










在大模型发展如火如荼的今天,训练和微调一个大模型对于绝大部分普通工程师来说仍然是一个难题。为了降低大模型训练、微调门槛,北航发布了LLAMA FACTORY,一个旨在普及LLMs微调的框架。
LLAMA FACTORY通过可扩展的模块统一了多种高效微调方法,使得数百种语言模型能够在资源有限的情况下进行高吞吐量的微调。此外,该框架还简化了常用的训练方法,如生成式预训练、监督式微调、基于人类反馈的强化学习以及直接偏好优化等。用户可以通过命令行或Web界面,以最小或无需编码的方式自定义和微调他们的语言模型。

论文地址:https://arxiv.org/pdf/2403.13372.pdf
Github地址:https://github.com/hiyouga/LLaMA-Factory
摘要
本文提出LLAMA FACTORY,一个集成了一套高效训练方法的统一大型语言模型微调框架。它允许用户灵活定制100+ LLM的微调,而无需通过内置的web UI LLAMA板进行编码。实证验证了该框架在语言建模和文本生成任务上的效率和有效性。目前已在Github上开源,地址https://github.com/hiyouga/LLaMA-Factory。
简介
LLAMA FACTORY是一个可以让大众轻松微调LLM的框架。它通过可扩展的模块统一了各种高效的微调方法,使数百个LLM能够以最小的资源和高吞吐量进行微调。此外,它简化了常用的训练方法,包括生成式预训练、监督式微调(SFT)、从人工反馈中强化学习(RLHF)和直接偏好优化(DPO)。用户可以利用命令行或web界面自定义和微调他们的LLM,只需很少或不需要编码工作。
LLAMA FACTORY由三个主要模块组成:Model Loader,Data Worker和Trainer。最小化了这些模块对特定模型和数据集的依赖,使该框架可以灵活扩展到数百个模型和数据集。首先建立一个模型注册中心,模型加载器可以通过识别精确的层,将适配器精确地附加到预训练模型。然后,我们开发了一个数据描述规范,允许数据工作者通过对齐相应的列来收集数据集。提供了高效微调方法的即插即用实现,使训练器能够通过替换默认方法来激活。这些设计允许这些模块在不同的训练方法中重用,显著降低了新方法的集成成本。
LLAMA FACTORY基于PyTorch实现。在此基础上,我们提供了一个具有更高抽象级别的开箱即用框架。此外,我们构建了LLAM,一个Gradio的界面,实现了在不需要编码工作的情况下对llm进行微调。
LLAMA FACTORY遵循Apache-2.0许可证开源。它已经在GitHub上开源,获得了13000多个stars和1600个fork,并在Hugging Face Hub上的LLAMA FACTORY上构建了数百个开源模型。
高效的微调技术
高效的LLM微调技术可以分为两大类:专注于优化的和旨在计算的。高效优化技术的主要目标是在保持成本最低的同时调整LLM的参数。另一方面,有效的计算方法寻求减少LLM中所需的计算的时间或空间。
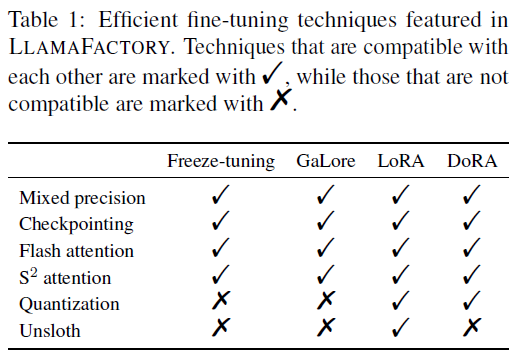
高效优化
LLAMA FACTORY使用了多种高效的优化技术,包括freeze-tuning方法、gradient low-rank projection方法、low-rank adaptation方法、weight-decomposed low-rank adaptation方法和LoRA+方法。这些方法可以提高模型的训练效率和内存使用效率。
