







本文回顾了经典的CNN结构,并附上相应的pytorch代码。融合了部分Ng、沐神讲解的内容(主要是ResNet),主要是写一下反思,帮助理解CNN的一些核心思想。
PPT来自:计算机视觉与深度学习 北京邮电大学 鲁鹏
代码来自沐神《动手学深度学习》。
文章目录
卷积概述

ReLU接在卷积层后面,对卷积的结果进行处理(卷积得到的结果不都是正数)!
卷积层堆叠:后面的conv可以在前面conv的基础上继续提取特征。
Pooling: 不改变深度信息,只减小空间尺寸,之后卷积需要计算的空间位置就减少了。【一般每pooling一次,下降一倍】
虽然卷积核的大小不变,但是越靠后,感受野“相对越大”,相当于从一个更大的尺度上观察图像【前面细粒度,后面粗粒度】。
卷积特征图

卷积核的个数决定了这一层输出的特征图的个数,也是下一层卷积核的深度。
池化层

AlexNet(2012)
贡献

动量:使得震荡方向减小,运动比较慢的方向加强,更快的通过平坦的区域。
结构

注:
1、这个Norm现在已经不用了,并不是BN。
2、说“网络层数”,我们只算Conv层和FC层。
3、算参数的时候“+1”是bias.
4、输入227 * 227 * 3的图像之前,进行了去均值处理【统计所有训练样本每个位置像素的均值,也是一个227 * 227 * 3的。然后对于每一个图像,减去这个均值向量】。
作用?——
在进行分类的时候,”绝对值“是无意义的,我们只需要比较”相对值“。去均值之后,保留了相对值,还可以使得数据减小。

这里使用的池化是重叠池化(但是在之后的网络中,一般还是使用不重叠的池化)。
池化不学习参数!

Norm的作用:将差距拉大,“助纣为虐,落井下石”。从VGG开始就去掉了。

呆码
以28 * 28 * 1的图片为例,pytorch代码:
# 这里由于是MINST数据集,所以输入的通道是1; 如果是ImageNet数据集,就应该是3了
net = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(),
nn.Linear(256 * 5 * 5, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 10)
)
*重要规律
验证集损失不下降时,可以手动降低10倍学习率。
反思:卷积层到底在做什么?

256是256种特征响应模板,亮代表此处切合度高。
ZFNet(2013)

1、将第一个卷积改成7 * 7,这样方便感受更细粒度的内容;
2、步长设置成2,不让分辨率降低的太快,而是一点点降低;
3、之所以只增加后面层卷积核的个数:认为 “基元” 的内容是很少的(图像的底层特征),我们不需要很多的卷积核;但是他们之间组合出来的特征却很多,越到后面,卷积核包含的语义信息就越多,增加卷积核的个数,可以理解更多的语义信息。
VGG(2014)

串联小卷积核可以获得更大的感受野,而不非用大卷积核。串联小卷积核经过了多次变换,非线性性更强。
VGG处理归一化和AlexNet不同。VGG统计所有图片R, G, B的均值,然后将【R, G, B】作为均值。
之前是,若干图片同一位置的像素的R、G、B求均值,现在是若干图片所有像素的R、G、B求均值。

前层卷积核的个数少,后层卷积核的个数多。前层学习的是 “基元”信息,后期学习的 “语义”信息多。【与ZFNet类似】
但是并不越多越好。因为后面要接一个FC,如果太大,展开成向量输入FC的话,会非常大。
VGG-11的呆码
与VGG-16相比,每一个卷积块都少一个卷积层。
# 超参数:需要的卷积层的个数、输入输出的channel数
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for i in range(num_convs):
layers.append(nn.Conv2d(
in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(
num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10)
)
反思:小卷积核有什么优势?

两个3 * 3的小卷积核串联,其实就等效于一个5 * 5的卷积核,他们的感受野是一样的。
但是,串联多经过了一次变换,非线性能力更强【感性理解:组合出来之后,会更复杂,得到更复杂的信息】。
此外,参数也更少。
反思:为什么经过一次Pooling, 卷积核个数要增加一倍?

