






如何_
实现深度学习目标检测 种如何实现基于Yolov8+PaddleOcr(LPRNet)车牌识别系统 来识别图片/视频/摄像头的检测 :并可iou,conf
Yolov8+PaddleOcr(LPRNet)车牌识别系统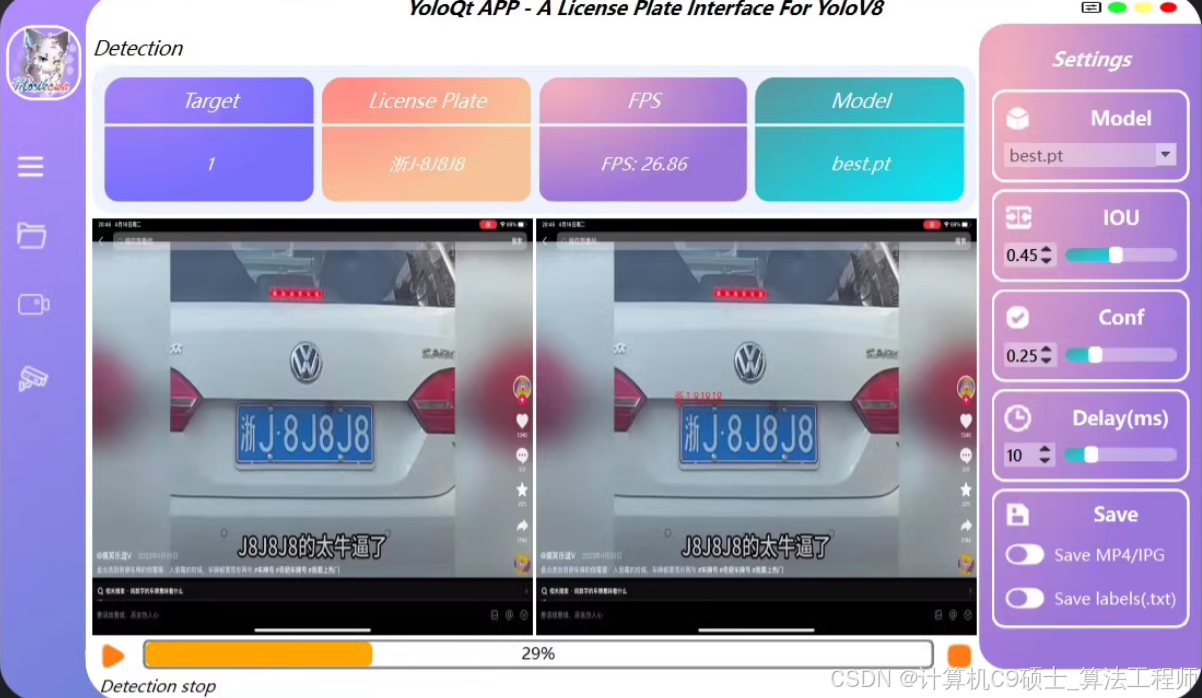
构建:项目文件:
①项目源码
②yolov8相关代码
③训练好的车牌检测模型(Yolov8),四个基于paddleocr训练好的文本识别模型,一个官方训练好的LPRNet模型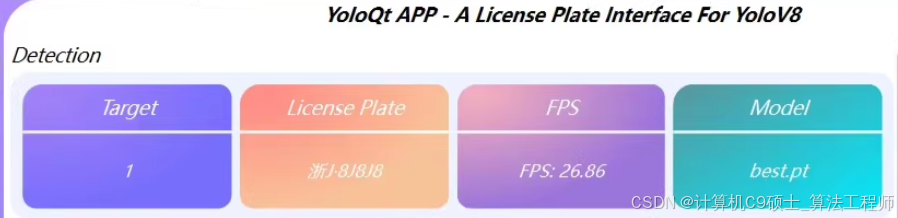
具体实现目标:_系统功能:
1.车牌识别(图像、视频、摄像头检测)
2。显示检测速度以及画面所有识别车牌号
可调节iou,conf
系统界面支持保存检测图像以及检测视频
所用技术:
Yolov8进行车牌检测定位,通过PaddleOcr进行车牌号识别,PyQt6写界面,本项目提供两类模型,yolov8,一个是PaddleOcr,一个是LPRNet。paddleocr的文本识别模型精度高,速度略慢于LPRNet,LPRNet精度低于paddleocr。
想要实现功能:————_说明:
1、运行本项目需要配置好pytorch环境,以及安装opencv,timm,pautil,PyQt6等少量依赖
2、PyQt6源码pytorch安装环境即可运行
3、检测识别蓝牌和绿牌
以下文字及代码仅供参考。
构建一个完整的YOLOv8 + PaddleOCR(LPRNet)车牌识别系统,我们将详细描述每个组件的实现,并提供详细的代码示例。包括车牌检测、车牌号识别、用户界面设计以及保存检测结果的功能。
项目结构
LicensePlateRecognition/
├── src/
│ ├── main.py # 主程序入口
│ ├── yolov8_detector.py # YOLOv8车牌检测模块
│ ├── paddle_ocr_recognizer.py # PaddleOCR文本识别模块
│ ├── lprnet_recognizer.py # LPRNet文本识别模块
│ ├── gui.py # PyQt6图形用户界面
│ └── utils.py # 辅助函数(如图像处理等)
├── models/
│ ├── yolov8_best.pt # 训练好的YOLOv8模型权重文件
│ ├── paddleocr_model1/ # 基于PaddleOCR训练的第一个模型
│ ├── paddleocr_model2/ # 第二个模型...
│ ├── paddleocr_model3/ # ...
│ ├── paddleocr_model4/ # ...
│ └── lprnet.pth # 官方训练好的LPRNet模型
├── requirements.txt # 项目依赖包列表
└── README.md # 项目说明文档
依赖安装
确保安装了所有必要的依赖库:
pip install -r requirements.txt
requirements.txt内容示例:
torch>=1.9.0
opencv-python
timm
paddleocr
PyQt6
numpy
代码实现
1. YOLOv8 车牌检测模块 (yolov8_detector.py)
from ultralytics import YOLO
import cv2
class YOLOv8Detector:
def __init__(self, model_path='models/yolov8_best.pt', conf_thres=0.5, iou_thres=0.45):
self.model = YOLO(model_path)
self.conf_thres = conf_thres
self.iou_thres = iou_thres
def detect(self, image):
results = self.model(image, conf=self.conf_thres, iou=self.iou_thres)
return results[0].boxes.cpu().numpy()
def draw_boxes(self, image, boxes, labels=None):
for box in boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0])
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
if labels:
label = labels[int(box.cls)]
cv2.putText(image, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return image
2. PaddleOCR 文本识别模块 (paddle_ocr_recognizer.py)
from paddleocr import PaddleOCR
class PaddleOCRRecognizer:
def __init__(self, use_gpu=True):
self.ocr = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=use_gpu)
def recognize(self, image):
result = self.ocr.ocr(image, cls=True)
texts = [line[-1][0] for line in result]
return texts
3. LPRNet 文本识别模块 (lprnet_recognizer.py)
import torch
from lprnet import build_lprnet # 假设有一个名为lprnet的库来加载LPRNet模型
class LPRNetRecognizer:
def __init__(self, model_path='models/lprnet.pth'):
