







SVM -支持向量机原理与实践之实践篇
最近太忙,这几天还是抽空完成实践篇,毕竟所有理论都是为实践服务的,上一篇花了很大篇幅从小白的角度详细的分析了SVM支持向量积的原理,当然还有很多内容没有涉及到,例如支持向量回归,不敏感损失函数等内容,但是也不妨碍我们用支持向量机去实现一个分类系统,因为有了对前面说讲述知识的一定的了解,就可以很好的为我们这一篇的实践内容服务。
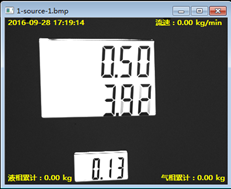
下面我们的实验内容,看下图中的几张图片,我们的目标是将图像中白底的数字字符串识别出来。

图一

图二
我们可以看到上图中的两张图片,他们的照片效果都还好,预计识别的难度不会很大,但是我们还有很多的样本,他们的效果可能会很不好,就像第一张图片中有点歪,但是可能会有样本歪得很厉害,第二张中我们看到字符后面还有阴影,我们看的很清晰,但是有的样本后面的阴影会很大,可能达到导致人眼有时候都会有错觉,最重要的是有时候我们的需求可能不是要我们识别图片中的某一串数字字符,而不是所有字符,就像我们这个试验中的目标一样(要识别第二行中的字符),所以我们首先需要对字符进行定位,字符定位以后我们还需要对字符进行分割,分割之后还会运用ANN即人工神经网络算法对它进行识别,当然这不是这一篇实践内容的需要讲解的内容。
我们这一篇实践内容主要讲解的是,在对原始图像的进行预处理以后,我们会得出一些有效的样本和一些无效的样本,也就是说,我们通过图像处理技术,处理和定位之后,我们仍然会得到一些有用的和没用的样本,我们如何将这些样本区分开来,也就是运用SVM支持向量机算法对这些样本进行分类,分类好以后,将有效的样本传到ANN模型对字符进行识别。
我们前面讲到,在获取原始的图像样本以后我们还需要对图像进行预处理,处理后我们还是会的到一些不无效的样本,我们要将这些无效的样本区分和有效样本区分开来,这就是我们SVM的工作。
但是如何对图像进行处理呢? 处理的动作包括一系列操作,我们如何完成这些一系列的操作呢?
我们运用OpenCV,一个开源的视觉识别库。
OpenCV是一个开源的计算机视觉库,它包含了一些完整的视觉处理算法的实现,当然还有一些机器学习的算法,例如SVM,决策树等。其中我们的讲解中就是用到它的SVM分类算法的实现。
这里不打算大笔墨的介绍OpenCV图像学操作的原理进行详细的讲解,因为这篇是讲SVM的,但是会展示我们要进行相关图像处理的一些步骤以及这些步骤达到的效果,当然我们后面会以源码的形式讲解OpenCV对原始图像的处理过程.
在一般的原始样本中,我们总需要定位到我们感兴趣-ROI的区域,这个实验中的感兴趣的区域就是我们这些数字字符,如果样本质量好的,也就是说没有我们之前提到的一些不好定位和区分图片中字符的因素在里面,也就是说那些高曝光,模糊的图片等等,这些样本图片还是比较好定位和萃取ROI内容的,下面列举了图片处理的一些基本步骤,步骤的顺序不是绝对,这一点一定要注意,毕竟是最终只是想要达到我们的目的。
灰度化简单的就是说把色彩的图像处理成计算机处理相对容易的灰度图像,用以下函数实现灰度化的处理:
cvtColor(src_in, grey, CV_BGR2GRAY);//转化为灰度图像
处理后的图像效果如下:
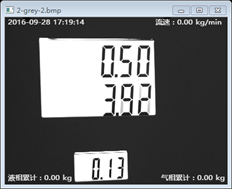
我们看到灰度化后的效果不太明显,因为图像本身就是黑白的,但是灰度化的操作是必须的,因为不是所有样本图像的效果都很好。
二值化的操作就是对图像像素做一个阀值化的处理,根据不同的光照的程度选择不同的阀值,使得图像中的像素只有黑白两种属性,用以下的处理可以取自适应阀值:
threshold(grey, grey, 0, 255, CV_THRESH_OTSU + CV_THRESH_BINARY_INV);
下面是二值化的效果:
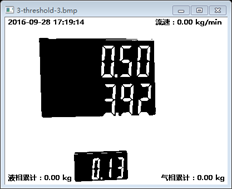
由于我们的原始图像有比较分明的横线和直线,也不需要要用Sobel算子等一些其他的算法去找图像的边缘,所以处理起来就更简单了,直接用Opencv找图像的轮廓即可,我们可以看到样本中有两个我们感兴趣的区域,都是长方体。直接上Opencv取轮廓操作,其中CV_RETR_TREE是取所有轮廓:
- findContours(grey,
- contours,// a vector of contours
- CV_RETR_TREE,
- CV_CHAIN_APPROX_NONE); // all pixels of each contours

findContours(grey,
contours,// a vector of contours
CV_RETR_TREE,
