






一、背景
本文我们继续介绍一个针对超长上下文的 LLM 推理加速工作,同样是 Token 稀疏化的方案,来解决 LLM 在超长序列场景计算量大、GPU 显存消耗大的问题,不过结合了 ANN 检索,可以实现更高的精度。
对应的论文为:[2409.10516] RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
二、摘要
本文中作者提出了 RetrievalAttention,无需训练就可以加速 Attention 计算。为了利用 Attention 的动态稀疏特性,RetrievalAttention 在 CPU 内存中使用 KV Cache 构建近似检索(ANN)索引,并在生成过程中通过向量检索识别最相关的索引。由于 Query 向量和 Key 向量之间存在 Out-Of-Distribution(OOD)问题,现成的 ANN 检索仍然需要扫描 O(N) 数据(通常占所以 Key 的 30%)进行准确检索,无法利用高稀疏性。
为了解决这个挑战,RetrievalAttention 采用注意力感知向量检索算法,可以调整 Query 只访问 1-3% 的数据,从而实现亚线性时间复杂度。RetrievalAttention 大幅降低了长上下文 LLM 推理的成本,大幅降低 GPU 显存需求,同时保持模型准确性。特别的,RetrievalAttention 只需要 16GB 内存就可以在具有 8B 参数的 LLM 上支持 128K Token的推理,在单个 RTX4090(24GB)上可以在 0.188s 内生成一个 Token。
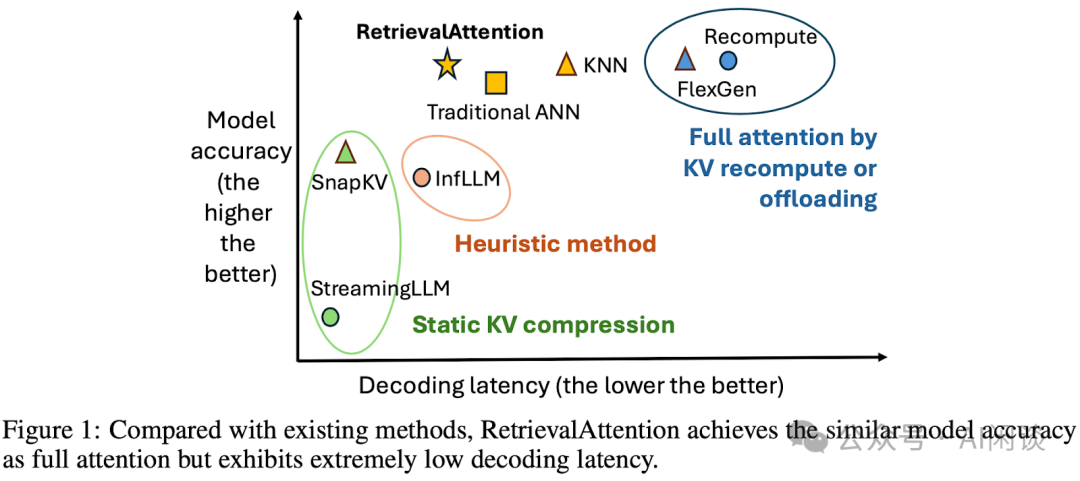
如下图 Figure 1 所示为本文方法与几种常见方案的对比(PS:可以看出,本文方案相比之前 Token 稀疏化方案,是在牺牲一定推理速度的情况下提升精度):
