









1. 写在前面
Linux perf 是 Linux 2.6+ 后内置于内核源码树中的性能剖析(profiling)工具,它基于事件采样,以性能事件为基础,针对 CPU 相关性能指标与操作系统相关性能指标进行性能剖析,可用于性能瓶颈查找与热点代码的定位。包含在 Linux 内核 tools/perf 下,通过命令 perf 实现一组子命令:stat , record , report ,[…]
2. perf 是什么?
perf 是由 Linux 官方提供的系统性能分析工具,perf 包含两部分:
-
perf 命令:用户空间应用程序;
-
perf_events:Linux 内核子系统;
perf 命令是一个用户空间工具,具备 profiling、tracing 和脚本编写等多种功能,是内核子系统 perf_events 的前置工具。通过 perf 命令可以设置和操作内核子系统 perf_events,完成系统性能数据的收集和分析。
内核子系统 perf_events 提供了性能计数器(hardware performance counters)和性能事件的支持,它以事件驱动型的方式工作,通过收集特定事件(如 CPU 时钟周期,缓存未命中等)来跟踪和分析系统性能。perf_events 是在 2009 年合并到 Linux 内核源代码中,成为内核一个新的子系统。
虽然 perf 命令是一个用户空间的应用程序,但它却位于 Linux 内核源代码树中,在 tools/perf 目录下。
perf 和 perf_events 最初支持硬件计数器(performance monitoring counters,PMC),后来逐步扩展到支持多种事件源,包括:tracepoints、kernel 软件事件、kprobes、uprobes 和 USDT(User-level statically-defined tracing)。
下图显示了 perf 命令和 perf_events 的关系,以及 perf_events 支持的事件源。
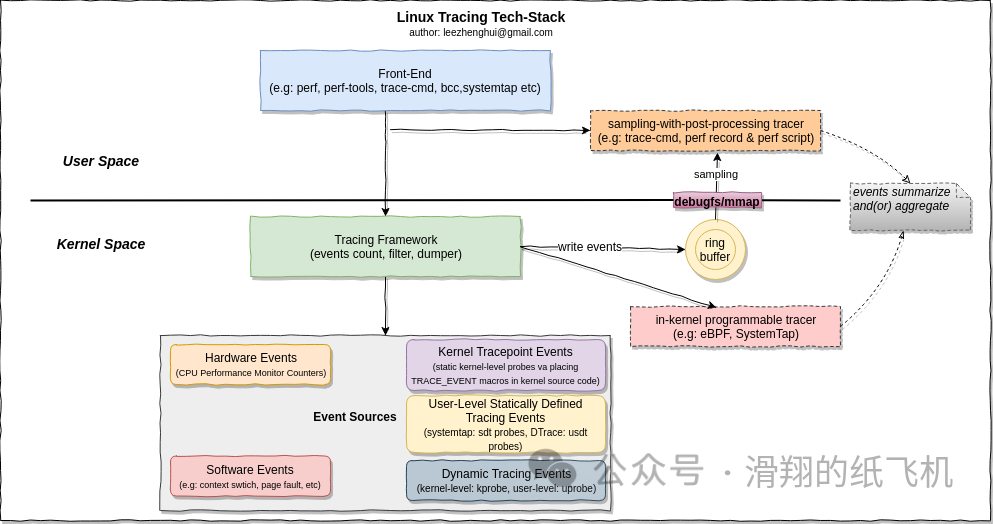
2.1 perf event
perf 支持来自硬件和软件等方面的各种事件。如下图所示:
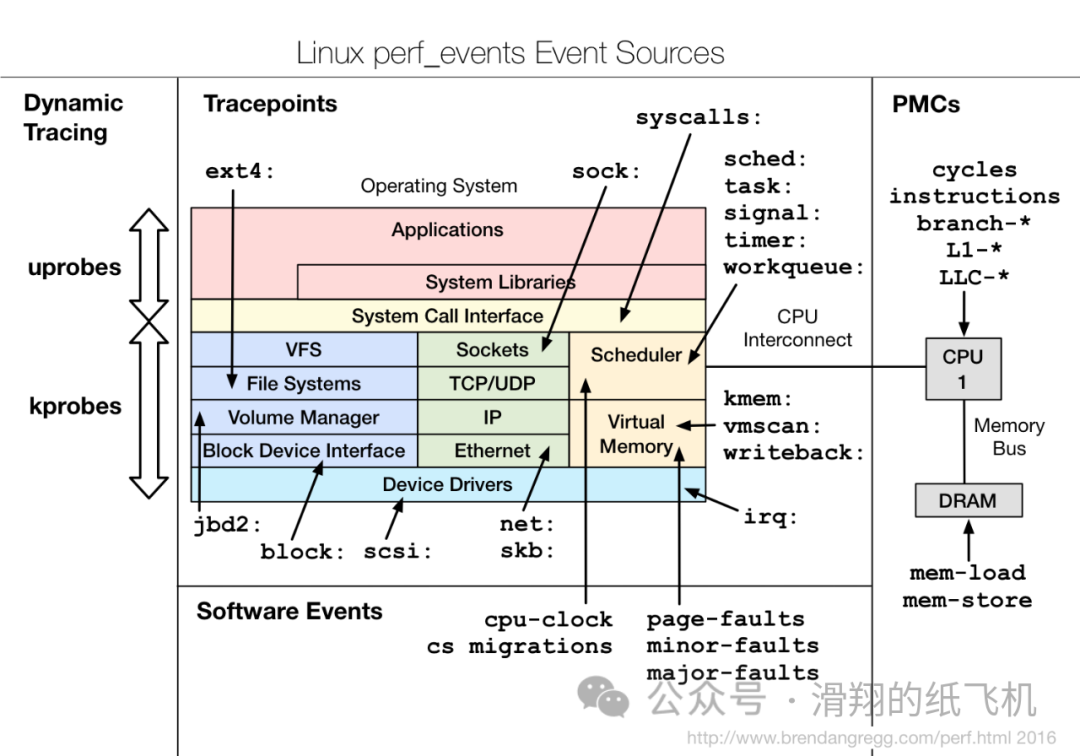
event 类型包括:
-
Hardware Events: CPU 性能监视计数器 PMCs;
-
