






点击上方“程序员大咖”,选择“置顶公众号”
关键时刻,第一时间送达!


一、初窥scrapy
scrapy中文文档:
http://scrapy-chs.readthedocs.io/zh_CN/latest/
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
scrapy是一个很好的爬虫框架,集爬取、处理、存储为一体,为无数爬虫爱好者所热捧,但个人认为对初学者并不友好,建议初学者打好基础再来看scrapy。
二、昨夜西风凋碧树,独上高楼,望尽天涯路(安装库)
本以为自己安装Python库已经有一定的理解和方法了,结果还是栽在了安装scrapy库上,本人是win7系统+Python3.5的环境。先给大家丢个安装Python库的网站:
http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
1 lxml库的安装 通过网站下载安装(具体安装方法见后面视频)
2 zope.interface库安装 pip3 install zope.interface
3 twisted库安装 通过网站下载安装
4 pyOpenSSL库安装 pip3 install pyOpenSSL
5 pywin32库安装 通过网站下载安装
6 pip3 install scrapy
你以为这样就结束了,天真,我在运行程序的时候说没有pywin32的DLL,当时我一脸懵逼,用黑窗口导入pywin32结果报错,还好在好友的帮助下解决了。
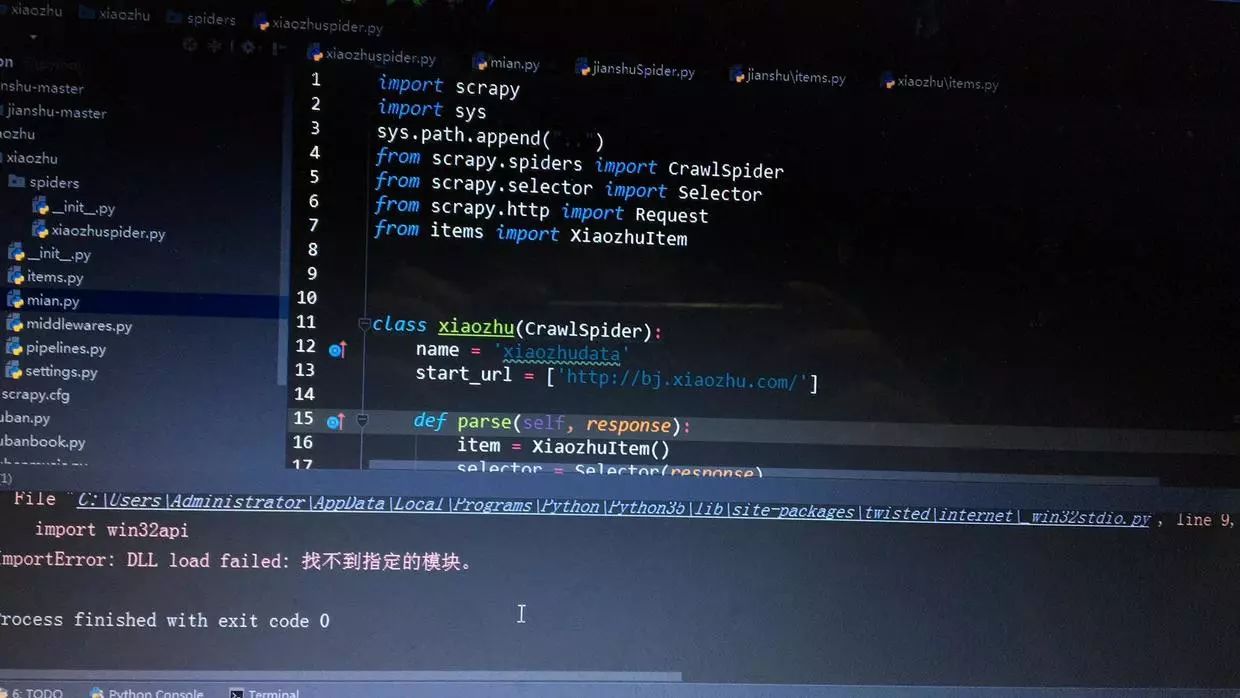
错误图
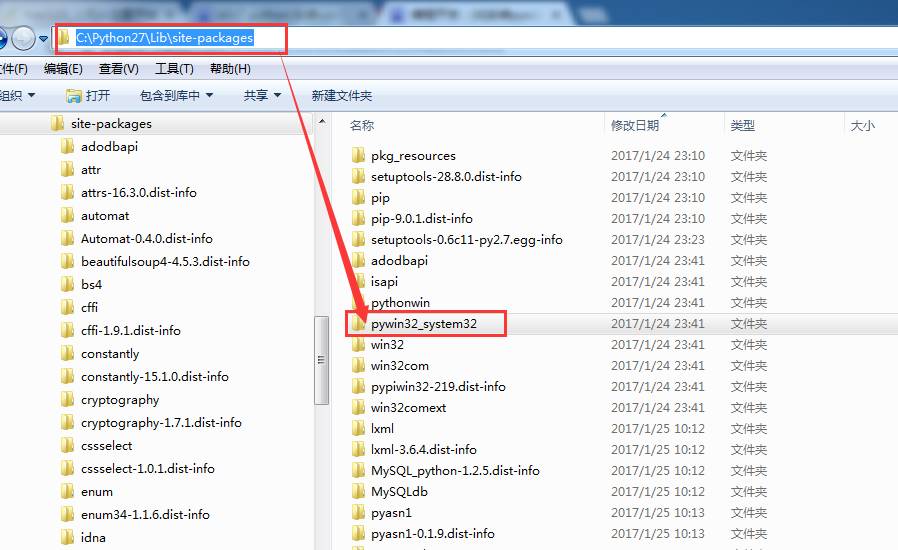
解决方法1

