









收藏关注不迷路,源码文章末
一、项目介绍
微博网络舆情分析系统采取Mysql作为后台数据的主要存储单元,运用软件工程原理和开发方法,采用Hadoop的Java、python技术构建的一个管理系统,实现了本系统的全部功能。完成系统的主要模块的页面设计和功能实现。本文展示了首页页面的实现效果图,并通过代码和页面介绍了微博信息、微博分类、发布微博、分享信息等功能的实现过程。
关键词:Hadoop技术;MYSQL;微博网络舆情分析系统
二、开发环境
Hadoop后端+HTML前端+大数据屏——>Hadoop、HTML、大数据屏
————————————————
三、功能介绍
2.3 系统功能分析
2.3.1 功能性分析
按照微博网络舆情分析系统的角色,我划分为了微博用户管理模块和管理员管理模块这三大部分。
微博用户管理模块:
(1)用户登录:用户登录微博网络舆情分析系统 ;用户对个人信息的增删改查,比如个人资料,密码修改。
(2)查看微博网络舆情分析系统 的首页信息:微博网络舆情分析系统 的首页信息包含了首页、交流论坛、系统公告、新闻资讯微博信息、我的(我的账户、我的收藏、个人中心)等。
(3)系统公告:用户可以查看后台管理员发布的公告消息信息,在查询到自己想要了解的系统公告的时候,可以进入查看详细的介绍。
(4)微博信息交流:在首页导航栏上我们会看到“微博信息交流”这一菜单,我们点击进入进去以后,会看到所有管理员在后台发布的交流信息;
(5)新闻资讯:用户可以查看新闻资讯信息,在查询到自己想要了解的新闻资讯的时候,可以进入查看详细的介绍进行评论、点赞、收藏操作。
(6)交流论坛:用户在交流论坛这一菜单下对用户提交的查看、同时也可以发布、评论。
(7)微博信息:在首页导航栏上点击“微博信息”弹跳出的是微博信息列表,可以点击随意一款微博信息进行了解其具体信息。包括微博标题、微博分类、微博用户、用户姓名等;
(8)个人中心:当用户点击右上角“我的”这个按钮,就会进入到对应的后台进行信息的管理了;
(9)我的账户:在首页导航栏上点击“我的”下面的“我的账户”可以对个人资料+密码修改+自己收藏的信息进行管控。
管理员管理模块:
(1)登录:管理员的账号是在数据表表中直接设置生成的,不需要进行注册;
(2)交流管理:当点击“资源管理”这一菜单的时候,会出现论坛列表+论坛分类列表这两个子菜单,可以对这两个模块进行增删改查操作;
(3)系统用户:当点击“系统用户”这一菜单的时候,会出现管理员+微博用户这两个子菜单,可以对这两个模块进行增删改查操作;
