






2024年5月11日,华为AI4SCI Lab团队联合北京航空航天大学科学智算团队,推出新一代方程通用求解模型智算天璇OmniArch-α,为大规模复杂动力系统的正反求解提供统一的解决方案。该项成果在鲲鹏昇腾开发者大会2024上首次亮相,预计下半年正式发布。

图1 北航周号益博士现场发布智算天璇基础模型OmniArch-α预览版
在全球范围内,北航智算天璇(OmniArch)模型首次实现了在1D、2D、3D的PDE数据联合训练,实现几十类正反求解问题的统一求解,在zero-shot的数据集上相比现有SOTA方法精度提升1个数量级,在流体、电磁、气象等多物理场和多方程耦合场景发现了“物理场-方程”联合学习的scaling-law涌现。该项工作是团队国家级科研项目的重要成果,为了促进学术交流和产业应用,代码将在昇思MindSpore社区开源和cnai4s.com上线服务(链接附在文末)。
PDE基础模型 = 物理场 + 方程 + 时序演化
OmniArch模型将流体力学、电磁学、气象学等多学科PDE求解问题统一为物理场时序演化形式,从而将其转变为适用于Transformer架构的机器学习问题,首次实现一维到三维的联合求解,并扩展到工业级全流场仿真。此外,OmniArch还引入了物理信息增强的强化学习(Physics-Informed Reinforcement Learning,PIRL),以实现求解过程中最大程度还原物理定律的准确性和鲁棒性。
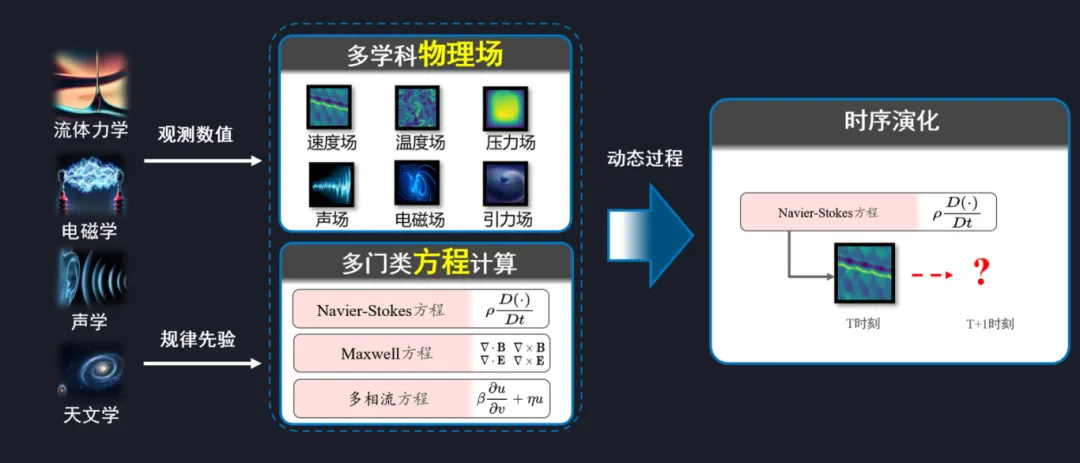
图2 OmniArch方程求解统一范式流程图
OmniArch对于1D、2D、3D不同的微分方程表达,采用卷积神经网络进行空间维度的物理场压缩,获得沿时间维度的物理场演化的Token序列,然后利用类LLaMA架构的Transformer模型,根据物理系统的不同分量个数进行分组时序回归,模拟传统有限元方法中的积分过程,最后模型使用逆卷积网络,根据预测的物理场Token进行全物理场的彻底重构。值得一提的是,OmniArch的架构首次实现了1D、2D、3D的PDE共享骨架求解网络,并显著提高了自研架构的扩展效率和并行效率。