CV_CHAIN_APPROX_NONE); // all pixels of each contours
取轮廓后我们再取ROI可以得到如下图所示的两个符合标准的图像的方框,由下面的细小白线框出:
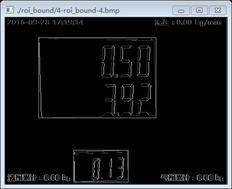
仔细看白底外边的方框,我们找到了我们定位的数字字符方框,有两个,一大一小如下:
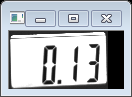
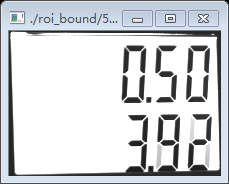
我们看到上面的两个图不是非常正,还是有点歪,后面还要进一步处理,最后定位到我们要找的数字字符串3.92和0.13.
为了把图像校正一些,需要取图像的最小外接矩形:
Rect mr = roi_rect.boundingRect();
然后再从原图像中截取原图像的ROI图块,进而获得拥有独立坐标的ROI图像:
- Rect_<float> safeBoundRect = Rect_<float>(mr.x, mr.y, mr.width, mr.height);
- bound_mat = src_in(safeBoundRect);
Rect_<float> safeBoundRect = Rect_<float>(mr.x, mr.y, mr.width, mr.height);
bound_mat = src_in(safeBoundRect);
最后通过rotation()函数获得校正后的图像,注意要旋转图像首先必须要知道的旋转的中心点以及角度:
- float roi_angle = roi_rect.angle;
- Point2f roi_ref_center = roi_rect.center - safeBoundRect.tl();
- rotation(bound_mat, rotated_mat, roi_rect.size, roi_ref_center, roi_angle);
float roi_angle = roi_rect.angle;
Point2f roi_ref_center = roi_rect.center - safeBoundRect.tl();
rotation(bound_mat, rotated_mat, roi_rect.size, roi_ref_center, roi_angle);
其中rotated_mat为输出旋转校正后的图像:
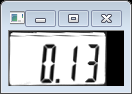
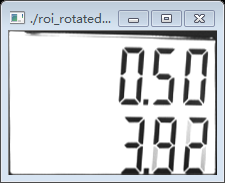
我们看到旋转校正过后的两个图像相对校正之前更加端正了,这样有利于我们后面对数字字符的分割。
这里开操作的作用是将我们要定位的字符从图像中截取出来,丢弃其它不相关的部分。如下图
黑色的阴影部分就是有效的数字区域。
注:开操作就是先做腐蚀操作,再做膨胀操作,即将白色的区域先用模板腐蚀,将黑色的部分连通起来,然后再对仍然是白色的部分进行膨胀,将黑色和白色分开得更加鲜明。下面是开操作的函数:
morphologyEx(temp_mat, temp_mat, MORPH_OPEN, element);
开操作的效果如下:
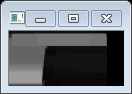
其中,我们可以看到黑色的部分就是我们的真正需要提取的区域。
分别对上一步骤中的出两个图进行后续的处理,这里用第一个图做演示。这一步骤是阀值化的过程。
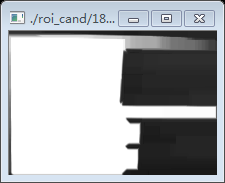
再次取轮廓后我们得出了两个轮廓,一个是数字字符串的有效区域,第二个是数字字符上边的模糊的阴影部分,看代码实现:
- findContours(grey,
- contours, // a vector of contours
- CV_RETR_EXTERNAL, // retrieve the external contours
- CV_CHAIN_APPROX_NONE); // all pixels of each contours
findContours(grey,
contours, // a vector of contours
CV_RETR_EXTERNAL, // retrieve the external contours
CV_CHAIN_APPROX_NONE); // all pixels of each contours
取得两个轮廓:
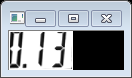

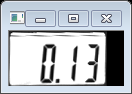
