






学习之前的废话O(∩_∩)O
整个的Elasticsearch的学习资源链接https://pan.baidu.com/s/1wBgs84D4rHn7Ok72opt6hw?pwd=ws9d
今天这个写的东西还是比较多的了,没有去复习期末考试内容,可以说一整天都是在工作室学习这个东西内容,要记下去的东西也很多,今天学习的文档基本就是边学边写,然后自己也过了一遍自己写的内容啊,可以说是我尽力去写了,我自己是能看懂的,但是别人会不会就很不自信了😅
其实学了大概的东西内容我才知道其实第一章要理解之后,后面的东西理解起来就没问题,主要是语法要去背下怎么去写的,其实我感觉就算有ai去辅助去写DSL的语句,也要懂点基本的语法至少50%是要学会的,要不然到之后Ai写的内容如果错了,还是很难去改的。而且也不知道怎给ai喂提示词去纠错
大家其实案例的语句可以自己写一下熟悉一下看是否会写,数据其实我都是在网上随便找的几个来做案例的,这些其实自己去写其实挺简单的。前提是要看懂基本的语法结构
一 数据库当中的正排索引和倒排索引
1 正排索引
什么是正排索引:指将文档的内容按照文档的顺序进行索引,每个文档对应一个索引条目,包含了文档的各个字段的内容
!通俗点来讲就是可以快速查找某个文档里包含哪些关键词,但是不适用于某个关键词在哪些文档中出现
!打个比方:在数据库系统中,将正排索引类比为表格的结构,每一行是一个记录,每一列是一个字段
| 学生ID | 姓名 | 年龄 | 成绩 |
|---|---|---|---|
| 1 | Jack | 20 | 90 |
| 2 | Tom | 18 | 85 |
| 3 | Carol | 19 | 92 |
| 4 | David | 21 | 88 |
| 5 | Ellen | 22 | 91 |
【可能看到这里还是会有点懵啊,没事看完倒排其实就差不多了】
2 倒排索引
什么是倒排索引:根据关键词构建的索引结构,记录了每个关键词出现在哪些文档或数据记录中,适用于全文搜索和关键词检索的场景
它将文档或数据记录划分成关键词的集合,并记录每个关键词所出现的位置和相关联的文档或数据记录的信息
假设我们有以下三个文档
-
文档1:我喜欢吃苹果
-
文档2:我喜欢吃橙子和苹果
-
文档3:我喜欢吃香蕉
倒排索引的结构示意图如下
-
关键词 "我":文档1、文档2、文档3
-
关键词 "喜欢":文档1、文档2、文档3
-
关键词 "吃":文档1、文档2、文档3
-
关键词 "苹果":文档1、文档2
-
关键词 "橙子":文档2
-
关键词 "香蕉":文档3
通过倒排索引,可以快速地找到包含特定关键词的文档或数据记录
3 总结
-
正排索引和倒排索引的结构和用途不同
-
正排索引用于快速访问和提取文档的内容
-
倒排索引用于快速定位和检索包含特定词语的文档
二 ElasticSearch8.X索引-文档-中文分词
这部分的内容就是一些基本的El的crud语法了,是简介版本的在第三部分我会写特殊且核心的一些语法的,同样的最后不可能就是说在这个面板上进行操作的,肯定要和springboot框架搭连起来的,在后端代码去写这些搜索语句。【和springboot连接肯定得要等到明天了,今天学不完😮💨,就学了点理论的核心操作】
1 ElasticSearch8.X索引Index核心操作
- 查看索引
GET /_cat/indices?v=true&pretty
- 查看分片情况
GET /_cat/shards?v=true&pretty
- 创建索引(Create Index)
PUT /<index_name> # 索引名称 随意取
{
"settings": { # 用于配置索引的 基础设置
"number_of_shards": 1, # 指定索引的 主分片数量 未指定的话就是1
"number_of_replicas": 1 # 指定索引的 副本分片数量
}
}PUT /guanmuya_shop
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
- 查看索引是否存在
HEAD /<index_name>
HEAD /guanmuya_shop
- 获取索引
GET /<index_name>
GET /guanmuya_shop
# 获取完了之后就可以看到这个索引区域的一些基本配置了,目前我还没学完,所以说不了太多😅
- 更新索引
PUT /<index_name>/_settings
{
"settings": {
"number_of_replicas": 2
}
}
PUT /guanmuya_shop/_settings
{
"settings": {
"number_of_replicas": 2
}
}
# 其实整个的语法可以看出,更加像json格式的一种,“/”更像是目录层级结构
- 删除索引
DELETE /<index_name>
DELETE /guanmuya_shop
2 Elastic Search8.X文档Document核心操作
文档document:真正的数据,存储一条数据就是一份文档,存储格式为JOSN,等同于mysql中的一条数据
文档的基本操作
- 查询文档
# 其实看这个语法也可以看的出来是查看某个索引下所存在的文档
GET /guanmuya_shop/_doc/1
# 结果 我是新增文档才会有这个数据的哈
{
"_index": "guanmuya_shop",
"_id": "1",
"_version": 1,
"_seq_no": 3,
"_primary_term": 2,
"found": true,
"_source": {
"id": 5555,
"title": "测试文档v1",
"pv": 144
}
}
- 新增文档(需要指定ID)POST方式也可以的 这里及下面的指定ID指的不是这个”id“,而是{ID}, id还是要加的
