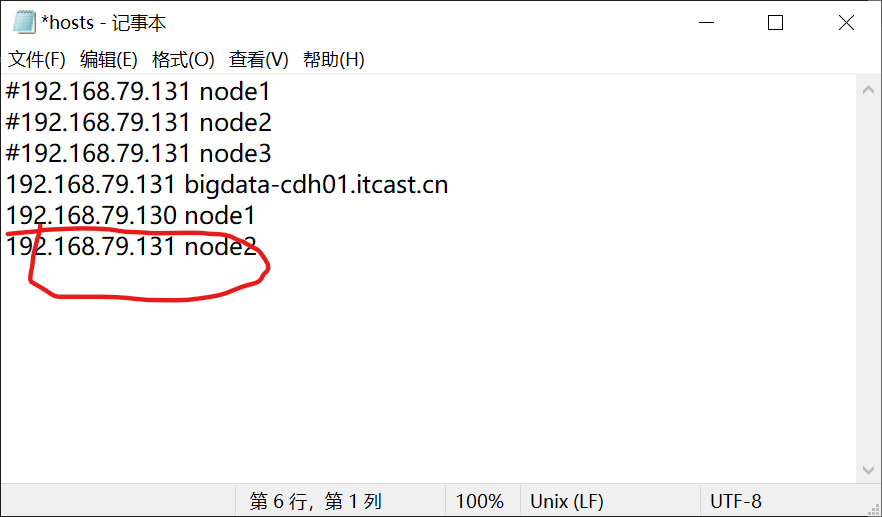
![]() 编辑
编辑
然后就是给node1跟node2两个用户配置免密登录(这个就不详细讲啦,百度有资料)
下一步就是修改一些配置文件(在node1用户中修改)

![]() 编辑
编辑
在hadoop的workers中增加node2节点(我们只克隆了这个,可以再加node3,有就加)
同一目录下

![]() 编辑
编辑
这里加上node2节点,原来只有node1一个节点
改完之后使用scp命令将hadoop文件夹复制到node2的用户当中就行啦
(设置免密登录之后复制,不免密好像也行会比较麻烦)
scp -r hadoop-3.3.4 node2:`pwd`/
![]()
#
集群部署常见问题
最后说一些集群部署的常见问题吧
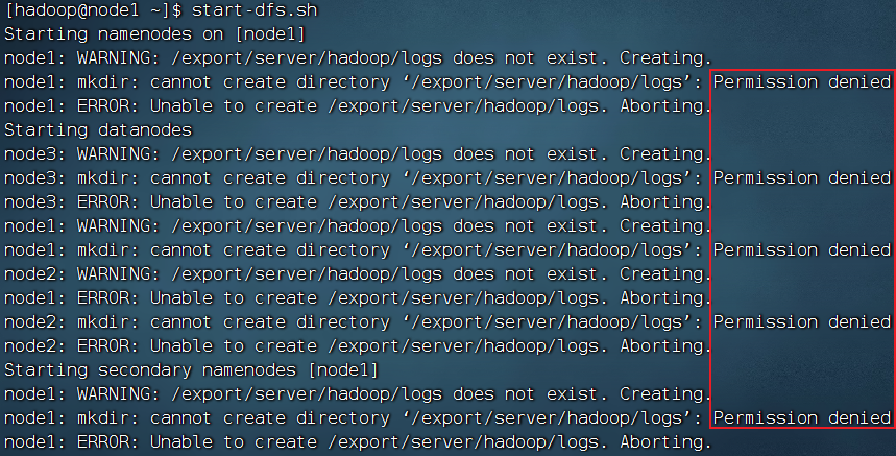
1.没有权限(这是由于你不是root用户没有操作这个文件夹的权限)
特此说一下,就是我们的集群启动通常是在普通用户下启动,因为使用root用户启动的话由于root用户权限过大会造成安全隐患所以建议使用普通用户来启动集群,这里的权限不足就是因为使用了普通用户来启动,这时候只要给用户赋予这个文件夹的操作权限就可以啦
![]() 编辑
编辑
在root用户下使用如下命令将hadoop文件夹的权限赋予给hadoop用户(假设这个用户叫做hadoop):
sudo chown hadoop:hadoop /export/server/hadoop
![]()
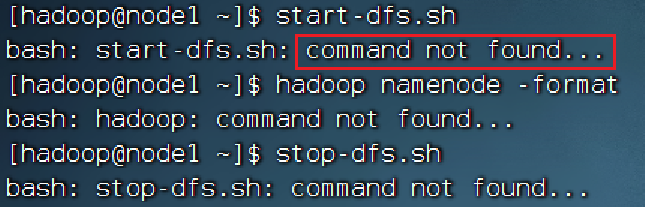
2.环境变量
这种没有找到命令的问题就是因为环境变量没有配置好,可以去检查一下自己的环境变量是否有问题,这些会导致/export/server/hadoop/bin/hadoop
/export/server/hadoop/sbin/start-dfs.sh & /export/server/hadoop/sbin/stop-dfs.sh这些 命令不能运行
![]() 编辑
编辑
3.logs日志(使用logs日志查看里面的内容可以解决你很多报错的问题)
![]()
暂时就是想到这么多啦,那就讲到这里。















 2496
2496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