(5)资源管理:管理员可以对微博网络舆情分析系统前台展示的新闻列表以及新闻分类列表所属的分类进行管控。
(6)模块管理:当点击“模块”这一菜单的时候,会出现微博信息+微博分类+发布微博+分享信息这四个子菜单,管理员能够对这四模块信息进行增删改查操作;
2.4 系统用例分析
通过2.3功能的分析,得出了本微博网络舆情分析系统的用例图:
微博用户角色用例如图2-3所示。
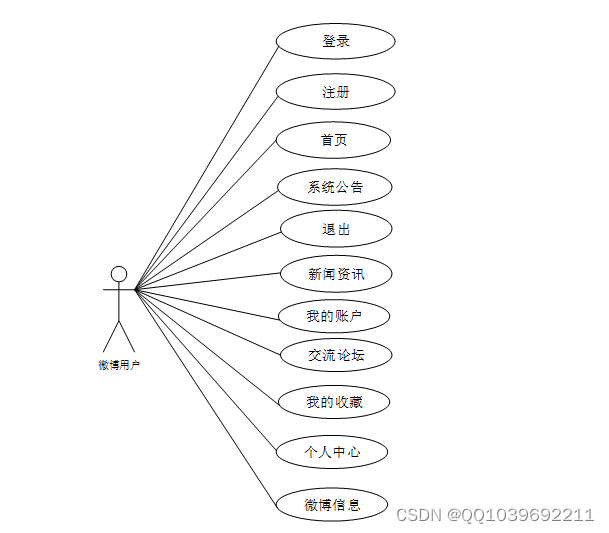
图2-3微博网络舆情分析系统 微博用户角色用例图
web后台管理上的管理员是维护整个微博网络舆情分析系统中所有数据信息的。管理员角色用例如图2-4所示。
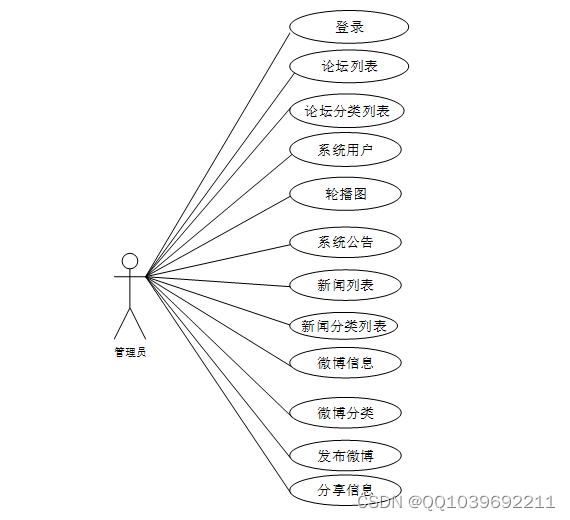
图2-4 微博网络舆情分析系统 管理员角色用例图
博网络舆情分析系统根据前面章节的需求分析得出,其总体设计模块图如图3-2所示。
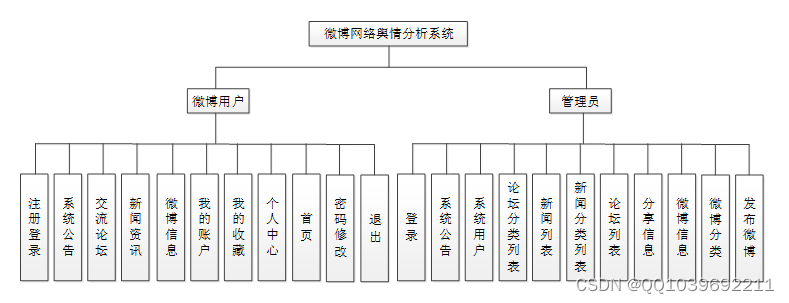
图3-2微博网络舆情分析系统功能模块图
四、核心代码
部分代码:
# -*- coding: utf-8 -*-
import os
import importlib
services_abspath_arr = []
services_arr = []
services_dir_ = os.getcwd() + "\\hadoop"
# 遍历模块文件(绝对路径)加到services_abspath_arr数组
# 选择服务函数
def service_hadoop_select(str):
for service_item in services_arr:
if str.capitalize() == service_item.__class__.__name__:
return service_item
def foreach_file(path_name):
for root, dirs, files in os.walk(path_name):
for f in files:
services_abspath_arr.append(os.path.join(root, f))
# 读取模块
# f:文件路径
def loadModule(f):
# 将f变成相对路径
f = f.replace(services_dir_ + "\\", "").replace(".py", "").replace("\\", "/")
# print(f)
mod = importlib.import_module(
"jobs."+f.replace("/", ".")
