











*本文系SDNLAB编译自Futuriom《Networking Infrastructure for Artificial Intelligence (AI)》报告
AI席卷了技术市场。然而,想开发出能推动各类垂直行业发展的企业级AI应用,需要一种新型的IT基础设施。这种基础设施要比传统集中式的客户端-服务器网络更快、更具可扩展性、更可靠。
英伟达黄仁勋曾表示:“加速计算已经到了转折点,‘通用计算’开始力不从心。我们需要另一种计算方式……”
黄仁勋所指的转变预示着整个技术栈的变化,其中就包括网络技术的变革。无论是超级计算机内部芯片的连接,还是AI集群内服务器的互联,亦或是将这些集群与网络边缘相连,所有技术都必须进化以支撑AI应用对性能的要求。
AI网络的市场趋势
更快的I/O
在AI网络的基础层,有着将CPU和GPU连接至内存以及在AI服务器内彼此相连的I/O连接。这些连接依赖于I/O标准,如PCIe、CXL等。
例如,作为AI网络市场的领导者,**英伟达支持NVLink。**据英伟达称,NVLink支持高达900Gb/s的GPU间速率,是PCIe带宽的七倍以上。为了在AI服务器中连接多个使用NVLink的GPU,英伟达提供了NVLink Switch,这是一种机架级芯片。通过NVLink Switch,NVLink连接可以跨节点扩展,创建一个无缝、高带宽、多节点GPU集群。
其他供应商也在构建类似的专有解决方案。例如,AMD提供Infinity Fabric架构,用于在其MI200加速器和EPYC处理器之间建立AI集群的连接。最近上市的Astera Labs提供了一款PCIe/CXL Smart DSP Retimer,它通过重新传输物理层信号来缩短AI服务器中CPU、DPU、存储和其他AI服务器组件之间的距离,从而提高整体性能。博通也提供自己的PCIe Retimer,并且最近声称发布了“世界上首款5nm PCIe Gen 5.0/CXL2.0和PCIe Gen 6.0/CXL3.1 Retimer”。
DPU
DPU从服务器的CPU中卸载网络和安全处理任务,有些还提供交换功能。DPU的使用并不局限于英伟达,博通和英特尔也是市场的领导者,像Acronix和Napatech等供应商也生产同时支持InfiniBand和以太网的DPU。
据说,微软正基于其2023年初通过收购初创企业Fungible所获得的技术,研发一款面向AI网络的DPU。Fungible开发了一款DPU,可在超大规模数据中心内汇聚固态硬盘存储,据报道,其性能比英伟达的DPU高出50%。
流量控制
AI网络对任何形式的拥塞、延迟、延时或数据包丢失都是零容忍的。因此,市场上出现了一系列旨在优化AI流量并使其“无损”的解决方案。
其中包括Arista采用的虚拟输出队列(VOQ),它消除了以太网数据包流中的某些延迟,并且当与调度结合使用时,确保了特定连接上的满额吞吐量。以太网芯片领导者博通在其Jericho3-AI芯片中集成了数据包调度,该芯片旨在为基于以太网的AI网络提供负载平衡、拥塞控制和零影响故障切换。
