






目录
2.基于VMware Workstation 16 PRO安装Centos7
2.2用vmware打开master、slave1、slave2文件夹下的虚拟机,并重命名
2.4修改master、slave1、slave2的主机名和IP的映射
3.1 借助开源工具MobaXterm将jdk-8u221-linux-x64.tar.gz上传到/usr/loca路径。
4.2.1在 /usr/local/zookeeper/bin/目录下新建脚本(启动和 停止)
4.2.4新建data和logs目录(data目录用来存放数据库快照,logs目录用来存放日志文件)
4.2.5重命名 zoo_sample.cfg 为zoo.cfg
4.2.7在data目录下面新建一个myid文件,将刚才添加代码里面server.n的n写入myid文件里面,只写入数字。
4.2.8将配置好了的zookeeper文件分发给slave1、slave2
4.3.1 启动master主服务器上面的zookeeper,其次slave1和slave2
5.1.1将hadoop-2.7.1.tar.gz上传到Centos7的/usr/local路径
5.1.2解压hadoop-2.7.1.tar.gz到/usr/local
5.1.4.7将配置好了的hadoop文件分发给slave1、slave2
5.1.5.1启动journalnode,三台机器都要这一步操作(仅第一次启动hadoop时,需要这一步操作,之后不再需要手动启动journalnode)
5.1.5.2在hadoop-01上执行格式化操作,格式化namenode和zkfc
5.1.5.3namenode主从信息同步,在hadoop-02节点上执行同步命令
5.1.5.4.5kill 掉主节点的 namenode 进程, 检验hadoop-02是否会自动切换到namenode
5.1.5.4.6再一次登录192.168.89.101:50070进行查看
2.2.6将配置好了的HBase文件分发给slave1、slave2
3.启动MySQL的mysqld进程(该进程是MySQL的服务端进程):
导引
使用Hadoop、Hbase搭建新能源汽车大数据平台。
要求:
- 集群至少要有三个节点;
- 由于条件有限,所以要求集群至少可以存储100G的数据;
- 将HDFS副本数设置为3;
- NameNode要高可用,即运行两个NameNode进程,同一时刻只有一个对外提供服务的NameNode,如果活跃的NameNode进程所在机器宕机了,整个集群还是可以正常运行的;
- 可以正常提交MapReduce运行;
- Hbase要集群部署,可正常建表、插入数据和查询数据等;
- 部署一个Mysql数据库,要求可以远程访问。
Hadoop集群搭建
1.安装VMware Workstation 16 PRO
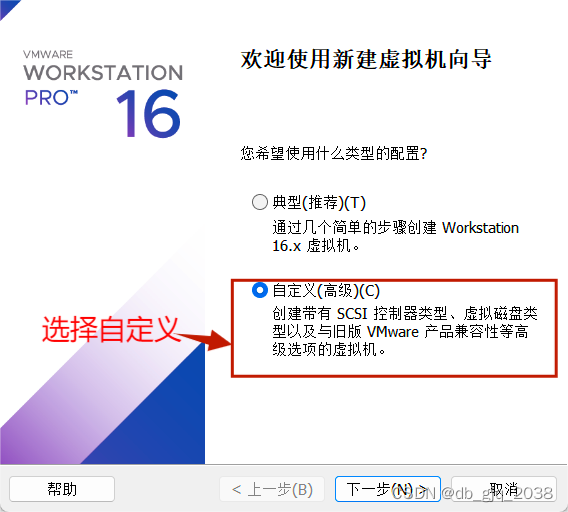
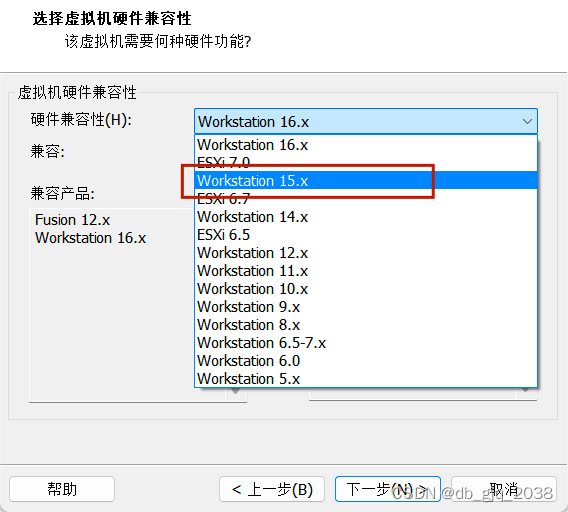
2.基于VMware Workstation 16 PRO安装Centos7
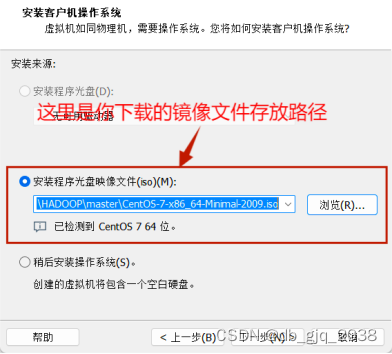
CentOS-7-x86_64-Minimal-2009.iso迅雷云盘![]() https://pan.xunlei.com/s/VNYbE5JmedEpJeF_Cj_vpN5LA1?pwd=p7kn#
https://pan.xunlei.com/s/VNYbE5JmedEpJeF_Cj_vpN5LA1?pwd=p7kn#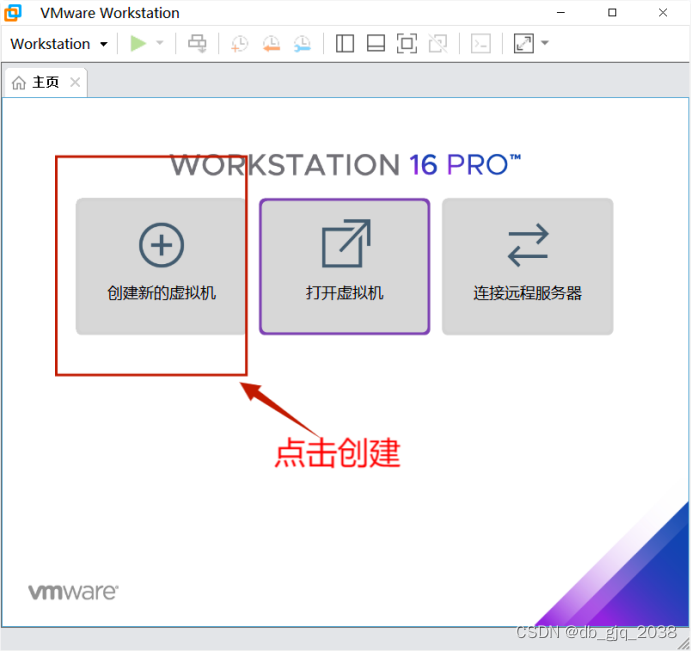
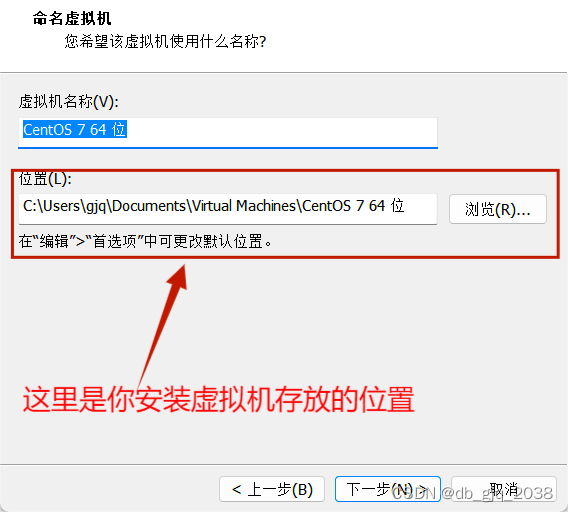
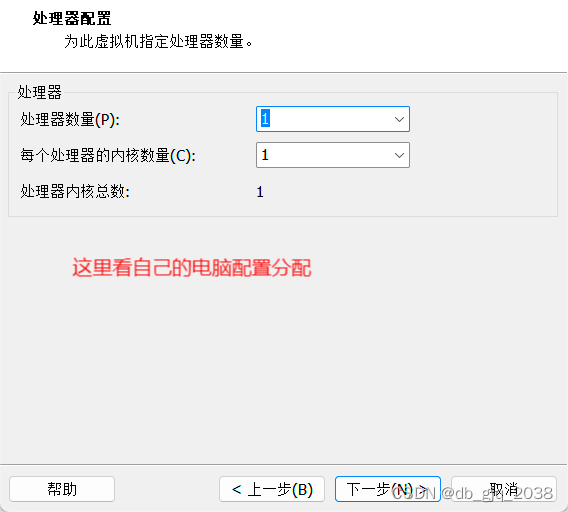
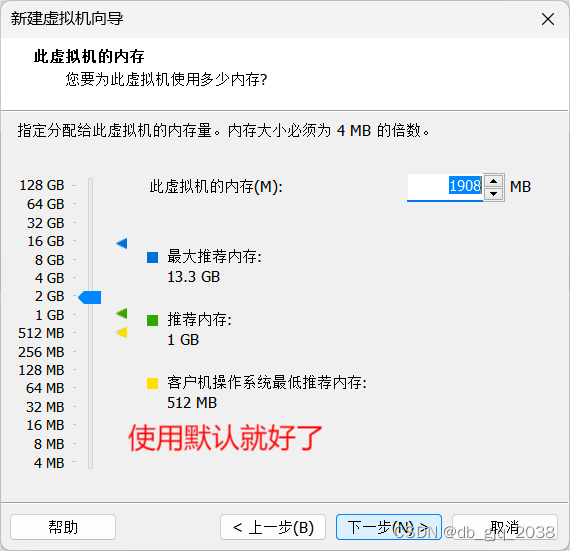
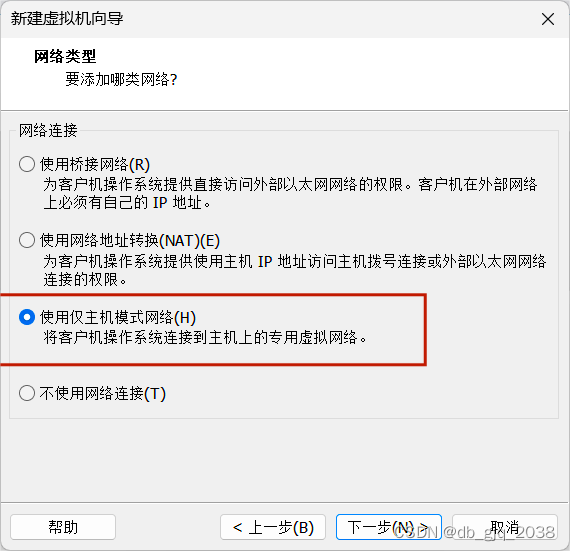
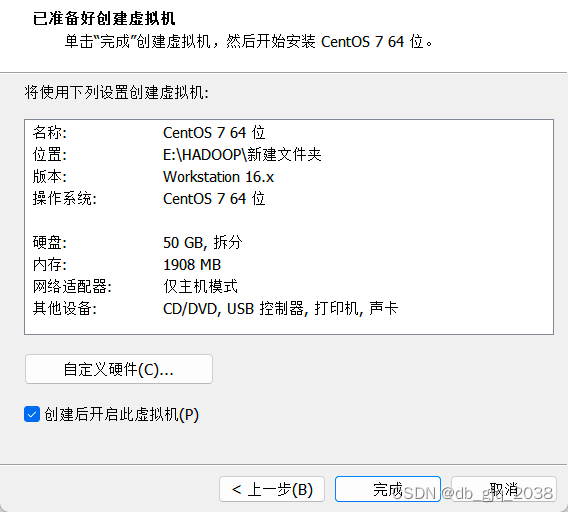
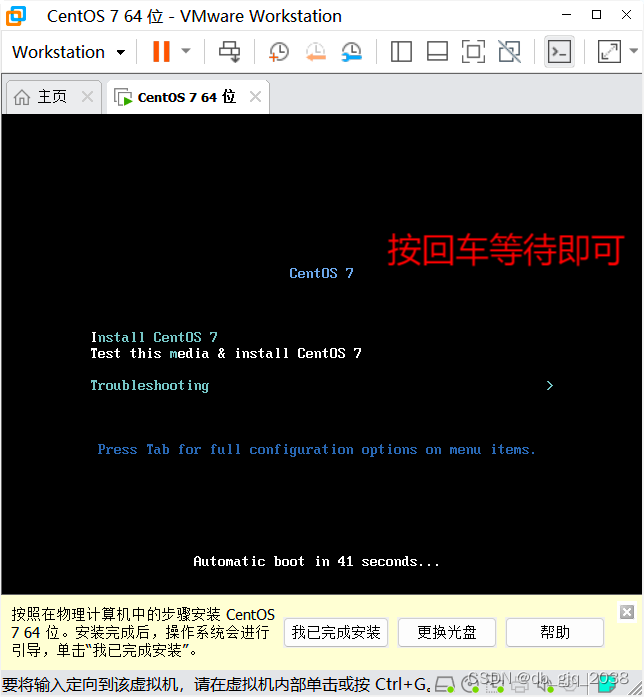
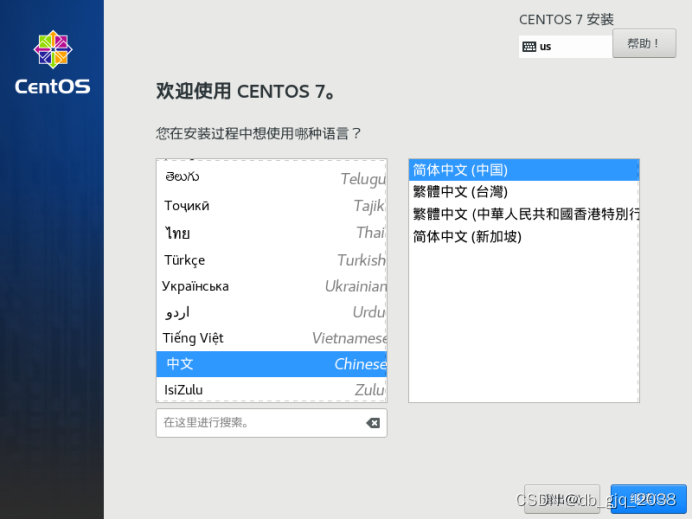
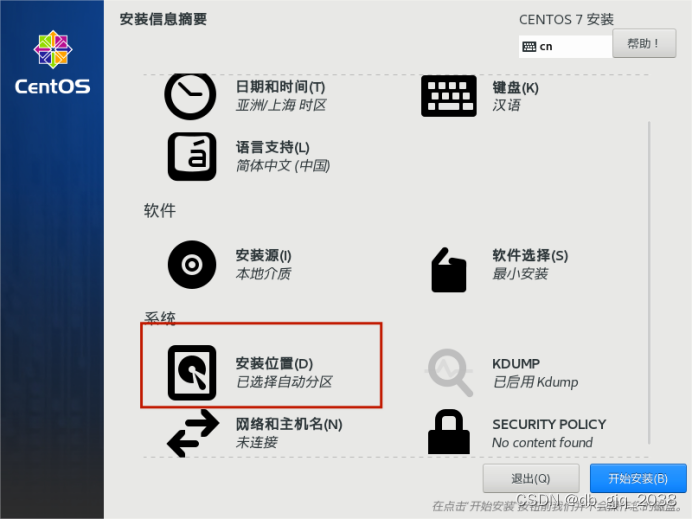
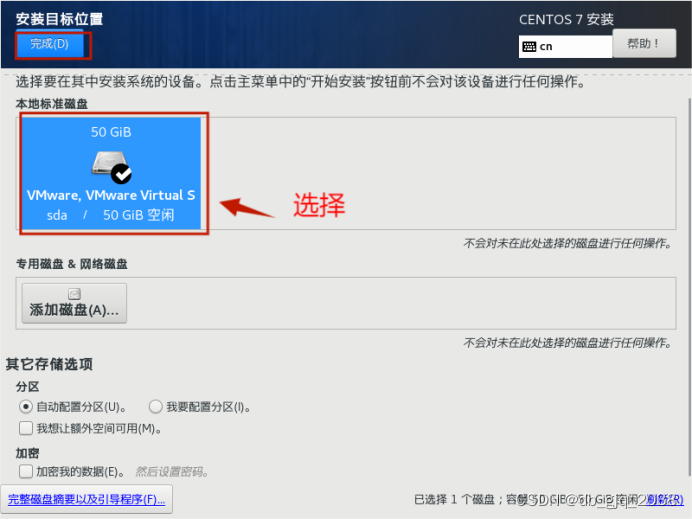
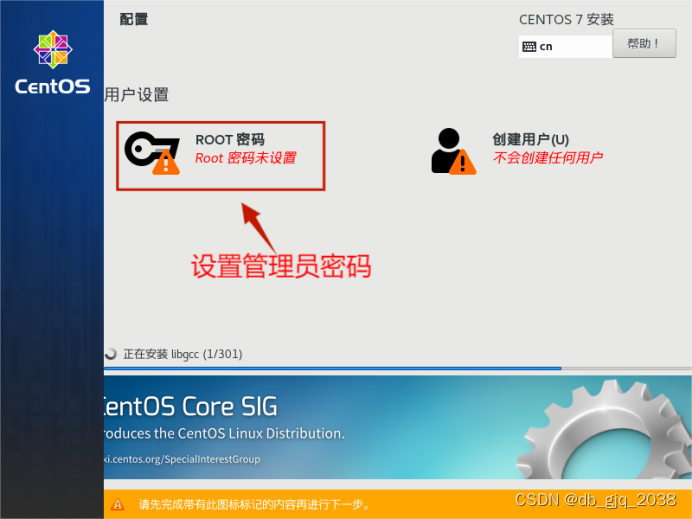