注意这里和之前的取所有轮廓不一样,这次再次取的轮廓是CV_RETR_EXTERNAL即最大外接轮廓。
对上面得出的两个候选图片做大小归一化,即先create一个固定大小的图像,然后将前面处理好的图像按照这个大小进行resize,大小归一化的实现代码:
- Mat cand_mat;
- cand_mat.create(36, 136, CV_8UC3);
- if (temp_cand_mat.cols >= 36 || temp_cand_mat.rows >= 136)
- resize(temp_cand_mat, cand_mat, cand_mat.size(), 0, 0, INTER_AREA);
- else
- resize(temp_cand_mat, cand_mat, cand_mat.size(), 0, 0, INTER_CUBIC);
Mat cand_mat;
cand_mat.create(36, 136, CV_8UC3);
if (temp_cand_mat.cols >= 36 || temp_cand_mat.rows >= 136)
resize(temp_cand_mat, cand_mat, cand_mat.size(), 0, 0, INTER_AREA);
else
resize(temp_cand_mat, cand_mat, cand_mat.size(), 0, 0, INTER_CUBIC);
于是我们得到以下归一化效果:


我们看到大小归一化后,所有得到的候选图片都是一样大小的,这样有助于我们后面的对图片的有效
性进行分析,并且也有助于后面进行字符分割。(本文还会讲到字符分割。)
在对样本图片进行预处理后,我们得到了一些候选图片,但是就如上面归一化后得到的候选图片的结果一样,这些图片中还是有一些是有效的图片和一些无效的图片,有效的图片中包含了我们要识别的内容,无效的图片中并没有包含这些内容,所以我们就需要将有效的图片和无效的图片区分开来,这个区分开来的工作就是SVM需要做的事情。
开始用SVM做训练之前,我们必须把处理后的样本分为两类,一类是有效的图片,另一类是无效的图片,然后从这两类图片中分别取出一部分用来做SVM模型训练,然后另一部分用来做测试集,这个测试集中同样包含有效的图片和无效的图片,用以验证SVM模型训练号的分类效果。
可建成上面面的目录结构,用以存放有效的图片和无效的图片,分别包含用于训练的数据和用于测试验证的数据。这个过程就是所谓大的贴标签过程。但是要注意的是,我们的用于训练的数据图片一般是要多于用于验证的图片集的,我们这里分成的是训练70%,测试30%。
将样本分好类后的数据还不是我们可以用来给训练模型训练的数据,我们还需要对这些训练的图片进行取特征的操作,这里不打算对如何取样本特征进行展开。
样本的特征有几种形式:
| 特征 | 描述 |
| HOG | 即Histogram of Oriented Gradient, HOG特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。 |
| LBP | 即Local Binary Pattern,局部二值模式,是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。 |
| HAAR | Haar特征分为三类:边缘特征、线性特征、中心特征和对角线特征,组合成特征模板。 |
SVM类型:SVM设置类型(默认0) 0 -- C-SVC 1 --v-SVC 2 – 一类SVM 3 -- e -SVR 4 -- v-SVR -t 核函数类型:核函数设置类型(默认2) 0 – 线性:u'v 1 – 多项式:(r*u'v + coef0)^degree 2 – RBF函数:exp(-gamma|u-v|^2) 3 –sigmoid:tanh(r*u'v + coef0)
-d degree:核函数中的degree设置(针对多项式核函数)(默认3) -g r(gama):核函数中的gamma函数设置(针对多项式/rbf/sigmoid核函数)(默认1/ k) -r coef0:核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0) -c cost:设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1) -n nu:设置v-SVC,一类SVM和v- SVR的参数(默认0.5) -p p:设置e -SVR 中损失函数p的值(默认0.1) -m cachesize:设置cache内存大小,以MB为单位(默认40) -e eps:设置允许的终止判据(默认0.001) -h shrinking:是否使用启发式,0或1(默认1) -wi weight:设置第几类的参数C为weight*C(C-SVC中的C)(默认1) -v n: n-fold交互检验模式,n为fold的个数,必须大于等于2 其中-g选项中的k是指输入数据中的属性数。option -v 随机地将数据剖分为n部
