







python图像处理-基于LBP的人脸检测和人脸识别
主要工作是:
1.了解LBP纹理特征的原理
2.调用OPEN-CV人脸识别库,框出图像中所有的人脸
3.将人脸区域做LBPH,将其计算结果与人脸标签做训练集(H表示直方图)
4.用爬虫爬出两个人的很多图片,构成较为多图片的训练集
5.用训练出来的分类器进行人脸识别
目录
头文件:
import numpy as np
import os
import cv2
import matplotlib.pyplot as plt
1. LBP纹理特征的原理
LBP: Local Binary Pattern, 局部二进制模式,是一种用来描述图像局部纹理的算子,它具有旋转不变性和灰度不变性等显著优点。它所提取的特征是局部特征,反映的是每个像素与周围像素的信息。
原始LBP算子:在33的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,33邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共2^8 = 256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。

圆形LBP算子:基本的 LBP 算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,并达到灰度和旋转不变性的要求,Ojala 等对 LBP 算子进行了改进,将 3×3 邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的 LBP 算子允许在半径为 R 的圆形邻域内有任意多个像素点,从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子。

旋转不变LBP算子:从LBP的定义可以看出,LBP算子是灰度不变的,但却不是旋转不变的。图像的旋转会得到不同的LBP值。Maenpaa等人又将 LBP 算子进行了扩展,提出了具有旋转不变性的 LBP 算子,即不断旋转圆形邻域得到一系列初始定义的 LBP 值,取其最小值作为该邻域的 LBP 值。

LBP等价模式:一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生2^p种模式。随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。同时,过多的模式种类对于纹理的表达是不利的。例如,将LBP算子用于纹理分类或人脸识别时,常采用LBP模式的统计直方图来表达图像的信息,而较多的模式种类将使得数据量过大,且直方图过于稀疏。因此,需要对原始的LBP模式进行降维,使得数据量减少的情况下能最好的代表图像的信息。
为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类。如00000000(0次跳变),00000111(只含一次从0到1的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)
以上都是些原理,下面是应用和思考:
在skimage库中有local_binary_pattern函数可以直接调用,函数的参数method分别取值为default, ror, uniform分别对应圆形LBP模式,LBP旋转不变模式和LBP等价模式。
下面比较旋转图片在default和ror模式下的提取效果。
原图:

default模式下的纹理特征提取:

roc模式下的纹理特征提取:

默认模式虽然很清楚,但是缺少旋转不变性,因为每旋转一定角度,生成的二进制就会移动,导致二进制数发生很大的变换。所以采用旋转不变性时,不论怎么旋转,都采用最小的值。这样一来,二进制不论怎么平移,都对应着唯一的值。但是这也导致,图像上的每一个点的灰度值都很接近,使图像偏暗。
2.调用OPEN-CV人脸识别库,框出图像中所有的人脸
## 这个函数是做人脸提取的,faces_rect是个四维向量,前两位输出人脸所在位置的左上方坐标,后两位是人类所在宽度
def detect_face(test_img):
gray_img = cv2.cvtColor(test_img, cv2.COLOR_BGR2GRAY) # converts color img to grayscale img
# the below line loads haar classifier
face_haar_cascade = cv2.CascadeClassifier("D:/classofmathpicture/trainingImages/haarcascade_frontalface_default.xml")
faces = face_haar_cascade.detectMultiScale(gray_img, scaleFactor = 1.32, minNeighbors = 5) # detectMultiScale returns rectangles
return faces, gray_img
# 在图片中,在人脸位置上框出人类,并且给它标上text内容
def b_boxes(test_img, face):
(x, y, w, h) = face
cv2.rectangle(test_img, (x, y), (x + w, y + h), (255, 0, 0), thickness = 1)
# 在框边写名字
def put_name(test_img, text, x, y):
cv2.putText(test_img, text, (x, y), cv2.FONT_HERSHEY_DUPLEX, 1, (255, 0, 0), 1)
3. 爬出两个人的很多图片
需要放入两个文件夹,方便下面的图片与标签对应

链接
4.将爬出的图片与标签对应
## 训练函数,输出id(通过文件名)和 每一张图片的人脸部分。都是以链表的形式储存
def labels_train_data(directory):
faces = []
labels = []
for path, subdirnames, filenames in os.walk(directory):
for filename in filenames:
if filename.startswith("."):
print("Skipping system file")
continue
id = os.path.basename(path) # fetching subdirectory names
img_path = os.path.join(path, filename) # fetching img path
print("img_path:", img_path)
print("id:", id)
test_img = cv2.imread(img_path) # loading each img
if test_img is None:
print("Image not loaded properly")
continue
faces_rect, gray_img = detect_face(test_img) # calling this fn returns faces detected in particular img
if len(faces_rect) != 1:
continue # since we are assuming only single person images are being fed to the classifier
(x, y, w, h) = faces_rect[0]
roi_gray = gray_img[y : y + w, x : x + h] # cropping region of interest (face area from grayscale image)
faces.append(roi_gray)
labels.append(int(id))
return faces, labels
5.进行分类
# 分类函数 输入某人的人脸图片以及其标签,生产训练集
def train_classifier(faces, labels):
face_recognizer = cv2.face.LBPHFaceRecognizer_create()
face_recognizer.train(faces, np.array(labels))
return face_recognizer
利用下面的LBPH提取人脸纹理直方图特征,进行分类,并记录在新的XML文件中。还可以用其他的特征提取算法:

6.实例
6.1 图像与标签构成训练集
faces, labels = labels_train_data("D:/classofmathpicture/wu")
文件夹应该是下图,0放入一个人的图片;1放入另一个人的图片。可以通过爬虫找图片
6.2 进行分类
#进行分类
face_recognizer = train_classifier(faces, labels)
#生成yml文件
face_recognizer.write("D:/classofmathpicture/trainingData.yml")
6.3 利用LBPH读取训练集
# 读取训练集,输出face_recognizer参数
face_recognizer = cv2.face.LBPHFaceRecognizer_create()
face_recognizer.read("D:/classofmathpicture/trainingData.yml")
6.4 选取测试图片,并进行人脸检测
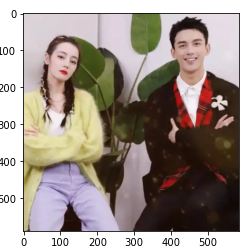
# 选取测试图片
test_img = cv2.imread("D:/classofmathpicture/wulei_test4.png",1) # test img path
test_img = cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)
faces_detected, gray_img = detect_face(test_img)
plt.imshow(test_img)
faces_detected是人脸位置,链表数表示已检测人脸数目:
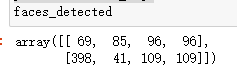
6.5 人脸识别
利用图像识别函数求出参数,根据参数识别不同的人脸
##选取最小的confidence值下的人脸作为匹配最接近的,其余判定other
name = {0:"wulei",1:"reba"} # creating dict containing names
for face in faces_detected:
(x, y, w, h) = face
roi_gray = gray_img[y:y+h, x:x+w]
label, confidence = face_recognizer.predict(roi_gray) # predicting the label of given image
print("Confidence:", confidence)
print("Label:", label)
b_boxes(test_img, face)
predicted_name = name[label]
# if confidence>100: # if this is true then it doesn't print predicted face text on screen
# continue
put_name(test_img, predicted_name, x, y)
plt.figure(figsize=(20, 10));
plt.imshow(test_img)
















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