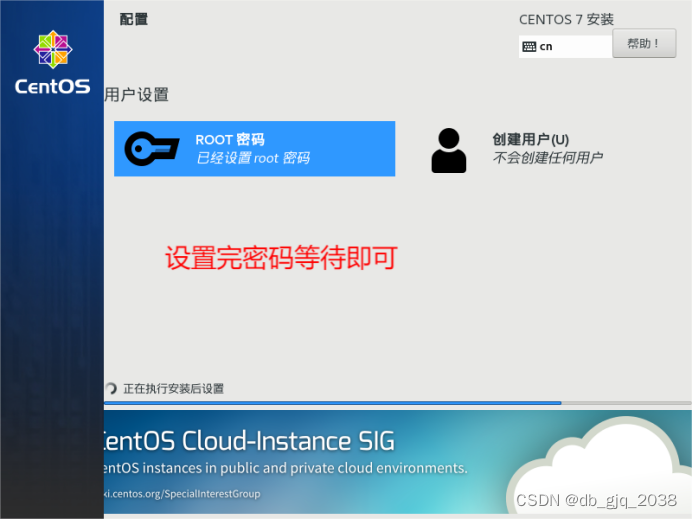
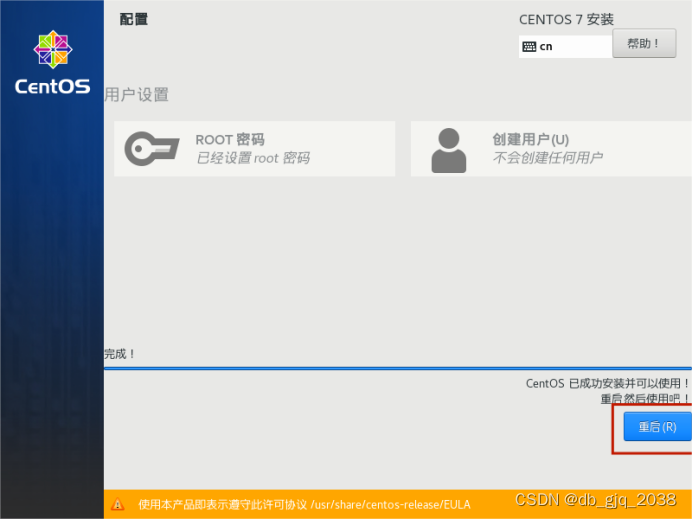
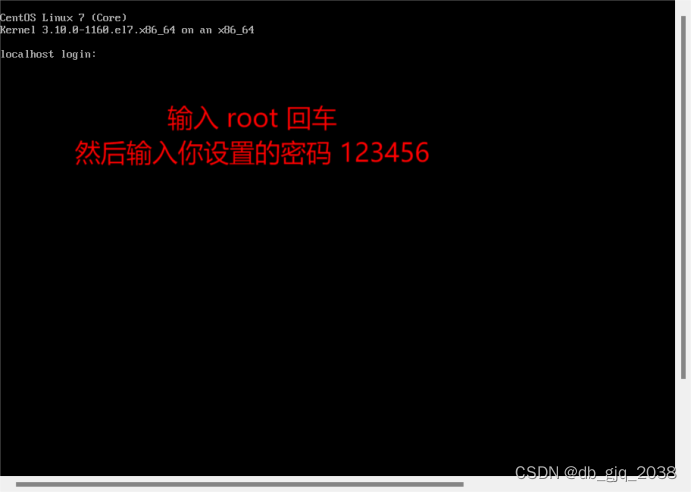
完全分布式安装
1.Hadoop集群节点设置
| IP | 主机名 | 描述 | 部署软件 |
| 192.168.89.100 | master | 主节点 | jdk,hadoop,zookee,Hbase,MySQL |
| 192.168.89.101 | slave1 | 备用主节点 | jdk,hadoop,zookeeper,Hbase,MySQL |
| 192.168.89.102 | slave2 | 数据服务节点 | jdk,hadoop,zookeeper,Hbase,MySQL |
2.准备三台虚拟机
2.1找到我们上面做好的虚拟机的根目录
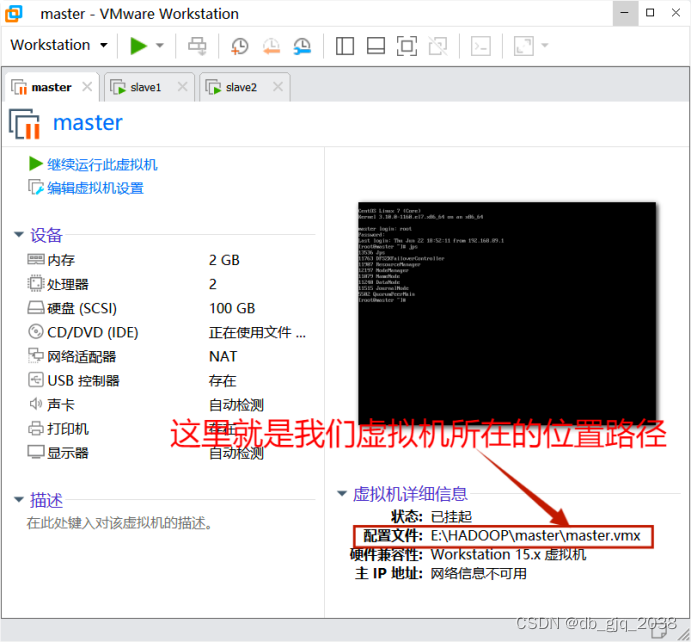