# 索引不存在其实问题不大,它会自动的帮你生成对于的索引的
# PUT /xdclass_shop/_doc/{ID}
PUT /guanmuya_shop/_doc/1
{
"id":5555,
"title":"测试文档v1",
"pv":144
}
- 新增文档(不指定ID或者指定ID都可以),会自动生成id
POST /guanmuya_shop/_doc
{"id" : 123
"title":"测试文档v2",
"pv":244
}
- 修改(put和post都行,需要指定ID){ID} 再提醒是大写的那部分
PUT /xdclass_shop/_doc/1
{
"id":999,
"title":"测试文档v2",
"pv":999,
"uv":55
}
POST /xdclass_shop/_doc/1
{
"id":999,
"title":"测试文档v3",
"pv":999,
"uv":559
}
- 搜索
GET /guanmuya_shop/_search
结果数据
{
"took": 846,
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "guanmuya_shop",
"_id": "1",
"_score": 1,
"_source": {
"title": "测试文档v3",
"pv": 100
}
},
{
"_index": "guanmuya_shop",
"_id": "2",
"_score": 1,
"_source": {
"id": 1111,
"title": "测试文档v1",
"pv": 144
}
},
{
"_index": "guanmuya_shop",
"_id": "2TNfOZcBXCvo6WCaNvHh",
"_score": 1,
"_source": {
"id": 123,
"title": "测试文档v3",
"pv": 100
}
},
{
"_index": "guanmuya_shop",
"_id": "2DNYOZcBXCvo6WCaefFx",
"_score": 1,
"_source": {
"title": "测试文档v2",
"pv": 244
}
}
]
}
}- 删除数据(指定一个,多个都是可以的)
# 指定一个
DELETE /xdclass_shop/_doc/1
# 指定多个
POST /xdclass_shop/_delete_by_query
{
"query": {
"match_all": {} // 匹配所有文档
}
}
3 Elastic Search8.X的Mapping和常见字段类型
什么是Mapping
-
类似于数据库中的表结构定义 schema,
-
定义索引中的字段的名称,字段的数据类型,比如字符串、数字、布尔等
查看索引库的字段类型
GET /<index_name>/_mapping
GET /my_index/_mapping
Dynamic Mapping(动态映射)
-
用于在索引文档时自动检测和定义字段的数据类型
-
当我们向索引中添加新文档时,Elasticsearch会自动检测文档中的各个字段,并根据它们的值来尝试推断字段类型
-
常见的字段类型包括文本(text)、关键词(keyword)、日期(date)、数值(numeric)等
-
动态映射具备自动解析和创建字段的便利性,但在某些情况下,由于字段类型的不确定性,动态映射可能会带来一些问题
-
例如字段解析错误、字段类型不一致等,如果对字段类型有明确的要求,最好在索引创建前通过显式映射定义来指定字段类型
ElasticSearch常见的数据类型 (学习新版本的好处来了,基本上软件的版本迭代我觉得,个人观点,叠个甲,1月一小更,3月一大更)
-
在 ES 7.X后有两种字符串类型:Text 和 Keyword
-
Text类型:用于全文搜索的字符串类型,支持分词和索引建立
-
Keyword类型:用于精确匹配的字符串类型,不进行分词,适合用作过滤和聚合操作。
-
-
Numeric类型:包括整数类型(long、integer、short、byte)和浮点数类型(double、float)。
-
Date类型:用于存储日期和时间的类型。
-
Boolean类型:用于存储布尔值(true或false)的类型。
-
Binary类型:用于存储二进制数据的类型。
-
Array类型:用于存储数组或列表数据的类型。
-
Object类型:用于存储复杂结构数据的类型
案例:自己可以试着写一个文档,然后查看索引库的字段类型

最高频使用的数据类型
text字段类型
- text类型主要用于全文本搜索,适合存储需要进行全文本分词的文本内容,如文章、新闻等。
- text字段会对文本内容进行分词处理,将文本拆分成独立的词项(tokens)进行索引
- 分词的结果会建立倒排索引,使搜索更加灵活和高效。
- text字段在搜索时会根据分词结果进行匹配,并计算相关性得分,以便返回最佳匹配的结果。
keyword字段类型
- keyword类型主要用于精确匹配和聚合操作,适合存储不需要分词的精确值,如ID、标签、关键字等。
- keyword字段不会进行分词处理,而是将整个字段作为一个整体进行索引和搜索
- 这使得搜索只能从精确的值进行匹配,而不能根据词项对内容进行模糊检索。
- keyword字段适合用于过滤和精确匹配,同时可以进行快速的基于精确值的聚合操作。
小结
- 在选择text字段类型和keyword字段类型时,需要根据具体的需求进行权衡和选择:
- 如果需要进行全文本检索,并且希望根据分词结果计算相关性得分,以获得最佳的匹配结果,则选择text字段类型。
- 如果需要进行精确匹配、排序或聚合操作,并且不需要对内容进行分词,则选择keyword字段类型。
案例实战
-
创建索引并插入文档
PUT /my_index
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"tags": {