交换机快速发展
交换机对AI网络至关重要,它们使用InfiniBand和以太网技术,有多种配置。供应商正在积极采用新技术,可以预见在接下来的几年里,这个市场将会呈现出动态且快速发展的态势。
例如,英伟达的Quantum-2交换机在1U机箱中提供64个400 Gb/s的InfiniBand端口。这些交换机可与英伟达的 ConnectX网络适配器和BlueField-3 DPU协同工作。英伟达表示,其InfiniBand解决方案“融合了自修复网络功能、服务质量、增强的虚拟通道映射和高级拥塞控制,最大限度地提高了应用程序的整体吞吐量。”该方案专为超大规模或超大企业环境中的多租户网络而设计。
从2025年开始,英伟达将推出Quantum-X800平台,包括 Quantum Q3400 InfiniBand交换机,支持144个800 Gb/s端口,以及ConnectX-8 SuperNIC和专门设计的LinkX电缆和收发器。
为了支持以太网,英伟达提供了Spectrum-X平台,包括一个支持64个800 Gb/s端口的以太网交换机,以及一个支持400 Gb/s RoCE连接的BlueField-3 SuperNIC。2025年,英伟达将发布其Spectrum-X800平台,其中包括一个新的800 Gb/s交换机以及BlueField-3 SuperNIC。
以太网与InfiniBand
AI网络互连是选择InfiniBand还是以太网,这是业界一直在讨论的问题。
当前,得益于英伟达在市场上的绝对领导地位,以及InfiniBand在整体性能上相对于以太网所展现出的优势,自2020年英伟达收购Mellanox后,InfiniBand技术在大多数AI网络环境中占据了约80%至90%的市场份额。
InfiniBand通过支持由英伟达软件协调的并行数据流提供了更高的吞吐量。它的服务质量控制是细粒度的,基于消息的交互协议有助于消除数据包丢失。InfiniBand也是一种确定性技术,它直接支持RDMA。在2024年的GTC大会上,英伟达宣传其Quantum Q3400 InfiniBand交换机可提供端到端的800Gb/s速度。不过,这款交换机要到2025年才开始交付。
然而,InfiniBand的高昂成本成为了其与以太网竞争的一大劣势,加之其对英伟达硬件和软件的高度依赖,这在某种程度上限制了客户的自由选择,使他们不得不绑定在英伟达的产品生态中。此外,InfiniBand在普及度与支持度方面远不及以太网广泛。
与此同时,以太网要想与InfiniBand在性能优势上齐头并进,还需付出大量努力。
以太网所需的改进
2023 年 7 月,AMD、Arista、博通、思科、Eviden、HPE、英特尔、Meta 和微软宣布成立超以太网联盟 (UEC)。该组织的目标是开发一种“基于以太网的、开放的、可互操作的、高性能、全通信堆栈架构,以满足大规模AI和HPC不断增长的网络需求。”预计相关规范将在2025年出台。
