







一、Linux进程和线程介绍
1、进程和线程的基本概念
进程是资源管理的最小单位,而线程是程序调度执行的最小单位。在操作系统设计上,从进程演化出线程,最主要的目的就是减小多进程上下文切换开销。
2、进程的三态模型
进程是并发执行的,宏观上在一段时间内能同时运行多个程序,但其实微观上是交替发生的。也就是说 CPU 一般不会让一个进程一次性执行完,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。某个进程的时间片用完后这个进程就会进入就绪态,而其他被分配到时间片的进程就会进入运行态。这个处于就绪态的进程就需要等待进程调度程序的下一次调度,为其分配 CPU 时间片后才能再次恢复运行。经典的进程三态模型有:运行态、就绪态、阻塞态,目前很多系统中都增加了新建态和中止态,形成五态模型,如下图:

3、进程和线程的区别
1、线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
2、一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
3、进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
4、调度和切换:线程上下文切换比进程上下文切换要快得多。
二、linux下的进程管理
1、进程的创建
1.1、fork函数
①fork函数分析
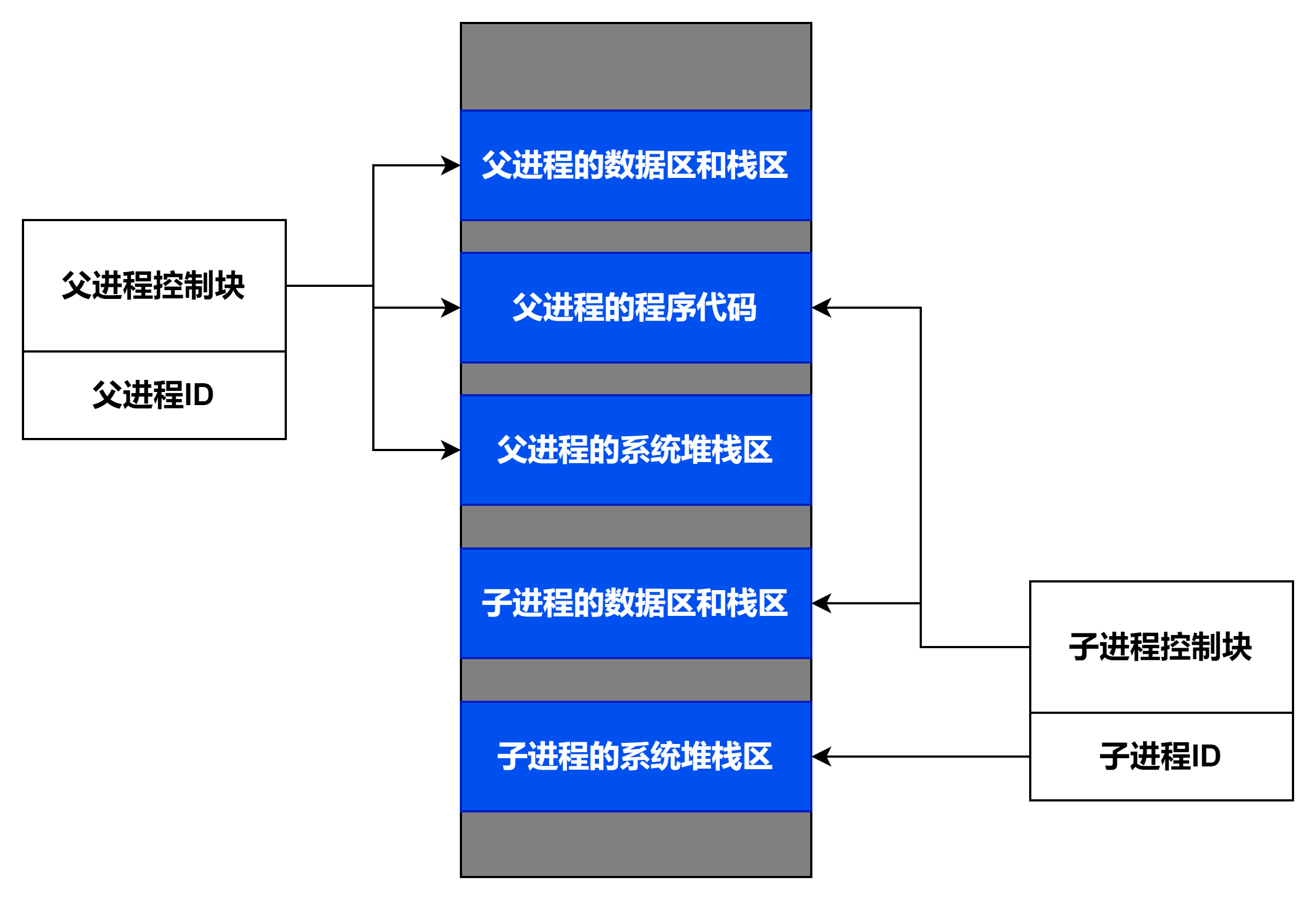
在Linux中,我们通常使用fork函数来为一个已经存在的进程创建一个新进程。而这个新创建出来的进程被称为原进程的子进程,原进程被称为该进程的父进程。
pid_t fork(void);特性:子进程会复制父进程的PCB,二者之间代码共享,数据独有,拥有各自的进程虚拟地址空间。
此时可能会有一个疑问,既然代码共享,并且子进程是拷贝了父进程的PCB,虽然他们各自拥有自己的进程虚拟地址空间,但其中的数据必然是相同的(拷贝而来),并且通过页表映射到同一块物理内存中,那么又如何做到数据独有呢?答案是:通过写时拷贝技术。
写时拷贝技术:子进程创建出来后,与父进程映射访问同一块物理内存,但当父子进程当中有任意一个进程更改了内存中的数据时,会给子进程重新在物理内存中开辟一块空间,并将数据拷贝过去。 这样避免了直接给子进程重新开辟内存空间,造成内存数据冗余。换句话说,如果父子进程都不更改内存中的值,那他们二者各自的进程虚拟地址空间通过页表映射,始终是指向同一块物理内存。
②fork 函数例子
#include <stdio.h>