Software Events: 基于内核计数器的低级别事件。例如,CPU迁移、 缺页中断(minor faults, major faults)等等。
-
Kernel Tracepoint Events: 硬编码在内核中的静态内核级的检测点,即静态探针
-
User-Level Statically-Defined Tracing (USDT): 这些是用户级程序和应用程序的静态跟踪点。
-
Dynamic Tracing: 可以被放置在任何地方的动态探针。对于内核软件,可使用 kprobes 框架,对于用户级软件,则使用 uprobes。
-
Timed Profiling: 使用
perf record -FHz选项以指定频率收集的快照。这通常用于 CPU 使用情况分析,其工作原理是周期性的产生时钟中断事件。
与其他性能分析工具相比,perf 特别适合 CPU 分析,它能对运行在 CPU 上代码调用栈(stack traces)进行采样,以确定程序在 CPU 上的运行情况,识别和优化代码中的热点。这种 CPU Profiling 能力是基于硬件计数器 (performance monitoring counters,PMC) 实现的,而 PMC 被内核子系统 perf_events 包装成了 Hardware Event。
list 子命令列出当前可用的事件:
root@dev:~# sudo perf list
---------------------------------------------------------------------------------
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
duration_time [Tool event]
msr/smi/ [Kernel PMU event]
msr/tsc/ [Kernel PMU event]
rNNN [Raw hardware event descriptor]
cpu/t1=v1[,t2=v2,t3 ...]/modifier [Raw hardware event descriptor]
(see 'man perf-list' on how to encode it)
mem:<addr>[/len][:access] [Hardware breakpoint]
alarmtimer:alarmtimer_cancel [Tracepoint event]
alarmtimer:alarmtimer_fired [Tracepoint event]
... ...
