







👉目录
1 概述
2 编译与产物
3 内存布局
4 内存管理
5 跨语言调用
6 当前的主要问题
7 未来与展望
8 小结
Kotlin Native 是 Kotlin 多平台生态的关键一环,也是 Kotlin 开发者突破自身发展瓶颈的重要方向。本文依据 Kotlin Native 的源码,结合作者在运用 Kotlin Native 开发多平台应用的实战经验,详细为大家解读 Kotlin Native 在编译时和运行时的实现细节和实践技巧。本文由腾讯 PCG 代码委员会出品,可能是你在全网能看到的关于 Kotlin Native 分析最全面的干货文章。
作者简介:霍丙乾 bennyhuo,腾讯高级工程师,Google 开发者专家(Kotlin 方向),《深入理解 Kotlin 协程》、《深入实践 Kotlin 元编程》 作者。
关注腾讯云开发者,一手技术干货提前解锁👇
01
概述
1.1 Kotlin 多平台的发展历程
Kotlin 是一门静态类型的语言,最早以 100% 兼容 Java 而闻名。从 2016 年 2 月正式发布以来,Kotlin 在很长一段时间里都是作为更好的 Java 或者一门更好的 JVM 语言而受到开发者喜爱的。
然而,Kotlin 团队的梦想从一开始就不止步于 JVM。事实上,从发布于 2012 年的 [Kotlin M2 版本](https://blog.jetbrains.com/kotlin/2012/06/kotlin-m2-candidate/#js)开始,Kotlin 编译器就支持将 Kotlin 编译成 JavaScript,运行在 JavaScript 可以运行的任何环境中,这就是 Kotlin JS。Kotlin JS 最终在 2017 年 3 月的 [Kotlin 1.1](https://blog.jetbrains.com/kotlin/2017/03/kotlin-1-1/) 中稳定发布。不过由于当时 Kotlin JS 的工具链仍然不完善,甚至在后来还出现了较大的设计调整,因此早期的 Kotlin JS 并没有引起多数开发者的注意。
接着很快在 2017 年 4 月, Kotlin 团队就公开了 Kotlin Native 的第一个预览版本和后续计划,这将成为 Kotlin 摆脱 JVM 的束缚和 Java 的影响的重要一步。如果有人说 Kotlin 就是 Java 的语法糖,从这一天开始,我们就可以告诉他,Kotlin JVM 只是 Kotlin 支持的目标平台之一。
Kotlin 1.1 是存续时间最短的一个版本,因为 Kotlin 1.2 在同一年的 12 月就正式发布了。Kotlin 多平台特性(Kotlin Multiplatform,KMP)从 [1.2](https://blog.jetbrains.com/kotlin/2017/11/kotlin-1-2-released/) 开始预览,直到 6 年后的 [1.9.20](https://blog.jetbrains.com/kotlin/2023/11/kotlin-1-9-20-released/) 才进入稳定阶段。
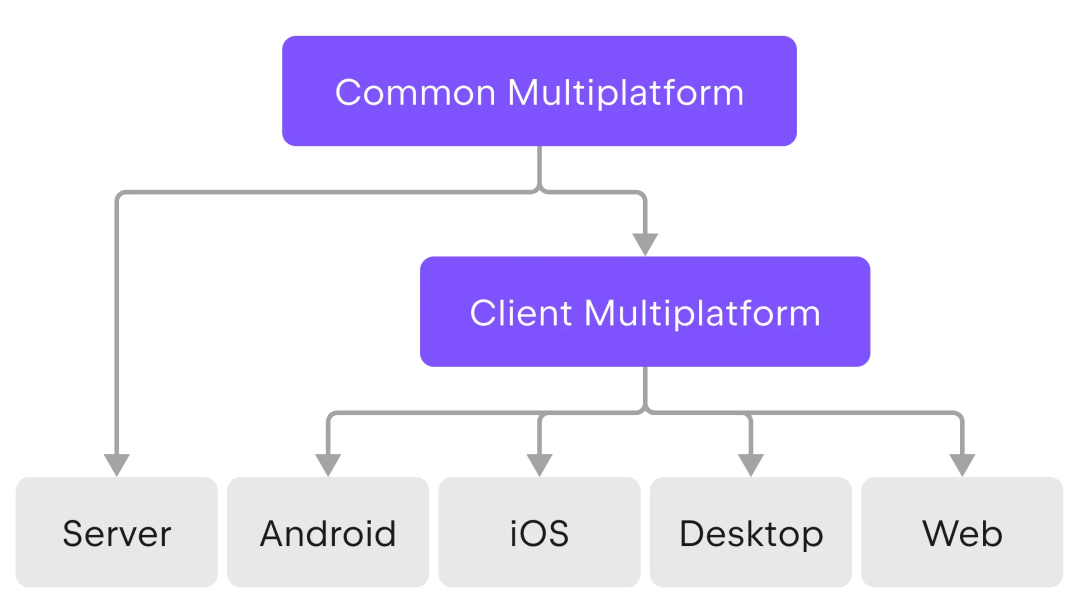
Kotlin 对多平台的支持,彻底将 Kotlin 转型为一门多平台静态类型的语言。Kotlin Native 运行时的不断完善和目标平台的不断扩展成为最近几年里 Kotlin 最重要的迭代路径之一。
1.2 Kotlin Native 简介
Kotlin Native 是指将 Kotlin 源代码编译为目标平台的本地二进制可执行程序或库,以类似于 C/C++、Go 等语言的方式运行在目标平台的原生环境中。与 Kotlin JVM 和 Kotlin JS 相比,Kotlin Native 在语言本身上没有什么特殊之处,只是目标产物不同而已。