#include <unistd.h>
int val=100;
int main()
{
pid_t pid=fork();
if(pid<0){
printf("fork error!\n");
return -1;
}else if(pid ==0){
val=200;
printf("This is Child! val=%d p=%p\n",val,&val);
}else{
sleep(1);
printf("This is Parent! val=%d p=%p\n",val,&val);
}
return 0;
}

③fork子进程与父进程之间的联系
1.2、execv函数
①execv函数介绍
linux为了在程序运行中能够加载并运行一个可执行文件,Linux提供系统调用execv()。
int execv(const char* path, char* const argv[]);
备注:参数path为可执行文件路径,argv[]为命令行参数如果一个进程调用了execv(),那么该函数便会把函数参数path所指定的可执行文件加载到进程的用户内存空间,并覆盖掉原文件,然后便运行这个新加载的可执行文件。
在实际应用中,通常调用execv()的都是子进程。人们之所以创建一个子进程,其目的就是执行一个与父进程代码不同的程序,而系统调用execv()就是子进程执行一个新程序的手段之一。子进程调用execv()之后,系统会立即为子进程加载可执行文件分配私有程序内存空间,从此子进程也成为一个真正的进程。
②execv函数例子
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid=fork();
if(pid<0){
printf("fork error!\n");
return -1;
}else if(pid ==0){
execv("/bin/ls",NULL);
printf("Test\n"); //不会返回到这里
}
return 0;
}
结果:

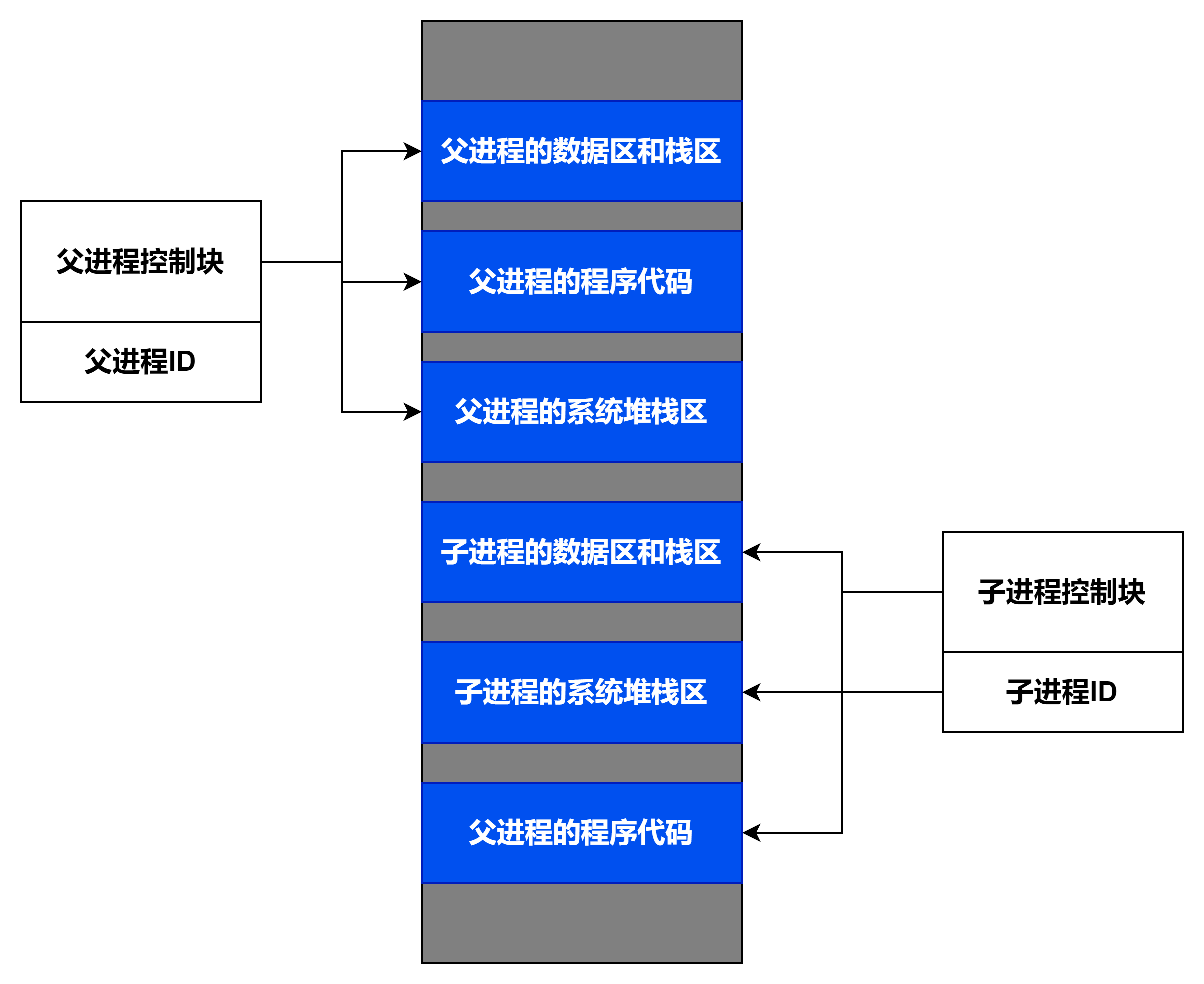
②execv子进程与父进程之间的联系
只有execv()是真正意义上的系统调用,其他的都是在此基础上经过包装的库函数。
与一般的函数不同,exec族函数执行成功后一般不会返回调用点,因为它运行了一个新的程序,进程的代码段、数据段和堆栈等都已经被新的数据所取代,只留下进程ID等一些表面信息仍保持原样,虽然还是旧的躯壳,但是其实质内容已经全部变化了。只有调用失败了,它们才会返回一个-1,从原程序的调用点接着往下执行。
1.3、shell 执行./a.out的流程