)
arr_1 = f.split("/")
cs_service = getattr(mod, arr_1[len(arr_1) - 1].capitalize())
# service的class形式
service = cs_service()
services_arr.append(service)
foreach_file(services_dir_)
for f in services_abspath_arr:
if f.find(".pyc") == -1 and f.find("__init__") == -1:
# print(f)
loadModule(f)
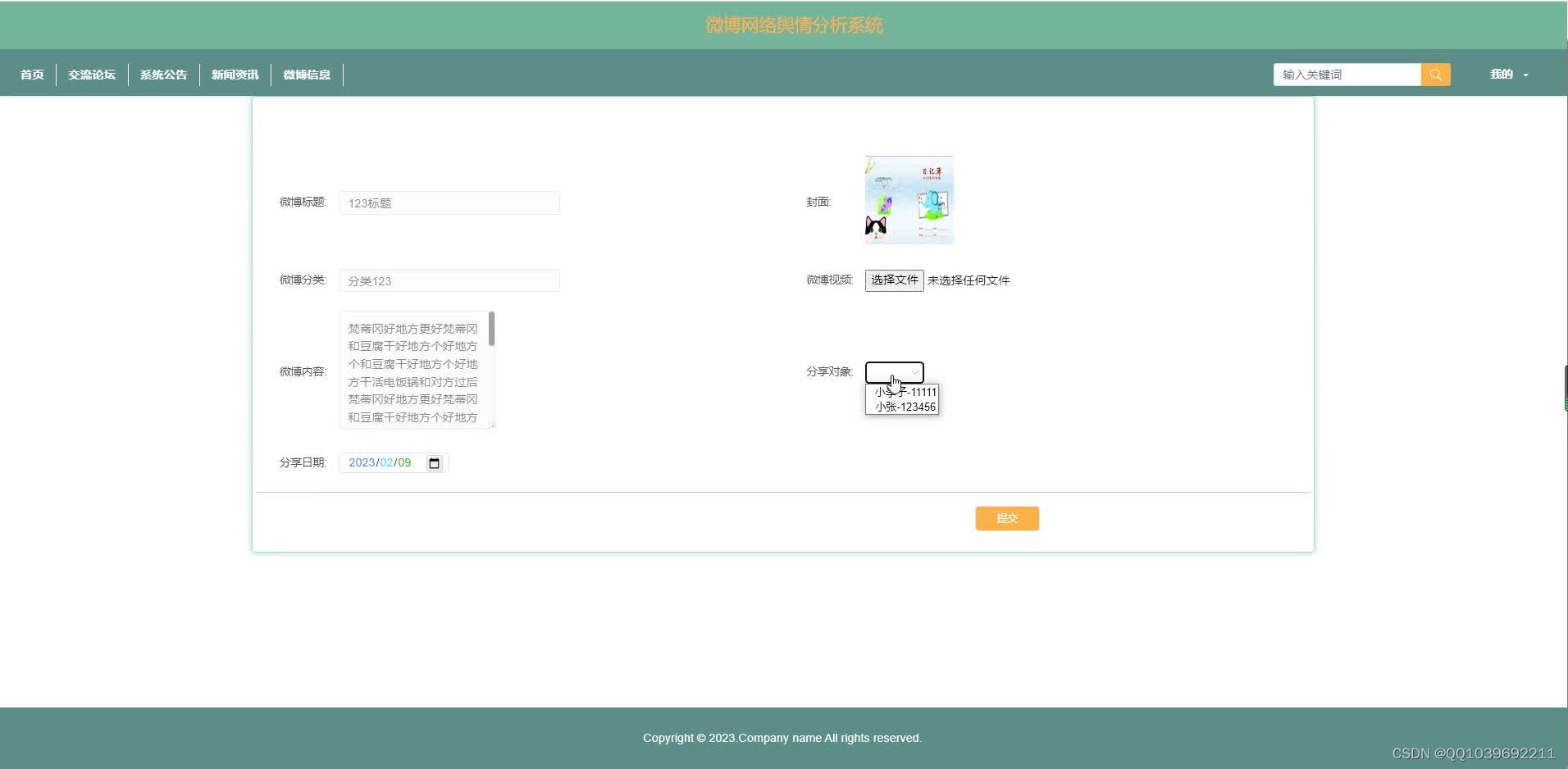
五、效果图
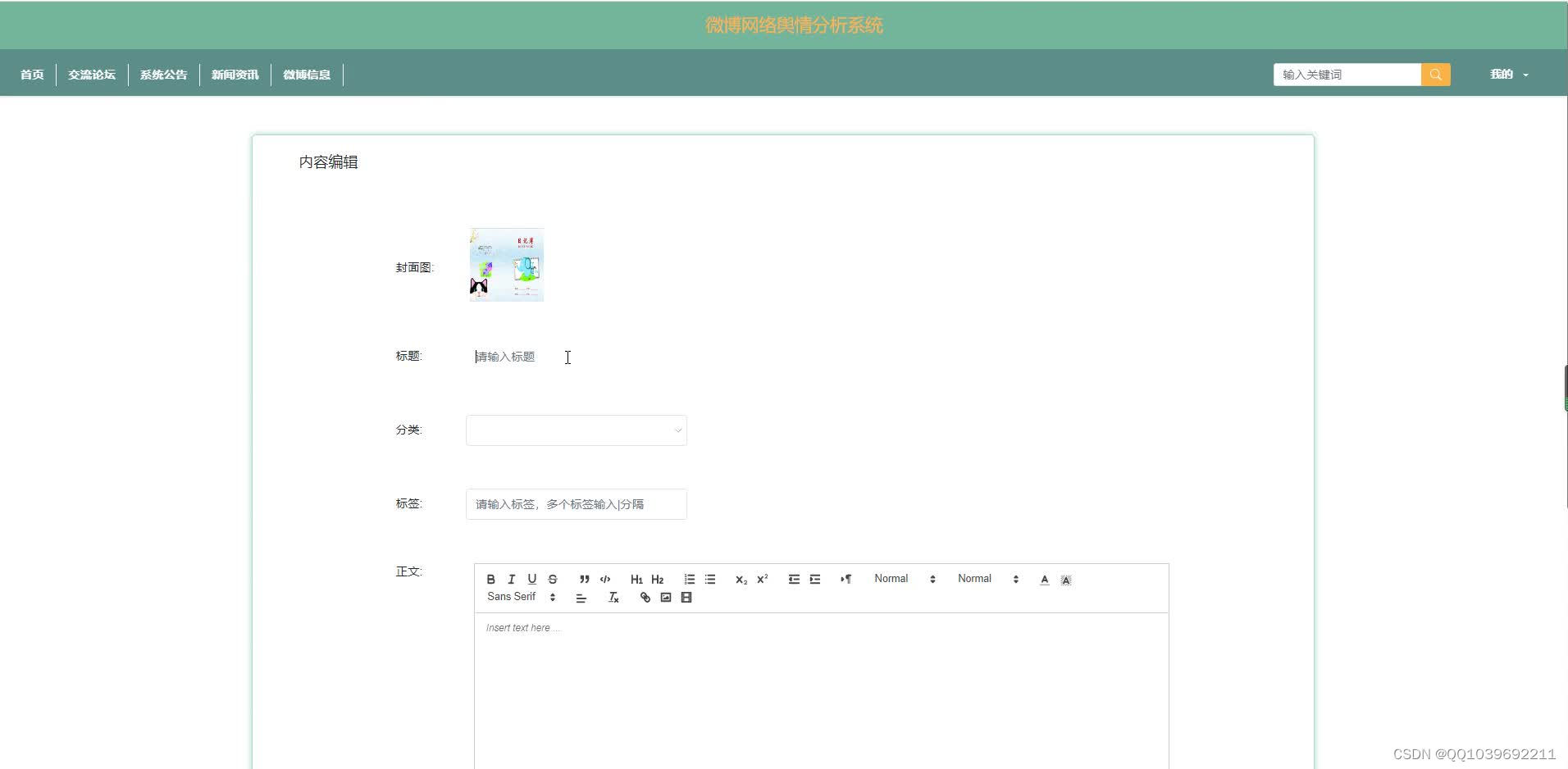
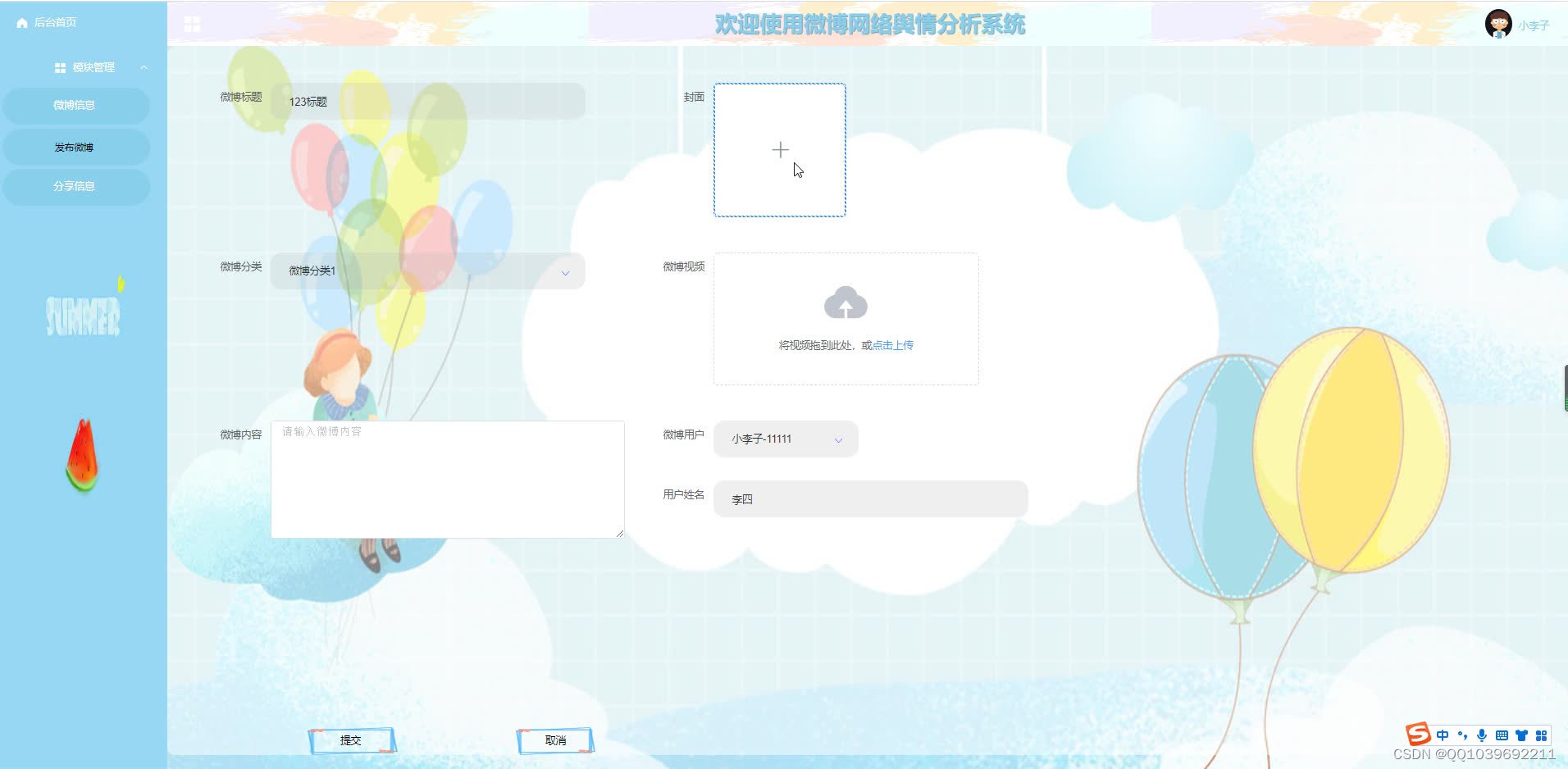
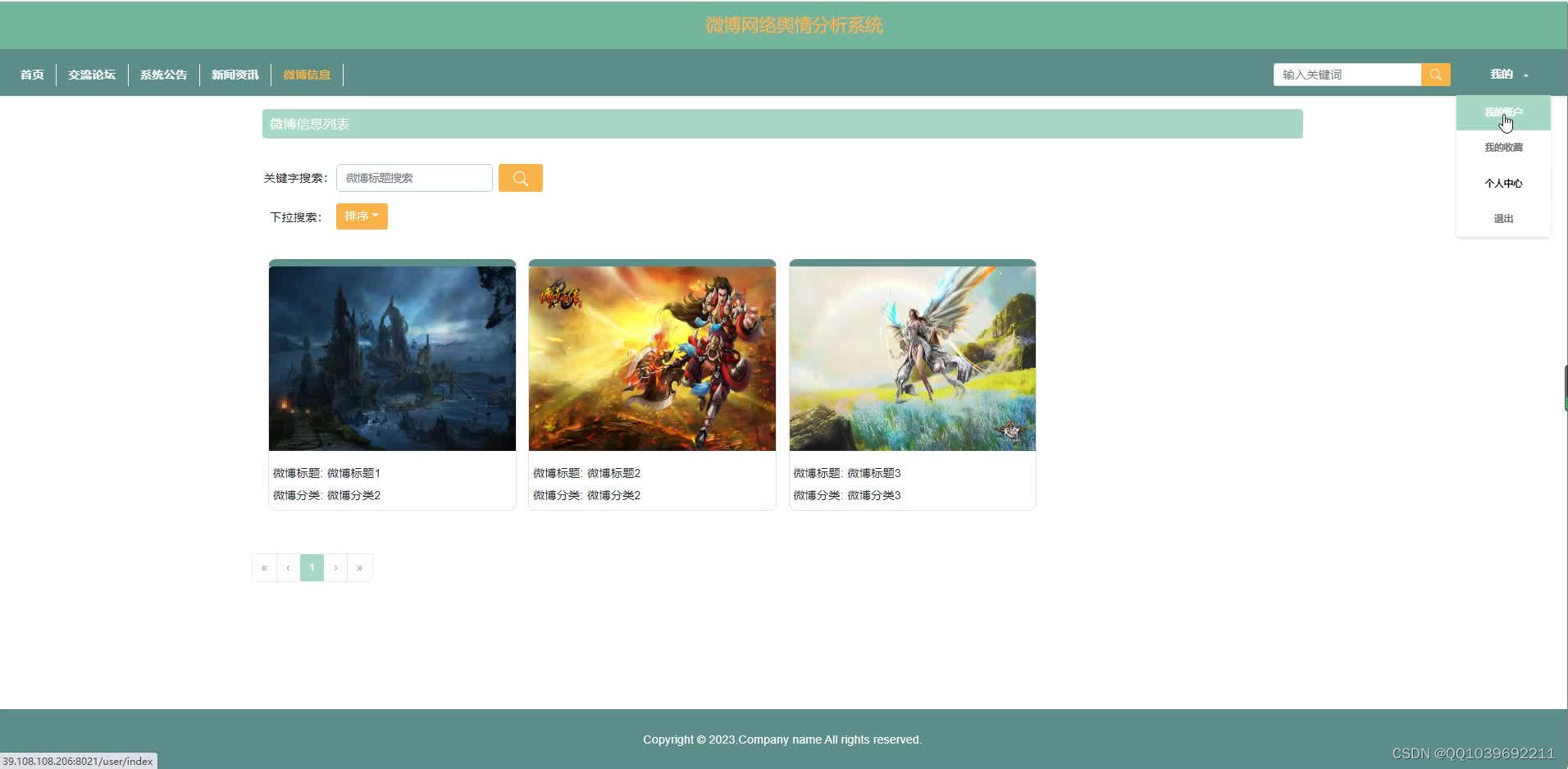
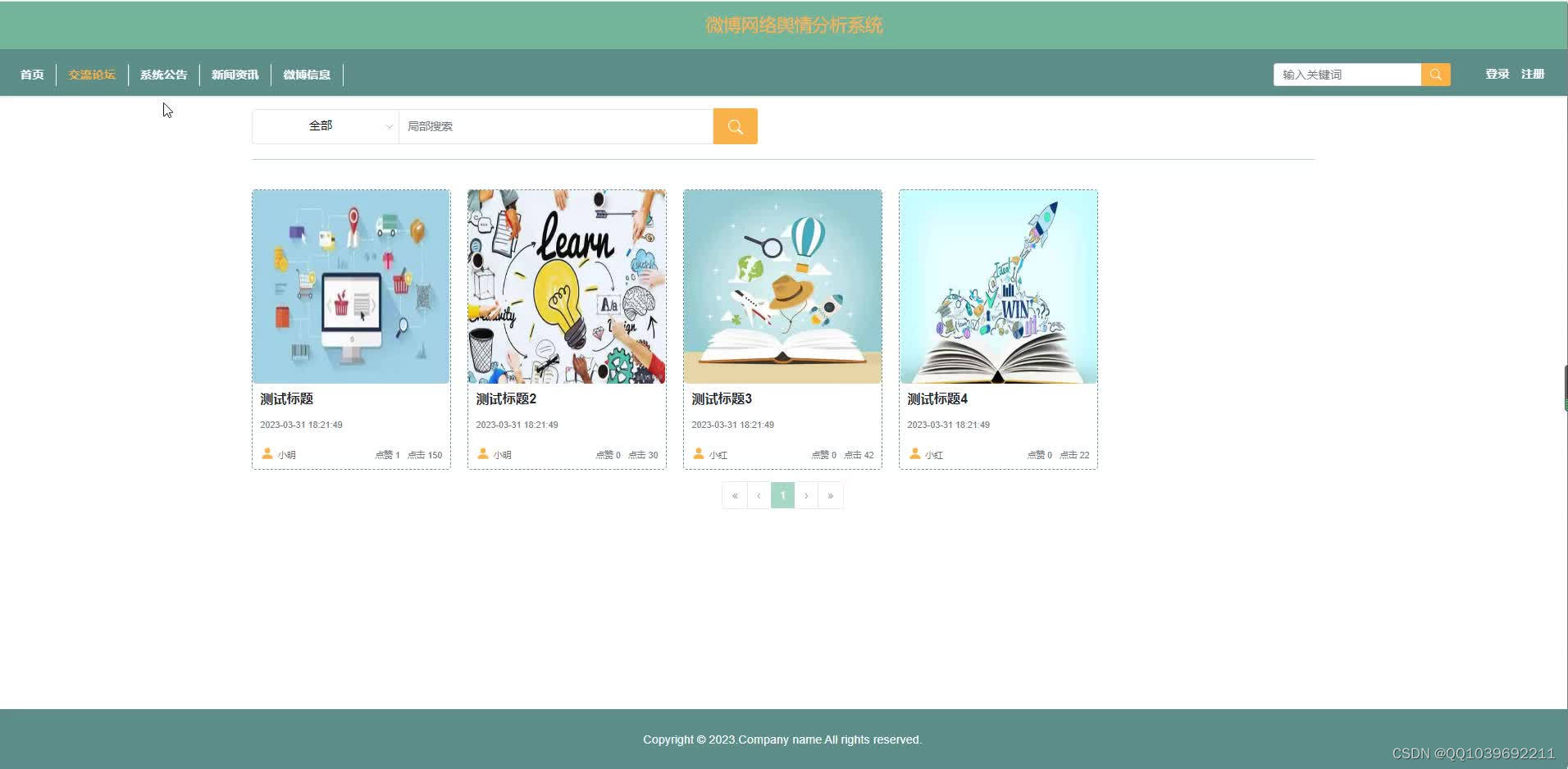
六、文章目录
目 录
摘要 1
1 绪论 1
