









声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
今天对我们之前推出的区间预测全家桶进行更新,将最新推出的QRCNN-BiGRU-MultiAttention模型加入到我们的全家桶当中,非常新颖!
如果你之前购买过区间预测全家桶,此次推出的模型免费下载即可!
同样,本期代码大家使用的时候只需要一键运行main即可出来所有图片与区间预测结果!非常方便!适合新手小白!如果你想替换成自己的其他数据集,也非常方便!只需替换Excel文件即可,无需更改代码!
我们提出的这个模型在知网和WOS平台依旧都是搜不到的!不信可以看下图!
结果展示
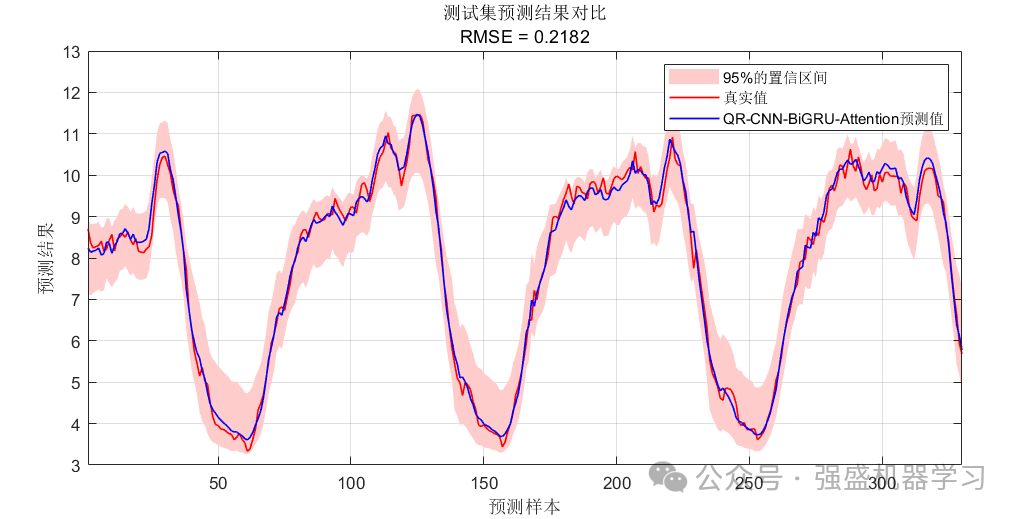
这里采用了95%的置信区间,如果大家需要其他的置信区间,也可以自行更改,只需在代码的创建网络处修改即可,非常简单!