①调用fork创建一个新进程
②调用execv创建新进程(覆盖代码段)
③使用_fo_fork创建新进程
- 创建新进程的task_struct数据结构
- 复制父进程的task_struct数据结构到新进程
- 复制父进程相关的页表项到新进程
- 设置新进程的内核栈
④插入调度列表
- 调用调度类select_task_rq(),为新进程寻找一个负载最轻的CPU(如果CPU0有四个线程在运行,CPU有一个线程在运行,那么新进程在寻址负载最轻的CPU为CPU1)
- 调用调度类的enqueue_task(),把新进程添加到CPU1的就绪队列里
⑤调度新进程
- 每次时钟节拍到来时,scheduler_tick()检查是否需要重新调度;check_preempt_tick会做检查,当需要重新调度时会设置当前进程的thread_info中的TIF_NEED_RESCHED标志位。
- 在中断返回前会检查当前进程是否需要调度。如需要调度,调用preempt_schedule_irq来切换进程运行。
- 调度器的schedule函数会调用调度类的pick_next_task来选择下一个最合适的进程
- switch_mm切换父进程和新进程的页表
- switch_to切换进程来运行
2、进程创建的代码跟读
2.1、fork函数源码分析
①fork -> do_fork/kernel_clone
注意:从内核的提交记录来看,在v5.10-rc1将_do_fork替换成了kernel_clone,因此fork/vfork/clone系统调用底层都将调用kernel_clone
fork->
weak_alias (__libc_fork, fork) //__libc_fork别名为fork
__libc_fork->
_Fork->
arch_fork->
INLINE_SYSCALL_CALL(clone,...)->
sys_clone->
do_fork()/kernel_clone()
②kernel_clone代码分析
在代码分析前,先了解一下进程相关的重要数据结构,如下:
标识符:与进程相关的唯一标识符,用来区别正在执行的进程和其他进程。
状态:描述进程的状态,因为进程有挂起,阻塞,运行等好几个状态,所以都有个标识符来记录进程的执行状态。
优先级:如果有好几个进程正在执行,就涉及到进程被执行的先后顺序的问题,这和进程优先级这个标识符有关。
程序计数器:程序中即将被执行的下一条指令的地址。
内存指针:程序代码和进程相关数据的指针。
上下文数据:进程执行时处理器的寄存器中的数据。
I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表等。
