









线性回归定义
线性回归属于机器学习中监督学习的范畴。其训练集中的数据一般拥有多个输入变量(也称特征)和一个输出变量,我们对训练集中的数据进行拟合,得到一条近似曲线,并输出为确定的连续函数,即预测函数,是一个从输入变量x到输出变量y的关系函数。然后就可以使用该预测函数对输入的数据进行结果预测。
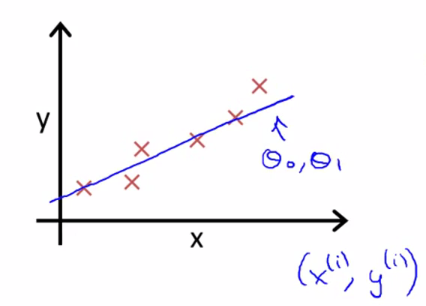
如上图所示,红叉表示训练集中数据的坐标,蓝色线即为拟合的预期函数曲线。
预测函数及代价函数
假设回归模型中的数据只有一个输入变量,即只有一个特征,以房屋估价为例,特征为房屋尺寸,输出为该房屋的估价,此时为简单回归问题。假设训练集中有m个样本,即m组房屋尺寸和对应房屋估价的数据,计算机要根据这些样本来拟合出贴合样本点的预测函数
。设预测函数为
=
。不同的参数
和
的取值,会产生不同的预期函数,而他们与训练集数据的贴合程序也不同,如下图所示。
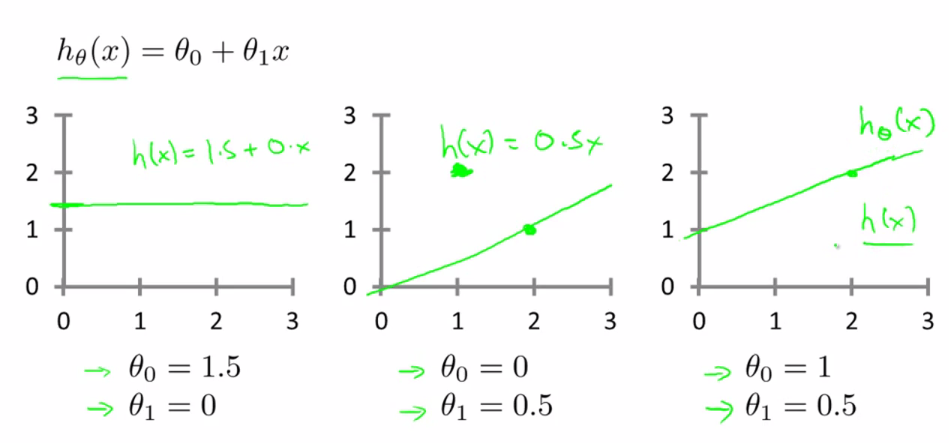
我们定义“代价”为预测函数所预测的结果相比真实结果的误差,要使预测函数拟合的更好,那么就要使代价更小。接着我们引入代价函数 ,即当预测函数的参数取不同值的时候,代价的变化趋势。代价函数的具体数学表示可以有很多种,其中应用广泛的一种为:使预测值
与实际值
的差的平方最小,下面给出这种代价函数的数学表示:
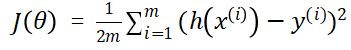
其中 m 为训练集的样本数, 为预测函数对第 i 个样本的预测结果,
为第 i 个样本的真实结果。我们需要找到合适的参数
和
来使该代价函数值最小。当预测函数中只有一个参数
时,该代价函数的为一个二次函数,函数图像大致如下:
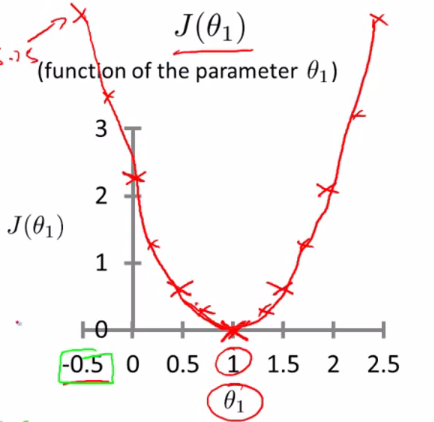
如上图所示,该代价函数在最低点时参数 的取值,即为最优的预测函数参数取值。
但当有两个参数 和
时,代价函数就会更加复杂,呈现为三维立体图像。
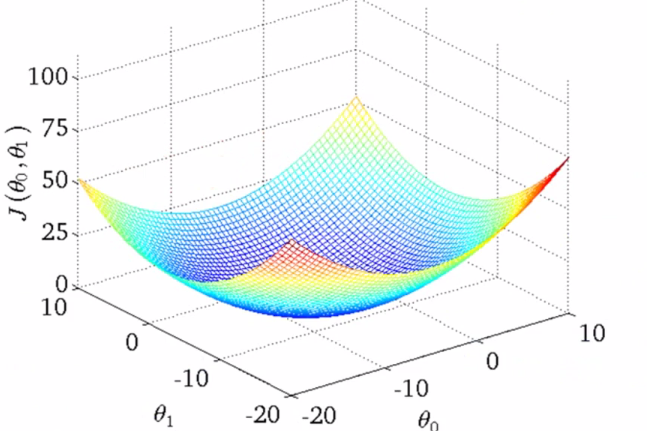
图像的高度为代价值,可以看出,此时代价函数仍存在最小值。而该三维立体图像也可以化为等高线图:
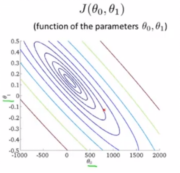
其中椭圆形的中心即为代价函数的最低点,也就是预测函数参数的最优取值点。当参数更多时,代价函数就无法可视化了。
上述介绍的这个代价函数即为均方误差函数(MSE),被广泛运用于回归问题中,对于大多数的回归问题它都表现得很好。找到使代价函数值最小时的的参数 、
、...
的取值的过程,称为代价函数的最小化。所以线性回归要做的就是:定义合适的预测函数,并将代价函数最小化,得到确定的预测函数。















 8306
8306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