self.lprnet = build_lprnet(num_classes=74, dropout_rate=0).eval()
self.lprnet.load_state_dict(torch.load(model_path))
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.lprnet.to(self.device)
def recognize(self, image):
input_tensor = preprocess_image(image) # 需要定义preprocess_image函数
with torch.no_grad():
output = self.lprnet(input_tensor.to(self.device))
prediction = postprocess_output(output) # 需要定义postprocess_output函数
return prediction
4. PyQt6 图形用户界面 (gui.py)
import sys
from PyQt6.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget, QFileDialog, QSlider, QLineEdit
from PyQt6.QtGui import QImage, QPixmap
from PyQt6.QtCore import Qt
import cv2
import numpy as np
from yolov8_detector import YOLOv8Detector
from paddle_ocr_recognizer import PaddleOCRRecognizer
from lprnet_recognizer import LPRNetRecognizer
from utils import save_image, save_video
class LicensePlateApp(QMainWindow):
def __init__(self):
super().__init__()
self.initUI()
self.detector = YOLOv8Detector()
self.recognizer_paddle = PaddleOCRRecognizer()
self.recognizer_lprnet = LPRNetRecognizer()
def initUI(self):
self.setWindowTitle('车牌识别系统')
self.setGeometry(100, 100, 800, 600)
layout = QVBoxLayout()
self.image_label = QLabel(self)
layout.addWidget(self.image_label)
self.detect_button = QPushButton('开始检测', self)
self.detect_button.clicked.connect(self.start_detection)
layout.addWidget(self.detect_button)
self.save_button = QPushButton('保存结果', self)
self.save_button.clicked.connect(self.save_result)
layout.addWidget(self.save_button)
self.conf_slider = QSlider(Qt.Orientation.Horizontal, self)
self.conf_slider.setMinimum(1)
self.conf_slider.setMaximum(100)
self.conf_slider.setValue(50)
self.conf_slider.setTickPosition(QSlider.TickPosition.TicksBelow)
self.conf_slider.setTickInterval(10)
self.conf_slider.valueChanged.connect(self.update_conf_threshold)
layout.addWidget(self.conf_slider)
self.conf_label = QLineEdit("0.5", self)
self.conf_label.textChanged.connect(self.update_conf_threshold)
layout.addWidget(self.conf_label)
self.iou_slider = QSlider(Qt.Orientation.Horizontal, self)
self.iou_slider.setMinimum(1)
self.iou_slider.setMaximum(100)
self.iou_slider.setValue(45)
self.iou_slider.setTickPosition(QSlider.TickPosition.TicksBelow)
self.iou_slider.setTickInterval(10)
self.iou_slider.valueChanged.connect(self.update_iou_threshold)
layout.addWidget(self.iou_slider)
self.iou_label = QLineEdit("0.45", self)
self.iou_label.textChanged.connect(self.update_iou_threshold)
layout.addWidget(self.iou_label)
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