三、方法
3.1 背景
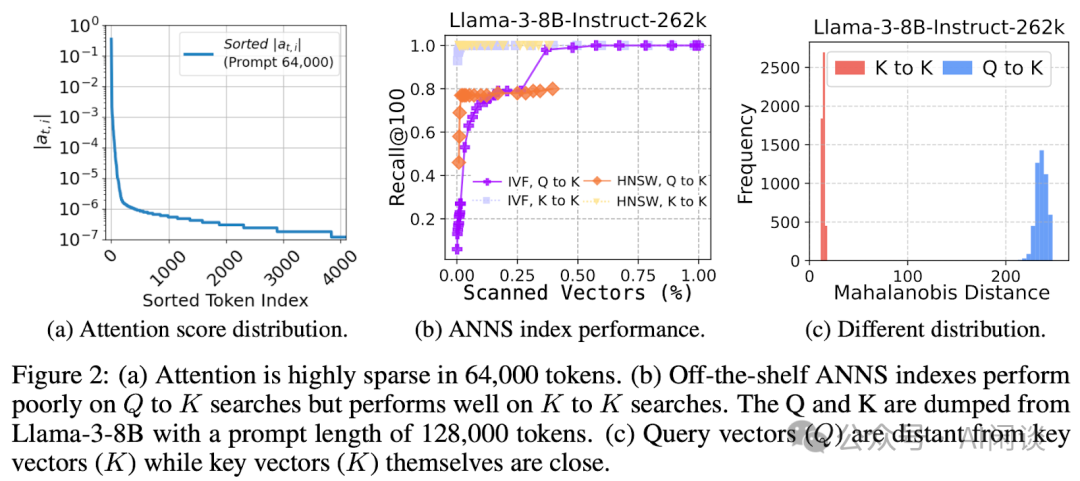
使用 ANN 来识别关键 Token 有个独特的挑战:当前大部分的 ANN 引擎都假设 Query 向量和 Key 向量满足相同的分布,以此来实现高召回率。作者在这篇论文中首次提出这种假设在 Attention 机制中不成立。Query 的这种 OOD 特性损坏了 ANN 的预期检索质量,从而导致不得不访问更多的数据来保持正确性,作者实验表明,为了维持可接受的准确率,至少需要扫描 30% 的 Key 向量。
如下图 Figure 2 所示:
-
(a)Attention Score 具有非常高的稀疏性,64000 个 Token,只有不到 500 Token 的 Score 大于 10-6。
-
(b)Q 和 Q 或者 K 和 K 的相关性很高,而 Q 和 K 的相关性很差,需要扫描 30% 左右的 Token 才能保证 0.8 左右的召回率。
-
(c)同样说明了 Q 和 K 的距离比较远。
3.2 概览
本文的工作主要聚焦于 Token Decoding 阶段,会假设 Prefill 阶段已经执行完成,比如通过 Context Caching 方案或 Prefill 和 Decoding 分离方案。
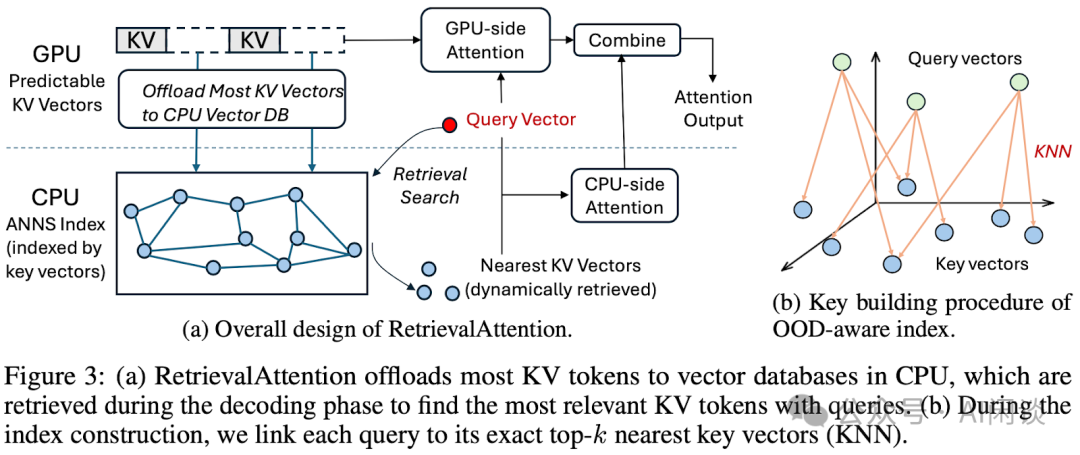
如下图 Figure 3(a)所示为本文方案 RetrievalAttention 的概览,其利用 CPU 侧的 ANN 检索来实现近似 Attention 计算,为了支持长序列,也会将所有 KV Cache Offload 到 CPU 内存以便构建索引。如图(b)所示是为了解决 OOD 问题而采用的索引机制。
3.3 近似 Attention