解决方法2
把图三的文件拷贝到C:WindowsSystem32
三、衣带渐宽终不悔,为伊消得人憔悴(各种出错)
创建scrapy项目:
scrapy startproject xiaozhu #今天还是爬取小猪短租数据scrapy项目文件结构:
xiaozhu/
scrapy.cfg #配置文件
xiaozhu/
__init__.py
items.py #定义需要抓取并需要后期处理的数据
pipelines.py #用于后期数据处理的功能
settings.py #文件配置scrapy
spiders/
__init__.py
...1 错误一
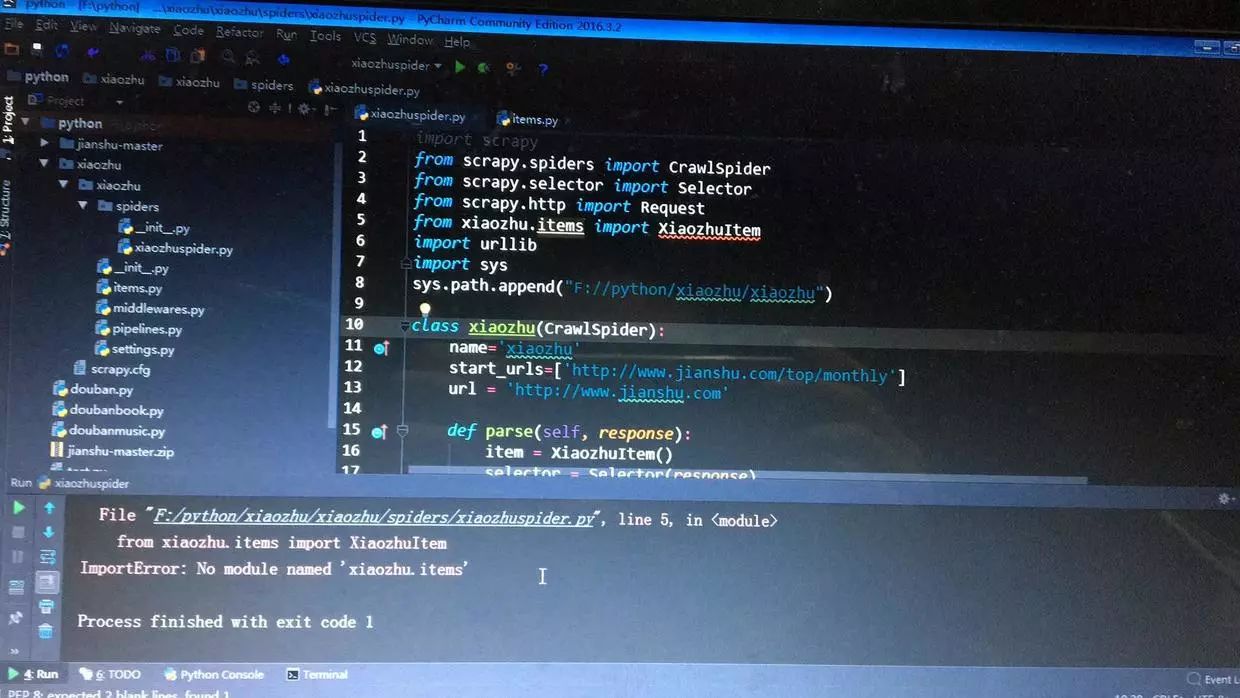
错误图

