







 该博客聚焦财政收入预测,先分析预测背景与数据特征相关性,指出多数特征与财政收入正相关但存在多重共线性。接着用Lasso回归选取关键特征,再结合灰色预测和SVR构建预测模型,最后经评价表明模型拟合效果好、预测精度高,可指导实际工作。
该博客聚焦财政收入预测,先分析预测背景与数据特征相关性,指出多数特征与财政收入正相关但存在多重共线性。接着用Lasso回归选取关键特征,再结合灰色预测和SVR构建预测模型,最后经评价表明模型拟合效果好、预测精度高,可指导实际工作。
第8章 财政收入预测分析
8.1 了解财政收入预测的背景与方法
8.1.1 分析财政收入预测背景
1、财政收入简介和需求
财政收入,是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而筹集的一切资金的总和。财政收入表现为政府部门在一定时期内(一般为一个财政年度)所取得的货币收入。财政收入是衡量一国政府财力的重要特征,政府在社会经济活动中提供公共物品和服务的范围和数量,在很大程度上取决于财政收入的充裕状况。
在我国现行的分税制财政管理体制下,地方财政收入不但是国家财政收入的重要组成部分,而且具有其相对独立的构成内容。如何制定地方财政支出计划,合理分配地方财政收入,促进地方的发展,提高市民的收入和生活质量是每个地方政府需要考虑的首要问题。因此,地方财政收入预测是非常必要的。
2、财政收入预测数据基础情况
考虑到数据的可得性,本项目所用的财政收入分为地方一般预算收入和政府性基金收入。地方一般预算收入包括以下2个部分。
1> 税收收入。主要包括企业所得税与地方所得税中中央和地方共享的40%,地方享有的25%的增值税,营业税和印花税等。
2> 非税收收入。包括专项收入、行政事业性收费、罚没收入、国有资本经营收入和其他收入等。
政府性基金收入是国家通过向社会征收以及出让土地、发行彩票等方式取得收入,并专项用于支持特定基础设施建设和社会事业发展的收入。
由于1994年我国对财政体制进行了重大改革,开始实行分税制财政体制,影响了财政收入相关数据的连续性,在1994年前后不具有可比性。由于没有合适的方法来调整这种数据的跃变,因此本项目仅对1994年至2013年的数据进行分析(本项目所用数据均来自《统计年鉴》)。
各项特征名称及特征说明如下(共13项):
社会从业人数(x1):就业人数的上升伴随着居民消费水平的提高,从而间接影响财政收入的增加。
在岗职工工资总额(x2):反映的是社会分配情况,主要影响财政收入中的个人所得税、房产税以及潜在消费能力。
社会消费品零售总额(x3):代表社会整体消费情况,是可支配收入在经济生活中的实现。当社会消费品零售总额增长时,表明社会消费意愿强烈,部分程度上会导致财政收入中增值税的增长;同时当消费增长时,也会引起经济系统中其他方面发生变动,最终导致财政收入的增长。
城镇居民人均可支配收入(x4):居民收入越高消费能力越强,同时意味着其工作积极性越高,创造出的财富越多,从而能带来财政收入的更快和持续增长。
城镇居民人均消费性支出(x5):居民在消费商品的过程中会产生各种税费,税费又是调节生产规模的手段之一。在商品经济发达的如今,居民消费的越多,对财政收入的贡献就越大。