"type": "keyword"
},
"publish_date": {
"type": "date"
},
"rating": {
"type": "float"
},
"is_published": {
"type": "boolean"
},
"author": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
},
"comments": {
"type": "nested",
"properties": {
"user": {
"type": "keyword"
},
"message": {
"type": "text"
}
}
}
}
}
}
# 插入数据
POST /my_index/_doc/1
{
"title": "上线新课 Elasticsearch Introduction",
"tags": ["search", "big data", "distributed system"],
"publish_date": "2025-01-01",
"rating": 4.5,
"is_published": true,
"author": {
"name": "John Doe",
"age": 30
},
"comments": [
{
"user": "Alice",
"message": "Great article!"
},
{
"user": "Bob",
"message": "Very informative."
}
]
}
案例的实际结果你们可以自己看看哈,不展示了,展示有点水了
查询匹配关键词的文档一
GET /my_index/_search
{
"query": {
"match": {
"title": "Elasticsearch"
}
}
}
查询匹配关键词的文档二
GET /my_index/_search
{
"query": {
"match": {
"tags": "data"
}
}
}
4 搜索引擎的分词和ES默认分词器
搜索引擎的分词:在Elasticsearch 8.X中,分词(tokenization)是将文本内容拆分成独立的单词或词项(tokens)的过程。分词是搜索引擎在建立索引和执行查询时的关键步骤,将文本拆分成单词,并构建倒排索引,可以实现更好的搜索和检索效果。【倒排索引之前说过完了看第一章】
!上案例<( ̄︶ ̄)↗[GO!]!
假设我们有两个产品标题:
"Apple iPhone 12 Pro Max 256GB"
"Samsung Galaxy S21 Ultra 128GB"
使用默认的标准分词器(Standard Tokenizer),这些标题会被分割为以下令牌:
标题1:["Apple", "iPhone", "12", "Pro", "Max", "256GB"]
标题2:["Samsung", "Galaxy", "S21", "Ultra", "128GB"]
分词器根据标点符号和空格将标题拆分为独立的词语。当我们执行搜索时,可以将查询进行分词,并将其与标题中的令牌进行匹配。
例如
如果我们搜索"iPhone 12",使用默认的分词器,它会将查询分解为["iPhone", "12"],然后与令牌进行匹配。
对于标题1,令牌["iPhone", "12"]匹配,它与查询相符。 标题2中没有与查询相符的令牌
分词规则是指定义如何将文本进行拆分的规则和算法
-
Elasticsearch使用一系列的分词器(analyzer)和标记器(tokenizer)来处理文本内容
-
分词器通常由一个或多个标记器组成,用于定义分词的具体规则
分词的一般过程
标记化(Tokenization):
分词的第一步是将文本内容拆分成单个标记(tokens),标记可以是单词、数字、特殊字符等。
标记化过程由标记器(tokenizer)执行,标记器根据一组规则将文本切分为标记。
过滤(Filtering):
标记化后,标记会进一步被过滤器(filters)处理。
过滤器执行各种转换和操作,如转换为小写、去除停用词(stop words),词干提取(stemming),同义词扩展等。
倒排索引(Inverted Indexing):
分词处理完成后,Elasticsearch使用倒排索引(inverted index)来存储分词结果。
倒排索引是一种数据结构,通过将标记与其所属文档进行映射,快速确定包含特定标记的文档。
查询匹配:
当执行查询时,查询的文本也会进行分词处理。
Elasticsearch会利用倒排索引来快速查找包含查询标记的文档,并计算相关性得分。
常见的分词器,如Standard分词器、Simple分词器、Whitespace分词器、IK分词等,还支持自定义分词器
ElasticSearch的默认Standard分词器的规则
标点符号切分:
标点符号会被删除,并将连字符分隔为两个独立的词。
例如,"Let's go!" 会被切分为 "Let", "s", "go"。
小写转换:
所有的文本会被转换为小写形式。
例如,"Hello World" 会被切分为 "hello", "world"。
停用词过滤:
停用词(stop words)是在搜索中没有实际意义的常见词,如 "a", "an", "the" 等。
停用词会被过滤掉,不会作为独立的词进行索引和搜索。
词干提取:
通过应用Porter2词干提取算法,将单词还原为其原始形式。
例如,running -> run、swimming -> swim、jumped -> jump
词分隔:
按照空格将文本切分成词项(tokens)。
查看ES分词存储效果
使用analyze API 来对文本进行分词处理并查看分词结果,基本语法如下
GET /_analyze
{
"analyzer": "分词器名称",
"text": "待分析的文本"
}
!上案例<( ̄︶ ̄)↗[GO!]!