记账信息:包括处理器的时间总和,记账号等等。
struct task_struct { //进程描述符
...
//运行状态值 -1:不可运行 0:在运行 >0:停止的
volatile long state;
...
int on_rq; //是否在就绪队列中
int prio; //动态优先级
int static_prio; //静态优先级
int normal_prio; //取决于静态优先级和调度策略
unsigned int rt_priority; //实时优先级
...
//调度策略 例如SCHED_NORMAL:用于普通进程,通过CFS调度器实现
unsigned int policy;
const struct sched_class *sched_class;
struct sched_entity se; //普通进程的调用实体
struct sched_rt_entity rt; //实时进程的调用实体
struct sched_dl_entity dl; //deadline的调用实体
...
pid_t pid; //进程的标识符
pid_t tgid; //线程组的领头线程的pid成员的值
...
int nr_cpus_allowed; //该进程允许的CPU数量
cpumask_t cpus_mask; //用于控制进程在那个处理器上运行
...
struct mm_struct *mm, //进程内存分区管理
struct mm_struct *active_mm; //进程活动的内存分区管理
...
//指向其父进程,如果创建它的父进程不再存在,则指向PID为1的init进程
struct task_struct __rcu *real_parent;
//指向其父进程,它的值通常与real_parent相同
struct task_struct __rcu *parent;
struct list_head children; //当前进程的子进程列表
struct list_head sibling; //父进程的子进程列表
struct task_struct *group_leader; //指向其所在进程组的领头进程 ...
pid_t pid; //进程的标识符
pid_t tgid; //进程的标识符
...
//用来表示进程与文件系统的联系,包括当前目录和根目录
struct fs_struct *fs;
//表示进程当前打开的文件
struct files_struct *files;
...
struct list_head tasks; //进程的链表
...