年末总人口(x6):在地方经济发展水平既定的条件下,人均地方财政收入与地方人口数呈反比例变化。
全社会固定资产投资额(x7):是建造和购置固定资产的经济活动,即固定资产再生产活动。主要通过投资来促进经济增长,扩大税源,进而拉动财政税收收入整体增长。
地区生产总值(x8):表示地方经济发展水平。一般来讲,政府财政收入来源于即期的地区生产总值。在国家经济政策不变、社会秩序稳定的情况下,地方经济发展水平与地方财政收入之间存在着密切的相关性,越是经济发达的地区,其财政收入的规模就越大。
第一产业产值(x9):取消农业税、实施三农政策,第一产业对财政收入的影响更小。
税收(x10):由于其具有征收的强制性、无偿性和固定性特点,可以为政府履行其职能提供充足的资金来源。因此,各国都将其作为政府财政收入的最重要的收入形式和来源。
居民消费价格指数(x11):反映居民家庭购买的消费品及服务价格水平的变动情况,影响城乡居民的生活支出和国家的财政收入。
第三产业与第二产业产值比(x12):表示产业结构。三次产业生产总值代表国民经济水平,是财政收入的主要影响因素,当产业结构逐步优化时,财政收入也会随之增加。
居民消费水平(x13):在很大程度上受整体经济状况GDP的影响,从而间接影响地方财政收入。
3、财政收入预测分析目标
结合财政收入预测的需求分析,本次数据分析建模目标主要有以下2个。
(1)分析、识别影响地方财政收入的关键特征。
(2)预测2014年和2015年的财政收入。
8.1.2 了解财政收入预测的方法
众多学者已经对财政收入的影响因素进行了研究,但是他们大多先建立财政收入与各待定的影响因素之间的多元线性回归模型,运用最小二乘估计方法来估计回归模型的系数,通过系数来检验它们之间的关系,模型的结果对数据的依赖程度很大,并且普通最小二乘估计求得的解往往是局部最优解,后续步骤的检验可能就会失去应有的意义。
本项目在已有研究的基础上运用Lasso特征选择方法来研究影响地方财政收入的因素。在Lasso特征选择的基础上,鉴于灰色预测对少量数据预测的优良性能,对单个选定的影响因素建立灰色预测模型,得到它们在2014年及2015年的预测值。由于支持向量回归较强的适用性和容错能力,对历史数据建立训练模型,把灰色预测的数据结果代入训练完成的模型中,充分考虑历史数据信息,可以得到较为准确的预测结果,即2014年和2015年财政收入。
8.1.3 熟悉财政收入预测的步骤与流程
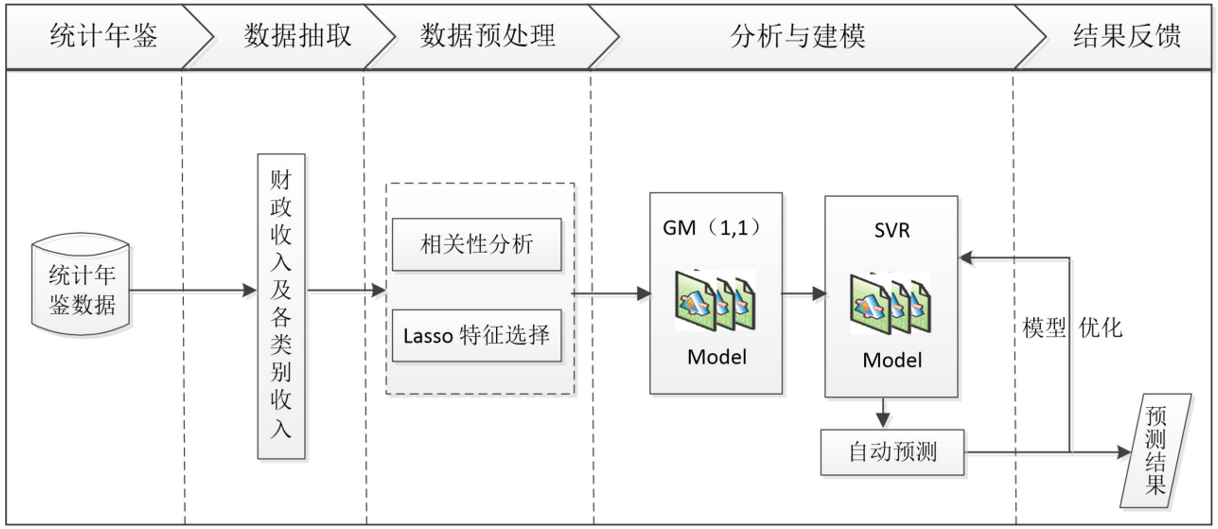
本项目的总体流程如图所示,主要包括以下步骤。
1、对原始数据进行探索性分析,了解原始特征之间的相关性。
2、利用Lasso特征选择模型进行特征提取。
3、建立单个特征的灰色预测模型以及支持向量回归预测模型。
4、使用支持向量回归预测模型得出2014-2015年财政收入的预测值。
5、对上述建立的财政收入预测模型进行评价。
8.2 分析财政收入数据特征的相关性
8.2.1 了解相关性分析
Pearson相关系数
相关性分析是指对两个或多个具备相关性的特征元素进行分析,从而衡量两个特征因素的相关密切程度。
在统计学中,常用Pearson相关系数来进行相关性分析。