#字段是text类型
POST /my_index/_analyze
{
"field": "title",
"text": "This is some text to analyze"
}#字段是text类型
POST /my_index/_analyze
{
"field": "title",
"text": "今天我在课堂学习"
}
#字段是keyword类型
POST /my_index/_analyze
{
"field": "tags",
"text": "This is some text to analyze"
}
#字段是keyword类型
POST /my_index/_analyze
{
"field": "tags",
"text": ["This is","课堂","Spring Boot" ]
}
每个分词结果对象包含
- 分词后的单词(token)
- 开始位置(start_offset)
- 结束位置(end_offset)
- 类型(type)
类型(type):ALPHANUM是一种数据类型,表示一个字符串字段只包含字母和数字,并且不会进行任何其他的分词或处理
- 它会忽略字段中的任何非字母数字字符(如标点符号、空格等),只保留字母和数字字符单词在原始文本中的位置(position)
5 IK中文分词器配置
ok啊,原版本自带的那个Standard分词器,由于是老外写的那个ElasticSearch所以整个对于中文的分词非常的不友好,如果你去对中文一段话去分词操作其实可以看出他都是一个字分开的,不是一个词语分开的。

Ik分词器:
-
是一个基于Java开发的开源中文分词器,用于将中文文本拆分成单个词语(词项)
-
是针对中文语言的特点和需求而设计的,可以有效处理中文分词的复杂性和多样性
注意:Elastic Search版本和IK分词器版本需要对应
如果你的那个版本不对可以去Ik官网仓库下载对应的ElasticSearch版本的IK分词器https://github.com/medcl/elasticsearch-analysis-ik/releases
特点
1) 高效且灵活
- IK分词器采用了多种算法和数据结构,以提供高效的分词速度。
- 支持细粒度的分词,可以根据应用需求进行灵活的配置。
2) 分词准确性
- IK分词器使用了词典和规则来进行分词,可以准确地将句子拆分成词语。
- 还提供了词性标注功能,可以帮助识别词语的不同含义和用途。
3) 支持远程扩展词库
- IK分词器可以通过配置和加载外部词典,扩展分词的能力
- 用户可以根据实际需求,添加自定义的词典,提升分词准确性和覆盖范围。
4) 兼容性与集成性
- IK分词器兼容了Lucene和Elasticsearch等主流搜索引擎,可以方便地集成到这些系统中。
- 提供了相应的插件和配置选项,使得分词器的集成变得简单。
配置说明
1)解压文件,上传到安装的Elstaicsearch中的plugin的ik目录下
tar -zxvf kibana-8.4.1-linux-x86_64.tar.gz
2) 先暂停Elstaicsearch服务进程
#关闭Elasticsearch节点
bin/elasticsearch -d
#检查进程是否已经停止
ps -ef | grep elasticsearch
其实后续只需要在分析语句中加上"analyzer":"ik_max_word" or "analyzer":"ik_smart" 这个字段就行了
GET /_analyze
{
"text":"今天星期一,我今天去小滴课堂学习spring cloud项目大课",
"analyzer":"ik_smart"
}
GET /_analyze
{
"text":"今天星期一,我今天去小滴课堂学习spring cloud项目大课",
"analyzer":"ik_max_word"
}
这里也提到了两种解析的粗粒度
-
ik_smart: 会做最粗粒度的拆分
-
ik_max_word(常用): 会将文本做最细粒度的分
三 ElasticSearch查询DSL语法进阶
1 Query DSL语法和应用
什么是Query DSL语法
-
Query DSL(Domain-Specific Language)是一种用于构建搜索查询的强大的领域特定查询语言
-
类似我们关系性数据库的SQL查询语法,
-
ES中用JSON结构化的方式定义和执行各种查询操作,在ES中进行高级搜索和过滤
基本语法
GET /索引库名/_search
{
"query":{
"查询类型":{
}
}
常见Query DSL查询语句和功能
-
match查询:用于执行全文搜索,它会将搜索查询与指定字段中的文本进行匹配
{
"query": {
"match": {
"title": "elasticsearch"
}
}
}
-
term查询:用于精确匹配一个指定字段的关键词,不进行分词处理。
{
"query": {
"term": {
"category": "books"
}
}
}
小总结
-
Query DSL提供了更多种类的查询和过滤语句,以满足不同的搜索需求。
-
可以根据具体的业务需求和数据结构,结合不同的查询方式来构建复杂的搜索和过滤操作
!上案例数据<( ̄︶ ̄)↗[GO!]! 为后续的一些做下铺垫学习
创建数据
PUT /guanmuya_shop_v1