“动态平衡”的思想。如果不Pooling,那显存占用太大。
GoogLeNet(2014)

核心改进:网络结构发生本质改变,引入Inception块。

为什么不采用串联结构了呢?
举一个栗子。如果图中有一条很宽的线,但是用小卷积核,只能把他提取成四条边,这样一个重要信息就丢失了。
所以,这个错误是“叠加”的,前面丢失了信息,后面无法挽回。
【注:沐神在《动手学深度学习》中提供另外一种说法:“小学生才做选择题,我全都要!”
既然不知道什么时候用3 * 3, 5 * 5,那我不如全都留下来,一起算。】
解决方案:保留前面层更多的信息。

兵分四路。1 * 1的卷积对于通道做融合(相当于全连接);3 * 3的卷积感受细粒度的信息,提取3 * 3局部信息; 5 * 5的卷积感受相对粗粒度的信息,提取5 * 5局部信息;MaxPooling对强信息做扩张【理解:如果有一个极大值像素,那么所有卷积操作包含它的部分都会变成这个值】。最后将所有的层concat(在深度方向拼接)起来。这四个层都不改变H * W的大小。
但是问题在于,如果直接这样做,会很慢。所以在前面先用NiN(Network in Netwok),不改变宽高,但是改变通道数(深度).所以第2,3路的1 * 1块与1,4路的1 * 1块功能不同,1,4路的是融合信息,对深度进行压缩,2,3路是主要减少计算量(当然也会融合信息)。

最后也砍掉了2个FC,大大减少了参数个数。取而代之的是一个AvgPooling,每个特征图用一个最大值代替。【之前是每一个特征图展开成一个长向量,现在是每个特征图只保留一个值】

此外,GoogLeNet中还有两个辅助分类器,因为网络太深,所以使用辅助分类器让前面也能有梯度回传(PPT中的两条红线)从而解决梯度消失问题。
ReLU虽然也可以一定程度解决梯度消失,但是并不能完全解决深层网络难以训练的问题。加上辅助分类器之后,前面的层更好训练,前面层学到的特征也能让网络更快的收敛。

Inception块呆码
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
反思:关于1 * 1的卷积(NiN):

对于卷积层,可以理解为每一个像素有多个通道,如果通道数是100,可以理解为一个像素有一个长为100的向量,可以认为这个向量是这个像素的特征。那么可以理解为,每一个像素就是一个样本,共有批量大小 * 高 * 宽个样本。故,可以把通道层当做卷积层的特征维度。【这也是1 * 1的卷积相当于全连接的解释】。
NiN会导致信息的损失吗?

理论上压缩会损失,但损失的是“不存在”的特征,所以实际上未太损失。
以上图为例,m * n * 64的特征图,每一个卷积核都是描述一种结构【这个向量描述的是某个点A被64个卷积核卷积的结果】。但是图像在同一个位置只会有1种结构(或再多一点点,2-3种,但是不会很多),不可能卷积核描述的特征在原图像同一个位置都有,所以描述图像上A位置的这个向量(64维)是一个很稀疏的向量。压缩之后,会把很多的0压缩掉,所以不会丢失信息。
ResNet(2015)
发现问题——网络并不是越深越好!


Residual
大名鼎鼎的残差块,几乎成为之后深层网络的必备了(如Transformer中的Add&Norm层)。
可以用下面的图理解残差块。【这主要是从正向传播的角度理解的】

原图 + 边缘图 = 锐化后的图,在保证了原图信息的同时,把细节进行了强化。那我们可以这样理解:输入的X就是原图,特征提取之后输出的F(X)就是这个边缘细节图,他们和在一起的H(X)就是最后的输出。【卷积在这里可以理解为那个边缘提取器。】当然,锐化的增强是“人的视觉效果”最关心的信息,在ResNet中增强的可不一定是人视觉上感兴趣的信息,有可能是对分类比较有兴趣的信息。这里只是拿锐化来对比理解下。
之前的网络,要学习的直接就是H(x),但是现在要学习的是F(X) = H(x) - X, 这也就是“残差”的思想,即输出和输入的差异。

这里第一次使用1 * 1的卷积,依然是为了降低通道数【减少运算量】; 而第二次使用1 * 1的卷积,是为了增加通道数【不升回去没法相加】。所谓 “瓶颈”就是深度先减小再增大。