};
kernel_clone的代码分析如下:
kernel_clone->
struct task_struct *p;
//创建新的进程任务队列并返回
p = copy_process(NULL, trace, NUMA_NO_NODE, args);->
//创建task_struct,并将父进程的资源拷贝给子进程
p = dup_task_struct(current, node);->
//为task_struct分配内存空间
tsk = alloc_task_struct_node(node);
//为新进程分配内核栈空间
stack = alloc_thread_stack_node(tsk, node);
//复制父进程描述符的所有内容复制到子进程
err = arch_dup_task_struct(tsk, orig);
//新进程的stack指向新分配的内核栈
tsk->stack = stack;
//拷贝thread_info,并将thread_info下的task指向当前进程
setup_thread_stack(tsk, orig);
//复制父进程的证书
retval = copy_creds(p, clone_flags);
//初始化p->delays
delayacct_tsk_init(p);
//设置进程为非超级用户,非WQ_WORKER线程,非idie线程
p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER | PF_IDLE);
p->flags |= PF_FORKNOEXEC;
//初始化新进程的子进程链表
INIT_LIST_HEAD(&p->children);
//初始化新进程的兄弟进程链表
INIT_LIST_HEAD(&p->sibling);
/*对从父进程拷贝来的task_struct进行一些重新初始化*/
//进程调度初始化,包括进程状态/等级/调度策略等,并将进程指派到某一个cpu
retval = sched_fork(clone_flags, p);
//复制父进程打开的文件等信息
retval = copy_files(clone_flags, p);
//复制父进程的fs_struct信息
copy_fs(clone_flags, p);
//复制父进程的信号系统
copy_sighand(clone_flags, p);
copy_signal(clone_flags, p);
//复制父进程的进程地址空间页表信息
copy_mm(clone_flags, p);
//为新进程分配pid数据结构和PID
pid = alloc_pid(p->nsproxy->pid_ns_for_children,...);
p->pid = pid_nr(pid);
//子进程是归属于父进程线程组
p->group_leader = current->group_leader;
p->tgid = current->tgid;
//获取pid和虚拟的pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid)
//将进程加入到就绪队列
wake_up_new_task(p);
//返回pid
return nr;
2.2、execv函数源码分析
①execv -> do_execveat_common
execv->
__execve->
SYSCALL_DEFINE3(execve,...)-> //系统调用
do_execve->
do_execveat_common-> //开始做事情
②do_execveat_common分析
在代码分析前,先了解一下进程相关的重要数据结构,如下:
struct linux_binprm {
char buf[BINPRM_BUF_SIZE]; // BINPRM_BUF_SIZE 的值为 128,用于保存可执行文件的前 128 个字节
struct vm_area_struct *vma; //保存参数用的 vma 结构
unsigned long vma_pages; //对应的 vma pages
struct mm_struct *mm; //当前进程的 mm_struct 结构,该结构描述 linux 下进程的地址空间的所有的内存信息
unsigned long p; //
unsigned int
called_set_creds:1,
cap_elevated:1,
secureexec:1;