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "keyword"
},
"summary": {
"type": "text"
},
"price": {
"type": "float"
}
}
}
}
导入数据
PUT /guanmuya_shop_v1/_bulk
{ "index": { "_index": "guanmuya_shop_v1" } }
{ "id": "1", "title": "Spring Boot","summary":"this is a summary Spring Boot video", "price": 9.99 }
{ "index": { "_index": "guanmuya_shop_v1" } }
{ "id": "2", "title": "java","summary":"this is a summary java video", "price": 19.99 }
{ "index": { "_index": "guanmuya_shop_v1" } }
{ "id": "3", "title": "Spring Cloud","summary":"this is a summary Spring Cloud video", "price": 29.99 }
{ "index": { "_index": "guanmuya_shop_v1" } }
{ "id": "4", "title": "Spring_Boot", "summary":"this is a summary Spring_Boot video","price": 59.99 }
{ "index": { "_index": "guanmuya_shop_v1" } }
{ "id": "5", "title": "SpringBoot","summary":"this is a summary SpringBoot video", "price": 0.99 }
2 ElasticSearch查询DSL多案例实战
搜索案例
- 查询全部的数据(match_all)
GET /guanmuya_shop_v1/_search
{
"query": {
"match_all": {}
}
}
- 有条件查询数据(match,对查询内容进行分词, 然后进行查询,多个词条之间是 or的关系然后在与文档里面的分词进行匹配,匹配度越高分数越高越前面)
GET /guanmuya_shop_v1/_search
{
"query": {
"match": {
"summary": "Spring"
}
}
}
#包括多个词
GET /guanmuya_shop_v1/_search
{
"query": {
"match": {
"summary": "Spring Java"
}
}
}
- 完整关键词查询(term查询,不会将查询条件分词,直接与文档里面的分词进行匹配虽然match也可以完成,但是match查询会多一步进行分词,浪费资源)
#keyword类型字段,ES不进行分词
GET /guanmuya_shop_v1/_search
{
"query": {
"term": {
"title": {
"value": "Spring Boot"
}
}
}
}
- 获取指定字段(某些情况场景下,不需要返回全部字段,太废资源,可以指定source返回对应的字段)
GET /guanmuya_shop_v1/_search
{
"_source":["price","title"],
"query": {
"term": {
"title": {
"value": "Spring Boot"
}
}
}
}
总结
-
match在匹配时会对所查找的关键词进行分词,然后分词匹配查找;term会直接对关键词进行查找
-
一般业务里面需要模糊查找的时候,更多选择match,而精确查找时选择term查询
3 Query DSL布尔-范围和分页-排序
1) rang查询
-
用于根据范围条件进行查询,例如指定价格在一定区间内的商品
-
范围符号(gte:大于等于、gt:大于、lte:小于等于、lt:小于)
GET /xdclass_shop_v1/_search
{
"query": {
"range": {
"price": {
"gte": 5,
"lte": 100
}
}
}
}
2) 分页查询
-
可以使用
from和size参数进行分页查询 -
可以指定要跳过的文档数量(
from)和需要返回的文档数量(size)
GET /guanmuya_shop_v1/_search
{
"size": 10,
"from": 0,
"query": {
"match_all": {}
}
}
3) 查询结果排序
-
sort字段可以进行排序desc和asc
GET /guanmuya_shop_v1/_search
{
"size": 10,
"from": 0,
"sort": [
{
"price": "asc"
}
],
"query": {
"match_all": {}
}
}
4) bool查询
-
通过组合多个查询条件,使用布尔逻辑(与、或、非)进行复杂的查询操作
-
语法格式
-
"must"关键字用于指定必须匹配的条件,即所有条件都必须满足
-