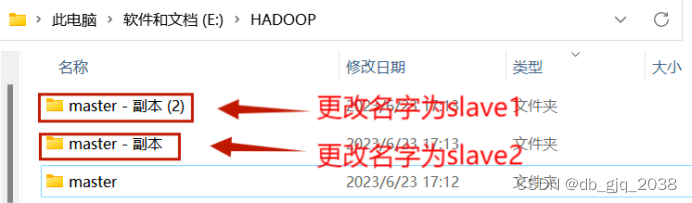

2.2用vmware打开master、slave1、slave2文件夹下的虚拟机,并重命名
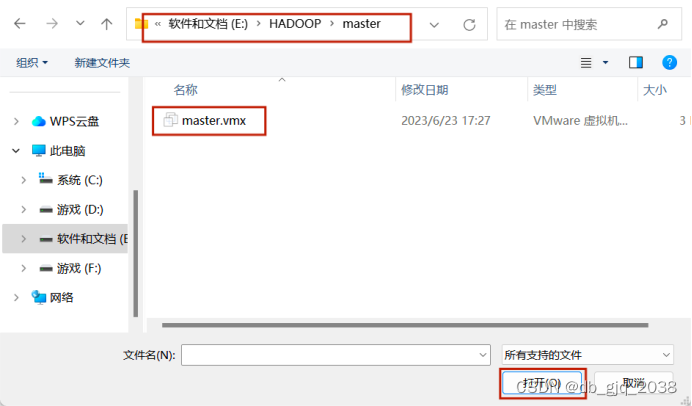
slave1、slave2如上操作。
2.3修改master、slave1、slave2的ip
通过执行这个命令 vi /etc/sysconfig/network-scripts/ifcfg-ens33,编辑ifcfg-ens33,修改master IP修改为192.168.89.100 slave1 IP修改为192.168.89.101 slave2 IP修改为192.168.89.102
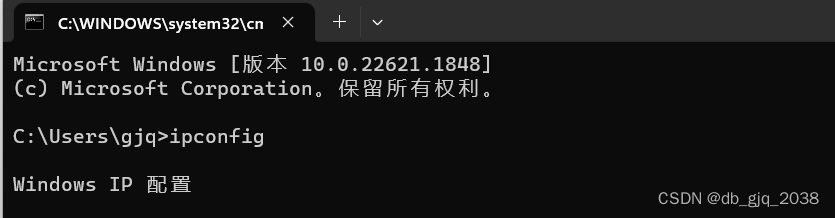
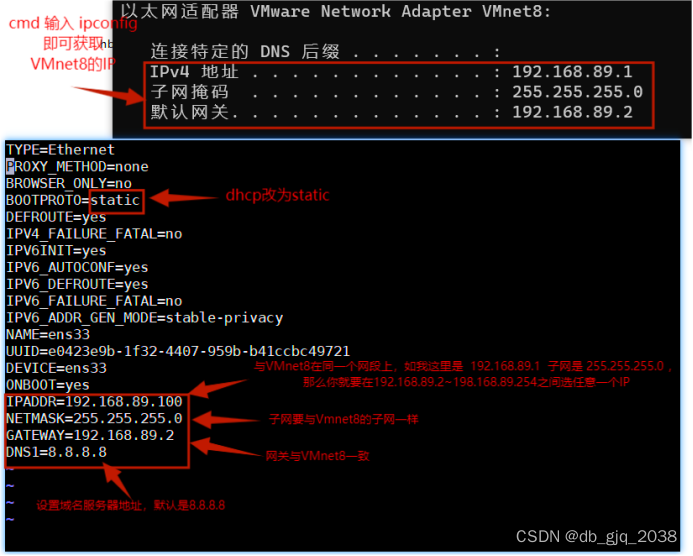
IP修改后重启网卡:systemctl restart network
ping www.qq.com确认访问外网有无问题。
如有问题先把虚拟机关机,按以下操作。
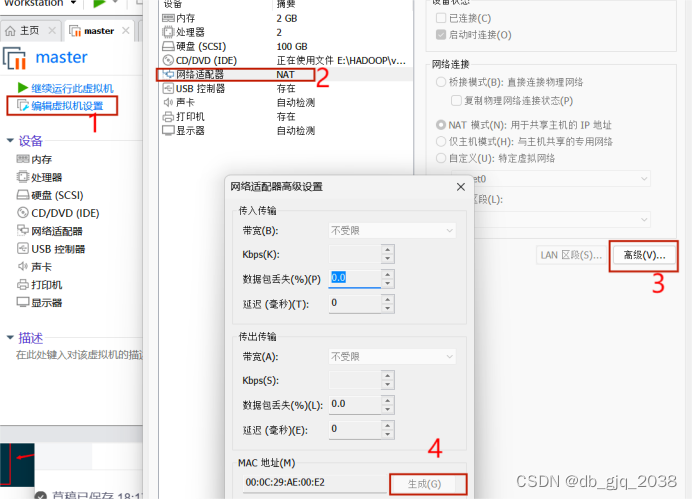
执行hostnamectl set-hostname master,将主机名改为master.
使用命令:su root 即可看到最新主机名