区间预测的测试集预测结果:
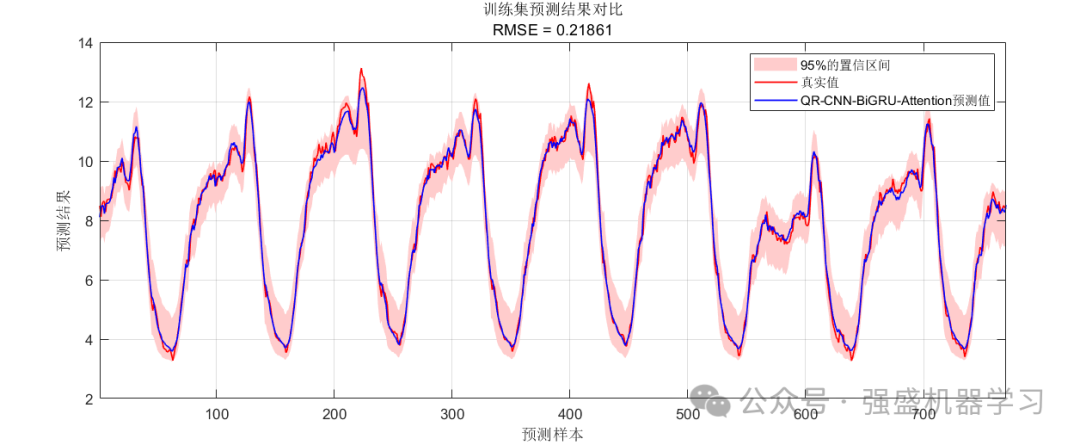
区间预测的训练集预测结果:
网络结构图:
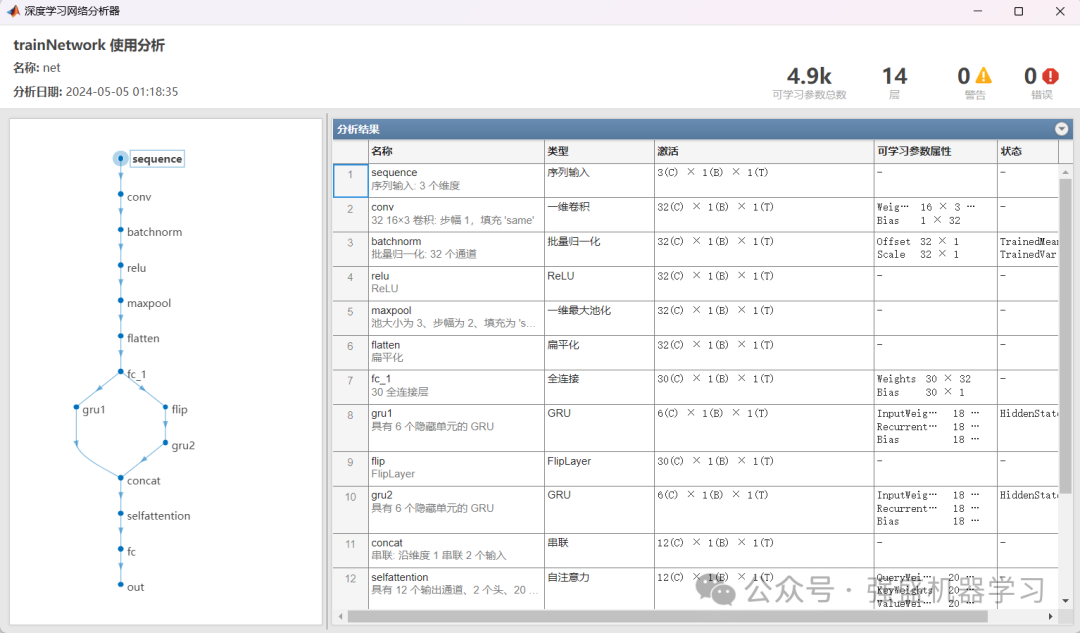
点预测的误差直方图:
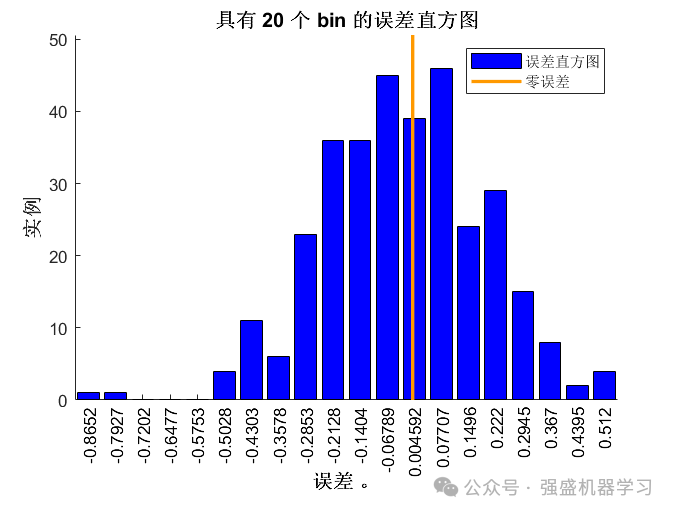
点预测的线性拟合图:
我们也很贴心地给出了很多评价指标,点预测包括4种评价指标,包括R2、MAE、MSE、MAPE,区间预测包括2种评价指标,区间覆盖率PICP、区间平均宽度百分比PIMWP,如果后续有需要增加评价指标的小伙伴可以私聊~

可以看到,我们的QRCNN-BiGRU-MultiAttention模型预测精度非常高,在95%置信水平下的PICP甚至达到了99.4%,R2也达到了0.99以上,与真实值基本吻合,这是很多论文都无法达到的效果,非常适合用来作为创新点!