"must_not"关键字指定必须不匹配的条件,即所有条件都不能满足
-
"should"关键字指定可选的匹配条件,即至少满足一个条件
-
{
"query": {
"bool": {
"must": [
// 必须匹配的条件
],
"must_not": [
// 必须不匹配的条件
],
"should": [
// 可选匹配的条件
],
"filter": [
// 过滤条件
]
}
}
}
bool案例
GET /guanmuya_shop_v1/_search
{
"query": {
"bool": {
"must": [
{ "match": { "summary": "Cloud" }},
{ "range": { "price": { "gte": 5 }}}
]
}
}
}
4 Query DSL查询过滤Filter多案例
filter查询
-
来对搜索结果进行筛选和过滤,仅返回符合特定条件的文档,而不改变搜索评分
-
Filter查询对结果进行缓存,提高查询性能,用于数字范围、日期范围、布尔逻辑、存在性检查等各种过滤操作。
-
语法格式
-
"filter"关键字用于指定一个过滤条件,可以是一个具体的过滤器,如term、range等,也可以是一个嵌套的bool过滤器
-
{
"query": {
"bool": {
"filter": {
// 过滤条件
}
}
}
}
!上案例<( ̄︶ ̄)↗[GO!]!为后续做准备
数据准备 ,先创建索引库,再插入数据(通过一次 POST 请求实现批量插入
每个文档都由两部分组成:index 指令用于指定文档的元数据,product_id 为文档的唯一标识符
插入后查询 GET /product/_search)
# 创建索引库
PUT /product
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"product_id": {
"type": "integer"
},
"product_name": {
"type": "text"
},
"category": {
"type": "keyword"
},
"price": {
"type": "float"
},
"availability": {
"type": "boolean"
}
} }
}
# 插入数据
POST /product/_bulk
{ "index": { "_id": "1" } }
{ "product_id": 1, "product_name": "Product 1", "category": "books", "price": 19.99, "availability": true }
{ "index": { "_id": "2" } }
{ "product_id": 2, "product_name": "Product 2", "category": "electronics", "price": 29.99, "availability": true }
{ "index": { "_id": "3" } }
{ "product_id": 3, "product_name": "Product 3", "category": "books", "price": 9.99, "availability": false }
{ "index": { "_id": "4" } }
{ "product_id": 4, "product_name": "Product 4", "category": "electronics", "price": 49.99, "availability": true }
{ "index": { "_id": "5" } }
{ "product_id": 5, "product_name": "Product 5", "category": "fashion", "price": 39.99, "availability": true }案例
# 案例一:使用 range 过滤器查询价格 price 在 30 到 50 之间的产品:
GET /product/_search
{
"query": {
"bool": {
"filter": {
"range": {
"price": {
"gte": 30,
"lte": 50
}
}
}
}
}
}
# 案例二:使用 term 过滤器查询 category 为 books 的产品:
GET /product/_search
{
"query": {
"bool": {
"filter": {
"term": {
"category": "books"
}
}
}
}
}小总结
-
过滤条件通常用于对结果进行筛选,并且比查询条件更高效
-
而bool查询可以根据具体需求组合多个条件、过滤器和查询子句
5 match高级用法之多字段匹配和短语搜索
1)多字段搜索匹配
-
业务查询,需要在多个字段上进行文本搜索,用 multi_match
-
在 match的基础上支持对多个字段进行文本查询匹配
语法格式
GET /index/_search
{
"query": {
"multi_match": {
"query": "要搜索的文本",
"fields": ["字段1", "字段2", ...]
}
}
}