具体来说,不使用完整的 Attention Score,而是采用最相关的 KV 向量来近似 Attention Score:
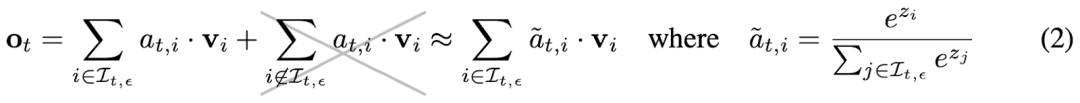
3.4 Attention 感知向量检索
对于每对 Key 和 Value,首先确定是放在 CPU Memory 还是 GPU Memory(方法见下一小节)。然后 Offload 到 CPU 内存的 Key 和 Value 会使用 Key 来构建索引,并使用 Query 来检索。
为了加速 Token 生成过程中的向量检索速度,RetrievalAttention 利用 Prefill 阶段的现有 Query 来指导 Key 向量的索引构建。如上图 Figure 3(b)所示,RetrievalAttention 显式的建立从 Query 向量到其最近的 Key 向量的连接(即精确的 K 个最近邻,或 KNN)。KNN 结果可以通过 GPU 高效计算,形成从 Query 向量分布到 Key 向量分布的映射。使用这种结构,Decoding 的 Query 向量查询时可以首先查询最近的 Query 向量,然后将其映射为 Key 向量。
因此,之前的 Query 向量充当了解决 OOD 问题的桥梁。然而,这种结构在内存开销和搜索效率方面仍然存在缺陷,因为除了 Key 向量之外,还需要存储和访问 Query 向量。为了解决这个问题,作者利用先进的跨模态 ANN 索引 RoarGraph 中的投影技术来消除 Query 向量。具体来说,通过使用 Query 向量和 Key 向量的连接关系,将 KNN 连接投影到 Key 向量中,从而有效地简化搜索。此外,此方法也允许对未来的 Query 向量进行高效的索引遍历。
作者实验结果表明,通过这种 Query 和 Key 的连接关系进行有效建模,向量数据库只需扫描 1-3% 的 Key 向量即可达到高召回率,与 IVF 索引相比,索引搜索延迟大幅降低 74%。