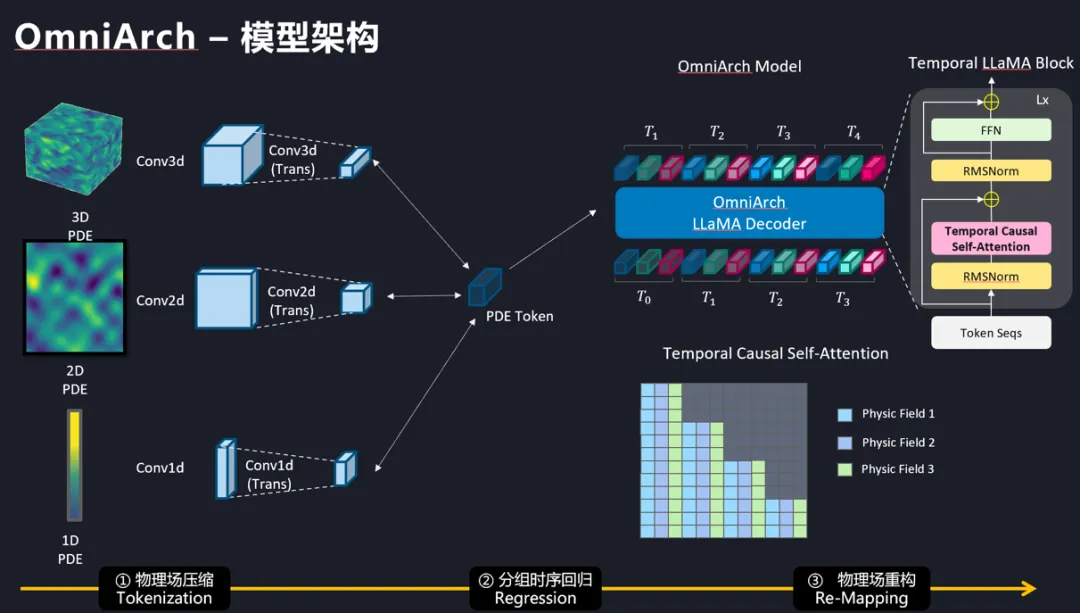
图3 OmniArch架构图(以预训练阶段为例,包含物理场压缩、分组时序回归、物理场重构三个步骤)
对于物理方程约束的引入,OmniArch独创地提出了一种对齐框架PIRL,合理运用对比学习,构建PDE文本描述-物理场观测数据的multi-alignment模型。针对PDE方程文本描述(<0.1K)数据量与物理场观测点(<1M)极度不匹配的现状,OmniArch采用了规则生成的PDE增强流水线,在采集的100个PDE方程的基础上,合成约1000倍不同的PDE方程描述。训练后的物理场耦合模型可以为多物理系统进行“消歧”,在PDEBench[1]的11个物理系统上进行区分度探针实验,其平均准确率超过了95%。
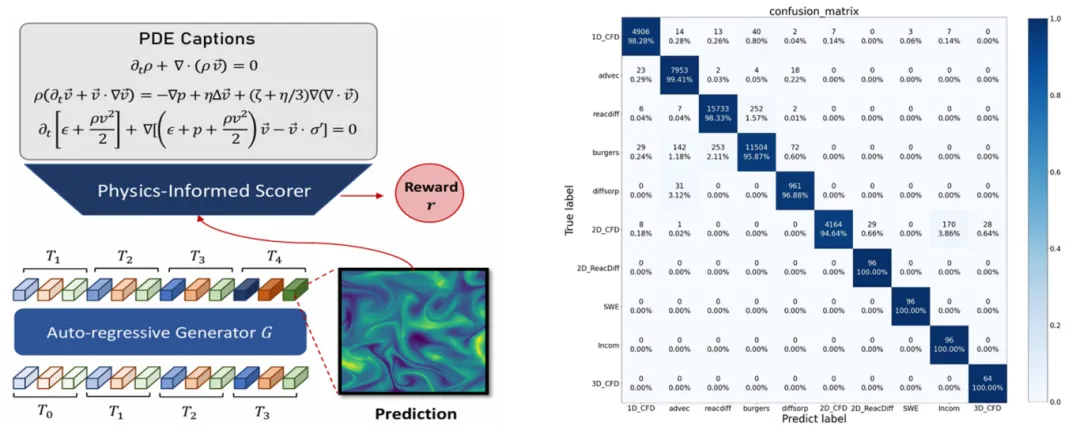
图4 Physics-informed Reinforcement Learning(PIRL)框架(左)与探针实验结果(右)
从OmniArch窥见“物理场-方程”联合学习的scaling-law
在公开研究领域,与OmniArch类似的“通用”模型往往只实现了某个维度的支持,如MPP-2D[2]等。通过在1D、2D、3D的联合训练,OmniArch首次实现了单个模型,单份权重即可对FNO、PINNs、U-Net等40余个不同参数下PDE专用模型的全方面超越,其中CFD、ReacDiff等流体力学算例实现了一个数量级的精度提升。
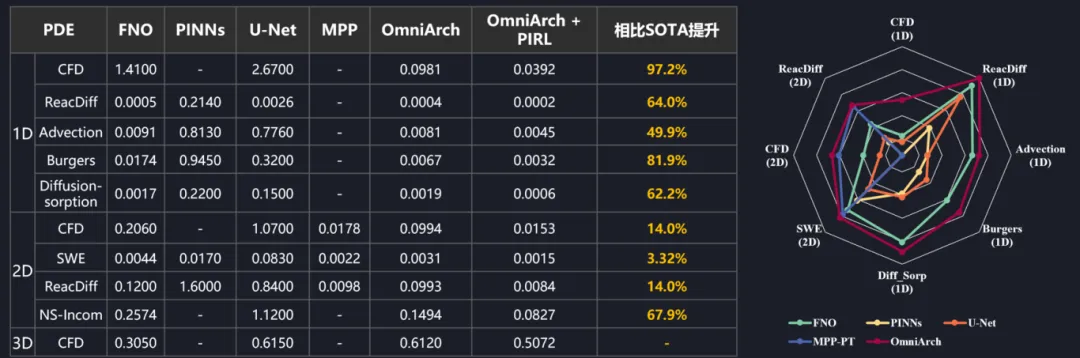
图5 北航智算天璇模型OmiArch在PDEBench的结果(采用nRMSE评估,从左到右分别是传统单场景模型FNO、PINNs、U-Net,SOTA多场景模型MPP[2])