200多本网络安全系列电子书
网络安全标准题库资料
项目源码
网络安全基础入门、Linux、web安全、攻防方面的视频
网络安全学习路线图
2.2 采样事件
perf -FHz :perf 每隔一个固定的时间,就在CPU上(每个核上都有)产生一个中断,在中断上看看,当前是哪个pid,哪个函数,然后给对应的pid和函数加一个统计值,这样,我们就知道CPU有百分几的时间在某个pid,或者某个函数上了。
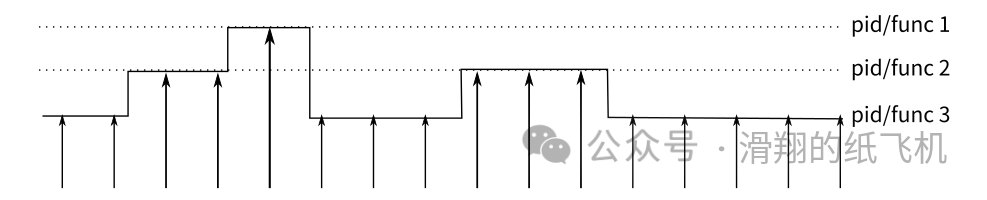
这种方式可以推广到各种事件,此时使用的不再是 -FHz 指定的频率,而是 -e 参数指定的各种 event。当指定的事件发生的时候,perf 就会上来冒个头,看看击中了谁,然后算出分布,我们就知道谁会引发特别多的那个事件了。
所以本质上 perf 属于一种抽样统计。既然是抽样统计我们就要警惕抽样带来的抽样误差。每次看 perf report 的报告,首先要去注意一下总共收集了多少个点,如果你只有几十个点,你这个报告就可能很不可信了。
3. 如何安装 perf
3.1 安装
Linux 系统上没有预装 perf 程序,安装方式因 Linux 发行版而异:
Ubuntu/Debian:
sudo apt install linux-tools-$(uname -r) linux-tools-generic
RHEL/CentOS:
sudo yum install perf
Fedora:
sudo dnf install perf
打印版本号,表明安装成功。
root@dev:~# perf --version
---------------------------------------------------------------------------------
perf version 5.4.257
3.2 允许普通用户使用
perf 命令默认需要 sudo 权限,要允许普通用户使用 perf,执行以下操作:
(1) 切换到 root 用户:
sudo su -
(2) 输入以下命令:
echo 0 > /proc/sys/kernel/perf_event_paranoid
该命令允许普通用户在当前会话中使用 perf 工具。
(3) 切换回普通用户:
exit
示例:
test@dev:~$ sudo su -
root@dev:~# echo 0 > /proc/sys/kernel/perf_event_paranoid
root@dev:~# exit
logout
test@dev:~$ perf --version
perf version 5.4.257
要保留更改,请执行以下操作:
(1) 编辑sysctl 配置文件:
sudo nano /etc/sysctl.conf
(2) 在文件中添加以下内容:
kernel.perf_event_paranoid = 0
(3) 保存更改并退出
4. Linux perf 命令语法
语法:perf <options> subcommand <options/arguments>
perf 工具的工作原理与 git 类似,包含不同子命令和活动界面。在不带任何选项或参数的情况下运行该命令,会显示可用子命令列表。
200多本网络安全系列电子书
网络安全标准题库资料
项目源码
网络安全基础入门、Linux、web安全、攻防方面的视频
网络安全学习路线图
4.1 Linux perf 子命令
常用的 perf 子命令:
| 子命令(Subcommand) | 描述 |
|---|---|
| annotate | 解析perf record生成的perf.data文件,显示被注释的代码; |
| list | 列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点; |
| stat | 执行某个命令,收集特定进程的性能概况,包括CPI、Cache丢失率等; |
| record | 收集采样信息,并将其记录在数据文件中。随后可通过其它工具对数据文件进行分析; |
| report | 读取perf record创建的数据文件,并给出热点分析结果; |
| script | 执行perl或python写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等; |
| top | 类似于linux的top命令,对系统性能进行实时分析; |
| diff | 对比两个数据文件的差异。能够给出每个符号(函数)在热点分析上的具体差异; |
| archive | 根据数据文件记录的build-id,将所有被采样到的elf文件打包。利用此压缩包,可以再任何机器上分析数据文件中记录的采样数据; |
| bench | perf中内置的benchmark,目前包括两套针对调度器和内存管理子系统的benchmark |
| buildid-cache | 管理perf的buildid缓存,每个elf文件都有一个独一无二的buildid;buildid被perf用来关联性能数据与elf文件; |
| buildid-list | 列出数据文件中记录的所有buildid; |
| evlist | 列出数据文件perf.data中所有性能事件; |
| inject | 该工具读取perf record工具记录的事件流,并将其定向到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件; |
| kmem | 针对内核内存(slab)子系统进行追踪测量的工具; |
| kvm | 用来追踪测试运行在KVM虚拟机上的Guest OS; |
| lock | 分析内核中的锁信息,包括锁的争用情况,等待延迟等; |
| mem | 内存存取情况; |
| sched | 针对调度器子系统的分析工具; |
| test | perf对当前软硬件平台进行健全性测试,可用此工具测试当前的软硬件平台是否能支持perf的所有功能; |
| timechart | 针对测试期间系统行为进行可视化的工具; |
| trace | 关于syscall的工具; |