1.1研究背景 1
1.2研究内容 2
1.3Hadoop优点 3
1.4 Hadoop框架介绍 3
1.5论文结构与章节安排 4
2 微博网络舆情分析系统 系统分析 5
2.1 可行性分析 5
2.2 系统流程分析 5
2.2.1数据增加流程 5
2.2.2数据修改流程 6
2.2.3数据删除流程 6
2.3 系统功能分析 7
2.3.1 功能性分析 7
2.3.2 非功能性分析 7
2.4 系统用例分析 8
2.5本章小结 8
3 微博网络舆情分析系统 总体设计 8
3.1 系统架构设计 8
3.2 系统功能模块设计 9
3.2.1整体功能模块设计 9
3.2.2用户模块设计 9
3.2.3评论管理模块设计 10
3.2.4微博管理模块设计 10
3.3 数据库设计 10
3.3.1 数据库概念结构设计 10
3.3.2 数据库逻辑结构设计 14
3.4本章小结 20
4 微博网络舆情分析系统 详细设计与实现 21
4.1用户功能模块 21
4.1.1 前台首页界面 21
4.1.2 登录界面 21
4.1.3注册界面 23
4.1.4 密码修改界面 24
4.1.5新闻资讯界面 25
4.1.6 微博信息详情界面 26
4.2管理员功能模块 27
4.2.1 登录界面 27
4.2.2 系统用户界面 29
4.2.3 资源管理界面 32
4.2.4交流管理界面 34
4.2.5 发布微博管理界面 35
4.2.6 分享信息管理界面 35=
5系统测试 36
5.1系统测试的目的 36
5.2 系统测试用例 36
5.3 系统测试结果 37
结论 38
参考文献 39
致 谢 40
















 1331
1331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