//这三个成员涉及到用户与访问权限
unsigned int recursion_depth; //记录 search_binary_handler 调用时的递归深度,在 4.14 版本内核中设置不能大于 5
struct file * file; //每个打开的文件都对应一个 struct file 结构,该 file 对应需要执行的可执行文件
struct cred *cred; //用户访问权限相关
int unsafe; //安全性描述字段
unsigned int per_clear; /* bits to clear in current->personality */
int argc, envc;
const char * filename; //要执行的文件名称
const char * interp; //要执行的真实文件名称,对于 elf 文件格式而言,等于 filename。
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
} __randomize_layout;
struct linux_binfmt {
struct list_head lh; //链表节点,所有类型的可执行文件对应的 struct linux_binfmt 结构会被链接到一个全局链表中,正是通过该节点链入
struct module *module; //对应的 module
int (*load_binary)(struct linux_binprm *); // 该回调函数实现可执行文件的加载
int (*load_shlib)(struct file *); // 该回调函数实现动态库的加载
int (*core_dump)(struct coredump_params *cprm); // core_dump 回调函数,用于核心转储文件
unsigned long min_coredump; // 最小的转储文件大小
} __randomize_layout;
do_execveat_common(已于kernel-5.10)分析如下:
do_execveat_common->
//为bprm结构分配内存空间,初始化struct mm_struct *mm(地址空间对象)
bprm = alloc_bprm(fd, filename);
//获取参数的个数
retval = count(argv, MAX_ARG_STRINGS);
//获取环境参数的个数
retval = count(envp, MAX_ARG_STRINGS);
//复制文件名
retval = copy_string_kernel(bprm->filename, bprm);
//复制环境变量
retval = copy_strings(bprm->envc, envp, bprm);
//复制命令行参数
retval = copy_strings(bprm->argc, argv, bprm);
//执行可执行文件
retval = bprm_execve(bprm, fd, filename, flags);->
//打开可执行文件
file = do_open_execat(fd, filename, flags);
//实现处理器均衡负载
sched_exec->
//开始执行加载到内存中的ELF文件
exec_binprm->
search_binary_handler->
//检查用户权限
retval = security_bprm_check(bprm);
//调用合适格式的处理函数加载该可执行文件,这里是load_elf_binary
//加载进来的可执行文件将把当前正在执行的进程的内存空间完全覆盖掉
//如果可执行文件是静态链接的文件,进程的IP寄存器值将被设置为main函数的入口地址,从而开始新的进程
//如果可执行文件是动态链接的,IP的值将被设置为加载器ld的入口地址,是程序的运行由该加载器接管,ld会处理一些依赖的动态链接库相关的处理工作,使程序继续往下执行
//而不管哪种执行方式,当前的进程都会被新加载进来的程序完全替换掉
retval = fmt->load_binary(bprm);->
load_elf_binary->
3、linux进程调度
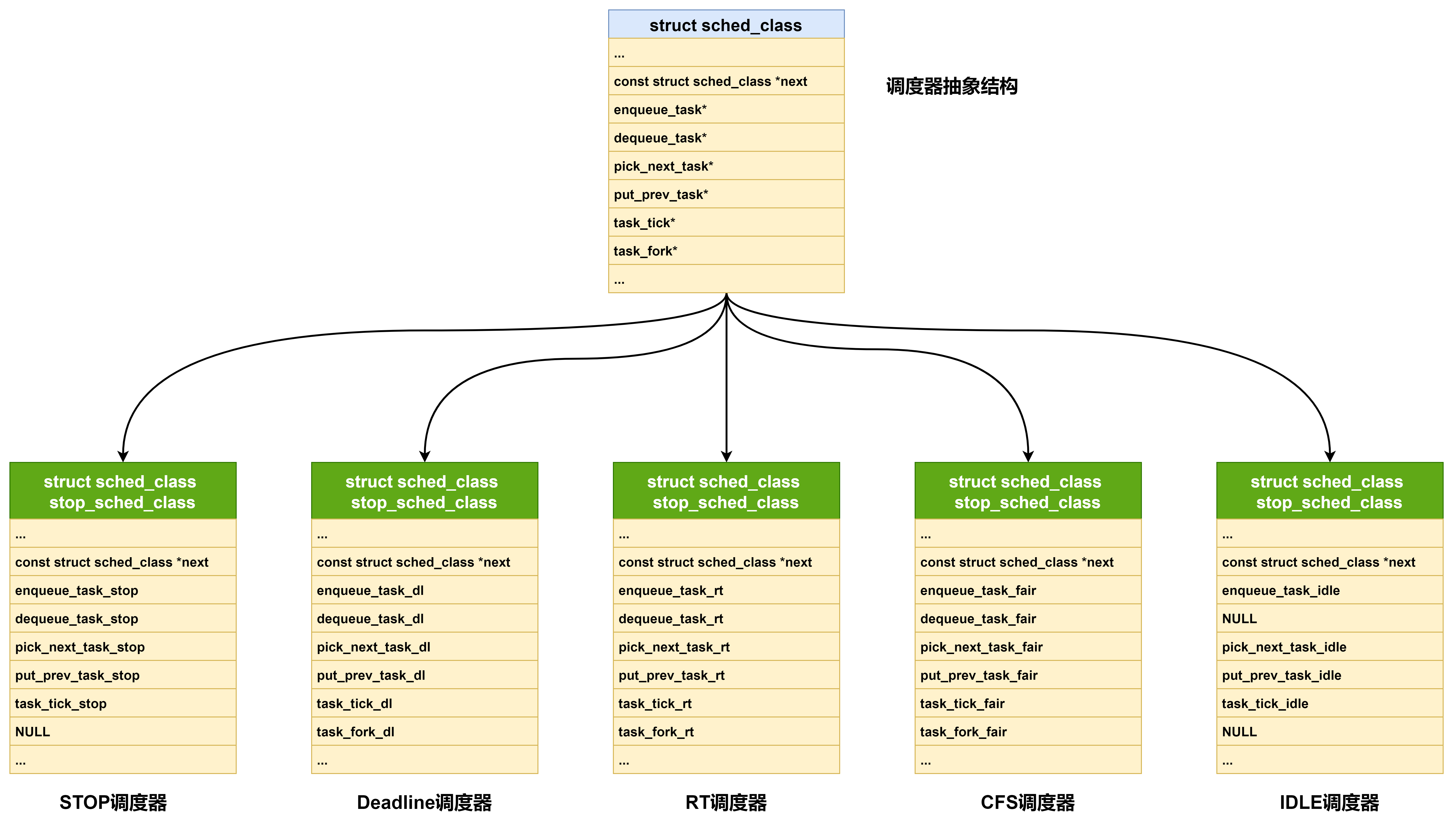
3.1、struct sched_class
struct sched_class:对调度器进行抽象,一共分为5类.