| probe | 用于定义动态检查点; |
要显示各个子命令的选项,执行:perf <subcommand> -h
test@dev:~$ perf stat -h
---------------------------------------------------------------------------------
Usage: perf stat [<options>] [<command>]
-a, --all-cpus system-wide collection from all CPUs
-A, --no-aggr disable CPU count aggregation
-B, --big-num print large numbers with thousands' separators
-C, --cpu <cpu> list of cpus to monitor in system-wide
-D, --delay <n> ms to wait before starting measurement after program start
-d, --detailed detailed run - start a lot of events
-e, --event <event> event selector. use 'perf list' to list available events
-G, --cgroup <name> monitor event in cgroup name only
-g, --group put the counters into a counter group
-I, --interval-print <n>
print counts at regular interval in ms (overhead is possible for values <= 100ms)
-i, --no-inherit child tasks do not inherit counters
-M, --metrics <metric/metric group list>
monitor specified metrics or metric groups (separated by ,)
-n, --null null run - dont start any counters
-o, --output <file> output file name
-p, --pid <pid> stat events on existing process id
-r, --repeat <n> repeat command and print average + stddev (max: 100, forever: 0)
... ...
5. Linux perf 命令示例
使用 perf 命令分析性能:
-
perf list 查看当前系统支持的性能事件;
-
perf stat 执行某个命令,收集特定进程的性能概况,包括CPI、Cache丢失率等;
-
perf record 收集采样信息,并将其记录在数据文件中。随后可通过其它工具对数据文件进行分析;
-
perf report 读取perf record创建的数据文件,并给出热点分析结果;
-
perf script 执行perl或python写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等;
5.1 Perf list
perf list(不带选项)返回所有事件类型(长列表)。如果要查看特定类别中可用的事件列表,请使用 perf list,后跟类别名称([hw|sw|cache|tracepoint|pmu|event_glob]),例如:
root@dev:~# sudo perf list
---------------------------------------------------------------------------------
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
duration_time [Tool event]
msr/smi/ [Kernel PMU event]
msr/tsc/ [Kernel PMU event]
... ...
显示 software events 列表:
root@dev:~# sudo perf list sw
---------------------------------------------------------------------------------
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
duration_time [Tool event]
5.2 Perf stat
perf stat 运行命令并收集命令执行过程中的 Linux 性能统计数据。当我们运行 dd 时,系统中会发生什么?
root@dev:~# sudo perf stat dd if=/dev/zero of=test.iso bs=10M count=1
---------------------------------------------------------------------------------
1+0 records in
1+0 records out
10485760 bytes (10 MB, 10 MiB) copied, 0.022202 s, 472 MB/s
Performance counter stats for 'dd if=/dev/zero of=test.iso bs=10M count=1':
24.10 msec task-clock # 0.576 CPUs utilized
2 context-switches # 0.083 K/sec
2 cpu-migrations # 0.000 K/sec
2645 page-faults # 0.110 M/sec
62,025,623 cycles # 2.8Ghz