3.5 CPU 和 GPU 协同执行
为了利用 GPU 并行性加速注意力计算,RetrievalAttention 将注意力计算分解为两组不相交的 KV Cache 向量:GPU 上的可预测向量和 CPU 上的动态向量,然后将两部分 Attention 输出合并在一起作为完整的 Attention 输出。
具体来说,利用 Prefill 阶段观察到的模式来预测 Token 生成过程中持续激活的 KV 向量。与 StreamingLLM 类似,作者将固定的几个初始 Token 和最近窗口内的 Token 作为静态 Token,持久化在 GPU 上。RetrievalAttention 也可以适配更复杂的静态模式,以便实现低推理成本和高准确性的平衡。为了最大限度减少通过慢速 PCIe 的数据传输,RetrievalAttention 在 CPU 和 GPU 上独立计算 Attention,然后将其组合起来,这个灵感来自 FastAttention([2205.14135] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness)。
四、评估
4.1 实验配置
机器包含三个:
-
RTX 4090 GPU(24G 显存),Intel i9-10900X CPU(20 Core),128 GB 内存。
-
A100 GPU(80GB 显存),AMD EPYC CPU(24 Core)。
-
A100 GPU(80GB 显存),AMD EPYC 7V12 CPU(48 Core),1.72TB 内存。
模型包含三个:
-
LLaMA-3-8B-Instruct-262K
-
Yi-6B-200K
-
Yi-9B-200K
对比框架包括:
-
Full Attention 的 vLLM
-
StreamingLLM
-
SnapKV
-