**英伟达会加入UEC吗?**消息人士称,如果UEC有突出的研究进展,英伟达将支持该组织,但是否会加入仍是个未知数。

超以太网联盟创始成员
UEC旨在对以太网进行以下调整:
**无损数据流。**数据包丢失是以太网的固有缺陷,在AI网络中,供应商们已经采取了一系列技术来应对这一问题。例如,博通在其用于叶交换机的Jericho3-AI芯片中集成了智能调度功能,确保了数据包的可靠传输。Arista、思科、Juniper等公司也在它们的交换机中提供了调度功能,以此提升网络性能。
**RoCEv2改革。**Arista、博通、Juniper、思科等交换机供应商都支持RoCEv2,将其作为实现最大吞吐量的关键因素。但他们认为,RoCEv2需要彻底改革。具体而言,需要对RDMA本身进行研究。Arista首席执行官Jayshree Ullal在去年的博客文章中写道:“几十年前,InfiniBand Trade Association(IBTA)定义的传统RDMA在高要求的AI/ML网络流量中显得有些过时。RDMA以大流量的形式传输信息,这些大流量可能导致链路不平衡和过载。是时候从头开始,构建一个支持RDMA的现代传输协议,以适应新兴应用。”
**Packet spraying。**以太网本质上会在数据传输中导致数据包冲突。供应商有自己的负载平衡解决方案,但这些方案通常是专有的。现在有多种尝试方案确保数据包在多条路径上均匀分布。其中之一被称为Packet spraying,用Ullal的话来说,它“允许每个流同时访问到达目的地的所有路径”。
**更多的拥塞管理。**即使相对较小的流量错误也可能破坏整个AI工作负载,迫使其重新运行。UEC正在研究控制多路径传输的负载平衡的算法,以确保对昂贵的GPU的最佳利用。
以太网供应商计划挑战英伟达
迄今为止,英伟达在AI交换市场上一直占据主导地位,但以太网的演进为其他供应商提供了潜在机遇,使他们能够提供可行的替代方案。随着RoCEv2、PFC、ECN和Packet spraying等技术的广泛应用,以太网也许能媲美InfiniBand的性能。
虽然英伟达凭借其Quantum-X和Spectrum-X产品系列,能够同时支持InfiniBand和以太网,但其他网络供应商正通过基于以太网的解决方案进军AI网络市场。Ullal预测在Arista的下一财年,AI网络市场的机会将达到7.5亿美元。
Arista Networks
Arista Networks的7800R3系列交换机提供AI主干和核心功能,支持多达576个400 Gb/s的连接端口,以及包括VOQ等一系列功能。Arista的7060X交换机还支持400 Gb/s和800 Gb/s的数据速率。该供应商的高性能数据中心交换机,包括7800R3、7280R3、7060X和7050X3,均支持RoCEv2协议。
思科