Pearson相关系数是用来度量两个特征X和Y之间的相互关系(线性相关的强弱),是最简单的一种相关系数,通常用r或p表示,取值范围在[-1,1]之间。
Pearson相关系数的一个关键的特性就是它不会随着特征的位置或是大小的变化而变化。例如,把X变为a + bX,把Y变为c + dY,其中a , b , c,d都是常数,不会改变相互之间的相关系数。

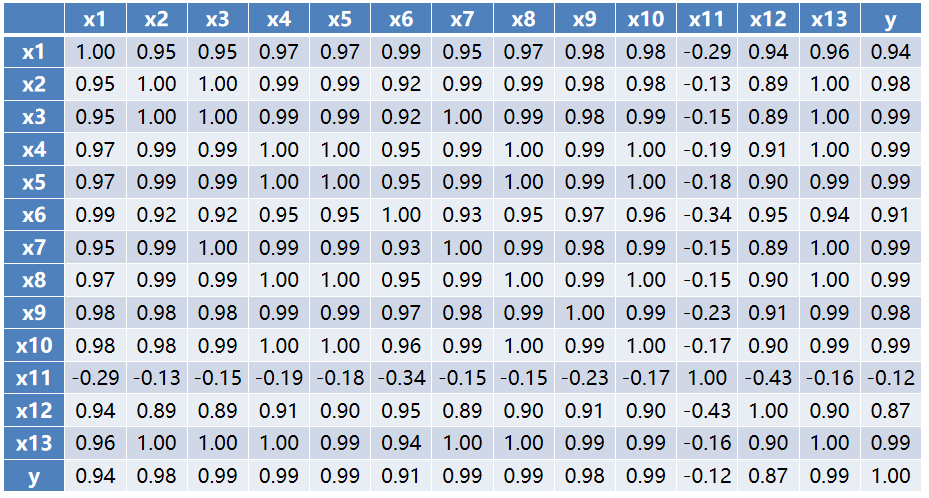
Pearson相关系数矩阵
8.2.3 代码
# 代码 8-1 求Pearson相关系数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
inputfile = 'F:/书籍/Python数据分析与应用/37304_Python数据分析与应用_源代码和实验数据' \
'/第8章\data/data.csv' ## 输入的数据文件
data = pd.read_csv(inputfile) ## 读取数据
## 保留两位小数
print('相关系数矩阵为:',np.round(data.corr(method = 'pearson'), 2))
# 皮尔森相关系数
corr = data.corr(method="pearson")
# 绘制热力图
ax = plt.subplots(figsize=(8, 8)) # 调整画布大小
ax = sns.heatmap(corr, square=True, annot=True, fmt='.2f') # 画热力图
plt.show()
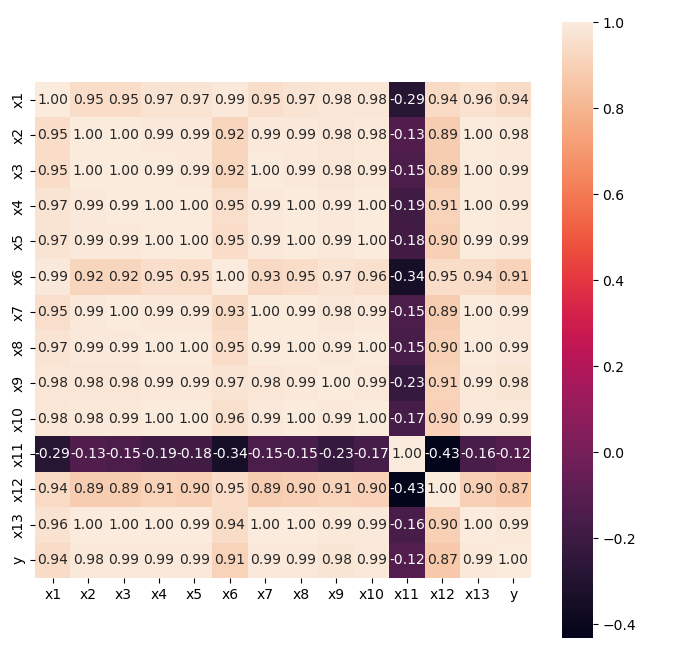
由上表可知,居民消费价格指数(x11)与财政收入(y)的线性关系不显著,呈现负相关。其余特征均与财政收入呈现高度的正相关关系。
- 按相关性大小,依次是x3,x4,x5,x7,x8,x10,x13,x2,x9,x1,x6和x12。
各特征之间存在着严重的多重共线性: - 特征x1,x4,x5,x6,x8,x9,x10与除了x11之外的特征均存在严重的共线性。
- 特征x2,x3,x7与除了x11和x12外的其他特征存在着严重的多重共线性。
- x11与各特征的共线性不明显。
- x12与除了x2,x3,x7,x11之外的其他特征有严重的共线性。
- x13与除了x11之外的各特征有严重的共线性。
- x2和x3,x2和x13,x3和x13等多对特征之间存在完全的共线性。
由上述分析可知,选取的各特征除了x11外,其他特征与y的相关性很强,可以用作财政收入预测分析的关键特征,但这些特征之间存在着信息的重复,需要对特征进行进一步筛选。
8.3 使用Lasso回归选取财政收入预测的关键特征
8.3.1 了解Lasso回归方法
1、概念
Lasso回归方法属于正则化方法的一种,是压缩估计。
它通过构造一个惩罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零,保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
2、基本原理
Lasso以缩小特征集(降阶)为思想,是一种收缩估计方法。
Lasso方法可以将特征的系数进行压缩并使某些回归系数变为0,进而达到特征选择的目的,可以广泛地应用于模型改进与选择。