在提取特征后我们就可以将特征集合带入到opencv训练算法中训练,在这里我们直接选用RBF核进行训练,对于RBF核而言模型的性能由惩罚因子和r(gamma)决定。所以为了使SVM的性能最优,我们就必须寻找C和r的最优组合。如何找到C和r的最优组合,最简单的办法就是所谓的穷举法,即分别取C和r的不同组合训练SVM模型,然后通过测试得到模型的性能,简单点说就是识别率,这样就必须尝试n*n中组合,这个过程比较耗时,当训练样本很大模型训练量就更多更耗时了,当然还有其他模型参数的选择方法,例如运用Fisher准则的方法等,后面会用单独的文章来介绍这种方法。
- void svm_train_test(void)
- {
- //#define AutoTrain
- svm_ = cv::ml::SVM::create();
- svm_->setType(cv::ml::SVM::C_SVC);
- svm_->setKernel(cv::ml::SVM::RBF);
- auto train_data = tdata();
- #ifndef AutoTrain
- double v_gamma = svm_->getGamma();
- double v_C = svm_->getC();
- fprintf(stdout,">> Training SVM RBF model gamma = %f C = %f, please wait...\n", v_gamma, v_C);
- #else
- svm_->trainAuto(train_data, 10, svm_->getDefaultGrid(svm_->C),
- svm_->getDefaultGrid(svm_->GAMMA), svm_->getDefaultGrid(svm_->P),
- svm_->getDefaultGrid(svm_->NU), svm_->getDefaultGrid(svm_->COEF),
- svm_->getDefaultGrid(svm_->DEGREE),true);
- double v_gamma = svm_->getGamma();
- double v_coef0 = svm_->getCoef0();
- double v_C = svm_->getC();
- double v_Nu = svm_->getNu();
- double v_P = svm_->getP();
- fprintf(stdout,">> Auto Training SVM paramter gamma %f,coef0 %f C %f Nu %f P %f\n", v_gamma, v_coef0, v_C, v_Nu, v_P);
- system("pause");
- #endif
- do {
- svm_->setGamma(v_gamma);
- svm_->setC(v_C);
- long start =utils::getTimestamp();
- svm_->train(train_data);
- long end =utils::getTimestamp();
- fprintf(stdout,">> Training done. Time elapse: %ldms\n", end - start);
void svm_train_test(void)
{
//#define AutoTrain
svm_ = cv::ml::SVM::create();
svm_->setType(cv::ml::SVM::C_SVC);
svm_->setKernel(cv::ml::SVM::RBF);
auto train_data = tdata();
#ifndef AutoTrain
double v_gamma = svm_->getGamma();
double v_C = svm_->getC();
fprintf(stdout,">> Training SVM RBF model gamma = %f C = %f, please wait...\n", v_gamma, v_C);
#else
svm_->trainAuto(train_data, 10, svm_->getDefaultGrid(svm_->C),
svm_->getDefaultGrid(svm_->GAMMA), svm_->getDefaultGrid(svm_->P),