self.current_image = None
self.detections = []
def update_conf_threshold(self):
value = self.conf_slider.value() / 100
self.conf_label.setText(f"{value:.2f}")
self.detector.conf_thres = value
def update_iou_threshold(self):
value = self.iou_slider.value() / 100
self.iou_label.setText(f"{value:.2f}")
self.detector.iou_thres = value
def start_detection(self):
file_name, _ = QFileDialog.getOpenFileName(self, "选择图片或视频", "", "Images (*.png *.xpm *.jpg *.bmp *.gif);;Videos (*.mp4 *.avi)")
if file_name:
if file_name.lower().endswith(('mp4', 'avi')):
self.process_video(file_name)
else:
self.process_image(file_name)
def process_image(self, file_name):
image = cv2.imread(file_name)
self.current_image = image.copy()
detections = self.detector.detect(image)
self.detections = detections
for detection in detections:
x1, y1, x2, y2 = map(int, detection.xyxy[0])
cropped_plate = image[y1:y2, x1:x2]
text_paddle = self.recognizer_paddle.recognize(cropped_plate)
text_lprnet = self.recognizer_lprnet.recognize(cropped_plate)
print(f"PaddleOCR: {text_paddle}")
print(f"LPRNet: {text_lprnet}")
image = self.detector.draw_boxes(image, [detection], ['License Plate'])
self.display_image(image)
def process_video(self, file_name):
cap = cv2.VideoCapture(file_name)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (int(cap.get(3)), int(cap.get(4))))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
detections = self.detector.detect(frame)
for detection in detections:
x1, y1, x2, y2 = map(int, detection.xyxy[0])
cropped_plate = frame[y1:y2, x1:x2]
text_paddle = self.recognizer_paddle.recognize(cropped_plate)
text_lprnet = self.recognizer_lprnet.recognize(cropped_plate)
print(f"PaddleOCR: {text_paddle}")
print(f"LPRNet: {text_lprnet}")
frame = self.detector.draw_boxes(frame, [detection], ['License Plate'])
out.write(frame)
cap.release()
out.release()
def display_image(self, image):
qimg = QImage(image.data, image.shape[1], image.shape[0], QImage.Format_BGR888)
pixmap = QPixmap.fromImage(qimg)
self.image_label.setPixmap(pixmap)
def save_result(self):
if self.current_image is not None:
file_name, _ = QFileDialog.getSaveFileName(self, "保存图片", "", "Images (*.png *.xpm *.jpg *.bmp *.gif)")
if file_name:
save_image(self.current_image, file_name)
# 如果是视频,则使用save_video函数保存
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = LicensePlateApp()
ex.show()
sys.exit(app.exec())
5. 辅助函数 (utils.py)
import cv2
def save_image(image, file_name):
cv2.imwrite(file_name, image)
def save_video(video_writer, frames):
for frame in frames:
video_writer.write(frame)
运行说明
- 环境配置:根据
requirements.txt安装依赖库,并确保已经正确安装了PyTorch环境。 - 启动应用:通过命令行运行主程序