2.4修改master、slave1、slave2的主机名和IP的映射
输入命令: vi /etc/hosts 设置IP映射
master、slave1、slave2三个主机的/etc/hosts新增的映射记录一样。下图是master的/etc/hosts文件的内容:
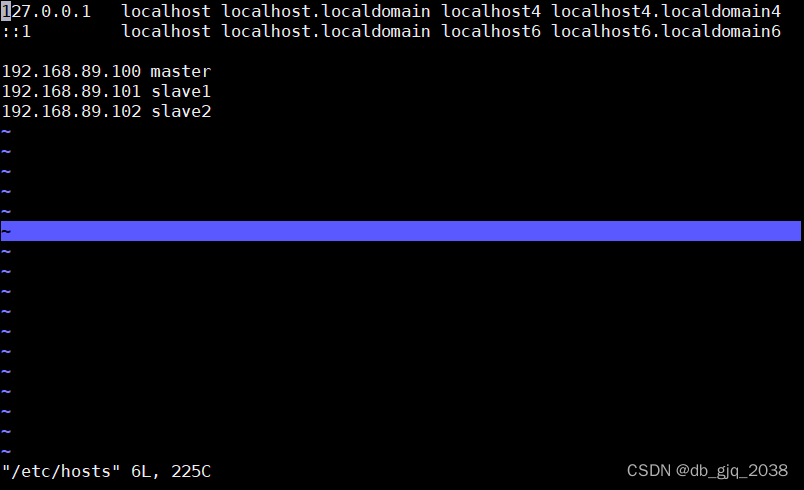
master的hosts映射配置好后,可以通过scp命令将master修改好的/etc/hosts文件,同步到slave1、slave2主机上。
scp /etc/hosts root@slave1:/etc
scp /etc/hosts root@slave2:/etc2.5设置免密登录和关闭防火墙
2.5.1首先生成公钥/私钥密码对:
master:
ssh-keygen -t rsa 通过这个命令生成公钥/私钥密码对
生成时一路按回车键
ssh-copy-id -i ~/.ssh/id_rsa.pub master 执行这个命令时,需要输入root@master的密码
slave1:
ssh-keygen -t rsa 通过这个命令生成公钥/私钥密码对
生成时一路按回车键
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1 执行这个命令时,需要输入root@slave1的密码
slave2:
ssh-keygen -t rsa 通过这个命令生成公钥/私钥密码对
生成时一路按回车键
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2 执行这个命令时,需要输入root@slave2的密码
2.5.2关闭防火墙
关闭防火墙命令: systemctl stop firewalld
查看防火墙是否开机自起命令:systemctl is-enabled firewalld
enabled表示开机自起,disabled表示开机不自起
![]()
禁止防火墙开机自启命令:systemctl disabled direwalld
![]()
3.在Centos7中安装jdk8
MObaXterm迅雷云盘![]() https://pan.xunlei.com/s/VNYc7vufFURmh3Baz93-ffw7A1?pwd=jxj9#
https://pan.xunlei.com/s/VNYc7vufFURmh3Baz93-ffw7A1?pwd=jxj9#
jdk迅雷云盘![]() https://pan.xunlei.com/s/VNYc7Xa4u5vdMb--TySzEVOtA1?pwd=rekk#
https://pan.xunlei.com/s/VNYc7Xa4u5vdMb--TySzEVOtA1?pwd=rekk#
3.1 借助开源工具MobaXterm将jdk-8u221-linux-x64.tar.gz上传到/usr/loca路径。
基本原理是:先通过ssh远程登录到虚拟机,然后借助MobaXterm的sftp功能上传文件。
注:第一次登陆需要密码
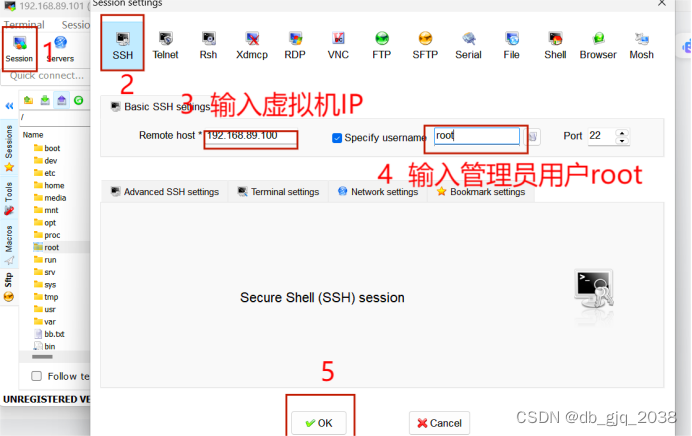
将jdk-8u221-linux-x64.tar.gz上传到Centos7的/usr/local路径
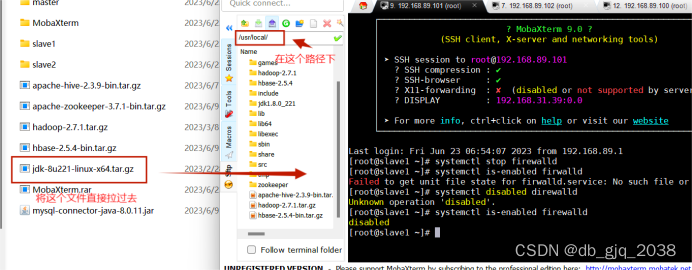
3.2 解压jdk到/usr/local路径下
切换路径:cd /usr/local
![]()
解压:tar -xzvf jdk-8u221-linux-x64.tar.gz
3.3添加环境变量
在/etc/profile文件最后追加两行:
export JAVA_HOME=/usr/local/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$PATH这个命令进去:vi /etc/profile
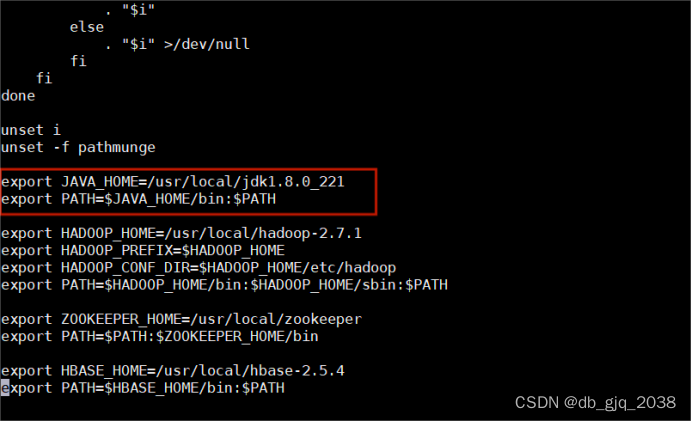
用这个命令:source /etc/profile就可以将全局变量刷新,重新可以获取全局变量的信息;

在执行java -version

3.4将配置好jdk文件分发给slave1、slave2
用scp命令进行文件传送
scp -r /usr/local/jdk1.8.0_221 root@slave1:/usr/loacl
scp -r /usr/local/jdk1.8.0_221 root@slave1:/usr/loacl4.在Centos7中安装zookeeper
4.1安装与解压zookeeper
zookeeper迅雷云盘![]() https://pan.xunlei.com/s/VNYcKOnnXMNP6YkPD6GH_svGA1?pwd=gtph#将apache-zookeeper-3.7.1-bin.tar.gz上传到Centos7的/usr/local路径
https://pan.xunlei.com/s/VNYcKOnnXMNP6YkPD6GH_svGA1?pwd=gtph#将apache-zookeeper-3.7.1-bin.tar.gz上传到Centos7的/usr/local路径
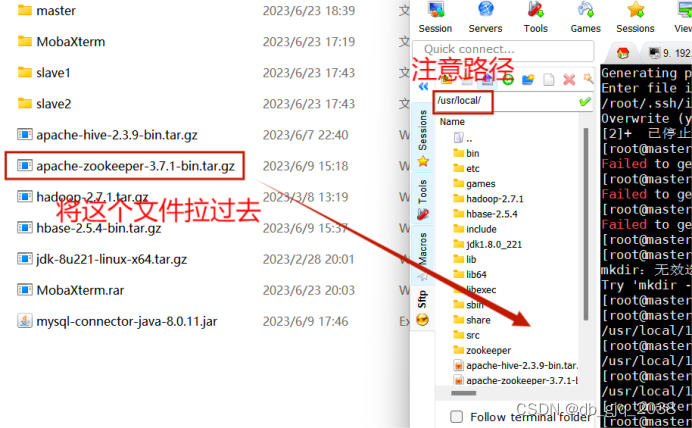
切换路径:cd /usr/local
解压:tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
安装后更改名字: mv apache-zookeeper-3.7.1-bin zookeeper
添加环境变量ZOOKEEPER_HOME
vi /etc/profile
在配置文件底下加上
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin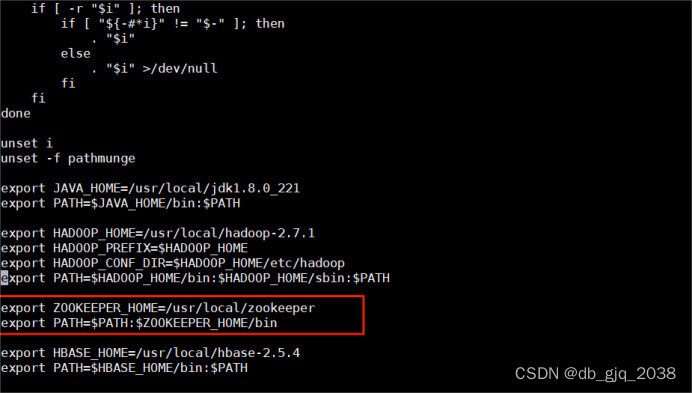
用这个命令:source /etc/profile就可以将全局变量刷新,重新可以获取全局变量的信息;
4.2集群模式配置
分布式模式需要每个节点都手动启动,所以我可以设置zookeeper集群启动脚本
4.2.1在 /usr/local/zookeeper/bin/目录下新建脚本(启动和 停止)
vi /usr/local/zookeeper/bin/zkstart-all.sh
#添加以下内容
#zkStart.sh
#start zk cluster
for host in master slave1 slave2
do
echo "===========start zk cluster :$host==============="
ssh $host 'source /etc/profile; /usr/local/zookeeper/bin/zkServer.sh start'
done
sleep 3s
#check status
for host in master slave1 slave2
do
echo "===========checking zk node status :$host==============="
ssh $host 'source /etc/profile;/usr/local/zookeeper/bin/zkServer.sh status'
done
4.2.1.1根据实际情况修改
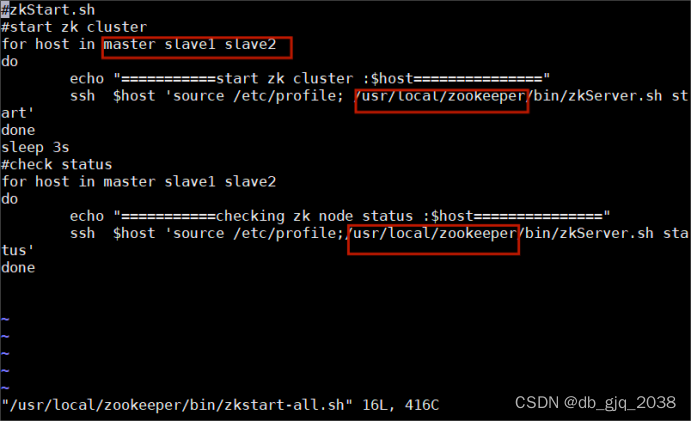
4.2.2添加停止脚本:
vi /usr/local/zookeeper/bin/zkstop-all.sh
#添加以下内容
#zkStop.sh
#stop zk cluster
for host in master slave1 slave2
do
echo "===========$host==============="
ssh $host ' source /etc/profile;/usr/local/zookeeper/bin/zkServer.sh stop'
done4.2.2.1根据实际情况修改