通过选择惩罚函数,借用Lasso思想和方法实现特征选择的目的。模型选择本质上是寻求模型稀疏表达的过程,而这种过程可以通过优化一个“损失”+“惩罚”的函数问题来完成。

3、 适用场景
当原始特征中存在多重共线性时,Lasso回归不失为一种很好的处理共线性的方法,它可以有效地对存在多重共线性的特征进行筛选。
在机器学习中,面对海量的数据,首先想到的就是降维,争取用尽可能少的数据解决问题,从这层意义上说,用Lasso模型进行特征选择也是一种有效的降维方法。
Lasso从理论上说,对数据类型没有太多限制,可以接受任何类型的数据,而且一般不需要对特征进行标准化处理。
4、Lasso回归方法优缺点
优点:可以弥补最小二乘法和逐步回归局部最优估计的不足,可以很好地进行特征的选择,可以有效地解决各特征之间存在多重共线性的问题。
缺点:如果存在一组高度相关的特征时,Lasso回归方法倾向于选择其中的一个特征,而忽视其他所有的特征,这种情况会导致结果的不稳定性。
虽然Lasso回归方法存在弊端,但是在合适的场景中还是可以发挥不错的效果。在财政收入预测中,各原始特征存在着严重的多重共线性,多重共线性问题已成为主要问题,这里采用Lasso回归方法进行特征选取是恰当的。
8.3.2 分析Lasso回归结果
用Python编制相应的程序后运行得到如下表所示的结果。
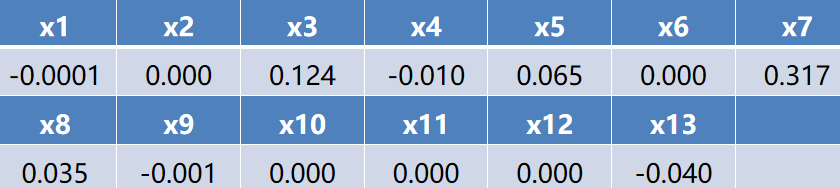
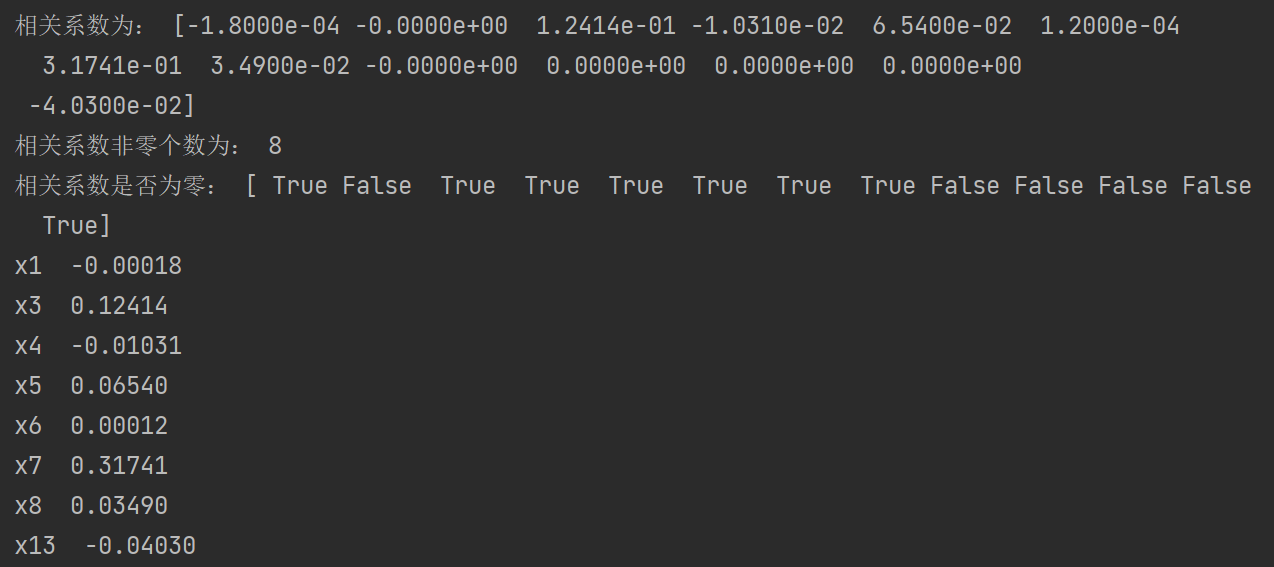
由上表可看出,利用Lasso回归方法识别影响财政收入的关键影响因素是社会从业人数(x1)、社会消费品零售总额(x3)、城镇居民人均可支配收入(x4)、城镇居民人均消费性支出(x5)、全社会固定资产投资额(x7)、地区生产总值(x8)、第一产业产值(x9)和居民消费水平(x13)。
8.3.3 代码:使用Lasso回归方法进行关键特征选取
使用Lasso回归方法进行关键特征选取
# 代码 8-2 使用Lasso回归方法进行关键特征选取
import numpy as np
import pandas as pd
from sklearn.linear_model import Lasso
inputfile = 'F:/书籍/Python数据分析与应用/37304_Python数据分析与应用_源代码和实验数据' \
'/第8章\data/data.csv' ## 输入的数据文件
data = pd.read_csv(inputfile) #读取数据
lasso = Lasso(1000) # 调用Lasso()函数,设置λ的值为1000
X = data.drop(['y'], axis=1)
y = data['y']
lasso.fit(data.iloc[:, 0:13], data['y'])
# lasso.fit(data.iloc[:, 0:13], data['y'])
print('相关系数为:', np.round(lasso.coef_, 5)) # 输出结果,保留五位小数
## 计算相关系数非零的个数
print('相关系数非零个数为:', np.sum(lasso.coef_ != 0))