# query:需要匹配的查询文本。
# fields:一个包含需要进行匹配的字段列表的数组。2)短语搜索匹配
-
是Elasticsearch中提供的一种高级匹配查询类型,用于执行精确的短语搜索
-
相比于
match查询,match_phrase会在匹配时考虑到单词之间的顺序和位置
语法格式
GET /index/_search
{
"query": {
"match_phrase": {
"field_name": {
"query": "要搜索的短语"
}
}
}
}
# field_name:要进行匹配的字段名。
# query:要搜索的短语。!上案例<( ̄︶ ̄)↗[GO!]!为后续做铺垫
# 创建索引库
PUT /product_v2
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"product_name": {
"type": "text"
},
"description": {
"type": "text"
},
"category": {
"type": "keyword"
}
}
}
}
# 插入数据
POST /product_v2/_bulk
{ "index": { "_index": "product_v2", "_id": "1" } }
{ "product_name": "iPhone 12", "description": "The latest iPhone model from Apple", "category": "electronics" }
{ "index": { "_index": "product_v2", "_id": "2" } }
{ "product_name": "Samsung Galaxy S21", "description": "High-performance Android smartphone", "category": "electronics" }
{ "index": { "_index": "product_v2", "_id": "3" } }
{ "product_name": "MacBook Pro", "description": "Powerful laptop for professionals", "category": "electronics" }
{ "index": { "_index": "product_v2", "_id": "4" } }
{ "product_name": "Harry Potter and the Philosopher's Stone", "description": "Fantasy novel by J.K. Rowling", "category": "books" }
{ "index": { "_index": "product_v2", "_id": "5" } }
{ "product_name": "The Great Gatsby", "description": "Classic novel by F. Scott Fitzgerald", "category": "books" }测试案例
# 多字段搜索案例实战
#在 product_name 和 description 字段上执行了一个multi_match查询
#将查询文本设置为 "iPhone",对这两个字段进行搜索,并返回包含匹配到的文档,这个是OR的关系,会有最佳匹配
GET /product_v2/_search
{
"query": {
"multi_match": {
"query": "iPhone",
"fields": ["product_name", "description"]
}
}
}
# 短语搜索案例实战
#使用match_phrase查询在description字段上执行了一个短语搜索将要搜索的短语设置为 "classic novel"。
#使用match查询,Elasticsearch将会返回包含 "classic novel" 短语的文档
#match_phrase短语搜索
GET /product_v2/_search
{
"query": {
"match_phrase": {
"description": "classic novel"
}
}
}
#match搜索,会进行分词
GET /product_v2/_search
{
"query": {
"match": {
"description": "classic novel"
}
}
}6 日常单词拼写错误-fuzzy模糊查询
fuzzy模糊匹配
-
fuzzy查询是Elasticsearch中提供的一种模糊匹配查询类型,用在搜索时容忍一些拼写错误或近似匹配 -
使用
fuzzy查询,可以根据指定的编辑距离(即词之间不同字符的数量)来模糊匹配查询词 -
拓展:编辑距离(是将一个术语转换为另一个术语所需的一个字符更改的次数。
比如
更改字符(box→fox)
删除字符(black→lack)
插入字符(sic→sick)
转置两个相邻字符(dgo→dog)) -
fuzzy模糊查询是拼写错误的简单解决方案,但具有很高的 CPU 开销和非常低的精准度
-
用法和match基本一致,Fuzzy query的查询不分词
语法格式
GET /index/_search
{
"query": {
"fuzzy": {