4.2.3最后修改一下权限
chmod 777 /usr/local/zookeeper/bin/zkstart-all.sh
chmod 777 /usr/local/zookeeper/bin/zkstop-all.sh4.2.4新建data和logs目录(data目录用来存放数据库快照,logs目录用来存放日志文件)
切换路径:cd /usr/local/zookeeper/
新建data:mkdir -p /usr/local/zookeeper/data
新建logs: mkdir -p /usr/local/zookeeper/logs
4.2.5重命名 zoo_sample.cfg 为zoo.cfg
切换路径:cd /usr/local/zookeeper/conf/
重命名:mv zoo_sample.cfg zoo.cfg
4.2.6用vi命令打开zoo.cfg文件
切换路径:cd /usr/local/zookeeper/conf/
打开命令:vi zoo.cfg
添加以下内容
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
server.1=192.168.89.100:2888:3888
server.2=192.168.89.101:2888:3888
server.3=192.168.89.102:2888:3888 
4.2.7在data目录下面新建一个myid文件,将刚才添加代码里面server.n的n写入myid文件里面,只写入数字。
切换路径:cd /usr/local/zookeeper/data/
创建文件:vi myid

4.2.8将配置好了的zookeeper文件分发给slave1、slave2
用scp命令进行文件传送
scp -r /usr/local/zookeeper1 root@slave:/usr/local
scp -r /usr/local/zookeeper root@slave2:/usr/local4.2.9传输完成之后在slave1和slave2上面更改myid文件,将他里面的数字改为slave1与slave2对应的IP地址(上面更改的zoo.cfg文件里面添加的服务器主机名或者IP是一 一对应的)。
slave1:

slave2:

4.3启动zookeeper服务
4.3.1 启动master主服务器上面的zookeeper,其次slave1和slave2
注:需要添加环境变量才可以直接用以下命令
master:
启动命令:zkServer.sh start
slave1 or slave2如上



4.3.2在master上面查看是否运行成功
命令:zkServer.sh status

5.在Centos7中安装Hadoop
5.1Hadoop安装
Hadoop迅雷云盘![]() https://pan.xunlei.com/s/VNYcXkNngSWn4Q3jhdJt8RSnA1?pwd=p6gp#
https://pan.xunlei.com/s/VNYcXkNngSWn4Q3jhdJt8RSnA1?pwd=p6gp#
5.1.1将hadoop-2.7.1.tar.gz上传到Centos7的/usr/local路径
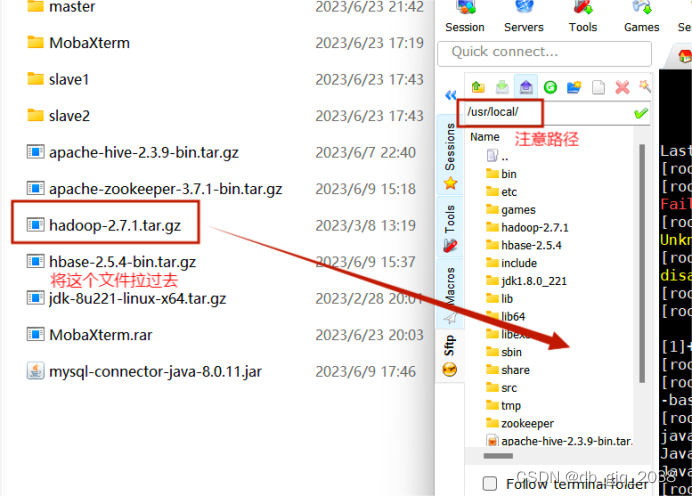
5.1.2解压hadoop-2.7.1.tar.gz到/usr/local
切换路径:cd /usr/local
解压:tar -xzvf hadoop-2.7.1.tar.gz
5.1.3 添加环境变量
vi /etc/profile
添加以下内容:
export HADOOP_HOME=/usr/local/hadoop-2.7.1
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH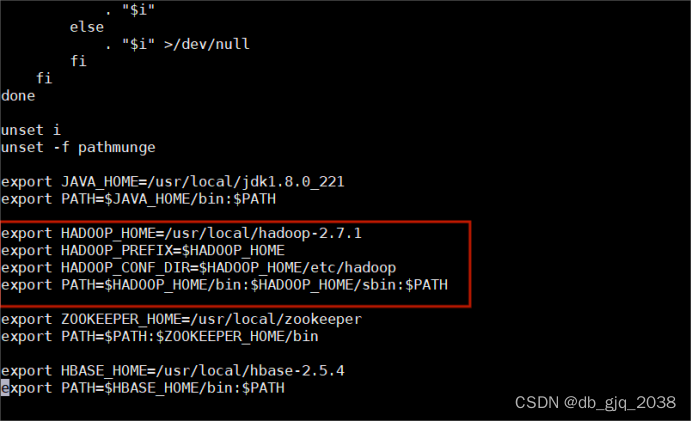
用这个命令:source /etc/profile就可以将全局变量刷新,重新可以获取全局变量的信息;
在执行命令:which hadoop
看到如下图内容则配置成功