1、Stop调度器:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占;
2、Deadline调度器:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行;
3、RT调度器:为每个优先级维护一个队列;
4、CFS调度器:采用完全公平调度算法,引入虚拟运行时间概念;
5、IDLE-Task调度器:每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程;
3.2、unsigned int policy
unsigned int policy:进程的调度策略有6种,用户可以调用调度器里的不同调度策略。
①SCHED_DEADLINE:使task选择Deadline调度器来调度运行
②SCHED_RR:时间片轮转,进程用完时间片后加入优先级对应运行队列的尾部,把CPU让给同优先级的其他进程;
③SCHED_FIFO:先进先出调度没有时间片,没有更高优先级的情况下,只能等待主动让出CPU;
④SCHED_NORMAL:使task选择CFS调度器来调度运行;
⑤SCHED_BATCH:批量处理,使task选择CFS调度器来调度运行;
⑥SCHED_IDLE:使task以最低优先级选择CFS调度器来调度运行;
3.3 CFS调度器
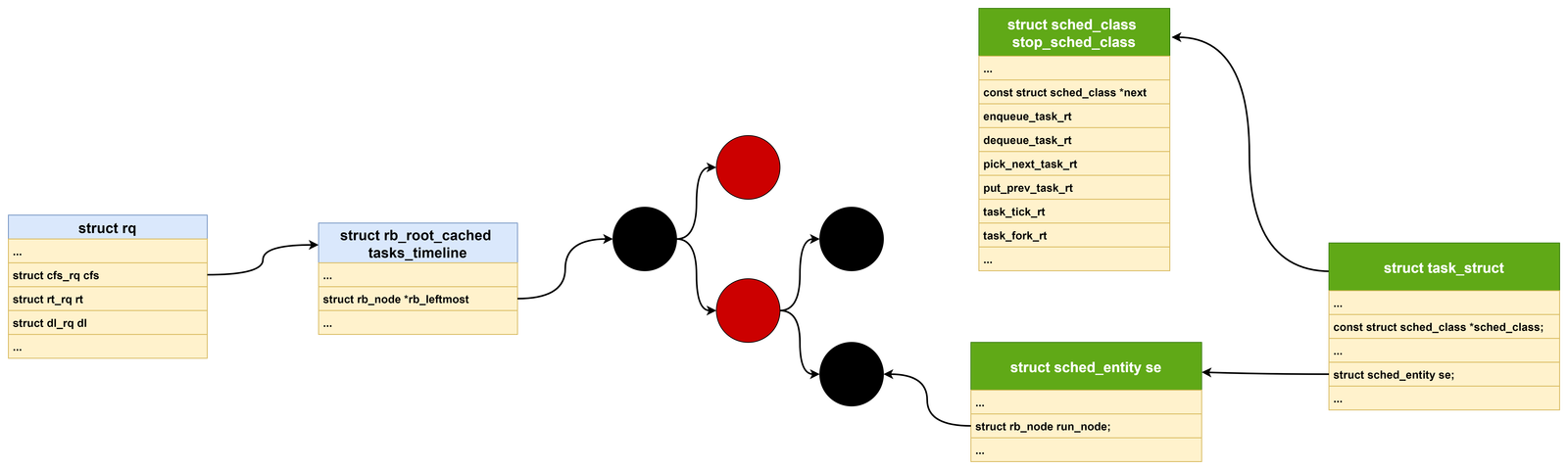
1、runqueue 运行队列
runqueue 运行队列是本 CPU 上所有可运行进程的队列集合。
struct rq {
......
struct cfs_rq cfs; //CFS调度队列
struct rt_rq rt; //RT调度队列
struct dl_rq dl; //DL调度队列
......
}
struct cfs_rq {
...
struct rb_root_cached tasks_timeline
...