Kotlin Native 支持多种平台,包括 Android(NDK)、iOS、Linux、Windows(MinGW)、macOS 等,可以覆盖绝大多数消费终端的开发场景。事实上,在早期的版本中,WebAssembly 也曾是 Kotlin Native 支持的平台之一,不过 Kotlin WASM 的后端编译器已经基于新版架构重写,成为与 Kotlin Native 并列的独立目标平台。
Kotlin Native 运行时提供了内存垃圾回收机制,使得 Kotlin Native 程序的开发体验与 Kotlin JVM 一致。Kotlin Native 还提供了与 C、Objective-C 的互调用接口,可以安全方便地实现跨语言调用,进而充分利用平台的原生能力。
本文将基于 Kotlin 2.0.0 版本从编译时和运行时两个角度介绍 Kotlin Native 的关键技术和核心特性。
02
编译与产物
Kotlin 编译器包含两个部分,即负责将 Kotlin 源代码编译成 Kotlin IR 的前端部分(Front-end)和将 Kotlin IR 编译成目标文件的后端部分(Back-end)。Kotlin Native 的编译流程如图所示:
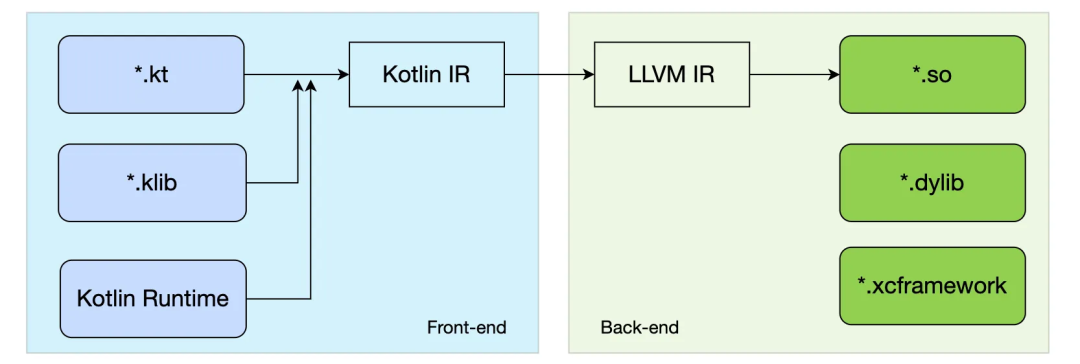
接下来我们用一个非常简单的例子来展示各阶段的编译结果。
2.1 前端编译与 Kotlin IR
我们准备将这段非常简单的 Kotlin 源代码编译成一个 macOS 平台的可执行程序:
fun main() {
println("Hello World!!")
}经过前端编译之后生成的 Kotlin IR 结构如下:
FILE fqName:<root> fileName:Main.kt
FUN name:main visibility:public modality:FINAL <> () returnType:kotlin.Unit
BLOCK_BODY
CALL 'public final fun println (message: kotlin.Any?): kotlin.Unit declared in kotlin.io' type=kotlin.Unit origin=null
message: CONST String type=kotlin.String value="Hello World!!"Kotlin IR(Kotlin Intermediate Representation)是 Kotlin 源码经过 Kotlin 前端编译器的语法解析、语义分析处理之后得到抽象语法树,并对抽象语法树进一步转换之后得到的只对目标代码的生成有意义的语法树。Kotlin IR 是前端编译器的产物,也是后端编译器的输入,它可以有效地屏蔽目标平台差异对 Kotlin 源代码的编译处理的影响。由此可见,这部分编译逻辑对于 Kotlin 的所有目标平台都是通用的。
2.2 后端编译与 LLVM IR
Kotlin Native 编译器会将 Kotlin IR 编译成 LLVM IR。我们将编译过程中生成的 LLVM bitcode 文件转换成 LLVM IR,摘取其中最核心的部分,如下所示:
@main = alias i32 (i32, i8**), i32 (i32, i8**)* @Konan_main
define i32 @Konan_main(...) #11 {
%3 = tail call i32 @Init_and_run_start(...)
ret i32 %3
}
define i32 @Init_and_run_start(...) ... {
...