5.1.4hadoop配置文件
切换路径:cd $HADOOP_HOME/etc/hadoop
5.1.4.1配置core-site.xml
vi core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.1/data</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>
5.1.4.2配置hdfs-site.xml
vi hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>master:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>slave1:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>slave1:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop-2.7.1/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
5.1.4.3配置yarn-site.xml
vi yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5.1.4.4配置mapred-site.xml
vi mapred-site.xml
<configuration>
<!-- 采用yarn作为mapreduce的资源调度框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.1.4.5配置slaves
vi slaves
master
slave1
slave2
5.1.4.6编辑yarn-env.sh
vi yarn-env.sh
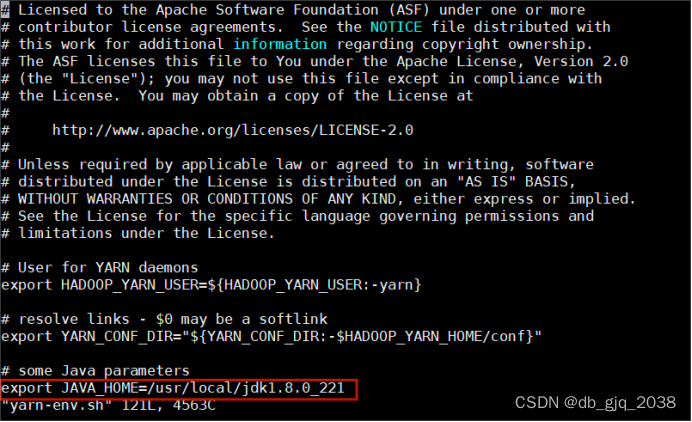
5.1.4.7将配置好了的hadoop文件分发给slave1、slave2
#在master上操作
scp -r /usr/local/hadoop-2.7.1 root@slave1:/usr/local
scp -r /usr/local/hadoop-2.7.1 root@slave2:/usr/local
scp -r /etc/profile root@slave1:/etc
scp -r /etc/profile root@slave2:/etc5.1.5启动服务
5.1.5.1启动journalnode,三台机器都要这一步操作(仅第一次启动hadoop时,需要这一步操作,之后不再需要手动启动journalnode)
hadoop-daemon.sh start journalnode5.1.5.2在hadoop-01上执行格式化操作,格式化namenode和zkfc
hdfs namenode -format
hdfs zkfc -formatZK5.1.5.3namenode主从信息同步,在hadoop-02节点上执行同步命令
start-all.sh
hdfs namenode -bootstrapStandby5.1.5.4启动集群
5.1.5.4.1启动
#master
start-all.sh
hadoop-daemon.sh start zkfc
#slave1
yarn-daemon.sh start resourcemanager
hadoop-daemon.sh start zkfc5.1.5.4.2停止
#master
stop-all.sh
hadoop-daemon.sh stop zkfc
#slave1
yarn-daemon.sh stop resourcemanager
hadoop-daemon.sh stop zkfc5.1.5.4.3查看进程
[root@master hadoop]# jps
2050 DataNode
3219 Jps
2326 JournalNode
2583 DFSZKFailoverController
2729 ResourceManager
2890 NodeManager
1579 QuorumPeerMain
1887 NameNode
[root@slave1 local]# jps
3846 NodeManager
3223 DataNode
3335 JournalNode
3132 NameNode
2989 QuorumPeerMain
4046 Jps
3567 DFSZKFailoverController
[root@slave2 ~]# jps
2737 DataNode
2849 JournalNode
2968 NodeManager
3113 Jps
2602 QuorumPeerMain
5.1.5.4.4验证
登录主节点
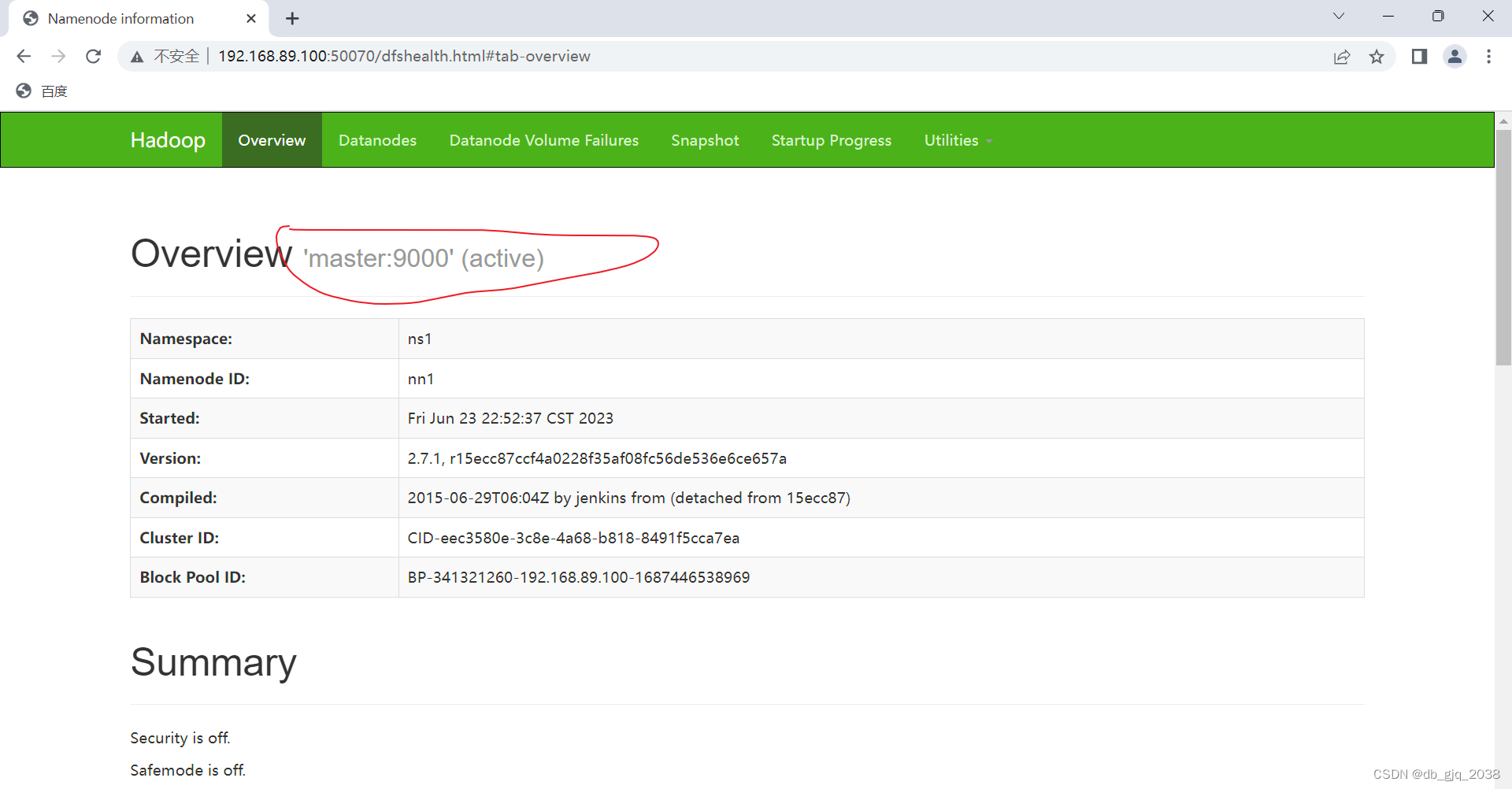
登录备用主节点
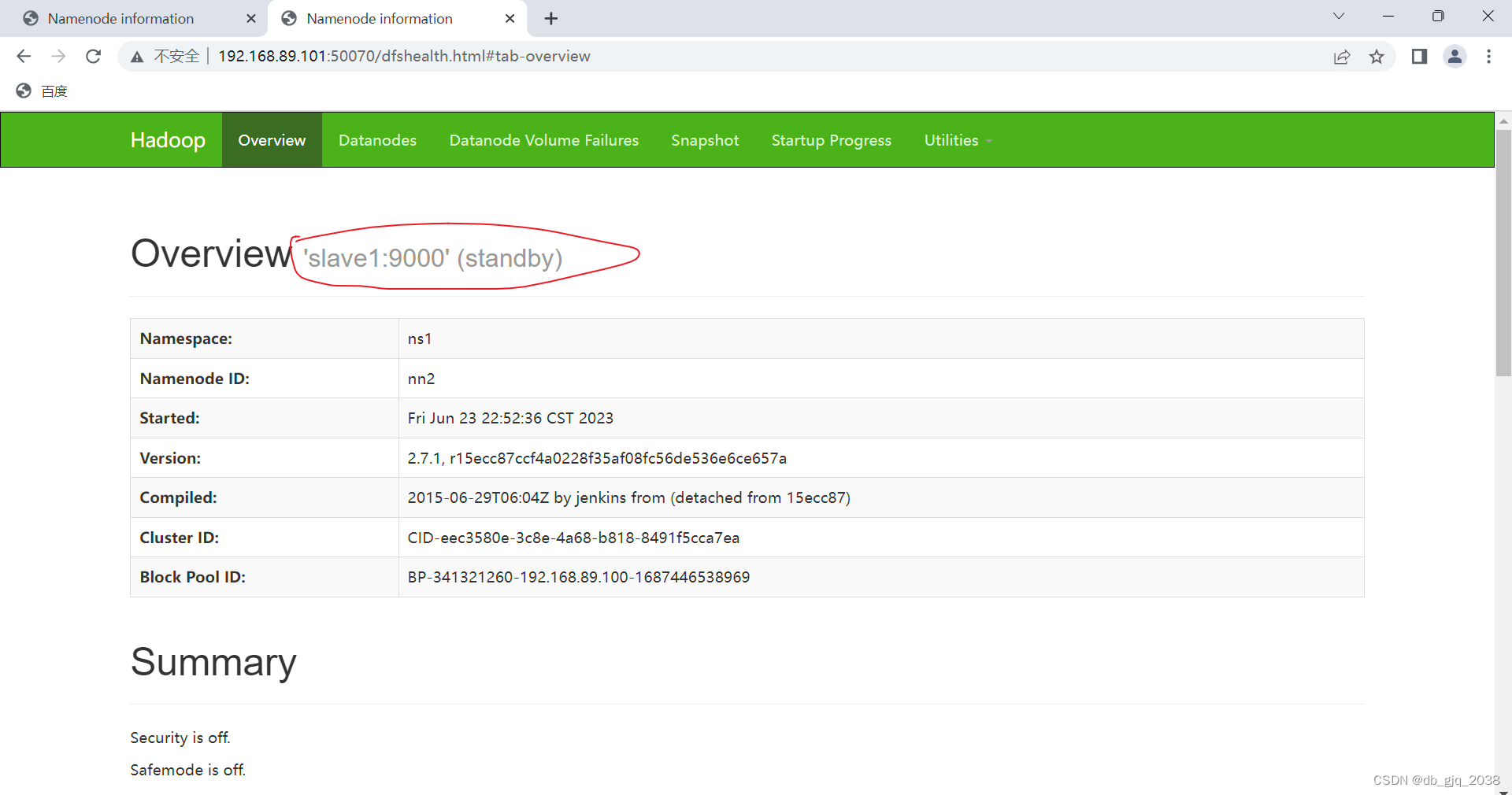
5.1.5.4.5kill 掉主节点的 namenode 进程, 检验hadoop-02是否会自动切换到namenode
[root@master hadoop]# jps
3248 Jps
2050 DataNode
2326 JournalNode
2583 DFSZKFailoverController
2729 ResourceManager
2890 NodeManager
1579 QuorumPeerMain
1887 NameNode
[root@master hadoop]# kill 1887
5.1.5.4.6再一次登录192.168.89.101:50070进行查看
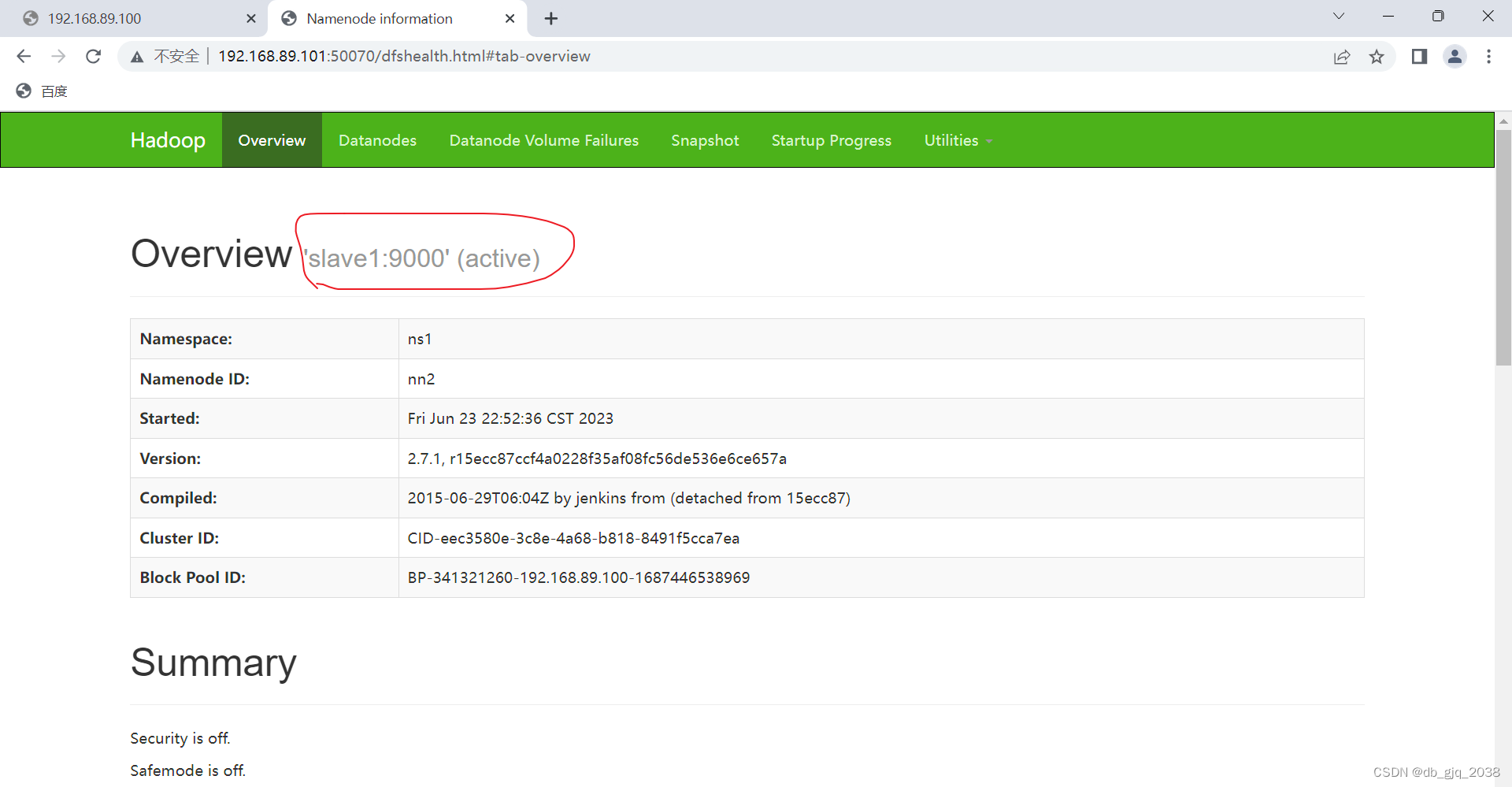
hadoop高可用集群搭建完毕
可以正常提交MapReduce运行
1.运行MapReduce提供的wordcount例子
worcount这个程序的作用:统计输入的文件中每个单词数量。
1.1编辑一个hello.txt
切换路径:cd ~
编辑:
vi hello.txt
hello hello
aa aa dd
bb aa dd
ss dd aa
hello hello
1.2将hello.txt上传
命令: hdfs dfs -put hello.txt /
查看结果
[root@master ~]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 3 root supergroup 53 2023-06-23 23:24 /hello.txt
1.3运行wordcount例子
切换路径:cd /usr/local/hadoop-2.7.1/share/hadoop/mapreduce/
运行:hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /hello.txt /wc
查看结果
[root@master mapreduce]# hdfs dfs -ls /wc
Found 2 items
-rw-r--r-- 3 root supergroup 0 2023-06-23 23:27 /wc/_SUCCESS
-rw-r--r-- 3 root supergroup 28 2023-06-23 23:27 /wc/part-r-00000查看结果
[root@master mapreduce]# hdfs dfs -cat /wc/part-r-00000
aa 4
bb 1
dd 3
hello 4
ss 1
Hbase要集群部署
1.启动hadoop、zookeeper集群
