






采取一个系统化方法来分析和处理数据_(充电桩local信息、时间、车辆状态、SOC、电流、电压等信息)之城市电动汽车充电桩数据集 数据预处理、特征工程、探索性数据分析
文章目录
城市电动汽车充电桩数据集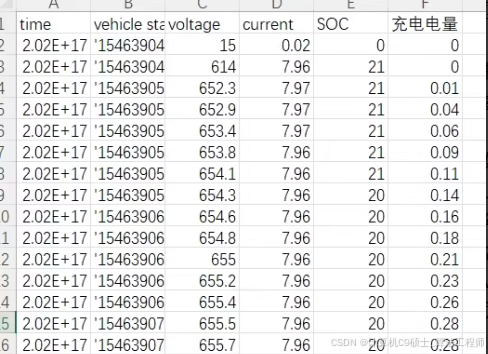
包括来自中国【北上深】9个充电站共27个充电桩的充电数据。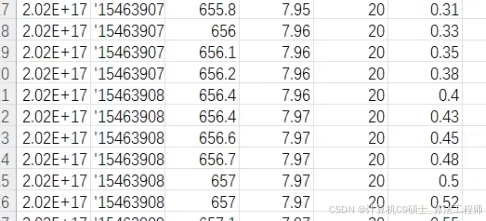
原始文件包括充电桩地理信息、时间、车辆状态、SOC、电流、电压等信息。数据点的采样时间约为18秒,数据跨度为一年半。
包含的两个文件夹中original_data文件夹包含的是原始数据csv和充电桩信息xlsx,其中原始数据csv有6个数据字段,分别为:
1.time,表示时间
2. vehicle state:车辆状态
3.voltage:充电电压,单位为V
4.current:充电电流,单位为A
5.SOC:充电车辆SOC,单位为%
6.充电电量:车辆充电电量,单位为度
充电桩信息xlsx包含27个充电桩及其地理固有属性字段,分别为桩功率(单位为kW)、桩ID、桩群地址、区域编码、纬度、经度、省、市和区。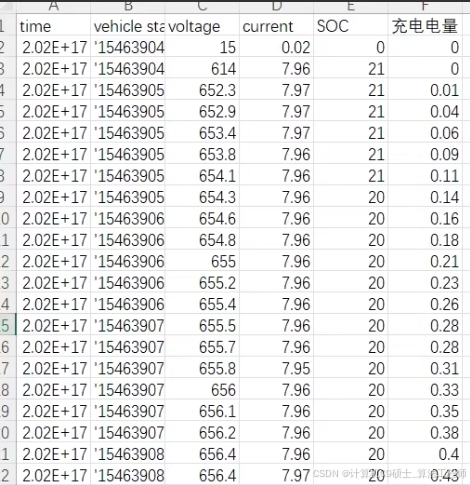
processed data文件夹包含的是处理后的数据,分别生成了18s和1h两份不同分辨率的数据。以18s resolution的数据为例,/18s resolution含有的表名为"fixed2_18seconds_10069936.csv”,表示桩ID为10069936的18s分辨率的处理后数据,csv包含时间和桩充电功率2个数据字段。
以下文字及代码仅供参考。
为了有效利用中国城市电动汽车充电桩数据集,我们可以采取一个系统化的方法来分析和处理这些数据。这个过程将包括数据预处理、特征工程、探索性数据分析(EDA)、模型构建与训练、以及最终的部署和应用。以下是详细的步骤指南:
1. 数据理解与准备
加载原始数据
首先,我们需要加载original_data文件夹中的CSV文件和XLSX文件。由于每个CSV文件可能对应不同的充电桩或时间段,我们应当设计一种方法来整合所有数据。
import pandas as pd
import os
# 加载原始数据
data_dir = 'path/to/original_data'
# 加载充电桩信息
charger_info = pd.read_excel(os.path.join(data_dir, '充电桩信息.xlsx'))
# 加载所有充电记录数据
def load_charging_data(data_dir):
charging_data = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
df = pd.read_csv(os.path.join(root, file))
df['file_name'] = file # 保留文件名用于后续匹配桩ID
charging_data.append(df)
return pd.concat(charging_data, ignore_index=True)
charging_records = load_charging_data(data_dir)
合并数据
接下来,我们将充电记录与充电桩信息合并,以便能够访问每个充电事件对应的地理位置和其他属性。
# 确保桩ID字段一致
charger_info.rename(columns={'桩ID': '桩ID'}, inplace=True)
# 假设充电记录中的桩ID可以通过文件名获取
charging_records['桩ID'] = charging_records['file_name'].str.extract(r'(\d+)')
charging_records['桩ID'] = charging_records['桩ID'].astype(int)
# 合并数据
merged_data = pd.merge(charging_records, charger_info, on='桩ID', how='left')
2. 数据清理与特征工程
数据清洗
- 缺失值处理:检查是否有缺失值,并决定是删除还是填补。
- 异常值检测:识别并处理异常值,如极高的电流或电压读数。
特征构造
- 时间特性:从时间戳中提取小时、日、周、月等特征。
- 充电模式:根据车辆状态构造充电模式特征,例如是否正在充电。
- 累积充电量:计算每个会话期间累积的充电电量。
- 充电速率:基于电压和电流计算充电速率。
# 提取时间特性
merged_data['datetime'] = pd.to_datetime(merged_data['time'])
merged_data['hour'] = merged_data['datetime'].dt.hour
merged_data['day_of_week'] = merged_data['datetime'].dt.dayofweek
merged_data['month'] = merged_data['datetime'].dt.month
# 构造充电模式特征
merged_data['is_charging'] = (merged_data['vehicle state'] == '充电').astype(int)
# 计算充电速率
merged_data['charge_rate'] = merged_data['voltage'] * merged_data['current']
# 累积充电量(需要考虑每个充电会话)
# 这里假设每次充电之间有明显的间隔,可以基于桩ID和时间戳分组
3. 探索性数据分析(EDA)
使用可视化工具(如Matplotlib、Seaborn)对数据进行探索性分析,以了解数据分布、趋势和潜在模式。
import matplotlib.pyplot as plt
import seaborn as sns
# 可视化充电功率随时间的变化
plt.figure(figsize=(14,7))
sns.lineplot(x='datetime', y='charge_rate', hue='桩ID', data=merged_data.sample(n=1000))
plt.title('Charging Rate Over Time by Charger ID')
plt.show()
4. 模型构建与训练
根据研究目的选择合适的模型类型。如果目的是预测充电需求或优化充电站布局,可以考虑回归模型或聚类分析。如果是为了检测异常充电行为,则可以选择分类模型或异常检测算法。
示例:充电需求预测(使用随机森林回归)
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# 准备训练数据
features = ['hour', 'day_of_week', 'month', '桩功率', '纬度', '经度']
target = 'charge_rate'
X = merged_data[features]
y = merged_data[target]
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 预测并评估模型
predictions = rf_model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')
5. 模型评估与优化
评估模型性能,尝试调整超参数或引入更多特征来提高模型的表现。
6. 部署与应用
一旦模型训练完成并且达到了满意的性能水平,就可以将其部署到实际的应用环境中,例如通过API接口接收实时充电数据并返回预测结果,或者集成到现有的管理系统中。
注意事项
- 隐私保护:确保在处理过程中遵守相关的隐私法规,特别是涉及到用户车辆信息时。
- 持续改进:随着新数据的积累,模型可能需要不断更新和优化。
- 解释性:为了提高模型的信任度,可以使用SHAP值或其他解释性工具来解释模型决策过程。
以上是一个针对城市电动汽车充电桩数据集的完整解决方案框架。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