main.py来启动GUI应用程序。 - 功能操作:
- 点击“开始检测”按钮,选择要检测的图片或视频。
- 程序会自动使用YOLOv8检测车牌位置,并用PaddleOCR或LPRNet识别车牌号码。
- 结果会在控制台打印出来,同时可以在界面上看到检测到的车牌区域。
- 使用滑动条调整IOU和置信度阈值。
- 点击“保存结果”按钮保存检测后的图像或视频。
注意事项
- 模型优化:考虑到PaddleOCR的速度较慢,你可以考虑在实际部署时仅用于高精度需求场景;而对于实时性要求较高的场合,优先使用LPRNet。
- 性能调整:允许用户调节IOU阈值和置信度阈值,以适应不同场景下的检测精度需求。
- 保存功能:在
process_image方法中添加逻辑,支持保存检测后的图像及视频。 - 多线程处理:对于视频流或摄像头实时检测,可能需要引入多线程或多进程技术来提高效率。
- 蓝牌和绿牌检测:确保YOLOv8模型已经被训练为能够区分蓝牌和绿牌。
详细描述从数据预处理到环境部署、数据集准备、模型定义、训练、评估以及结果分析与可视化等各个步骤。以下是详细的指南和代码示例。
1. 数据预处理
数据集准备
确保你的数据集按照YOLO格式组织,并包含以下内容:
- 图像文件夹 (
images/) - 标签文件夹 (
labels/) - 数据集配置文件 (
dataset.yaml)
每个图像对应一个同名的.txt文件作为标注文件,其中包含物体的位置信息(边界框坐标)和类别ID。
# dataset.yaml
train: ./dataset/images/train
val: ./dataset/images/valid
nc: 2 # Number of classes (blue, green)
names: ['blue_plate', 'green_plate']
图像预处理
编写脚本对图像进行预处理,如调整大小、归一化等。
import cv2
import os
def preprocess_image(image_path, output_size=(640, 640)):
image = cv2.imread(image_path)
resized_image = cv2.resize(image, output_size)
normalized_image = resized_image / 255.0
return normalized_image
def preprocess_dataset(input_dir, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for filename in os.listdir(input_dir):
if filename.endswith(('.png', '.jpg', '.jpeg')):
input_path = os.path.join(input_dir, filename)
output_path = os.path.join(output_dir, filename)
preprocessed_image = preprocess_image(input_path)
cv2.imwrite(output_path, preprocessed_image * 255) # Save as uint8
# 示例调用
preprocess_dataset('path/to/raw_images', 'path/to/preprocessed_images')
2. 环境部署
确保安装了所有必要的依赖库:
pip install -r requirements.txt
requirements.txt内容示例:
torch>=1.9.0
opencv-python
timm
paddleocr
PyQt6
numpy
3. 数据集准备
将数据集划分为训练集和验证集,并为每个集合创建相应的标签文件。
import random
import shutil
import os
def split_dataset(src_dir, dst_train_dir, dst_val_dir, val_ratio=0.2):
images = [f for f in os.listdir(os.path.join(src_dir, 'images')) if f.endswith(('png', 'jpg', 'jpeg'))]
labels = [f for f in os.listdir(os.path.join(src_dir, 'labels')) if f.endswith('txt')]
random.shuffle(images)
split_idx = int(len(images) * (1 - val_ratio))
for i, img in enumerate(images):
label = img.replace('.jpg', '.txt').replace('.png', '.txt')
if i < split_idx:
shutil.copy(os.path.join(src_dir, 'images', img), os.path.join(dst_train_dir, 'images', img))
shutil.copy(os.path.join(src_dir, 'labels', label), os.path.join(dst_train_dir, 'labels', label))
else:
shutil.copy(os.path.join(src_dir, 'images', img), os.path.join(dst_val_dir, 'images', img))
shutil.copy(os.path.join(src_dir, 'labels', label), os.path.join(dst_val_dir, 'labels', label))