mask = lasso.coef_ != 0 # 返回一个相关系数是否为零的布尔数组
print('相关系数是否为零:', mask)
listname = list(X)
for i in range(0, len(listname)):
if mask[i]:
print("{} {:.5f}".format(listname[i], lasso.coef_[i]))
outputfile = 'F:/书籍/Python数据分析与应用/37304_Python数据分析与应用_源代码和实验数据' \
'/第8章\data/new_reg_data.csv' #输出的数据文件
data1 = data.iloc[:,0:13]
new_reg_data = data1.iloc[:, mask] #返回相关系数非零的数据
new_reg_data.to_csv(outputfile) #存储数据
print('输出数据的维度为:',new_reg_data.shape) #查看输出数据的维度
8.4 使用灰色预测和SVR构建财政收入预测模型
8.4.1 了解灰色预测算法
1、概念
灰色预测法是一种对含有不确定因素的系统进行预测的方法。
在建立灰色预测模型之前,需先对原始时间序列进行数据处理,经过数据处理后的时间序列即称为生成列。
灰色系统常用的数据处理方式有累加和累减两种。
2、基本原理

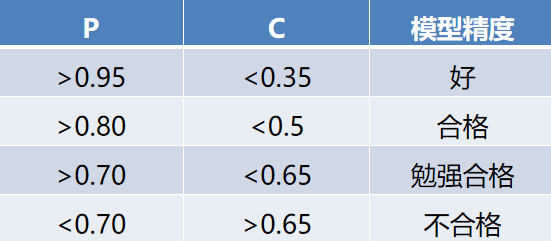
后验差检验模型精度如下表所示。
3、适用场景
灰色预测法的通用性比较强些,一般的时间序列场合都可以用,尤其适合那些规律性差且不清楚数据产生机理的情况。
4、灰色预测优缺点
优点:具有预测精度高、模型可检验、参数估计方法简单、对小数据集有很好的预测效果。
缺点:对原始数据序列的光滑度要求很高,在原始数据列光滑性较差的情况下灰色预测模型的预测精度不高甚至通不过检验,结果只能放弃使用灰色模型进行预测。
8.4.2 了解SVR算法
1、基本原理

2、适用场景
由于支持向量机拥有完善的理论基础和良好的特性,人们对其进行了广泛的研究和应用,涉及分类、回归、聚类、时间序列分 析、异常点检测等诸多方面。
具体的研究内容包括统计学习理论基础、各种模型的建立、相应优化算法的改进以及实际应用。
支持向量回归也在这些研究中得到了发展和逐步完善,已有许多富有成果的研究工作。
3、SVR算法优缺点
优点:支持向量回归不仅适用于线性模型,对于数据和特征之间的非线性关系也能很好抓住;持向量回归不需要担心多重共线性问题,可以避免局部极小化问题,提高泛化性能,解决高维问题;支持向量回归虽然不会在过程中直接排除异常点,但会使得由异常点引起的偏差更小。
缺点:计算复杂度高,在面临数据量大的时候,计算耗时长。
4、主要参数介绍
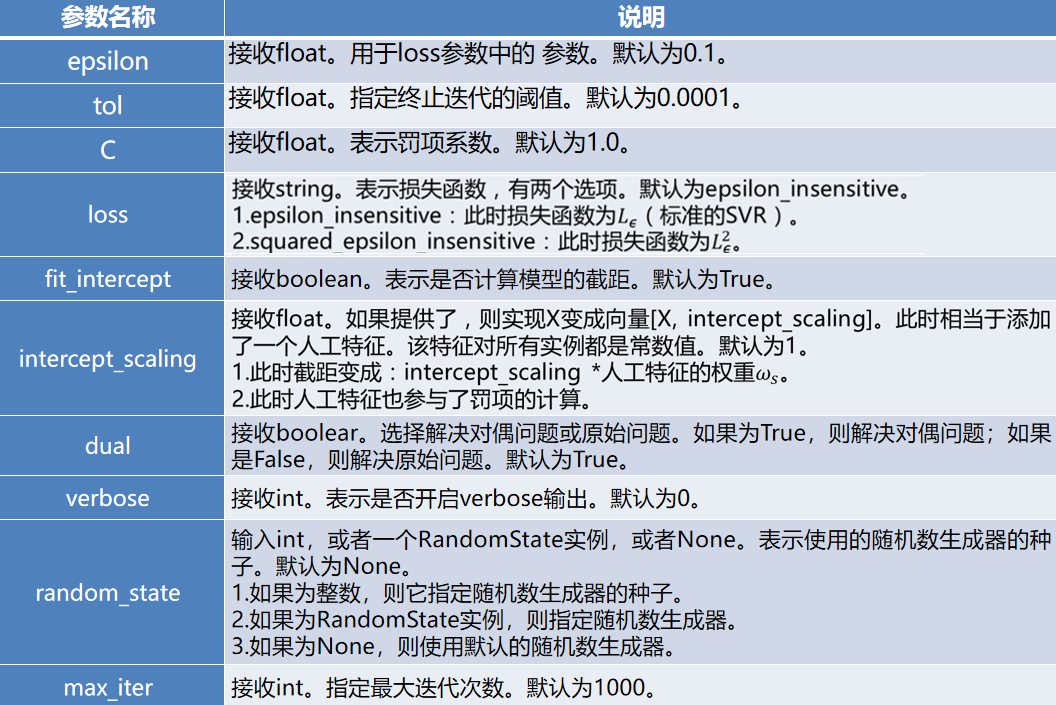
sklearn库的LinearSVR函数实现了线性支持向量回归,其使用语法如下。
class sklearn.svm.LinearSVR(epsilon=0.0, tol=0.0001, C=1.0, loss=’epsilon_insensitive’…)