高效计算
LLAMA FACTORY是一个整合了多种高效计算技术的框架,包括混合精度训练、激活检查点、闪存注意力、S2注意力、量化策略和适配器技术。通过这些技术的结合,LLAMA FACTORY能够显著提高LLM的效率,将内存占用从每个参数18字节或8字节降低到仅为0.6字节。
LLAMA FACTORY架构
LLAMA FACTORY是由三个主要模块组成:Model Loader、Data Worker和Trainer。Model Loader为微调准备了各种架构,支持100多个LLM。Data Worker通过一个精心设计的流水线处理来自不同任务的数据,支持50多个数据集。Trainer统一了高效的微调方法,以适应不同的任务和数据集,提供了四种训练方法。LLAMA BOARD为上述模块提供了友好的可视化界面,使用户能够以无代码的方式配置和启动单独的LLM微调过程,并实时监控训练状态。
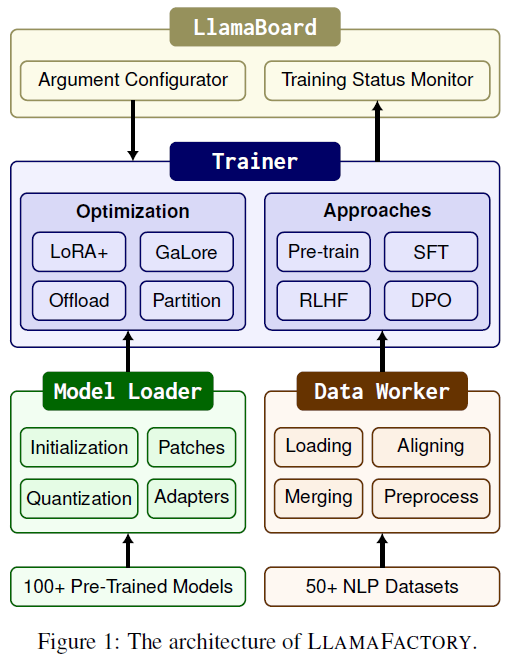
Model Loader
Model Loader是一个用于加载和初始化模型参数的框架。它包括四个组件:模型初始化、模型修补、模型量化和适配器附加。模型初始化使用Transformers库的AutoModel API来加载和初始化模型参数。模型修补通过替换模型的前向计算来实现flash attention和S 2 attention。模型量化可以将模型动态量化为8位或4位,支持多种后训练量化方法。适配器附加根据模型注册表自动识别适配器应该附加的层,并使用PEFT库来附加适配器。精度适应根据设备的能力处理预训练模型的浮点精度,使用不同的精度来加载模型参数。
Data Worker
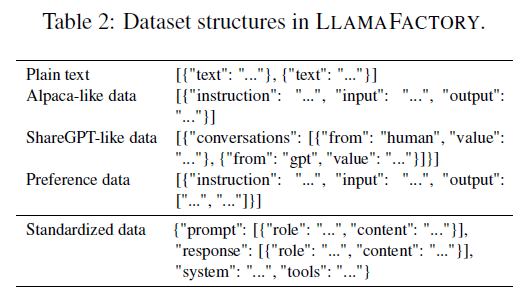
LLAMA FACTORY是一个数据处理管道,包括数据集加载、数据集对齐、数据集合并和数据集预处理。它将不同任务的数据集标准化为统一格式,使我们能够在各种格式的数据集上微调模型。我们使用datasets库加载数据集,设计数据描述规范来统一数据集格式,提供多个聊天模板和分层序列打包等预处理方法。
Trainer
**高效训练。**将最先进的高效微调方法集成到Trainer中,包括LoRA+、GaLore。利用transformer的Trainer进行预训练和SFT,而采用TRL的Trainer进行RLHF和DPO。
**模型共享RLHF。**提出模型共享RLHF,使整个RLHF训练不需要多于一个预训练模型。我们首先训练一个适配器和一个 value head,该 value head具有奖励建模的目标函数,允许模型计算奖励分数。然后我们初始化另一个适配器和 value head,并用PPO算法训练它们。在训练期间,通过PEFT的set_adapter和disable_adapter api动态切换适配器和 value head,使预训练模型同时作为策略、值、参考和奖励模型。据我们所知,这是第一个在消费设备上支持RLHF训练的方法。
**分布式训练。**我们可以将上述Trainer与DeepSpeed 结合起来进行分布式训练。利用DeepSpeed ZeRO优化器,可以通过分区或卸载进一步减少内存消耗。
其他工具