如果你再做一些模型对比,证明你的模型优越性,那论文不就蹭蹭发了吗?
当然,如果你觉得效果不好,想要效果更好,在时间充足的情况下,可以增大设置中的最大迭代次数,比如500次,1000次,可根据个人需求调整!
数据介绍
本期数据使用的依旧是多变量回归数据集,是某地一个风电功率的数据集,经过处理后有3个特征,分别用特征1、2、3来表示,具体特征含义大家不必深究,这边只是给大家提供一个示例而已,大家替换成自己的数据集即可~
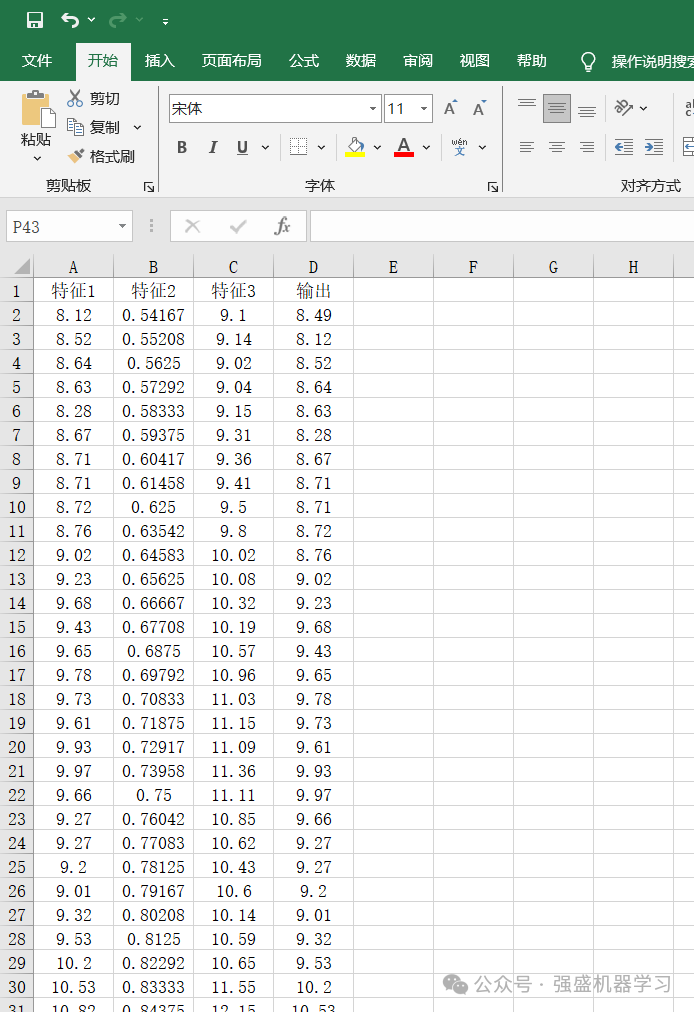
更换自己的数据时,只需最后一列放想要预测的列,其余列放特征即可,无需更改代码,非常方便!
以上所有图片,作者都已精心整理过代码,都可以一键运行main直接出图!不信的话可以看下面文件夹截图,非常清晰明了!
适用平台:Matlab2023a版本及以上,没有的文件夹里已免费提供安装包!