6,299,287 stalled-cycles-frontend # 10.16% frontend cycles idle
24,456,020 stalled-cycles-backend # 39.43% backend cycles idle
6,299,287 instructions # 0.20 insns per cycle
# 1.93 stalled cycles per insn
3,552,630 branches # 162.873 M/sec
51,348 branch-misses # 1.45% of all branches
0.041854933 seconds time elapsed
0.000000000 seconds user
0.024977000 seconds sys
上述统计数据表明:
(1) 执行 dd 命令占用 CPU 24.10 msec。如果用这个数字除以下面的 "seconds time elapsed"值(0.041854933 s => 41.85493 msec),就会得出 0.5757(CPU 使用率)。
(2) 在执行命令时,2 context-switches 2 次上下文切换(也称为进程切换)表明 CPU 从一个进程(或线程)切换到另一个进程(或线程)15 次。
(3) 2 次 CPU 迁移是 2 核 CPU 平均分配工作负载的预期结果。在这段时间内(24.10 毫秒),CPU 总共消耗了 62,025,623 个 CPU 周期,除以 24.10 秒得 2.843 GHz。
(4) 如果我们将周期数除以指令总数,就会得到 4.9 个周期/指令,这意味着每条指令平均需要近 5 个 CPU 周期才能完成。我们可以将此归咎于 branches 和 branch-misses 的数量,因为它们最终浪费或误用了 CPU 周期。
(5) 在执行命令的过程中,总共遇到了 3,552,630 个 branches。这是代码中决策点和循环的 CPU-level 表示。branches 越多,性能越低。为了弥补这一缺陷,所有现代 CPU 都会尝试预测代码的流向。51 348 次 branch-misses 表明预测功能有 1.45% 的时间是错误的。
同样的原理也适用于在应用程序运行时收集统计数据。只需启动所需的应用程序,并在一段合理的时间后关闭它,perf 就会在屏幕上显示统计信息。通过分析这些统计数据,可以找出潜在的问题。
收集 5s 内 Linux 性能统计数据:
整个系统在 5 秒钟内收集的详细报告。在没有参数 5 的情况下,系统测量直至使用 CTRL+C 终止。
root@dev:~# sudo perf stat -a sleep 5
---------------------------------------------------------------------------------
Performance counter stats for 'system wide':
20050.80 msec cpu-clock # 3.999 CPUs utilized
2739 context-switches # 0.137 K/sec
4 cpu-migrations # 0.000 K/sec
1527 page-faults # 0.076 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
5.013329052 seconds time elapsed
按类型统计 Linux 内核系统调用:
sudo perf stat -e 'syscalls:sys_enter_*' -a sleep 5
5秒后,显示所有系统范围的调用及其计数。
200多本网络安全系列电子书
网络安全标准题库资料
项目源码
网络安全基础入门、Linux、web安全、攻防方面的视频
网络安全学习路线图
5.3 Perf top
perf top 与 top 命令类似,它几乎实时显示系统概况(也称为实时分析)。
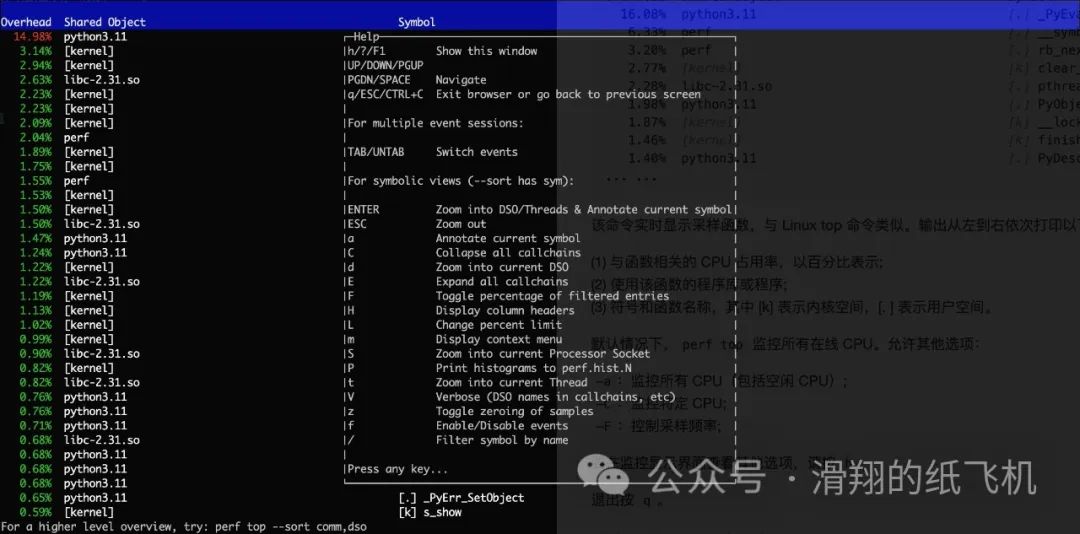
显示所有 cycles 事件:
root@dev:~# sudo perf top -a
---------------------------------------------------------------------------------
Samples: 8K of event 'cpu-clock:pppH', 4000 Hz, Event count (approx.): 2109843750 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
10.96% perf [.] __symbols__insert
9.79% python3.11 [.] _PyEval_EvalFrameDefault
7.22% [kernel] [k] clear_page_erms
4.07% perf [.] rb_next
2.38% libc-2.31.so [.] pthread_attr_setschedparam
1.91% libc-2.31.so [.] explicit_bzero
1.56% libelf-0.176.so [.] gelf_getsym
1.33% perf [.] rust_demangle_callback
1.33% [kernel] [k] __softirqentry_text_start
1.33% libc-2.31.so [.] calloc
1.28% [kernel] [k] __d_looku
显示所有与 CPU 时钟相关的事件:
root@dev:~# sudo perf top -e cpu-clock
---------------------------------------------------------------------------------
Samples: 7K of event 'cpu-clock', 4000 Hz, Event count (approx.): 1841687500 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