推理加速**。**在推理过程中,我们重用data worker中的聊天模板来构建模型输入。我们提供了使用transformer对模型输出进行采样的支持和vLLM,两者都支持流解码。实现了一个openai风格的API,利用vLLM的异步LLM引擎和分页注意力来提供高吞吐量的并发推理服务,便于将微调的LLM部署到各种应用程序中。
**综合评价。**评估指标包括多项选择任务,如MMLU、CMMLU和C-Eval,以及计算文本相似度分数,如BLEU-4和ROUGE。
LLAMA BOARD:LLAMA FACTORY统一接口
LLAMA BOARD是一个基于Gradio的统一用户界面,允许用户在不编写任何代码的情况下自定义LLM的微调。它提供了简化的模型微调和推理服务,使用户可以轻松地利用100多个LLM和50多个数据集。LLAMA BOARD具有易于配置、可监控的训练、灵活的评估和多语言支持等特点。用户可以通过与Web界面交互来自定义微调参数,并可以实时监视训练进度。此外,LLAMA BOARD支持自动评估模型的文本相似度分数或通过与模型聊天进行人工评估。目前,LLAMA BOARD支持英语、俄语和中文三种语言。
实证研究
本文从两个角度对LLAMA FACTORY进行评估:1)训练效率,包括内存使用、吞吐量和困惑度;2)适应下游任务的效果。
训练效率
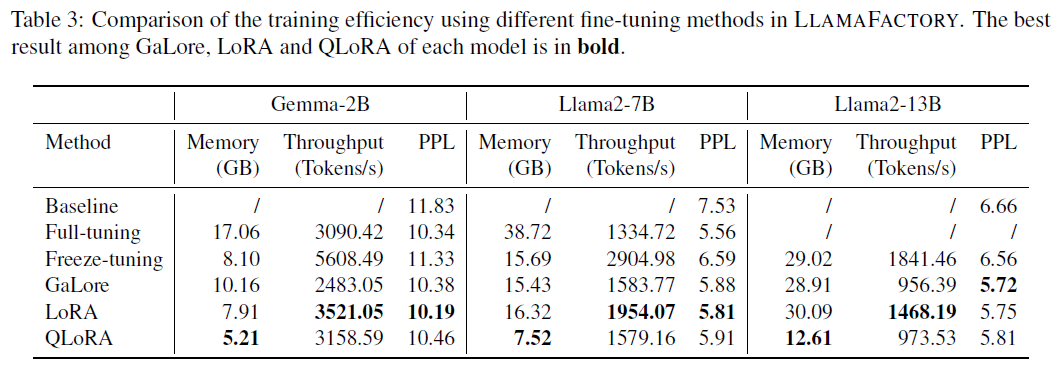
本文利用PubMed数据集进行实验,提取了约400,000个标记用于构建训练样本。通过fine-tune Gemma-2B、Llama2-7B和Llama2-13B模型,使用不同的fine-tuning方法进行比较。结果表明,QLoRA具有最低的内存占用,LoRA具有更高的吞吐量,GaLore在大型模型上具有更低的PPL,而LoRA在小型模型上具有优势。
下游任务微调
通过在下游任务上微调各种模型并比较它们的性能来进行评估。使用来自CNN/DM、XSum和AdGen三个代表性文本生成任务的2,000个示例和1,000个示例构建训练集和测试集。选择几个经过指令微调的模型,并使用不同的微调方法进行微调,包括全微调(FT)、GaLore、LoRA和4位QLoRA。微调后,计算每个任务的测试集上的ROUGE分数。将原始指令微调模型的分数作为基准。实验结果表明,LoRA和QLoRA在大多数情况下表现最佳,除了Llama2-7B和ChatGLM36B模型在CNN/DM和AdGen数据集上。这一现象突出了这些高效微调方法在适应特定任务中的有效性。此外,观察到Mistral-7B模型在英语数据集上表现更好,而Qwen1.5-7B模型在中文数据集上获得更高的分数。这些结果表明,微调模型的性能也与其在特定语言上的内在能力有关。

总结和未来工作
LLAMA FACTORY是一个统一的框架,可用于高效微调超过100个LLM模型。通过模块化设计,最小化模型、数据集和训练方法之间的依赖关系,并提供一种集成的方法来进行微调。此外,LLAMA BOARD提供了一个灵活的Web UI,可以在不需要编码的情况下进行自定义微调和评估LLM。该框架在语言建模和文本生成任务上得到了实证验证。未来,LLAMA FACTORY将与最先进的模型和高效微调技术保持同步,并探索更高级的并行训练策略和多模态高效微调LLM的可能性。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 6288
6288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