常用参数及说明如下。
使用sklearn构建的SVR模型属性及其说明如下表所示。

8.4.3 分析预测结果
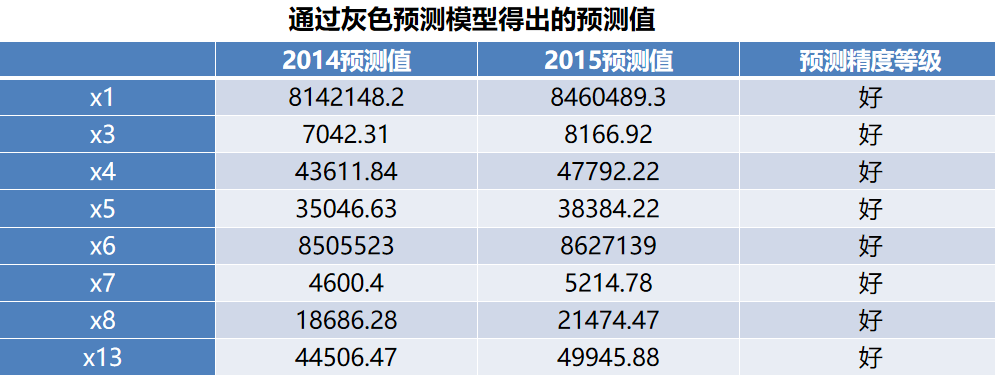
社会从业人数(x1)、社会消费品零售总额(x3)、城镇居民人均可支配收入(x4)、城镇居民人均消费性支出(x5)、全社会固定资产投资额(x6)、地区生产总值(x7)、第一产业产值(x8)和居民消费水平(x13)特征的2014年及2015年通过建立的灰色预测模型得出的预测值,如下表所示。
将上表的预测结果代入地方财政收入建立的支持向量回归预测模型,得到1994年至2015年财政收入的预测值,其中Y_pred表示预测值。
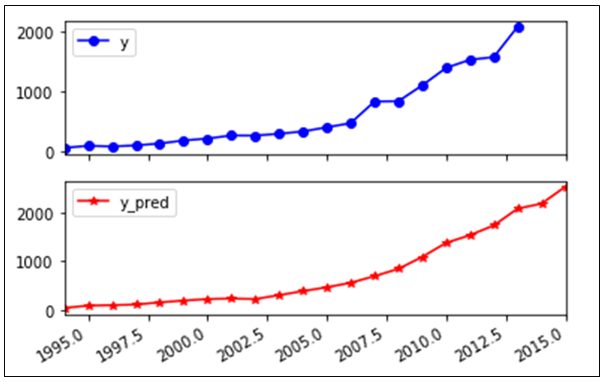
模型评价指标
采用回归模型评价指标对地方财政收入的预测值进行评价,得到的结果如下表所示。
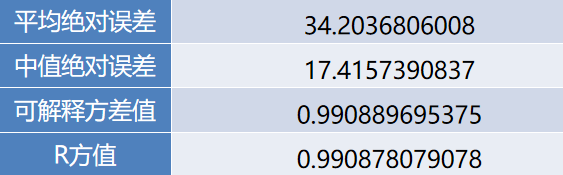
可以看出平均绝对误差与中值绝对误差较小,可解释方差值与R方值十分接近1,表明建立的支持向量回归模型拟合效果优良,可以用于预测财政收入。
8.4.4 代码:财政收入灰色预测
# 代码 8-3 财政收入灰色预测
import numpy as np
import pandas as pd
# from GM11 import GM11 ## 引入自编的灰色预测函数
def GM11(x0): # 自定义灰色预测函数
x1 = x0.cumsum() # 1-AGO序列
z1 = (x1[:len(x1) - 1] + x1[1:]) / 2.0 # 紧邻均值(MEAN)生成序列
z1 = z1.reshape((len(z1), 1))
B = np.append(-z1, np.ones_like(z1), axis=1)
Yn = x0[1:].reshape((len(x0) - 1, 1))
[[a], [b]] = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Yn) # 计算参数
f = lambda k: (x0[0] - b / a) * np.exp(-a * (k - 1)) - (x0[0] - b / a) * np.exp(-a * (k - 2)) # 还原值
delta = np.abs(x0 - np.array([f(i) for i in range(1, len(x0) + 1)]))
C = delta.std() / x0.std()
P = 1.0 * (np.abs(delta - delta.mean()) < 0.6745 * x0.std()).sum() / len(x0)
return f, a, b, x0[0], C, P # 返回灰色预测函数、a、b、首项、方差比、小残差概率
inputfile = 'F:/书籍/Python数据分析与应用/df/new_reg_data.csv' # 输入的数据文件
inputfile1 = 'F:/书籍/Python数据分析与应用/df/data.csv' # 输入的数据文件