原理讲解与流程
传统预测是以点预测的形式提供的,这种单一的预测信息不足以体现预测的不确定性。分位数回归可以直接估计不同分位数的点值,其优点是可以在整个分位数范围内提供预测值,而不用提前假设分布函数的参数形式。
因此,我们结合分位数理论,提出基于分位数的 CNN-BiGRU-MultiAttention区间预测模型,该模型可实现在不同分位数下的预测,从而实现区间预测功能。
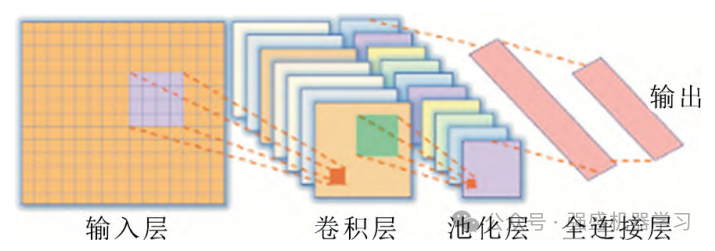
1.CNN(卷积神经网络)
CNN 具有出色的特征提取能力,已经在计算机视觉、故障诊断等领域得到了广泛的应用。卷积层和池化层是 CNN 的两个重要组成部分,也是 CNN 特有的结构,其在CNN结构中通常交替出现, 同时在CNN结构通常还包含全连接层。CNN 网络的典型结构如下图所示。卷积层的主要作用是深入挖掘输入数据的特征,池化层通常紧随在卷积层后,可以降低特征维度,使CNN网络的收敛速度更快。具体的卷积计算过程式为:
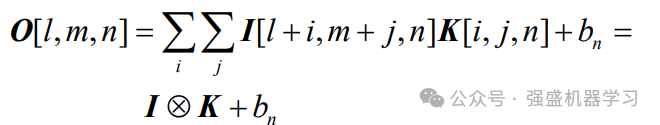
式中:O 表示神经元局部输出;I 为神经元输入;l、 m、n 分别表示输出矩阵的 3 个维度;i、j、n 分别 表示卷积核 K 的长度、宽度和深度;n b 表示卷积核 的阈值;⊗表示矩阵的乘法运算。
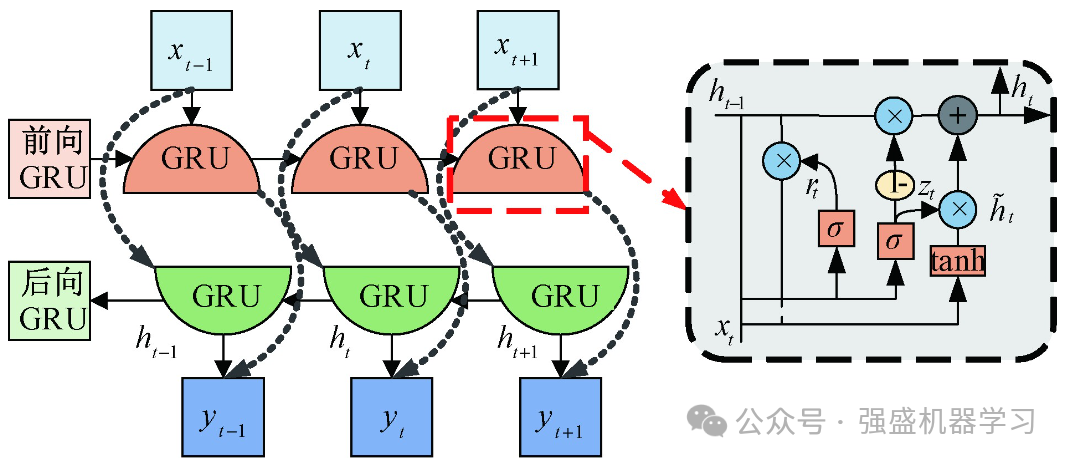
2.BiGRU(双向门控循环单元)
门控循环单元(GRU)是循环神经网络的一种, 是循环神经网络(RNN)和长短期记忆网络(LSTM) 的改进。BiGRU 本质上是一个双层 GRU 网络,在前向 GRU 层中,通过前向传播将特征输入到网络训练中,并挖掘数据的前向相关性。在逆向 GRU 层中,输入序列通过反向传播进行训练,挖掘数据的逆相关性。这种网络架构可以对输入的特征进行双向提取,更好地提高特征的完整性和全局性。
3.MultiAttention(多头自注意力)
注意力机制通过动态计算注意力权重来适应不同的输入情况。自注意力机制在传统注意力机制的基础上进行了进一步改良,获取全局的信息而非单一上下文的信息,使其更全面地理解整个序列的语义,并更好地捕捉元素之间的复杂关系。
多头自注意力机制引入多个注意力头,每个注意力头都是一个独立的自注意力机制,学习到一组不同的权重和表示。在多头自注意力机制中,输入序列首先通过线性变换映射到多个不同的query、key、和value空间。每个注意力头都会对这些映射后的查询、键和值进行独立的注意力计算,得到每个位置的表示。最后,将模型中每个注意力头的表示通过线性变换和拼接操作来合并,就得到最终的输出表示。
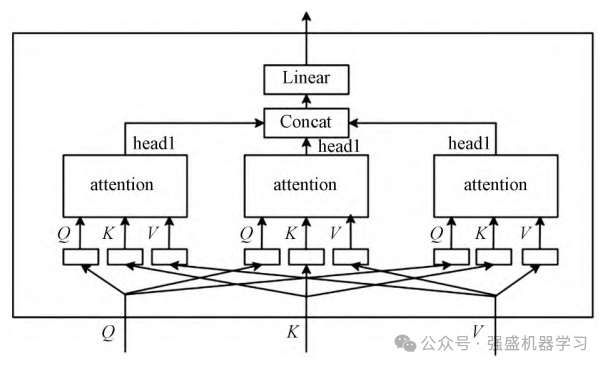