};
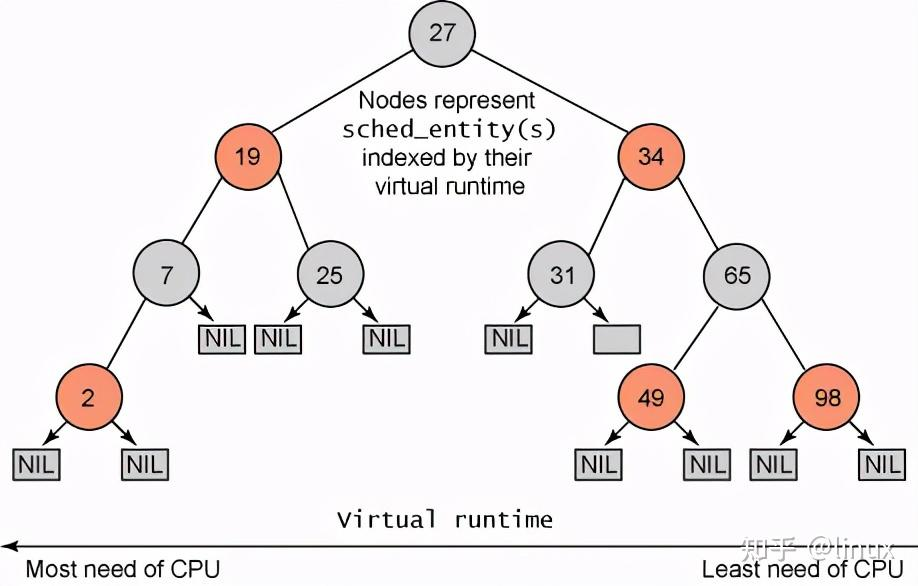
cfs_rq:跟踪就绪队列信息以及管理就绪态调度实体,并维护一棵按照虚拟时间排序的红黑树。tasks_timeline->rb_root是红黑树的根,tasks_timeline->rb_leftmost指向红黑树中最左边的调度实体,即虚拟时间最小的调度实体。
3.4、进程调度
调度的本质就是选择下一个进程,然后切换,调度前会判断TIF_NEED_RESCHED参数是否被设置,如果进程的标志位被设置为TIF_NEED_RESCHED,那么调用函数 schedule 进行调度。
1、调度标记设置的时刻
①scheduler_tick 时钟中断
②wake_up_process 唤醒进程的时候
③do_fork 创建新进程的时候
④set_user_nice 修改进程nice值的时候
⑤smp_send_reschedule 负载均衡的时候
3.5、执行调度
Kernel 判断当前进程标记是否为 TIF_NEED_RESCHED,是的话调用 schedule 函数,执行调度,切换上下文,这也是上面抢占(preempt)机制的本质。那么在哪些情况下会执行 schedule 呢?
1、用户态抢占
ret_to_user 是异常触发,系统调用,中断处理完成后都会调用的函数
2、内核态抢占
可以看出无论是用户态抢占,还是内核态抢占,最终都会调用 schedule 函数来执行真正的调度:
schedule->
__schedule->
next = pick_next_task(rq, prev, &rf);->
//CFS调度器调度执行任务调度
p = pick_next_task_fair(rq, prev, rf);
3.6、CFS 公平调度算法
CFS 引入了虚拟时间的概念。虚拟时间(vriture_runtime)和实际时间(wall_time)转换公式如下:
vriture_runtime = (wall_time * NICE0_TO_weight) / weight
其中,NICE0_TO_weight 代表的是 nice 值等于0对应的权重,即1024,weight 是该任务对应的权重。
权重越大的进程获得的虚拟运行时间越小,那么它将被调度器所调度的机会就越大,所以,CFS 每次调度原则是:总是选择 vriture_runtime 最小的任务来调度。
为了能够快速找到虚拟运行时间最小的进程,Linux 内核使用红黑树来保存可运行的进程。CFS跟踪调度实体sched_entity的虚拟运行时间vruntime,将sched_entity通过enqueue_entity()和dequeue_entity()来进行红黑树的出队入队,vruntime少的调度实体sched_entity排列到红黑树的左边。
参考:
1、CFS Scheduler — The Linux Kernel documentation
3、Linux-进程控制详解(进程创建+进程终止+进程等待+进程程序替换)_fork core dump-CSDN博客
4、【Linux】Linux进程的创建与管理_linux创建独立进程-CSDN博客
5、在shell中执行一条可执行程序(./a.out) 系统执行的过程_shell脚本运行某个程序-CSDN博客
6、https://www.cnblogs.com/dakewei/p/12969572.html
7、linux 内核task_struct 源码分析与解析(整合配图)_task struct 分析-CSDN博客















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