InfLLM
基准测试包括:
-
∞-Bench
-
RULER
-
Needle-in-a-haystack
4.2 长文本任务精度
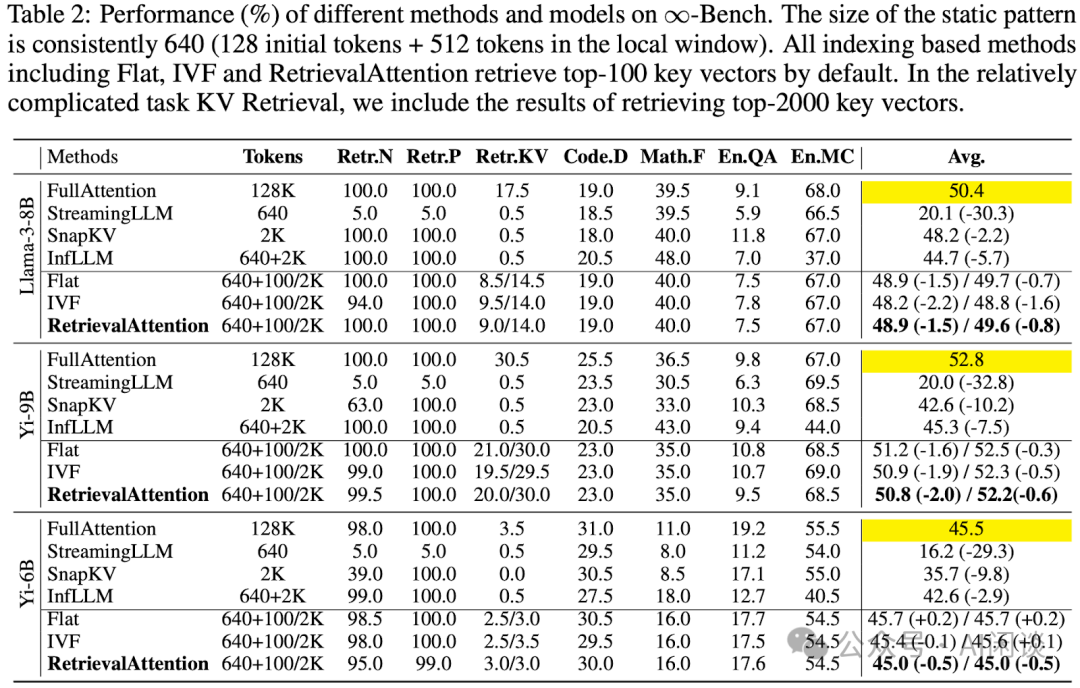
如下图 Table 2 所示,本文提出的 RetrievalAttention 明显优于之前的方案,平均精度非常接近 Full Attention。当然,部分模型上 Flat(暴露检索索引数据) 会略好于 RetrievalAttention,不过差距不大。
4.3 时延评估
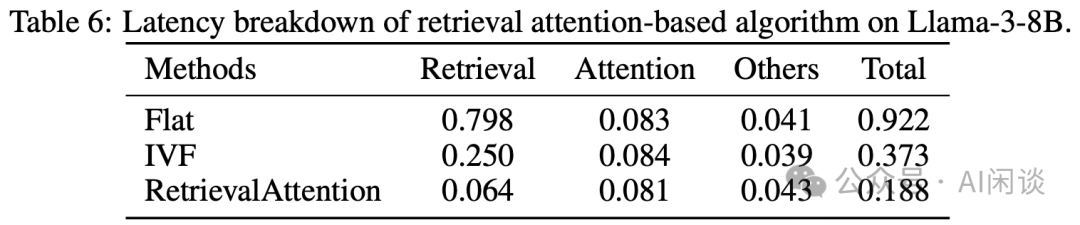
如下图 Table 6 所示,作者首先验证了本文提出的检索方式的有效性,可以看出,提出的 RetrievalAttention 相比 Flat 和 IVF 可以提供 4.9x 和 1.98x 的加速,证明了检索机制的有效性:
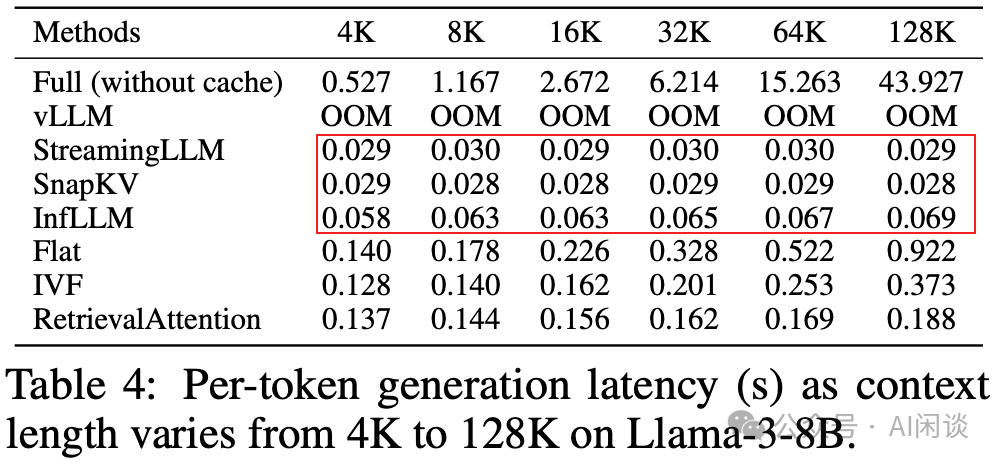
如下图 Table 4 所示,作者也与之前的其他稀疏化方案进行对比,可以看出,之前的方案往往采用固定的 Token 数,因此随着序列变长并没有明显增加时延,而本文的方法会略微增加。同时,本文方法推理 Latency 相比之前方法明显增加,大概是之前方法 Latency 的 3x-6x。然而其仍然明显低于 Full Attention(FlexGen) 的结果。相当于在效果和速度之间的折衷。
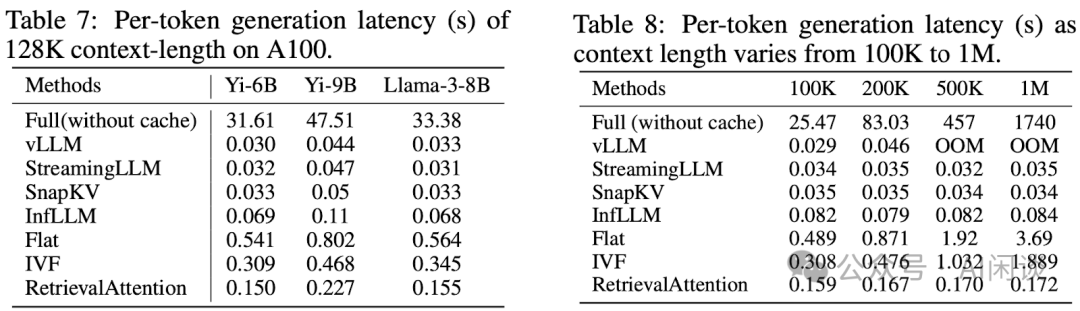
如下图 Table 7 和 Table 8 为在 A100 上的结果,结论类似,不过在 100K 和 200K 时其 Latency 会超过 vLLM:
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