两种ResNet块
只看上图会发现一个问题:维度对不上!因为Residual结构的存在,所以输入输出的维度应该完全不变才对(和X一致)。
这里鲁鹏老师没有讲,其实是因为有两种ResNet结构:高宽减半的resnet块和高宽不变的resnet块。【注:这里李沐老师讲的和上面的resnet结构稍有不同,因为鲁鹏老师讲的是resnet152,沐神讲的是resnet18,但是原理一样】。具体细节可以看下面的代码。

反思:为什么ResNet可以训练到1000层?
从反向传播理解
之前网络一个很大的问题——深度太深之后,梯度会消失,前面的网络训练不好。
如何避免梯度消失?-> 乘法变加法
梯度消失: 新加的层如果拟合能力很强(例如AlexNet的全连接层),那么高层的梯度会很快变得非常小【导数可以理解为:真实值和预测值之间的差别(可以去看softmax求导)】。如果梯度很小的话,只能增大学习率。但是增的太大,高层的学习率也大了,会使得训练很不稳定(这里假设的是全局统一的学习率)。
但是resnet:每一层都会把上一层的导数传过来,于是不会太小。贴近数据的W的梯度可以由上层直接经过高速公路传下来,一开始下面的层也可以拿到比较大的梯度,才可以对很深的网络做训练。

结合吴恩达老师的再理解下。如果我们在此基础上再使用L2正则化(权重衰退),会进一步压缩W的值。
如果W学到了0,那么a[l + 2]就会学习到a[l](因为是relu函数,a[l]肯定是大于0的),这就实现了恒等式的传递。

也就是说,当网络足够深的时候,开始起反作用的时候,这个模块可以保证你网络性能不变(尽管加了两层)。这里是假设很深的时候梯度消失了,此时这个网络可以退回到梯度消失之前。但是plain NN 是做不到这样的,随着深度的加深,会学的更烂。
吴恩达老师提出观点,residual有用的原因就是:他学习恒等函数很容易。

集成模型(核心理解)
残差可以看成很多子网络的求和。

Ensemble当然效果好鸭。
研究人员发现,随便盖住ResNet中的某几层,效果依然很好,但是如果对VGG这么干,就GG了。后面提出的DenseNet也是对ResNet的优化,他发现Ensemble的坏处在于,“投票“虽然好,但是有很多冗余信息,这里就不在深究了。
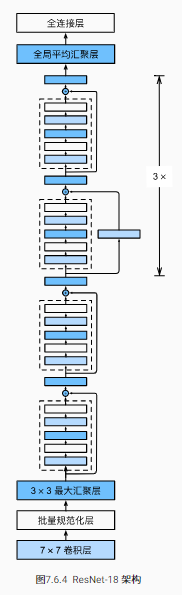
ResNet18呆码
注意resnet的“加法“是直接数值相加【见下面Y += X】,而不是像GoogLeNet那样做通道堆积合并。
class Residual(nn.Module): # use_1x1conv:要不要使用1x1的卷积
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1) # 这里输入通道数=输出通道数,这是左边的第二个3x3
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(implace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X #!!!!!
return F.relu(Y)
使用两种不同的resnet块:
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
torch.Size([4, 3, 6, 6])
增加输出通道的同时,高宽减半。
blk = Residual(3, 6, use_1x1conv=True, strides=2)
Y = blk(X)
Y.shape
torch.Size([4, 6, 3, 3])
下面是RetNet18网络的实现:
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
# 一个stage要多少个residual小块,是不是第一个stage
def residual_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals): # 只在第一个stage(b2)才减半,其余的都不减半
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*residual_block(64, 64, 2, True))
b3 = nn.Sequential(*residual_block(64, 128, 2))
b4 = nn.Sequential(*residual_block(128, 256, 2))
b5 = nn.Sequential(*residual_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1]) # 用池化变成1 * 1
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
ResNet18结构图
Summary

一般要自己做任务的时候,建议使用resnet或InceptionV4.
当然最新的研究表明,swin transformer好像吊锤CNN?不过我不会,长大后在学习。
















 3098
3098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