通过在超过4TB的PDE数据集上进行预训练,OmniArch模型展现出了类似于大模型的涌现能力。对于OOD的动态物理系统,OmniArch模型可以不改变模型参数(即zero-shot)的情况下,直接从给定的前序物理场变化中学习物理运算符。在Advection、CFD、SWE等物理系统上,研究团队观察到随着输入物理场序列上下文的长度增加,模型求解精度稳定提高。值得一提的是,In-context Learning能力是现代大模型Chain-of-Thoughts和RAG等能力的先导,有望拓展到物理系统的增强式自适应推理,彻底告别“手工作坊式”专家模型训练。
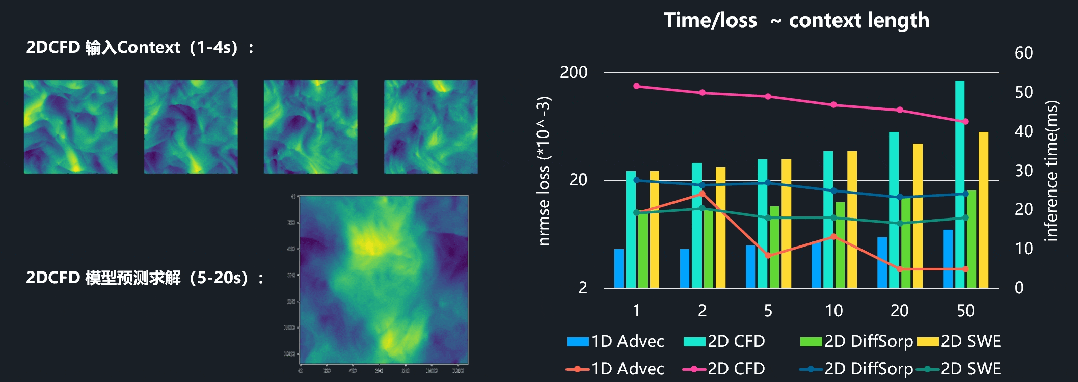
图6 OmniArch的涌现能力:PDE In-context Learning情境学习(左图2DCFD预测的样本,右图横轴表示Prompt长度,纵轴1表示推断精度损失,纵轴2表示推断时间)
研究团队构建了Tiny(0.5B)、Small(0.5B)、Base(1.2B)、Large(2.6B)四种参数规模的OmniArch基础模型,观察到了从30M到0.5B,模型收敛速度与参数规模成正比例关系,当模型参数规模超过1B时,损失函数开始稳定下降,且不再过拟合。另外,模型性能增长依赖于物理场观测数据规模,目前开源数据规模约106,可支持模型极限大小约2.6B。
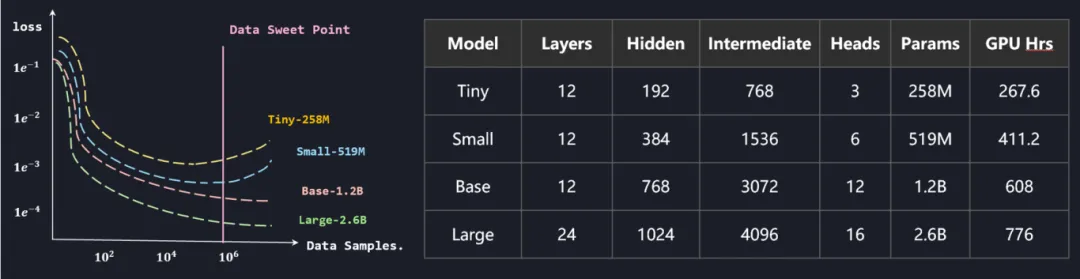
图7 科学智算基础模型的Scaling Law(左图表示不同数据样本下训练曲线过程,右表是四个不同规模大小模型的具体尺寸参数)
研究团队在方腔流(Cavity)、圆柱绕流(Cylinder)、堤坝流(Dam)、圆管流(Tube)等四类常用流体PDE上对OmniArch基础模型进行微调。相比于Polymathic AI发布的MPP-2D方程求解通用模型[2],OmniArch仅需50个样本左右,就可实现1e-3级别求解精度(领先1个以上数量级),充分展现了较高的迁移数据效率和广泛的应用灵活性。此外,在处理方程高阶项反演、方程边界条件反演等挑战逆问题,该模型展示出极高精度和逻辑性,从另外一个侧面展示出基础模型极大的普适性。
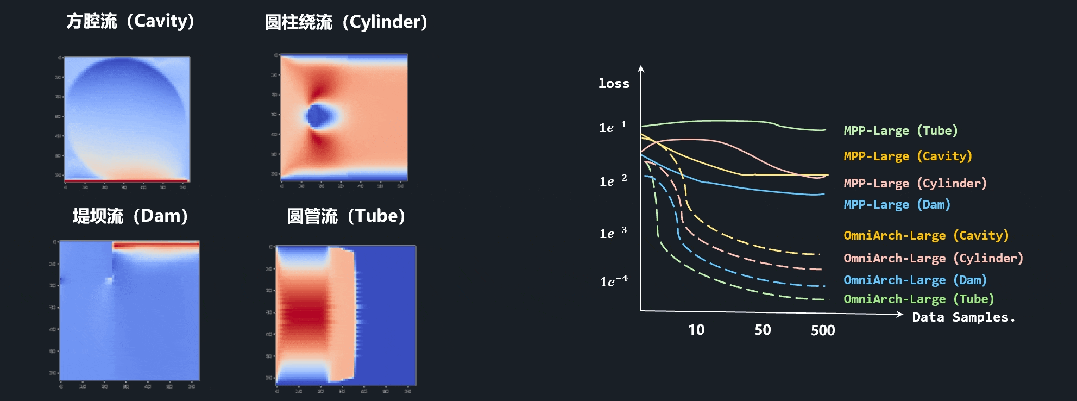
图8 在CFDBench[3]等经典流程问题上微调效率(与Polymathic AI的MPP[2]对比,左图为四类典型问题的示例,右图为微调时模型损失函数下降曲线)