2.将HBase的安装包上传到虚拟机后安装
Hbase迅雷云盘![]() https://pan.xunlei.com/s/VNYcwOASFyjGpxaRclZkWMYrA1?pwd=2t6q#
https://pan.xunlei.com/s/VNYcwOASFyjGpxaRclZkWMYrA1?pwd=2t6q#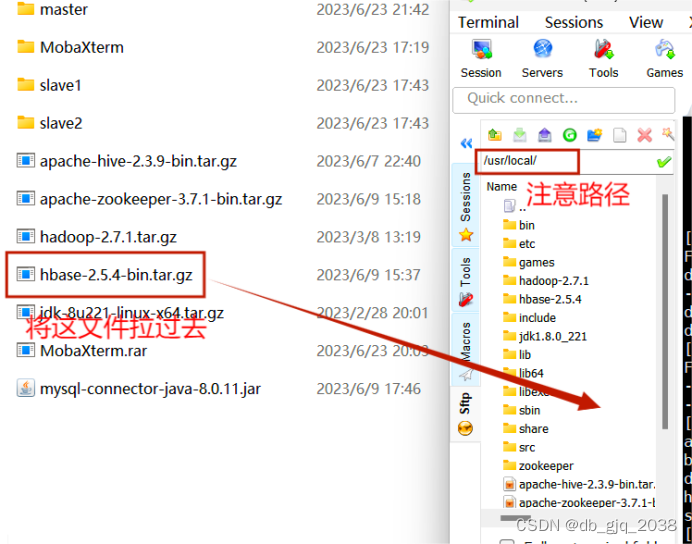
2.1解压HBase到/usr/local
切换路径:cd /usr/local
解压:tar -zxvf hbase-2.5.4-bin.tar.gz
2.2修改 HBase 的配置文件
切换路径:cd /usr/local/hbase-2.5.4/conf/
2.2.1修改hbase-env.sh
vi hbase-env.sh
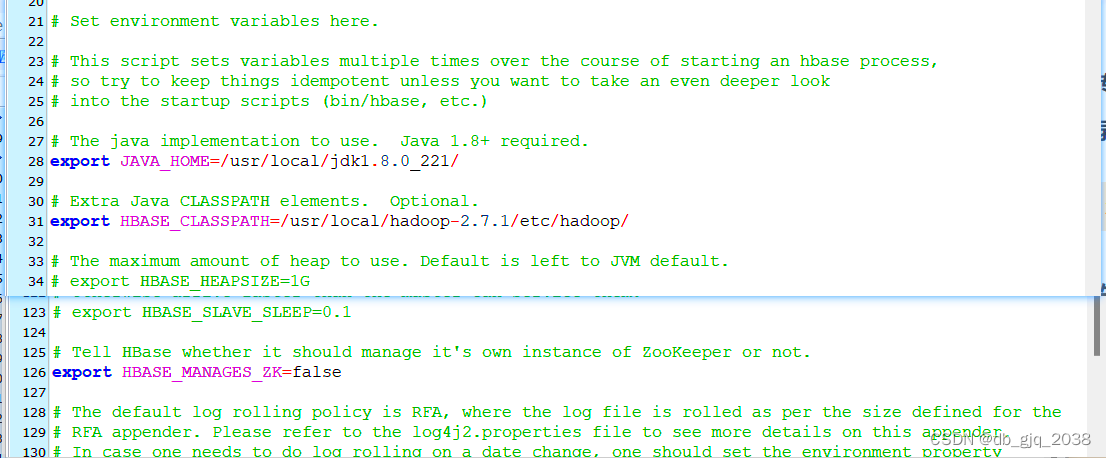
2.2.2修改hbase-site.xml
vi hbase-site.xml
添加以下内容
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper/data</value>
</property>
</configuration>2.2.3 修改regionservers
vi regionservers
master
slave1
slave2
2.2.4 软连接 hadoop 配置文件到 hbase
ln -s /usr/local/hadoop-2.7.1/etc/hadoop/core-site.xml /usr/local/hbase-2.5.4/conf/core-site.xml
ln -s /usr/local/hadoop-2.7.1/etc/hadoop/hdfs-site.xml /usr/local/hbase-2.5.4/conf/hdfs-site.xml2.2.5添加环境变量
vi /etc/profile
添加以下内容:
export HBASE_HOME=/usr/local/hbase-2.5.4
export PATH=$HBASE_HOME/bin:$PATH
用这个命令:source /etc/profile就可以将全局变量刷新,重新可以获取全局变量的信息;
2.2.6将配置好了的HBase文件分发给slave1、slave2
scp -r /usr/local/hbase-2.5.4 root@slave1:/usr/local
scp -r /usr/local/hbase-2.5.4 root@slave2:/usr/local
scp -r /etc/profile root@slave1:/etc
scp -r /etc/profile root@slave2:/etc
2.3HBase 服务
2.3.1启动
start-hbase.sh2.3.2停止
stop-hbase.sh2.4查看进程
#master
[root@master ~]# jps
2050 DataNode
7092 HMaster
3509 NameNode
2326 JournalNode
2583 DFSZKFailoverController
2729 ResourceManager
2890 NodeManager
7290 HRegionServer
1579 QuorumPeerMain
7391 Jps
#slave1
[root@slave1 local]# jps
5924 Jps
3846 NodeManager
3223 DataNode
3335 JournalNode
5704 HRegionServer
4201 NameNode
2989 QuorumPeerMain
3567 DFSZKFailoverController
#slave2
[root@slave2 ~]# jps
2737 DataNode
2849 JournalNode
2968 NodeManager
2602 QuorumPeerMain
3755 HRegionServer
3949 Jps
2.5查看 HBase 页面
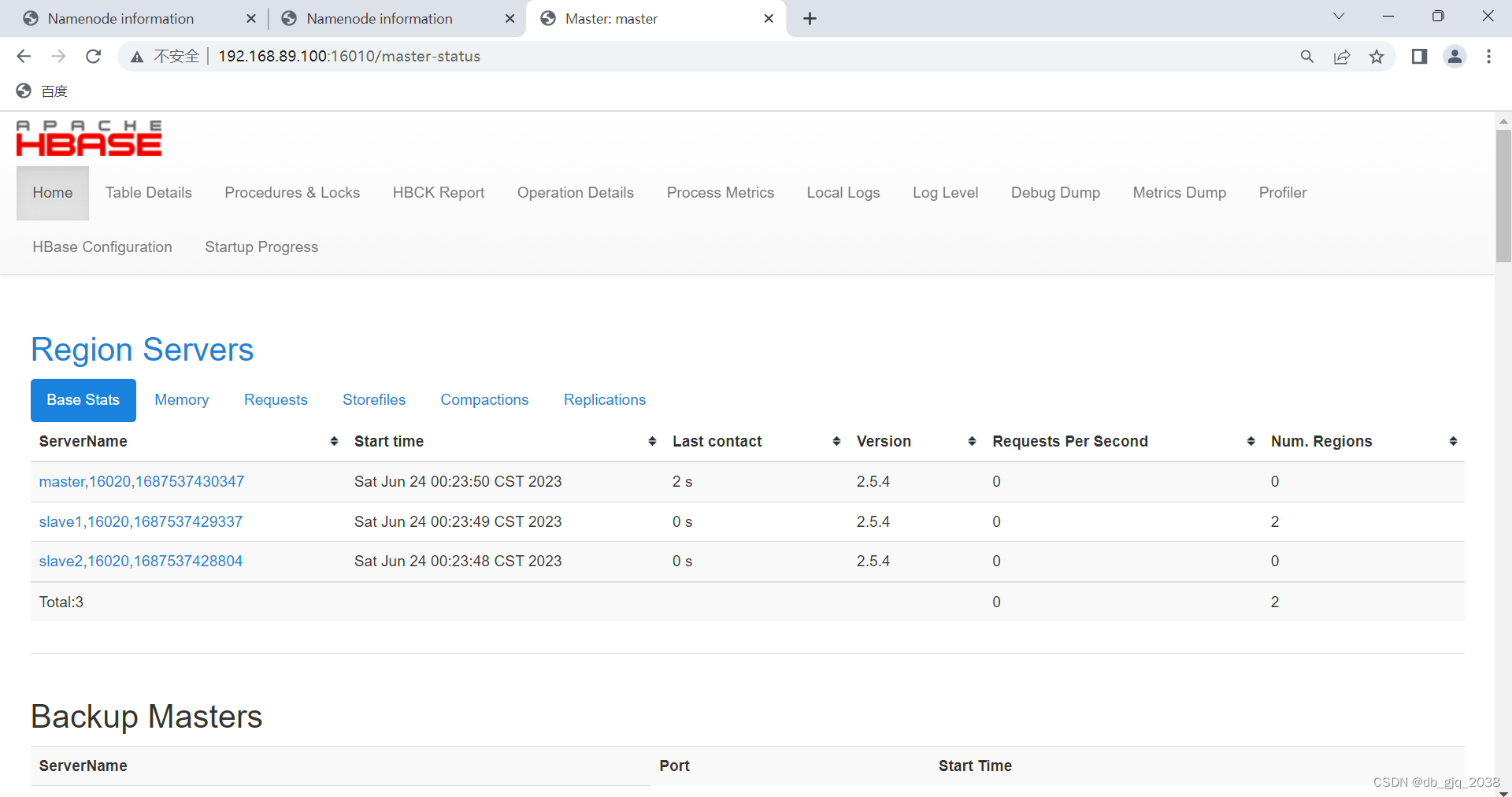
2.6HBase Shell 操作
2.6.1基本操作
2.6.1.1进入 HBase命令行
hbase shell2.6.1.2查看帮助命令
help2.6.1.3查看当前数据库有什么表
list2.6.2表的操作
2.6.2.1创建表
create 'student','info'2.6.2.2插入数据
put 'student','1001','info:sex','male'
put 'student','1001','info:age','18'
put 'student','1002','info:name','Janna'
put 'student','1002','info:sex','female'
put 'student','1002','info:age','20'2.6.2.3查看表数据
scan 'student'Hbase集群搭建完毕
部署一个Mysql数据库,要求可以远程访问
在Centos7安装MySQL5.7
1.安装mysql repo:
rpm -ivh http://repo.mysql.com/mysql57-community-release-el7-8.noarch.rpm
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
2.在线安装mysql:
yum install -y mysql-community-client mysql-community-devel mysql-community-server3.启动MySQL的mysqld进程(该进程是MySQL的服务端进程):
systemctl start mysqld4.查看MySQL服务端是否启动成功:
systemctl status mysqld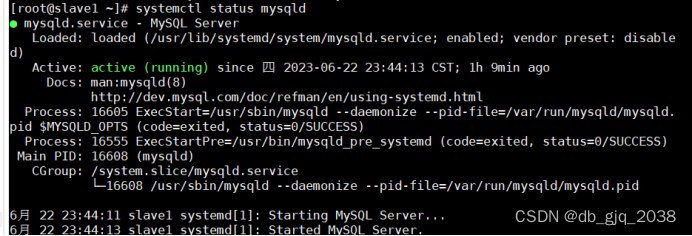
5.登录mysql
注:Mysql5.7默认安装之后root是有密码的。
5.1 获取MySQL的临时密码
cat /var/log/mysqld.log | grep "password"![]()
这里获取的临时密码是:Vjszyo_86aZ?
5.2登陆
#第一次登录后需要修改密码才可以继续使用mysql
mysql -u root -p
5.3修改密码
注:如果密码设置太简单出现以下的提示
如:ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
![]()
如何解决ERROR 1819 (HY000): Your password does not satisfy the current policy requirements呢?
提供一个方法:
修改两个全局参数:
首先,修改validate_password_policy参数的值
set glodal validate_password_policy=0;
再修改密码的长度:
set global validate_password_length=1; 
再次执行修改密码就可以了
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';6.授权其他机器登陆
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '这里输入自己设置的密码' WITH GRANT OPTION;
FLUSH PRIVILEGES;
7.远程访问mysql
使用idea访问