思科在以太网版本中似乎看到了未来的希望,该版本增加了思科Silicon One ASIC,以在HPC环境和AI网络中与InfiniBand竞争。此外,思科的Nexus 9000交换机具有一系列功能,可以提高以太网数据包流的可靠性,包括PFC和ECN以及智能缓冲。该交换机使用RoCEv2进行AI网络。思科表示,它支持多个400 Gb/s端口,并准备提供800 Gb/s的连接。它还支持光纤通道和IP存储。
Juniper Networks
Juniper 提供QFX交换机(基于博通的Tomahawk 5芯片)、PTX路由器和线路卡,所有这些现在都支持400 Gb/s和800 Gb/s的无损连接,并与Apstra AIOps基于意图的软件协同工作,该软件还与Juniper的AI Native Networking Platform和Marvis Virtual Network Assistant相关联。PTX和QFX系列的几种型号都支持RoCEv2网络。Juniper希望其交换机和路由器能够“无偏见”,并与各种第三方SmartNIC/DPU兼容。
Enfabrica
初创公司 Enfabrica提供了一种用于AI服务器的计算到计算互联交换机,充当高带宽的“crossbar of NIC”,增强了集群内的计算、网络和内存连接。这款名为ACF-S的芯片增强了SmartNIC和PCIe交换机的功能。虽然尚未开始发货,但ACF-S原型已在多个会议和展会上展示数月,公司正在接受今年发货的订单。
AI网络架构
AI网络的架构随着AI用例的不断增加而各不相同。例如,英伟达的大型多GPU系统由NVLink和InfiniBand连接,并配备多个DPU,通常用于训练生成式AI应用的LLM。包括Meta、微软和谷歌在内的大公司是少数承担得起这些高度可扩展和复杂系统成本的买家,这些系统能够在多个集群中运行数千个GPU。
以Arista为例,其以太网叶交换机和主干交换机包含智能负载平衡功能,使以太网成为比InfiniBand更可行(更便宜)的选择。在下图中,展示了一个基于以太网的训练设置,顶部是前端网络,底部是配备有GPU和存储的后端网络。彩色圆圈相当于主干交换机,如Arista 7800,灰色圆圈表示叶交换机,可能是Arista 7050或7280平台。xPU”是指来自不同供应商的组件。
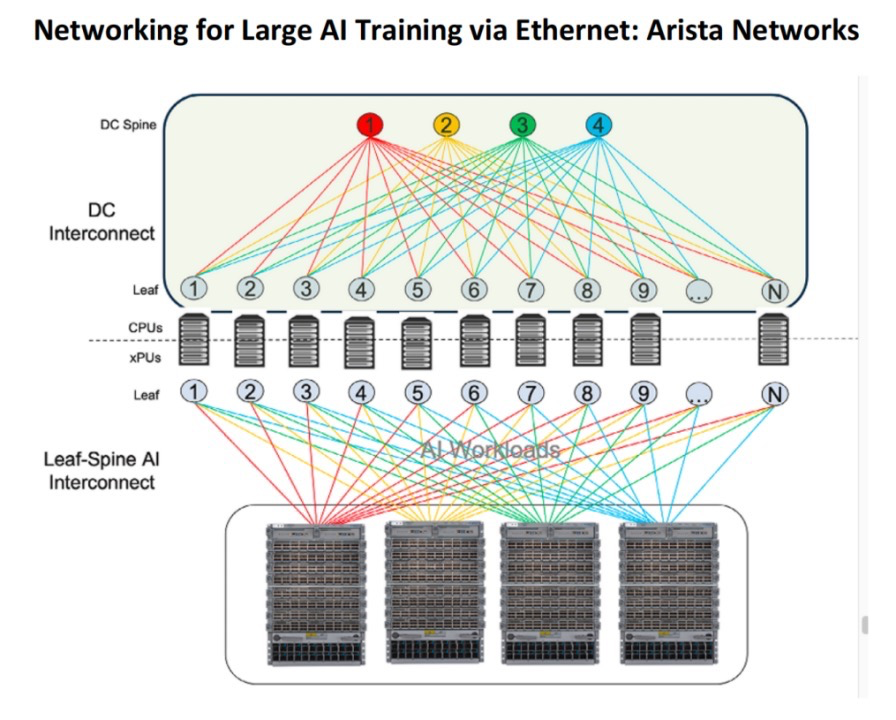
对于AI推理,有很多选择。一般来说,推理场景中仍然需要GPU,但数量较少,可能只需要几十个或几百个GPU。
Juniper 在下图中概括地描述了推理架构的不同需求:
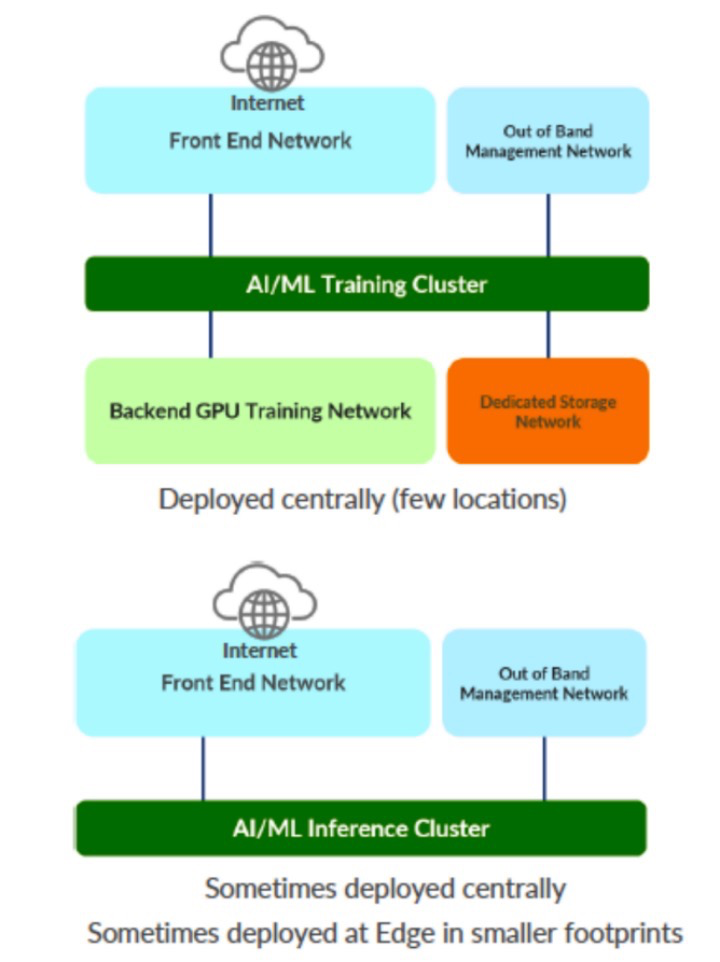
OR还是AND?
当谈到InfiniBand和以太网在AI网络中的实际应用时,目前两者都各占一席之地。谷歌网络工程师Amrinder R.在博客中写道:“很难断定哪一个更好。”目前,大多数超大规模数据中心运营商都在使用InfiniBand,并没有放弃的迹象。像Meta这样的企业则同时运行InfiniBand和以太网。
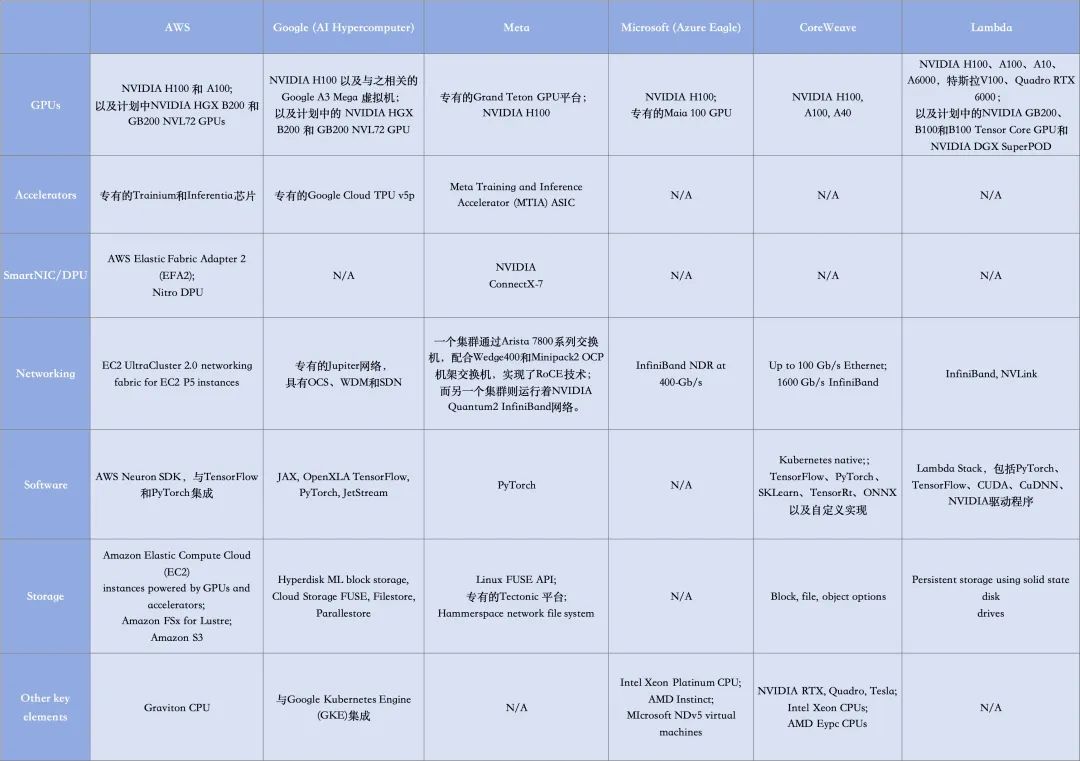
Meta对InfiniBand和以太网的实现如下图所示:

Meta基于Arista 7800、Wedge400和Minipack2 OCP机架交换机,构建了一个基于RoCE 网络fabric 解决方案的RDMA集群。另一个集群采用了英伟达Quantum2 InfiniBand结构。这两种解决方案都能互连 400 Gbps 端点。(更多信息可点击《揭秘 Meta 最新大规模AI集群技术细节!》)
其他AI网络部署选择
除了InfiniBand和UEC以太网之外,其他选择也正在崭露头角。
**DriveNets提供了一种Network Cloud-AI解决方案,**该方案采用分布式分散式机箱(DDC)方法,通过cell-based 架构将AI集群中任何品牌的GPU互连。该产品基于博通Jericho 2C+和Jericho 3-AI组件的白盒实现,能够以高达800 Gb/s的速度连接多达32000个GPU。
光网络也展现出了广阔的未来前景。
谷歌为其AI超级计算机创造了自己的光网络技术Jupiter。光学设备市场领导者Ciena表示,其在相干光学方面的专业能力使Ciena有机会推出加快数据中心互联速度的产品,可能也适用于AI数据中心。Ciena的竞争对手英飞凌提供了一种名为ICE-D的芯片,用于数据中心内部的连接。该芯片集成了一系列光学功能,通过串行和并行光纤配置,以1.6 Tb/s及以上的数据速率,在100米至10公里的距离内连接系统。它可以与电交换或光交换设备一起使用。
总结
“这是一场新工业革命的开始,这场工业革命关乎的不是能源生产,也不是食物生产,而是智能的生产。”
这种对AI的关注要求从通用计算过渡到黄仁勋所说的加速计算。加速计算环境的网络化必须实现AI网络所需的更低延迟、更高吞吐量、更大带宽和整体性能。AI工作负载不容忍任何延迟、拥塞或故障,任何环节的故障都会迫使整个任务重新运行。考虑到GPU及其相关AI组件的巨大成本,失败的后果是高昂的。
如今,英伟达在GPU市场的统治地位使其也成为AI网络领域最畅销的供应商。分别用于集群内和集群间GPU连接的NVLink和InfiniBand长期以来在超级计算环境中占据主导,且这种主导地位仍在延续。其他供应商以及他们所服务的企业都将以太网视为AI网络互连的另一选择。他们认为,以太网比InfiniBand更便宜,可用的专业知识范围更广,且不受单一企业销售的限制。这一切促成了UEC的成立。
与此同时,诸如Enfabrica之类的组件作为替代网络技术的一部分正在兴起,这些组件替换了一些交换机,提高了GPU集群的性能。
随着市场的发展,无疑会出现挑战InfiniBand的替代品,但并不会完全淘汰它。InfiniBand在超级计算市场上的长期主导地位,加上其悠久的高性能历史,将确保它在未来几年与任何替代品并驾齐驱。
`黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。

(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