new_reg_data = pd.read_csv(inputfile) # 读取经过特征选择后的数据
data = pd.read_csv(inputfile1) # 读取总的数据
new_reg_data.index = range(1994, 2014)
# print(new_reg_data)
# new_reg_data.loc[2014] = None
# new_reg_data.loc[2015] = None
l = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13']
for i in l:
# f = GM11(new_reg_data.loc[range(1994, 2014),i].as_matrix())[0]
# as_matrix()已淘汰,改使用values
f = GM11(new_reg_data.loc[range(1994, 2014), i].values)[0]
new_reg_data.loc[2014, i] = f(len(new_reg_data) - 1) # 2014年预测结果
new_reg_data.loc[2015, i] = f(len(new_reg_data)) # 2015年预测结果
new_reg_data[i] = new_reg_data[i].round(2) # 保留两位小数
outputfile = 'F:/书籍/Python数据分析与应用/df/new_reg_data_GM11.xlsx' # 灰色预测后保存的路径
y = list(data['y'].values) # 提取财政收入列,合并至新数据框中
y.extend([np.nan, np.nan])
new_reg_data['y'] = y
new_reg_data.to_excel(outputfile) # 结果输出
print('预测结果为:', new_reg_data.loc[2014:2015, :]) # 预测结果展示

8.4.5 代码:财政收入支持向量回归预测模型
# 代码 8-4 财政收入支持向量回归预测模型
import pandas as pd
import numpy as np
from sklearn.svm import LinearSVR
import matplotlib.pyplot as plt
from sklearn.metrics import explained_variance_score,\
mean_absolute_error,mean_squared_error,\
median_absolute_error,r2_score
inputfile = 'F:/书籍/Python数据分析与应用/df/new_reg_data_GM11.xlsx' #灰色预测后保存的路径
data = pd.read_excel(inputfile) # 读取数据
# print(data)
feature = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13']
data_train = data.iloc[:-2, :] # 取2014年前的数据建模
