







1.爬虫的概念
爬虫是一种自动地获取网页数据并存储到本地的程序。它的主要作用是获取网站上的数据,这些数据可以用于分析、研究、开发等多种目的。爬虫可以帮助我们获取网站上的数据,而不需要人工浏览和抓取。爬虫的分类主要有通用爬虫和聚焦爬虫。通用爬虫是指搜索引擎和大型web服务提供商的爬虫,它们抓取的是一整张页面数据。聚焦爬虫是针对特定网站的爬虫,它们定向的获取某方面数据的爬虫。

2.爬虫应用场景
爬虫的应用场景非常广泛,主要包括以下几个方面:
- 数据分析和研究:爬虫可以获取网站上的数据,然后进行分析和研究,从而获取有价值的信息。
- 新闻聚合:爬虫可以抓取多个网站上的新闻内容,并将其整合到一个地方,方便用户查看。
- 电子商务:爬虫可以抓取网站上的商品信息,并将其整理成报表,方便商家分析和决策。
- 数据挖掘:爬虫可以抓取网站上的数据,并将其转换成机器可以理解的格式,从而进行数据挖掘和分析。
3.爬虫的工作原理和流程
- 确定爬虫的目标网站和需要抓取的数据。
- 编写爬虫的代码,包括爬虫的起始地址、结束地址、请求头、爬取的数据类型等。
- 运行爬虫程序,将爬虫代码发送到目标网站。
- 目标网站返回响应数据,爬虫程序将其存储到本地。
- 爬虫程序对存储的数据进行处理和分析,得到需要的数据。
- 爬虫程序重复以上步骤,直到爬虫的目标数据被抓取完毕。
举例来说,我们可以使用Python编写一个爬虫程序,用于抓取一个电子商务网站上的商品信息。我们可以使用requests库发送HTTP请求,使用BeautifulSoup库解析HTML响应,然后将抓取的数据存储到本地。这个爬虫程序可以定期运行,从而获取该网站上的商品信息。这些商品信息可以用于分析和研究,从而帮助商家做出更好的决策。
4.爬取网页
想要爬取网页的内容,首先我们需要审查页面元素。以我的博客 陆理手记 为例,如果想要抓取Python教程分类下所有的文章标题,我们可以先进入分类页进行审查页面元素。
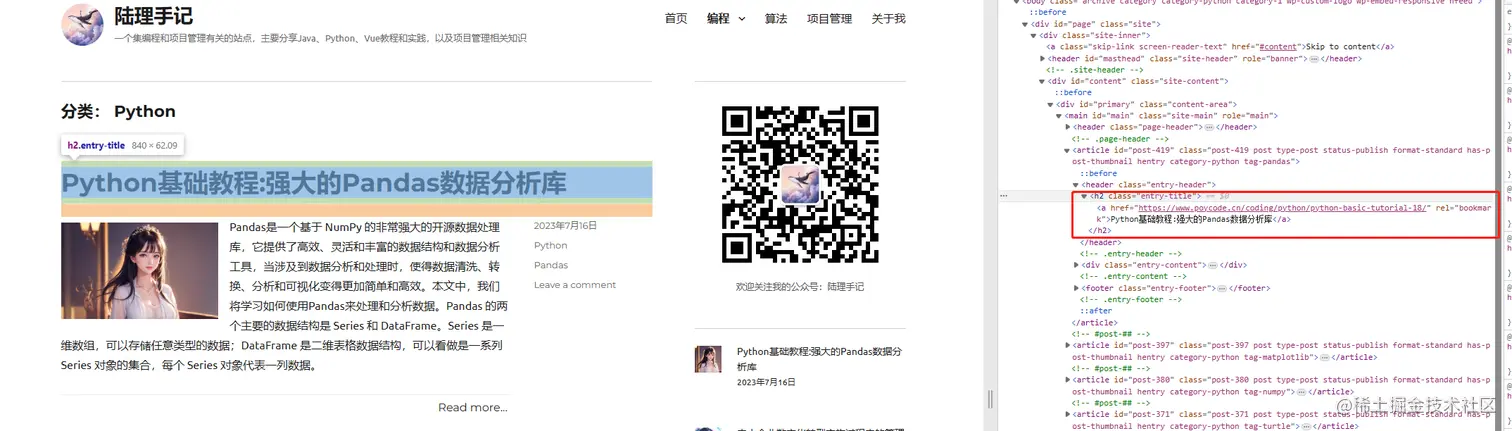
判断网页可抓取后,可以使用之前教程 Python基础教程:requests模块发送http请求 | 陆理手记) 提到过的requests模块进行网页请求,请求到网页内容后,再对内容进行解析,提取我们所需要的数据,这里用到的就是BeautifulSoup模块。
5.BeautifulSoup模块应用
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导,可以通过标签名、属性或文本内容搜索和修改网页内容,使用 BeautifulSoup,可以轻松地从复杂的 HTML 或 XML 文档中提取信息,并将其用于 Python 程序中。
python
代码解读
复制代码
pip install bs4 # 安装完成后 from bs4 import BeautifulSoup
下面我们举个简单的例子,以抓取我的博客 陆理手记 中Python分类的文章标题为例
python
代码解读
复制代码
# -*- coding: utf-8 import requests from bs4 import BeautifulSoup resp = requests.get("http://www.poycode.cn/category/coding/python/") print(resp.status_code) soup = BeautifulSoup(resp.content) # 格式化html输出 print(soup.prettify()) # 获取所有class='entry-title'的h2标签 tags = soup.find_all('h2', class_='entry-title') for tag in tags: a_tag = tag.find('a') print('Title:[%s], URL:[%s]' %(tag.text, a_tag['href']))
输出结果:
ruby
代码解读
复制代码