"field_name": {
"value": "要搜索的词",
"fuzziness": "模糊度"
}
}
}
}
# 语法解析
# field_name:要进行模糊匹配的字段名。
# value:要搜索的词
# fuzziness参数指定了模糊度,常见值如下
# 0,1,2
# 指定数字,表示允许的最大编辑距离,较低的数字表示更严格的匹配,较高的数字表示更松散的匹配
# fuziness的值,表示是针对每个词语而言的,而不是总的错误的数值
# AUTO:Elasticsearch根据词的长度自动选择模糊度
# 如果字符串的长度大于5,那 funziness 的值自动设置为2
# 如果字符串的长度小于2,那么 fuziness 的值自动设置为 0案例实战<( ̄︶ ̄)↗[GO!]
# 指定模糊度2,更松散匹配
GET /guanmuya_shop_v1/_search
{
"query": {
"fuzzy": {
"summary": {
"value": "clo",
"fuzziness": "2"
}
}
}
}
# 指定模糊度1,更严格匹配
GET /guanmuya_shop_v1/_search
{
"query": {
"fuzzy": {
"summary": {
"value": "clo",
"fuzziness": "1"
}
}
}
}
# 使用自动检查,1个单词拼写错误
GET /guanmuya_shop_v1/_search
{
"query": {
"fuzzy": {
"summary": {
"value": "Sprina",
"fuzziness": "auto"
}
}
}
}7 DSL搜索高亮显示
日常搜索产品的时候,会有关键词显示不一样的颜色,方便用户直观看到区别
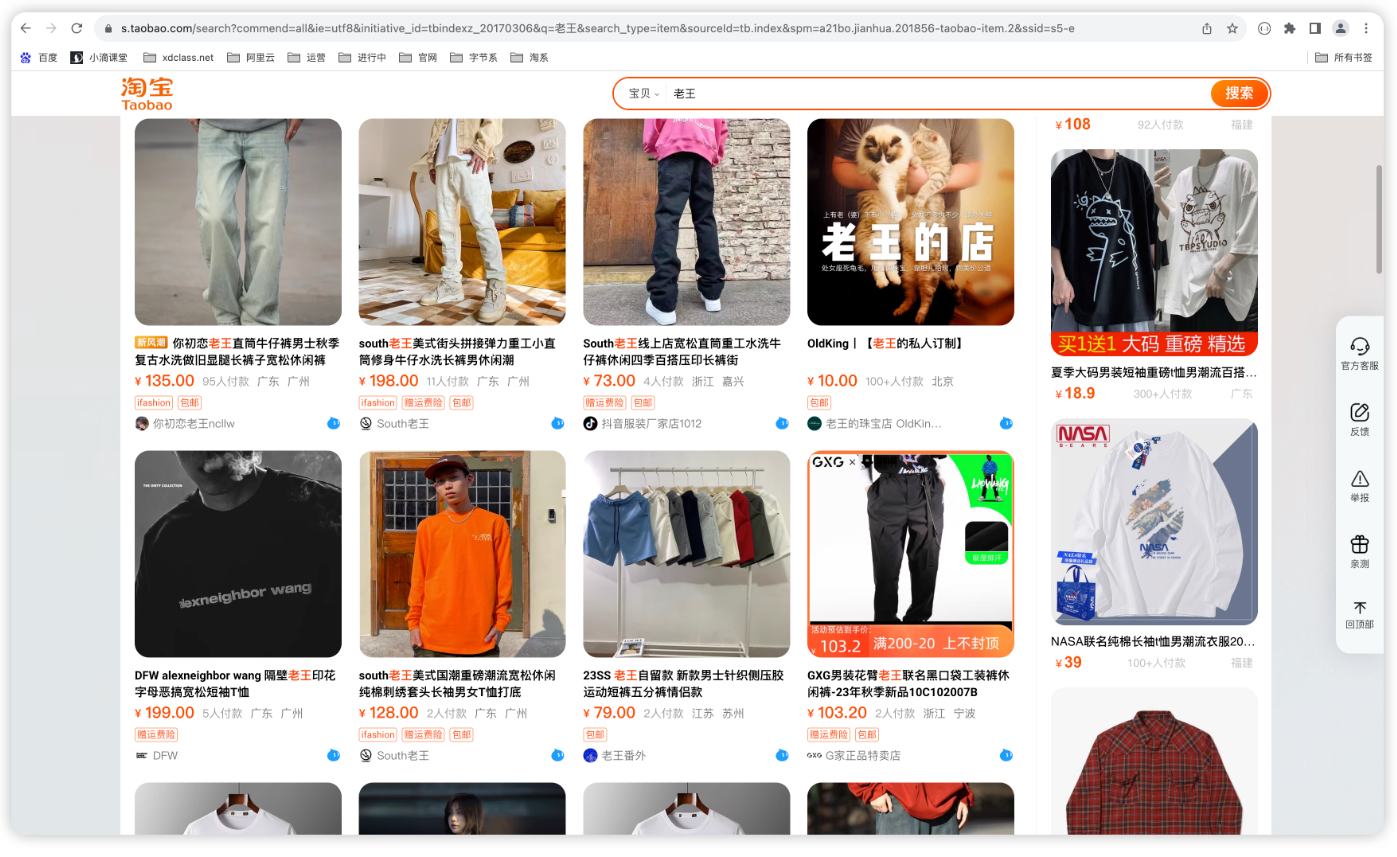
-
在 ES 中,高亮语法用于在搜索结果中突出显示与查询匹配的关键词
-
高亮显示是通过标签包裹匹配的文本来实现的,通常是
<em>或其他 HTML 标签 -
基本用法:在 highlight 里面填写要高亮显示的字段,可以填写多个
!上案例<( ̄︶ ̄)↗[GO!]!
数据准备
#创建索引库
PUT /guanmuya_high_light_test
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
},
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
}
}
#插入数据
PUT /guanmuya_high_light_test/_doc/1
{
"title": "课堂2028年最新好看的电影推荐",
"content": "每年都有新电影上线,2028年最新好看的电影有不少,课堂上线了《架构大课》,《低代码平台》,《小王往事》精彩电影"
}
PUT /guanmuya_high_light_test/_doc/2
{
"title": "写下你认为好看的电影有哪些",
"content": "每个人都看看很多电影,说下你近10年看过比较好的电影,比如《架构大课》,《海量数据项目大课》,《小王的故事》"
}1) 单条件查询高亮显示
GET /guanmuya_high_light_test/_search
{
"query": {
"match": {
"content": "电影"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}2) 组合多条件查询,highlight里面填写需要高亮的字段
GET /guanmuya_high_light_test/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "课堂"
}
},
{
"match": {
"content": "小王"
}
}
]
}
},
"highlight": {
"fields": {
"title": {},
"content": {}
}
}
}3) match查询,使用highlight属性,可以增加属性,修改高亮样式
-
pre_tags:前置标签
-
post_tags:后置标签
-
fields:需要高亮的字段
GET /xdclass_high_light_test/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "课堂"
}
},
{
"match": {
"content": "老王"
}
}
]
}
},
"highlight": {
"pre_tags": "<font color='yellow'>",
"post_tags": "</font>",
"fields": [{"title":{}},{"content":{}}]
}
}四 总结
ok啊今天也是学到吐了,看了下才刚刚入门,后续还有一些高级的聚合语法之类的,还有和spingboot链接的语法还没看完,不过目前的一些DSL语句其实并不复杂只是有点多了,但是常用的格式其实差不多,所以我学起来其实还算是可以的,至少能够差不多70%能够记住,后续的话就开始边学边记了,好了今天也是结束了拜拜明天见。

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









