










一、pandas是什么?
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
一、回归树
基于树的回归方法主要是依据分层和分割的方式将特征空间划分为一系列简单的区域。对某个给定的待预测的自变量,用他所属区域中训练集的平均数或者众数对其进行预测。由于划分特征空间的分裂规则可以用树的形式进行概括,因此这类方法称为决策树方法。决策树由结点(node)和有向边(diredcted edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类别或者某个值。区域 𝑅1,𝑅2 等称为叶节点,将特征空间分开的点为内部节点。
建立回归树的过程大致可以分为以下两步:

回归树与线性模型的比较:

回归树与线性模型的比较:
线性模型的模型形式与树模型的模型形式有着本质的区别,具体而言,线性回归对模型形式做了如下假定: 𝑓(𝑥)=𝑤0+∑𝑗=1𝑝𝑤𝑗𝑥(𝑗) ,而回归树则是 𝑓(𝑥)=∑𝑚=1𝐽𝑐̂ 𝑚𝐼(𝑥∈𝑅𝑚) 。那问题来了,哪种模型更优呢?这个要视具体情况而言,如果特征变量与因变量的关系能很好的用线性关系来表达,那么线性回归通常有着不错的预测效果,拟合效果则优于不能揭示线性结构的回归树。反之,如果特征变量与因变量的关系呈现高度复杂的非线性,那么树方法比传统方法更优。
树模型的优缺点:
树模型的解释性强,在解释性方面可能比线性回归还要方便。
树模型更接近人的决策方式。
树模型可以用图来表示,非专业人士也可以轻松解读。
树模型可以直接做定性的特征而不需要像线性回归一样哑元化。
树模型能很好处理缺失值和异常值,对异常值不敏感,但是这个对线性模型来说却是致命的。
树模型的预测准确性一般无法达到其他回归模型的水平,但是改进的方法很多。
二、支持向量机回归(SVR)
在介绍支持向量回归SVR之前,我们先来了解下约束优化的相关知识:

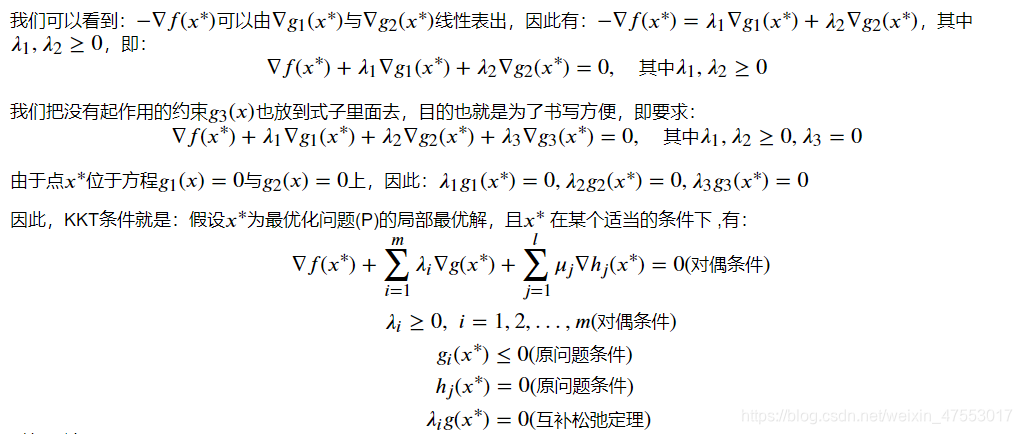
对偶理论:
为什么要引入对偶问题呢?是因为原问题与对偶问题就像是一个问题两个角度去看,如利润最大与成本最低等。有时侯原问题上难以解决,但是在对偶问题上就会变得很简单。再者,任何一个原问题在变成对偶问题后都会变成一个凸优化的问题,这点我们后面会有介绍。下面我们来引入对偶问题:

我们可以观察到,对偶问题是关于 𝜆 和 𝜇 的线性函数,因此对偶问题是一个凸优化问题,凸优化问题在最优化理论较为简单。 弱对偶定理:对偶问题(D)的最优解 𝐷∗ 一定小于原问题最优解 𝑃∗ ,这点在刚刚的讨论得到了充分的证明,一定成立。
强对偶定理:对偶问题(D)的最优解 𝐷∗ 在一定的条件下等于原问题最优解 𝑃∗ ,条件非常多样化且不是唯一的,也就是说这是个开放性的问题,在这里我给出一个最简单的条件,即: 𝑓(𝑥) 与 𝑔𝑖(𝑥) 为凸函数, ℎ𝑗(𝑥) 为线性函数,X是凸集, 𝑥∗ 满足KKT条件,那么 𝐷∗=𝑃∗ 。
支持向量回归SVR
在介绍完了相关的优化知识以后,我们开始正式学习支持向量回归SVR。
在线性回归的理论中,每个样本点都要计算平方损失,但是SVR却是不一样的。SVR认为:落在 𝑓(𝑥) 的 𝜖 邻域空间中的样本点不需要计算损失,这些都是预测正确的,其余的落在 𝜖 邻域空间以外的样本才需要计算损失,因此:
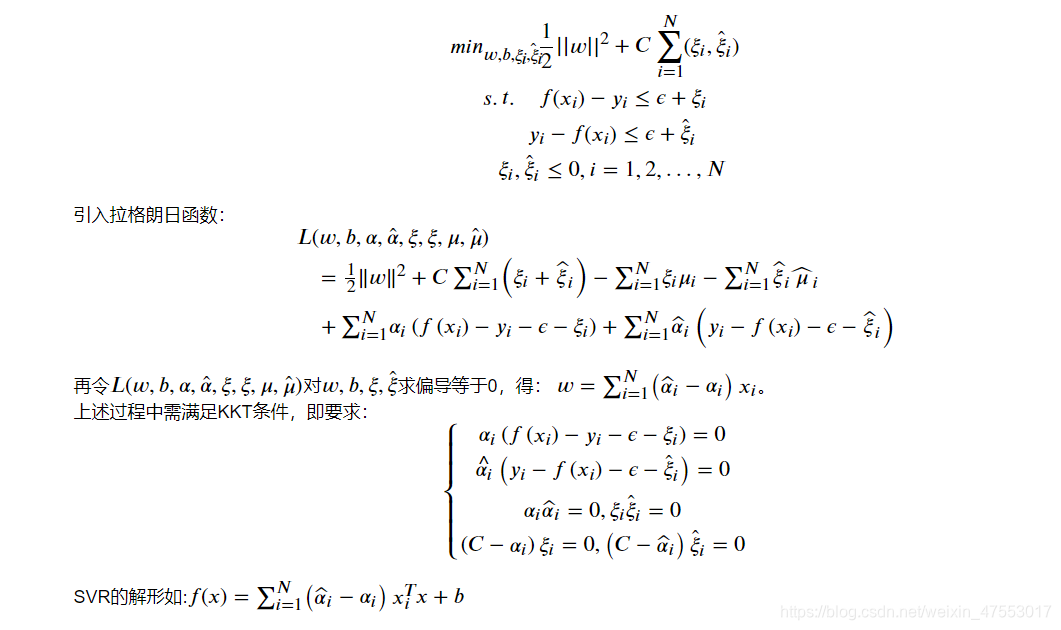















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