Title:[Python基础教程:sklearn机器学习入门], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-19/] Title:[Python基础教程:强大的Pandas数据分析库], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-18/] Title:[Python基础教程:Matplotlib图形绘制], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-17/] Title:[Python基础教程:NumPy库的使用], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-16/] Title:[Python基础教程:Turtle绘制图形], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-15/] Title:[Python基础教程:使用smtplib发送邮件], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-14/] Title:[Python基础教程:requests模块发送http请求], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-13/] Title:[Python基础教程:装饰器], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-12/] Title:[Python基础教程:多线程编程], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-11/] Title:[Python基础教程:正则表达式], URL:[http://www.poycode.cn/coding/python/python-basic-tutorial-10/]
上述代码中,首先通过requests库请求python教程的分类页面,获取到整个html文档。然后我们使用BeautifulSoup(html, features='html.parser')解析该html文档,便能获取到一个BeautifulSoup对象。features是解析器,有如下几种,这里我们使用Python内置的标准库。
soup_html.find_all('h2', class_='entry-title')是查找html文档中所有的 class='entry-title' 的 h2 标签,BeautifulSoup提供了许多方便快捷强大的标签搜索功能,这里就不一一介绍,原因是我认为:Beautiful Soup 中文文档 已经写的非常详细,如果你需要进行爬虫相关的编程,查阅也是非常方便的。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") | Python的内置标准库 执行速度适中 文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快 文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"])``BeautifulSoup(markup, "xml") | 速度快 唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") | 最好的容错性 以浏览器的方式解析文档 生成HTML5格式的文档 | 速度慢 不依赖外部扩展 |
6.总结
本文简单介绍了爬虫的基础知识以及需要用的库和方法,并做了非常简单的示例。总地来说,爬虫就是模拟网络请求,并解析、提取出我们想要的数据。爬虫可以帮助我们更快地获取网站上的数据,为工作和生活带来诸多便利。当然,也希望在学习 python 爬虫的过程中,大家能够更好的理解和应用 python的语法。
最后这里给大家免费分享一份Python学习资料,包含了视频、源码、课件,希望能够帮助到那些不满现状,想提示自己却又没用方向的朋友,也可以和我一起来交流呀!
编辑资料、学习路线图、源代码、软件安装包等!【点击这里】领取!
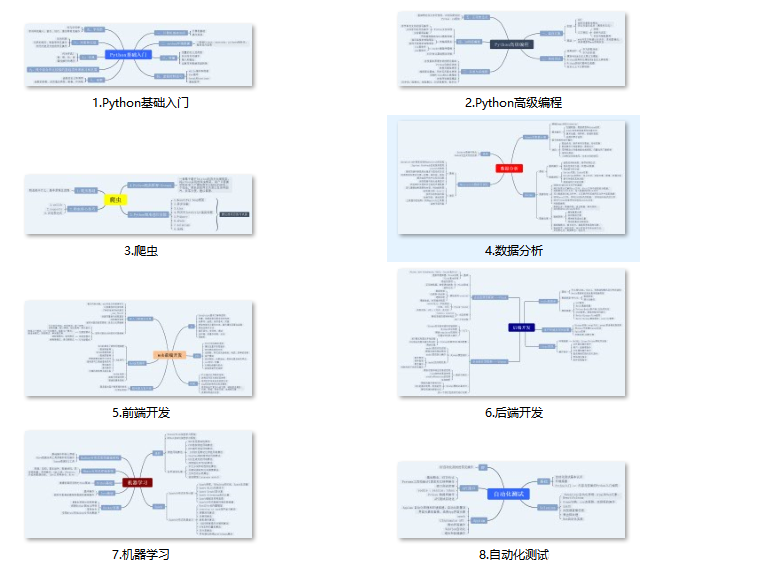
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。




















 4623
4623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