4.模型结构
以下是程序中的网络结构图,跟其他程序中的CNN-BiGRU-MultiAttention模型相比,我们的模型结构非常简洁,各结构层之间能简化的一定简化!省去了很多不必要的网络结构和代码,更加清晰易懂,适合新手小白!同时,直接运行main文件即可一键自动生成此网络结构图!
部分代码展示
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
res = xlsread('数据集.xlsx');
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
%res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 格式转换
for i = 1 : M
vp_train{i, 1} = p_train(:, i);
vt_train{i, 1} = t_train(:, i);
end
for i = 1 : N
vp_test{i, 1} = p_test(:, i);
vt_test{i, 1} = t_test(:, i);
end
%% 创建网络
save_net = [];
for i = 0.02 : 0.05 : 0.97 % 置信区间范围 0.97 - 0.02 = 0.95
%% 建立模型
lgraph = layerGraph();可以看到,代码注释非常清晰,适合新手小白!
全家桶代码目录
目前,全家桶在之前9个模型的基础上又增加了一个,共10个,之后还会推出更多更新颖的模型!
正如上文提到的,如果你想蹭蹭发顶刊,需要很多对比模型衬托你的模型的优越性,那么全家桶包含这么多模型可以说完全符合你的需求!

更重要的是,购买后如果以后推出其他区间预测模型,可直接免费下载,无需再次付费!
但如果你之后再买,一旦推出新模型,价格肯定是会上涨的!所以需要创新的小伙伴请早下手早超生!!
目前已经提供了10种区间预测模型,如果小伙伴有想要跟自己的预测模型结合起来,比如将BiTCN-BiGRU-Attention这类高级的模型形成区间预测,都是没有问题的!后台留言或私信我即可!)
代码获取
1.已将本文算法加入区间预测全家桶中,点击下方小卡片,后台回复关键字,不区分大小写:
区间预测全家桶
2.如果实在只想要QRCNN-BiGRU-MultiAttention单品的同学,点击下方小卡片,后台回复关键字,不区分大小写:
QCBMA
更多免费代码链接:更多代码链接
















 26
26











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