svm_->getDefaultGrid(svm_->NU), svm_->getDefaultGrid(svm_->COEF),
svm_->getDefaultGrid(svm_->DEGREE),true);
double v_gamma = svm_->getGamma();
double v_coef0 = svm_->getCoef0();
double v_C = svm_->getC();
double v_Nu = svm_->getNu();
double v_P = svm_->getP();
fprintf(stdout,">> Auto Training SVM paramter gamma %f,coef0 %f C %f Nu %f P %f\n", v_gamma, v_coef0, v_C, v_Nu, v_P);
system("pause");
#endif
do {
svm_->setGamma(v_gamma);
svm_->setC(v_C);
long start =utils::getTimestamp();
svm_->train(train_data);
long end =utils::getTimestamp();
fprintf(stdout,">> Training done. Time elapse: %ldms\n", end - start); - fprintf(stdout,">> Saving model file...\n");
- svm_->save(svm_xml_);
- fprintf(stdout,">> Your SVM Model was saved to %s\n", svm_xml_);
- fprintf(stdout,">> Testing...\n");
- svm_test_tmp(v_gamma, v_C, start, end);
- #ifndef AutoTrain
- v_gamma += 0.2;
- v_C += 0.2;
- #else
- break;
- #endif
- }while (v_gamma && v_C < 30.0);
- }
fprintf(stdout,">> Saving model file...\n");
svm_->save(svm_xml_);
fprintf(stdout,">> Your SVM Model was saved to %s\n", svm_xml_);
fprintf(stdout,">> Testing...\n");
svm_test_tmp(v_gamma, v_C, start, end);
#ifndef AutoTrain
v_gamma += 0.2;
v_C += 0.2;
#else
break;
#endif
}while (v_gamma && v_C < 30.0);
}
加载训练训练和测试数据:
开始训练:
从原理的分析中我们知道SVM中的惩罚因子C和r是影响SVM性能的关键因素。参数C的作用是确定数据子空间中调节学习机器的置信区间范围,不同数据子空间中最优的C是不同的,而核参数r的改变实际上隐含地改变映射函数从而改变样本数据子空间分布的复杂程度,即线性分类的最大VC维,也就决定了线性分类达到的最小误差。
下面两个图是根据固定C和r其中的某一因子训练出的模型对测试样本进行预测的出的各项性能曲线,分别反映参数C和r对SVM性能的影响。
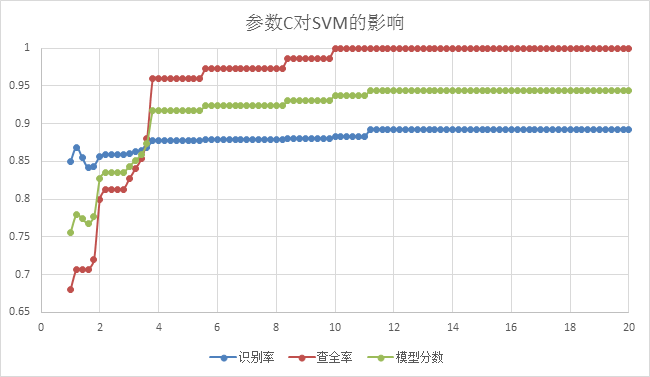
从上图我们可以看到在固定r,C作为变量,对模型进行训练后,C对SVM性能的影响情况。很明显当C越来越大,在达到12以上后,模型无论是从识别率、查全率还是综合的评估分数都达到了最优,随着C再往上增大,曲线则区域稳定,甚至没有变化了。
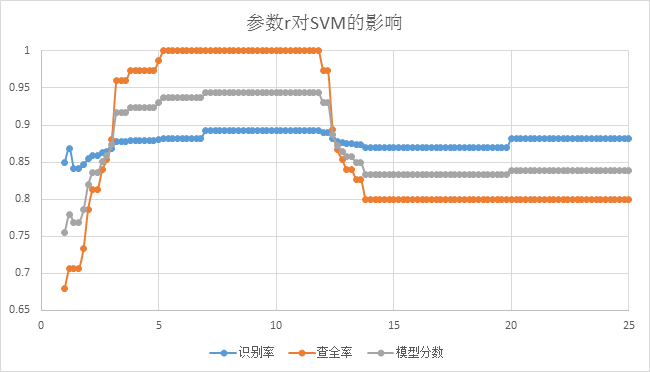
上图为固定惩罚因子C, 参数r对SVM性能影响,我们可以看到当r取值逐渐上升在大概7到11的区间时候SVM模型性能达到最优,然后随着r取值再增大,SVM的性能随之下降,最终在20以后趋于平稳。
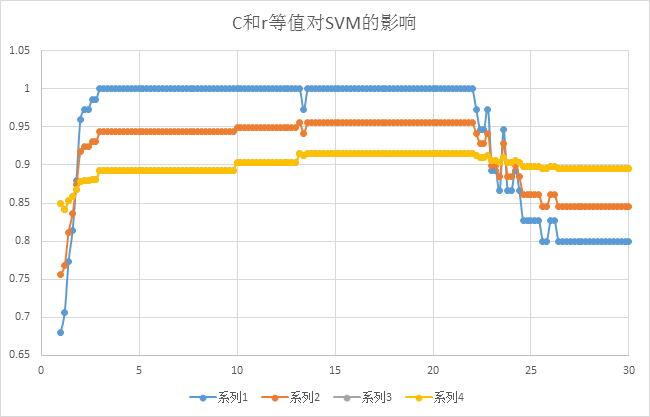
从上图我们可以看到在C和r等值的情况下,逐渐增加,在14至22的区间内SVM的性能达到最优,所以进一步的缩小了SVM参数C和r的取值范围,可以为最终的取值做参考,当然针对训练取得最优的C和r的同时优化图片处理效果和对特征提取的优化也是极为重要的。一个好的模型的生成就是对系统的整个处理流程的优化过程。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