昇腾、昇思AI生态支撑PDE通用求解模型发展
依托昇思MindSpore AI框架的开发训练微调部署全方位支持,以及昇腾AI处理器强大的半精度计算能力,OmniArch模型规模实现与PDE数据的同步快速扩展。OmniArch基于昇腾AI基础软硬件高度协同优化的傅里叶变换和分组时序回归等技术,已加速赋能MindSpore Flow等新一代流体力学科学计算套件,并有望实现自主创新软硬件生态能力的最大化释放。
了解更多,请查看论文:

论文链接:https://arxiv.org/pdf/2402.16014
平台网站:https://cnai4s.com/
北航、昇思MindSpore开源社区等共同承担人工智能科学计算共性平台研发和门户运营。
更多发布信息请关注公众号:ACTBIGDATA
参考链接
[1]Takamoto, M. et al. PDEBENCH: An Extensive Benchmark for Scientific Machine Learning. Preprint at https://doi.org/10.48550/arXiv.2210.07182 (2023).
[2]McCabe, M. et al. Multiple Physics Pretraining for Physical Surrogate Models. Preprint at https://doi.org/10.48550/arXiv.2310.02994 (2023).[3]Luo, Y., Chen, Y. & Zhang, Z. CFDBench: A Large-Scale Benchmark for Machine Learning Methods in Fluid Dynamics. Preprint at https://doi.org/10.48550/arXiv.2310.05963 (2024).

















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