11.86% perf [.] __symbols__insert
10.46% python3.11 [.] _PyEval_EvalFrameDefault
6.13% perf [.] rb_next
2.38% libc-2.31.so [.] pthread_attr_setschedparam
1.78% [kernel] [k] clear_page_erms
1.65% perf [.] rust_demangle_callback
1.61% libc-2.31.so [.] explicit_bzero
1.55% libelf-0.176.so [.] gelf_getsym
从左到右三列:
(1) 与函数相关的 CPU 占用率(自运行开始以来采样的百分比),以百分比表示;
(2) 使用该函数的程序库或程序;
(3) 符号和函数名称,其中 [k] 表示内核空间,[. ] 表示用户空间。
默认情况下,perf top 监控所有在线 CPU。允许其他选项:
-a:监控所有 CPU(包括空闲 CPU);
-C:监控特定 CPU;
-F:控制采样频率;
要在监控显示界面查看其他选项,请按 h。
退出按 q。
5.4 Perf record
perf record 运行一条命令,并将统计数据保存到当前工作目录下名为 perf.data 的文件中。它的运行方式与 perf stat 类似。
输入 perf record,然后输入执行命令:
root@dev:~# sudo perf record dd if=/dev/null of=test.iso bs=10M count=1
---------------------------------------------------------------------------------
0+0 records in
0+0 records out
0 bytes copied, 0.000256291 s, 0.0 kB/s
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.013 MB perf.data (32 samples) ]
perf.data:
root@dev:~# ls -l
---------------------------------------------------------------------------------
-rw------- 1 root root 21844 Jan 6 23:44 perf.data
5.5 Perf report
perf report 将上述 perf.data 中收集的数据格式化为性能报告:
root@dev:~# sudo perf report
---------------------------------------------------------------------------------
Samples: 32 of event 'cpu-clock:pppH', Event count (approx.): 8000000
Overhead Command Shared Object Symbol
9.38% dd [kernel.kallsyms] [k] __lock_text_start
9.38% dd [kernel.kallsyms] [k] find_get_entries
9.38% dd [kernel.kallsyms] [k] truncate_inode_pages_range
6.25% dd [kernel.kallsyms] [k] ext4_invalidatepage
6.25% dd [kernel.kallsyms] [k] truncate_cleanup_page
3.12% dd [kernel.kallsyms] [k] block_invalidatepage
3.12% dd [kernel.kallsyms] [k] do_last
3.12% dd [kernel.kallsyms] [k] ext4_releasepage
3.12% dd [kernel.kallsyms] [k] file_path
3.12% dd [kernel.kallsyms] [k] filemap_map_pages
3.12% dd [kernel.kallsyms] [k] free_pcp_prepare
3.12% dd [kernel.kallsyms] [k] free_unref_page_list
3.12% dd [kernel.kallsyms] [k] jbd2_journal_try_to_free_buffers
3.12% dd [kernel.kallsyms] [k] kmem_cache_free
3.12% dd [kernel.kallsyms] [k] mark_page_accessed
3.12% dd [kernel.kallsyms] [k] page_cache_free_page.isra.0
3.12% dd [kernel.kallsyms] [k] page_mapped
使用 perf script 命令可以打印收集在 perf.data 中的每个样本:
root@dev:~# sudo perf script
---------------------------------------------------------------------------------
dd 300223 223778.568539: 250000 cpu-clock:pppH: 7fd7de4bc3d7 __get_cpu_features+0x15d7 (/usr/lib/x86_64-linux-gnu/ld-2.31.so)
dd 300223 223778.568720: 250000 cpu-clock:pppH: ffffffffbb84e048 vma_interval_tree_remove+0x158 ([kernel.kallsyms])