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train - data_mean)/data_std # 数据标准化
# print(data_train)
x_train = data_train[feature].values # 特征数据
y_train = data_train['y'].values # 标签数据
linearsvr = LinearSVR(random_state=0) # 调用LinearSVR()函数
linearsvr.fit(x_train, y_train)
x = ((data[feature] - data_mean[feature])/data_std[feature]).values # 预测,并还原结果。
data['y_pre'] = linearsvr.predict(x) * data_std['y'] + data_mean['y']
# SVR预测后保存的结果
outputfile = 'F:/书籍/Python数据分析与应用/df/new_reg_data_GM11_revenue.xlsx'
data.to_excel(outputfile)
print(data[['y', 'y_pre']])
y = data.loc[0:19, 'y']
y_pre = data.loc[0:19, 'y_pre']
print('平均绝对误差为:', mean_absolute_error(y, y_pre))
print('均方误差为:', mean_squared_error(y, y_pre))
print('中值绝对误差为:', median_absolute_error(y, y_pre))
print('可解释方差值为:', explained_variance_score(y, y_pre))
print('R方值为:', r2_score(y, y_pre))
# 画图
print('预测图为:')
data[['y', 'y_pre']].plot(subplots=True, style=['b-o', 'r-*'])
plt.show()
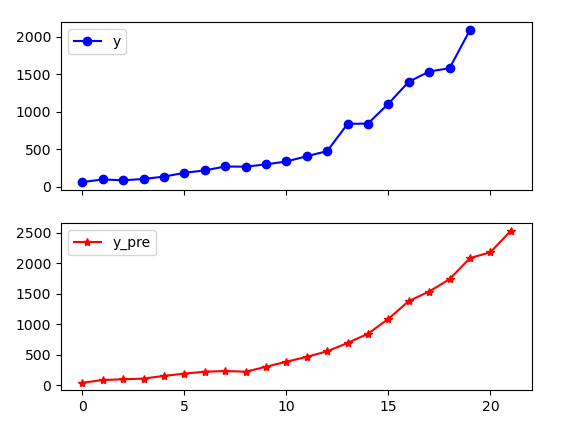
小结
本项目财政收入预测,主要介绍了原始数据的相关性分析、特征的选取、构建灰色预测和支持向量回归预测模型、模型的评价四部分内容。
在财政收入相关数据的相关性分析中,采用了简单相关系数对数据进行了分析。
在特征选取中,运用了广泛使用的Lasso回归模型。
在模型的构建阶段,针对历史数据首先构建了灰色预测模型,对所选特征的2014年与2015年的值进行预测。然后根据所选特征的原始数据与预测值,建立支持向量回归模型,得到财政收入的最终预测值。
最后用平均绝对误差、中值绝对误差、可解释方差值和R方值进行模型的评价。
本项目建立的财政收入预测模型,通过最后一个图可以看出,很好的拟合了财政收入的变化情况。同时,模型还具有很高的预测精度,可以用来指导实际的工作。



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