# 示例调用
split_dataset('path/to/dataset', 'path/to/train', 'path/to/val')
4. 模型定义
YOLOv8 模型定义 (yolov8_detector.py)
from ultralytics import YOLO
class YOLOv8Detector:
def __init__(self, model_path='models/yolov8_best.pt', conf_thres=0.5, iou_thres=0.45):
self.model = YOLO(model_path)
self.conf_thres = conf_thres
self.iou_thres = iou_thres
def detect(self, image):
results = self.model(image, conf=self.conf_thres, iou=self.iou_thres)
return results[0].boxes.cpu().numpy()
def draw_boxes(self, image, boxes, labels=None):
for box in boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0])
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
if labels:
label = labels[int(box.cls)]
cv2.putText(image, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return image
PaddleOCR 和 LPRNet 文本识别模块 (paddle_ocr_recognizer.py, lprnet_recognizer.py)
参见之前的代码实现。
5. 训练模型
编写训练脚本来启动训练过程。
from yolov8_detector import YOLOv8Detector
def train_model():
detector = YOLOv8Detector(model_path='models/yolov8n.yaml') # 使用预定义配置或自定义模型
results = detector.model.train(data='dataset.yaml', epochs=100, imgsz=640)
if __name__ == '__main__':
train_model()
6. 评估模型
编写评估脚本来测试模型性能,并计算mAP等指标。
from yolov8_detector import YOLOv8Detector
def evaluate_model():
detector = YOLOv8Detector(model_path='runs/detect/train/weights/best.pt') # 加载最佳模型权重
results = detector.model.val(data='dataset.yaml')
print(results)
if __name__ == '__main__':
evaluate_model()
7. 结果分析与可视化
编写脚本以分析和可视化检测结果。
import matplotlib.pyplot as plt
import numpy as np
import cv2
def plot_detection_results(image_paths, detection_results):
fig, axes = plt.subplots(len(image_paths), 1, figsize=(10, len(image_paths) * 5))
if len(image_paths) == 1:
axes = [axes]
for ax, image_path, result in zip(axes, image_paths, detection_results):
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
for det in result:
x1, y1, x2, y2 = map(int, det.xyxy[0])
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
ax.imshow(image)
ax.axis('off')
plt.tight_layout()
plt.show()
# 示例调用
image_paths = ['path/to/image1.jpg', 'path/to/image2.jpg']
detection_results = [detector.detect(cv2.imread(path)) for path in image_paths]
plot_detection_results(image_paths, detection_results)
8. 集成与部署
使用PyQt6构建图形用户界面,并集成上述功能模块。
PyQt6 图形用户界面 (gui.py)
参见之前的代码实现。
9. 注意事项
- 蓝牌和绿牌检测:确保YOLOv8模型已经被训练为能够区分蓝牌和绿牌。
- 模型优化:考虑到PaddleOCR的速度较慢,可以在实际部署时仅用于高精度需求场景;而对于实时性要求较高的场合,优先使用LPRNet。
- 性能调整:允许用户调节IOU阈值和置信度阈值,以适应不同场景下的检测精度需求。
- 保存功能:在
process_image方法中添加逻辑,支持保存检测后的图像及视频。 - 多线程处理:对于视频流或摄像头实时检测,可能需要引入多线程或多进程技术来提高效率。
,你可以构建一个完整的YOLOv8 + PaddleOCR(LPRNet)车牌识别系统



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