dd 300223 223778.568968: 250000 cpu-clock:pppH: ffffffffbb931bc5 userfaultfd_unmap_prep+0x5 ([kernel.kallsyms])
dd 300223 223778.569222: 250000 cpu-clock:pppH: ffffffffbb8e583f do_last+0x22f ([kernel.kallsyms])
dd 300223 223778.569490: 250000 cpu-clock:pppH: ffffffffbb8ce6d5 file_path+0x5 ([kernel.kallsyms])
dd 300223 223778.569725: 250000 cpu-clock:pppH: ffffffffbb8e1e6f path_init+0x1f ([kernel.kallsyms])
dd 300223 223778.569986: 250000 cpu-clock:pppH: ffffffffbb819894 filemap_map_pages+0x334 ([kernel.kallsyms])
dd 300223 223778.570221: 250000 cpu-clock:pppH: ffffffffbc09a028 xas_load+0x28 ([kernel.kallsyms])
5.6 查看进程 CPU 性能
使用 -p 选项并提供进程 ID (PID),将 CPU 性能统计数据附加到特定运行进程:
sudo perf -p <PID> sleep 5
示例:
root@dev:~# sudo perf stat -p 831 sleep 5
---------------------------------------------------------------------------------
Performance counter stats for process id '831':
4.96 msec task-clock # 0.001 CPUs utilized
175 context-switches # 0.035 M/sec
0 cpu-migrations # 0.000 K/sec
0 page-faults # 0.000 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
5.003798082 seconds time elapsed
显示给定进程的性能统计数据。
上述所有子命令(list、stat、top、record 或 report)都有对应帮助信息,按以下方式查看:
man perf-subcommand
题外话
初入计算机行业的人或者大学计算机相关专业毕业生,很多因缺少实战经验,就业处处碰壁。下面我们来看两组数据:
-
2023届全国高校毕业生预计达到1158万人,就业形势严峻;
-
国家网络安全宣传周公布的数据显示,到2027年我国网络安全人员缺口将达327万。
一方面是每年应届毕业生就业形势严峻,一方面是网络安全人才百万缺口。
6月9日,麦可思研究2023年版就业蓝皮书(包括《2023年中国本科生就业报告》《2023年中国高职生就业报告》)正式发布。
2022届大学毕业生月收入较高的前10个专业
本科计算机类、高职自动化类专业月收入较高。2022届本科计算机类、高职自动化类专业月收入分别为6863元、5339元。其中,本科计算机类专业起薪与2021届基本持平,高职自动化类月收入增长明显,2022届反超铁道运输类专业(5295元)排在第一位。
具体看专业,2022届本科月收入较高的专业是信息安全(7579元)。对比2018届,电子科学与技术、自动化等与人工智能相关的本科专业表现不俗,较五年前起薪涨幅均达到了19%。数据科学与大数据技术虽是近年新增专业但表现亮眼,已跻身2022届本科毕业生毕业半年后月收入较高专业前三。五年前唯一进入本科高薪榜前10的人文社科类专业——法语已退出前10之列。

“没有网络安全就没有国家安全”。当前,网络安全已被提升到国家战略的高度,成为影响国家安全、社会稳定至关重要的因素之一。
网络安全行业特点
1、就业薪资非常高,涨薪快 2021年猎聘网发布网络安全行业就业薪资行业最高人均33.77万!

2、人才缺口大,就业机会多
2019年9月18日《中华人民共和国中央人民政府》官方网站发表:我国网络空间安全人才 需求140万人,而全国各大学校每年培养的人员不到1.5W人。猎聘网《2021年上半年网络安全报告》预测2027年网安人才需求300W,现在从事网络安全行业的从业人员只有10W人。

行业发展空间大,岗位非常多
网络安全行业产业以来,随即新增加了几十个网络安全行业岗位︰网络安全专家、网络安全分析师、安全咨询师、网络安全工程师、安全架构师、安全运维工程师、渗透工程师、信息安全管理员、数据安全工程师、网络安全运营工程师、网络安全应急响应工程师、数据鉴定师、网络安全产品经理、网络安全服务工程师、网络安全培训师、网络安全审计员、威胁情报分析工程师、灾难恢复专业人员、实战攻防专业人员…
职业增值潜力大
网络安全专业具有很强的技术特性,尤其是掌握工作中的核心网络架构、安全技术,在职业发展上具有不可替代的竞争优势。
随着个人能力的不断提升,所从事工作的职业价值也会随着自身经验的丰富以及项目运作的成熟,升值空间一路看涨,这也是为什么受大家欢迎的主要原因。
从某种程度来讲,在网络安全领域,跟医生职业一样,越老越吃香,因为技术愈加成熟,自然工作会受到重视,升职加薪则是水到渠成之事。
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图

攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。

(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。

因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