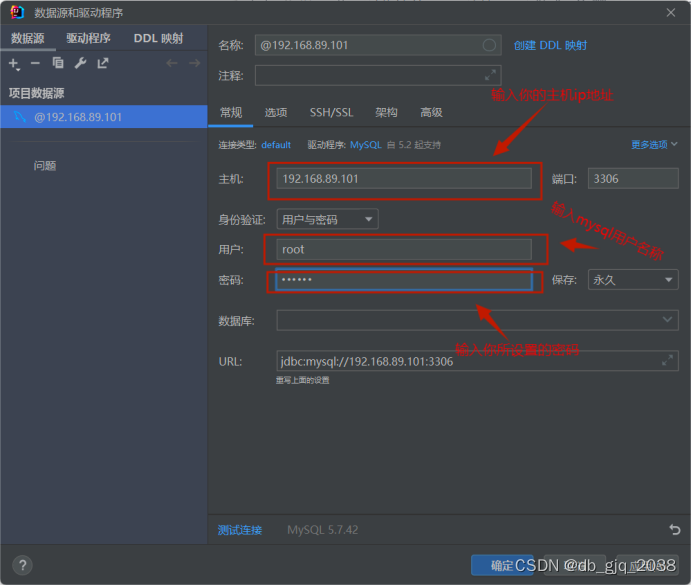
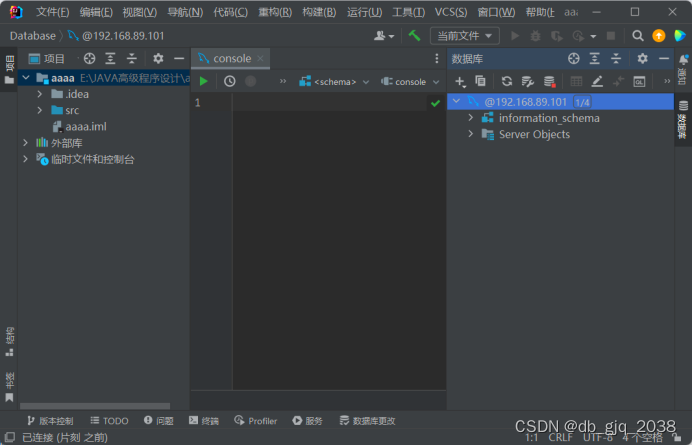
部署一个Mysql数据库,要求可以远程访问完毕
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