出错原因
解决方案代码见下
2 错误二
无法导出为csv,看了向右奔跑的导出csv代码,在我本地电脑无法导出
然来去scrapy文档看了下,对settings.py进行了修改如下:
FEED_URI = 'file:C://Users/Administrator/Desktop/xiaozhu.csv'
FEED_FORMAT = 'csv' #csv小写
四、纵里寻他千百度,蓦然回首,那人却在灯火阑珊处(代码运行成功)
1 items.py代码
from scrapy.item import Item,Field
class XiaozhuItem(Item):
address = Field()
price = Field()
lease_type = Field()
bed_amount = Field()
suggestion = Field()
comment_star = Field()
comment_amount = Field()
2 新建xiaozhuspider.py
import scrapy
import sys
sys.path.append("..") #解决问题1
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from scrapy.http import Request
from xiaozhu.items import XiaozhuItem
class xiaozhu(CrawlSpider):
name = 'xiaozhu'
start_urls = ['http://bj.xiaozhu.com/search-duanzufang-p1-0/']
def parse(self, response):
item = XiaozhuItem()
selector = Selector(response)
commoditys = selector.xpath('//ul[@class="pic_list clearfix"]/li')
for commodity in commoditys:
address = commodity.xpath('div[2]/div/a/span/text()').extract()[0]
price = commodity.xpath('div[2]/span[1]/i/text()').extract()[0]
lease_type = commodity.xpath('div[2]/div/em/text()').extract()[0].split('/')[0].strip()
bed_amount = commodity.xpath('div[2]/div/em/text()').extract()[0].split('/')[1].strip()
suggestion = commodity.xpath('div[2]/div/em/text()').extract()[0].split('/')[2].strip()
infos = commodity.xpath('div[2]/div/em/span/text()').extract()[0].strip()
comment_star = infos.split('/')[0] if '/' in infos else '无'
comment_amount = infos.split('/')[1] if '/' in infos else infos
item['address'] = address
item['price'] = price
item['lease_type'] = lease_type
item['bed_amount'] = bed_amount
item['suggestion'] = suggestion
item['comment_star'] = comment_star
item['comment_amount'] = comment_amount
yield item
urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(str(i)) for i in range(1, 14)]
for url in urls:
yield Request(url, callback=self.parse)
3 新建main.py(运行main.py就可以运行爬虫了)
from scrapy import cmdline
cmdline.execute("scrapy crawl xiaozhu".split())

结果
五、视频
没完全理解的同学可以观看视频讲解哦。
https://v.qq.com/x/page/t0356cp46sw.html

来自:罗罗攀
https://www.jianshu.com/p/e5ead6af4eb2
程序员大咖整理发布,转载请联系作者获得授权

















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









