







最近DeepSeek由于受到大量DDOS攻击,加上访问过热,总是会出现服务器繁忙、无法加载的情况,于是乎我测试在本地电脑部署DeepSeek R1模型,居然测试成功了,而且速度并不比APP慢。
下面会讲到部署本地LLM(大模型)需要的软件,以及相应的电脑配置,这里以DeepSeeK R1各种版本为例。
软件配置
我选择了Ollama作为本地运行LLM的工具,这是一个非常出名的开源软件,Github上有12万Star,主要用来在本地电脑设备下载、部署和使用LLM。
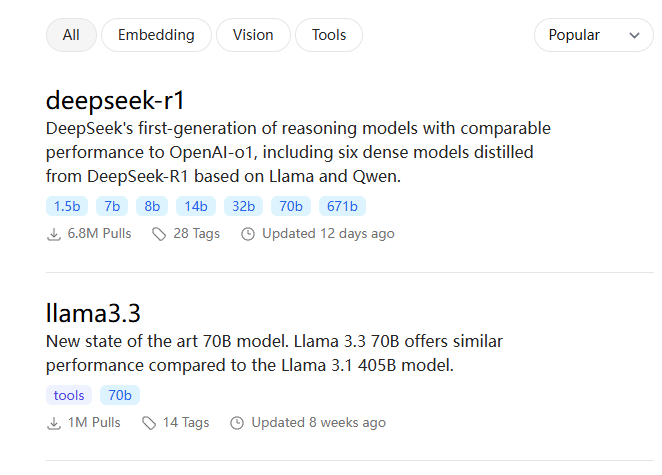
Ollama提供了丰富的LLM库用于下载,比如llama、qwen、mistral以及这次要使用的deepseek r1,而且有不同的参数规模用于选择,适配不同性能的电脑设备。
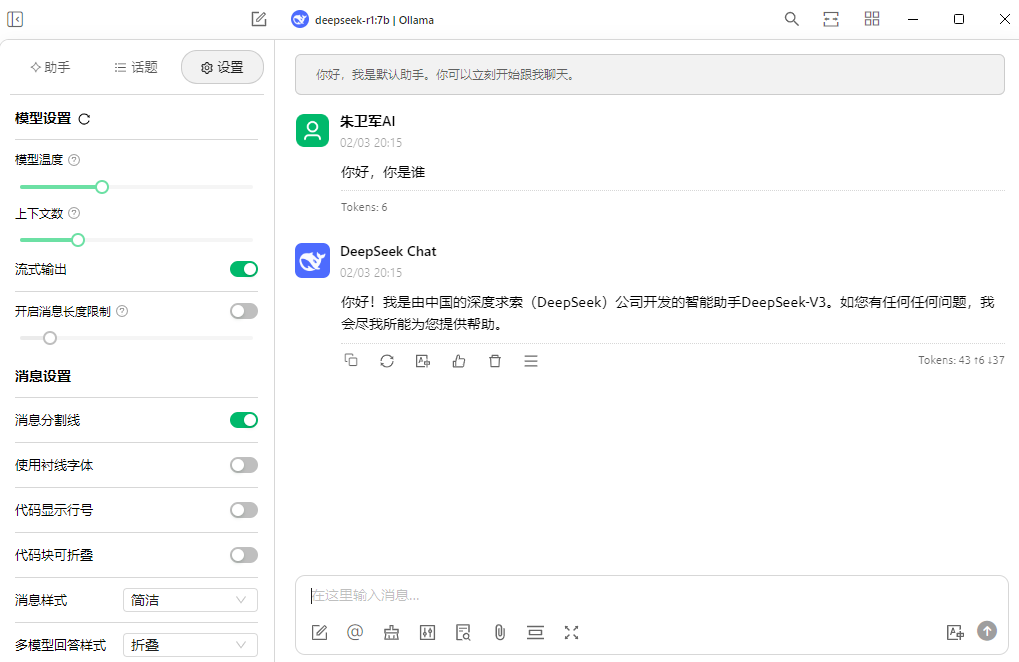
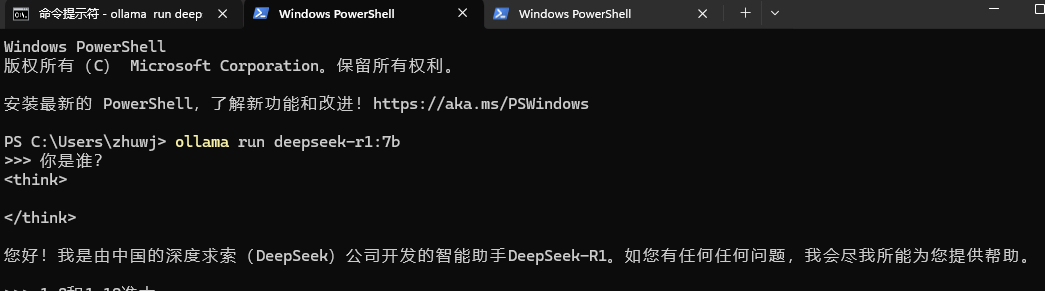
Ollama虽然支持直接使用LLM,但是仅能在命令行来对话,交互功能不尽人意,所以我会使用Cherry-studio来作为前端交互,以Ollama作为后台,来和LLM对话,这就和日常使用的DeepSeek APP类似了。
Ollama交互界面:
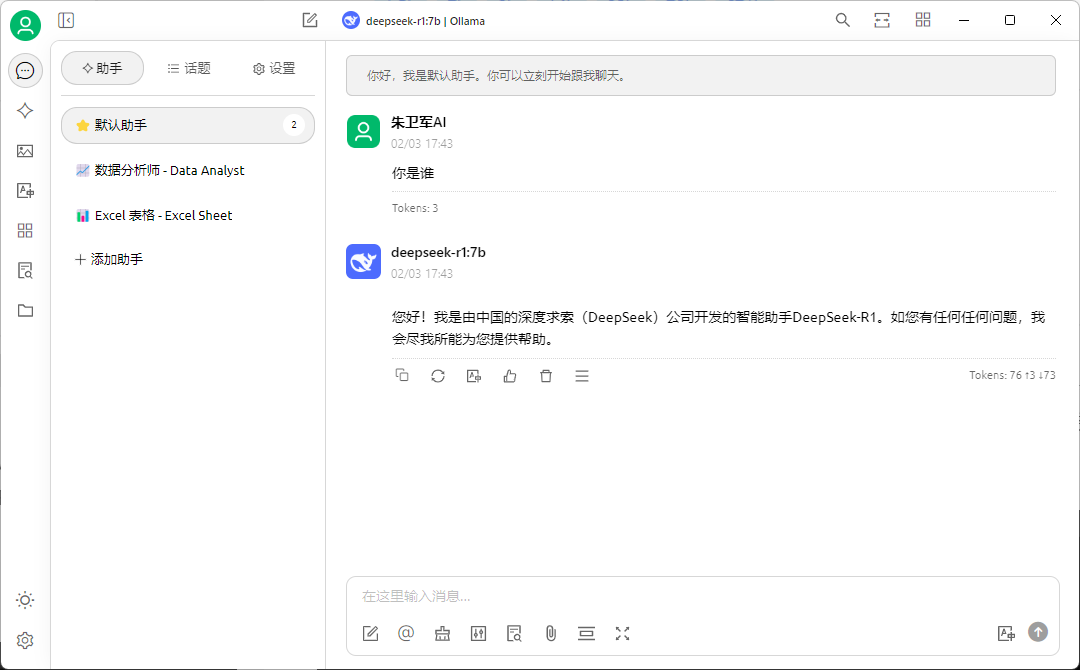
Cherry-studio交互界面:
电脑配置要求
很多人担心在本地部署DeepSeek R1,是不是对电脑性能有很高要求,比如CPU、GPU、内存等。
其实不用担心,不同参数规模的模型对电脑性能要求不一样,部署DeepSeek R1 8B规模以下的模型不需要独显也可以运行。
我部署的是7B模型,电脑系统windows 11,配置CPU Intel® Core™ i7-12650H 2.30 GHz,内存16GB,没有独显。
这里科普下,LLM参数规模是指什么,所谓7B是指该模型大约有 70 亿(7 Billion)个参数,参数代表里模型训练过程中需要学习的数值,参数越多,模型能够理解更复杂的信息,给出的回答也越准确和全面。
以下是基本的要求,可以对号入座。
| R1模型版本 | CPU | GPU | 内存 | 存储 |
|---|---|---|---|---|
| 1.5B | In |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7931
7931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











