







 本文档详细介绍了如何搭建一个完全分布式Hadoop集群,包括集群拓扑设计、虚拟机安装、克隆、配置以及SSH服务的配置,确保实现各节点间免密登录。通过在虚拟环境中设置master和两个slave节点,关闭SeLinux并配置静态IP,为后续的大数据处理打下基础。
本文档详细介绍了如何搭建一个完全分布式Hadoop集群,包括集群拓扑设计、虚拟机安装、克隆、配置以及SSH服务的配置,确保实现各节点间免密登录。通过在虚拟环境中设置master和两个slave节点,关闭SeLinux并配置静态IP,为后续的大数据处理打下基础。
(一)Hadoop集群拓扑
1、集群拓扑
一个主节点,两个从节点
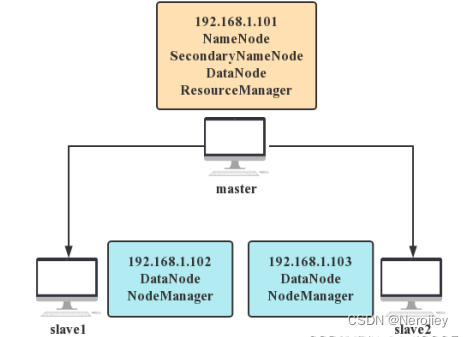
2、角色分配
完全分布式Hadoop集群搭建需要在集群的每个节点都安装Hadoop,集群角色分配如下表所示。
| 节点 | 角色 |
|---|---|
| master | NameNode, DataNode |
| slave1 | DataNode |
| slave2 | DataNode |
(二)虚拟机安装
Hadoop集群的搭建要涉及到多台机器,而在日常学习和个人开发测试过程中,这显然是不可行的,为此,可以使用虚拟机软件(例如VMware Workstation)在同一台电脑上构建多个Linux虚拟机环境,从而进行Hadoop集群的学习和个人测试。
安装了虚拟机CentOS 7

配置了静态IP地址(192.168.1.100)和主机名(ied)

关闭与禁用了防火墙

安装了vim编辑器

(三)虚拟机克隆
1、克隆类型
(1)完整克隆
完整克隆是对原始虚拟机完全独立的一个拷贝,它不和原始虚拟机共享任何资源,可以脱离原始虚拟机独立使用。
(2)链接克隆
链接克隆需要和原始虚拟机共享同一虚拟磁盘文件,不能脱离原始虚拟机独立运行。但是采用共享磁盘文件可以极大缩短创建克隆虚拟机的时间,同时还节省物理磁盘空间。
2、克隆步骤
(1)克隆出master虚拟机
关闭CentOS 7虚拟机,在VMware工具左侧系统资源库中右键单击CentOS 7,选择“管理”列表下的“克隆”选项,弹出克隆虚拟机向导。


选择克隆源——虚拟机中的当前状态

选择克隆类型——创建链接克隆

设置新虚拟机名称和位置

单击【完成】按钮

单击【关闭】,查看master虚拟机

(2)克隆出slave1虚拟机
按照克隆master虚拟机的步骤克隆出slave1虚拟机

(3)克隆出slave2虚拟机
按照克隆master虚拟机的步骤克隆出slave2虚拟机
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3493
3493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









