









车型识别车型检测数据集
车型识别车型检测数据集,用于目标检测
2026张图片数据,已标注好,jpg与xml一一对应
该数据集分为7类,分别有小型车,中型车,大型车,小型卡车,大型卡车,油罐车,特种车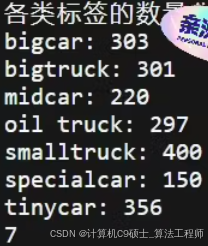
好的,下面是使用YOLOv8训练车型识别和检测数据集的详细步骤。假设你的数据集已经按照YOLO格式进行了标注,并且每个类别都有对应的XML文件。
数据集结构
假设你的数据集目录结构如下:
vehicle_detection_dataset/
├── images/
│ ├── img_00001.jpg
│ ├── img_00002.jpg
│ └── ...
└── labels/
├── img_00001.txt
├── img_00002.txt
└── ...
创建配置文件 data.yaml
首先,创建一个配置文件 data.yaml 来描述数据集:
train: ./vehicle_detection_dataset/images
val: ./vehicle_detection_dataset/images
nc: 7 # 类别数量
names: ['small_car', 'medium_car', 'large_car', 'small_truck', 'large_truck', 'tanker_truck', 'special_vehicle'] # 替换为实际的类别名称
安装必要的库
确保你已经安装了YOLOv8和其他必要的Python库:
pip install ultralytics opencv-python-headless numpy xml.etree.ElementTree
准备数据集
由于你的数据集是以XML格式标注的,我们需要将这些XML文件转换为YOLO格式的边界框标注。这里我们提供一个脚本来完成这一任务。
脚本:将XML标注转换为YOLO格式的边界框标注
更新配置文件 data.yaml
更新 data.yaml 文件以包含新的标注路径:
train: ./vehicle_detection_dataset/images
val: ./vehicle_detection_dataset/images
nc: 7 # 类别数量
names: ['small_car', 'medium_car', 'large_car', 'small_truck', 'large_truck', 'tanker_truck', 'special_vehicle'] # 类别名称
train_labels: ./vehicle_detection_dataset/labels
val_labels: ./vehicle_detection_dataset/labels
编写训练脚本
下面是一个完整的训练脚本,用于使用YOLOv8训练车型识别和检测数据集:
运行训练脚本
将上述代码保存为一个Python文件(例如 train_vehicle_detection.py),然后在终端中运行:
python train_vehicle_detection.py
解释
- 加载预训练模型: 使用
YOLO('yolov8n.pt')加载YOLOv8的小型预训练模型。你可以根据需要选择其他大小的模型(如yolov8s,yolov8m,yolov8l,yolov8x)。 - 开始训练: 使用
model.train()方法启动训练过程。参数包括数据集路径、训练轮数、批量大小、图像大小等。 - 验证模型: 使用
model.val()方法评估模型在验证集上的表现。 - 测试模型: 使用
model.predict()方法对测试集进行预测,并打印预测结果。
可视化预测结果
使用 model.predict()
YOLOv8 提供了 model.predict() 方法来对图像进行预测,并返回预测结果。我们可以使用 OpenCV 或其他库来可视化这些预测结果。
以下是一个完整的脚本,用于加载训练好的模型并对测试集中的图像进行预测和可视化:
解释
- 加载训练好的模型: 使用
YOLO('runs/detect/vehicle_detection/exp/weights/best.pt')加载训练好的模型。 - 遍历测试集中的所有图像: 使用
Path('./vehicle_detection_dataset/images').glob('*.jpg')获取所有测试图像路径。 - 进行预测: 使用
model.predict()方法对每张图像进行预测,并设置置信度阈值。 - 获取预测结果: 从预测结果中提取边界框、置信度和类别ID。
- 读取图像: 使用
cv2.imread()读取图像。 - 绘制边界框: 使用
cv2.rectangle()和cv2.putText()在图像上绘制边界框和标签。 - 保存结果图像: 将处理后的图像保存到指定的输出目录。
运行脚本
将上述代码保存为一个Python文件(例如 evaluate_and_visualize_vehicle_detection.py),然后在终端中运行:
python evaluate_and_visualize_vehicle_detection.py
结果
运行脚本后,你会在 ./vehicle_detection_dataset/output 目录中看到带有预测结果的图像。这些图像会在检测到的车辆上绘制绿色的边界框和标签。
通过这些步骤,你可以全面地评估和可视化你的车型识别和检测模型的表现。如果需要进一步优化模型,可以根据评估结果调整超参数或增加数据增强技术。


















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