; 创建 Kotlin Native 运行时
tail call void @Kotlin_initRuntimeIfNeeded() #9
...
; 注意这里调用 @Konan_start
%11 = invoke i32 @Konan_start(...) ...
...
; 销毁 Kotlin 运行时
call void @Kotlin_shutdownRuntime()
...
}
define internal i32 @Konan_start(...) ... {
...
entry:
; 调用开发者定义的 main 函数
invoke void @"kfun:#main(){}"() #57 ...
...
}
define internal void @"kfun:#main(){}"() #6 !dbg !14199 {
...
entry:
; 调用 println("Hello World!!")
call void @"kfun:kotlin.io#println(kotlin.Any?){}"(...), ...
...
}不难发现,在 main 函数中调用 println,参数是常量 @1012,类型是 ArrayHeader,大小是 13 x i16,其中 i16 就是 16 位的整型,即 13 x 16 bit,共 26 个字节。常量 @1012 的值如下:
@1012 = internal unnamed_addr constant {
...,
[13 x i16] [
i16 72, i16 101, i16 108, i16 108, i16 111,
i16 32, i16 87, i16 111, i16 114, i16 108,
i16 100, i16 33, i16 33
]
}由于 Kotlin 的字符是采用 UTF-16 编码的,每个字符占两个字节,因此 13 个 i16 正好对应于 13 个字符。
LLVM IR 可以直接对应到最终可执行程序中的指令,因此我们可以非常完整地观察看到 Kotlin Native 的 main 函数调用前后分别做了哪些准备和清理工作。此外,阅读 LLVM IR 也对于我们理解和认识 Kotlin 对象的内存布局有很大的帮助。
最后,LLVM 编译器会将 LLVM IR 编译成对应平台的可执行程序或库,至此 Kotlin Native 的编译工作就全部完成了。
03
内存布局
3.1 基本数值类型的内存布局
基本数值类型的内存布局与 C/C++ 一致,在不涉及装箱操作时,占用内存的大小就是对应数值类型的定义的大小。例如 Int 类型占 4 字节,Double 类型占 8 字节。例如:
val a = 1
var b: Float = 2f
var c: Double = a * 2 + b.toDouble()
val d = 'a'
val e: Short = 28这段程序中包含 Char、Short、Int、Float、Double 五种基本数值类型的变量,它们的内存占用如图所示:
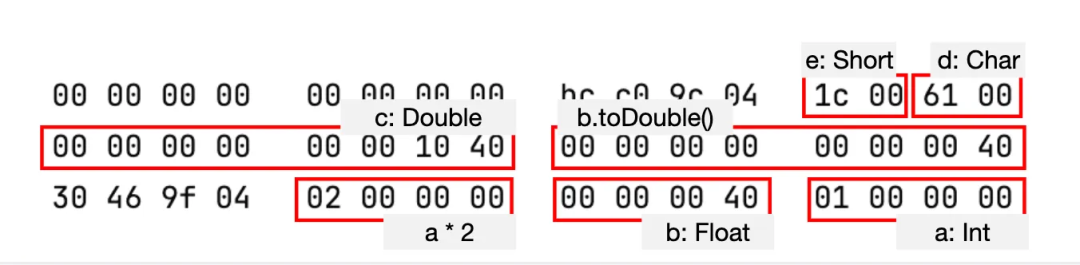
图中内存地址从上往下递增。由于这些变量的内存在函数调用栈上开辟,先声明的变量在栈底,因而地址比后声明的变量更大。
3.2 对象的内存布局
与 Java 类似,Kotlin 也存在对基本数值类型的装箱和拆箱的设计。不同之处在于,Kotlin 的装箱和拆箱是隐式的,开发者无须在代码编写时关心装箱和拆箱,编译器会根据实际的使用情况来决定是否需要装箱并保证尽可能不装箱。尽管与 Kotlin JVM 在实现上有不少差异,但显然 Kotlin Native 也存在装箱和拆箱。
例如:
val value: Double = 4.0
println(value)value 作为基本数值类型,在栈上只占用 8 字节。随后我们将其传入 println 中,Kotlin 编译器就会生成相应的装箱代码,在堆上开辟一个 Double 类型的对象作为 println 的实参,这个对象占 24 字节的内存。
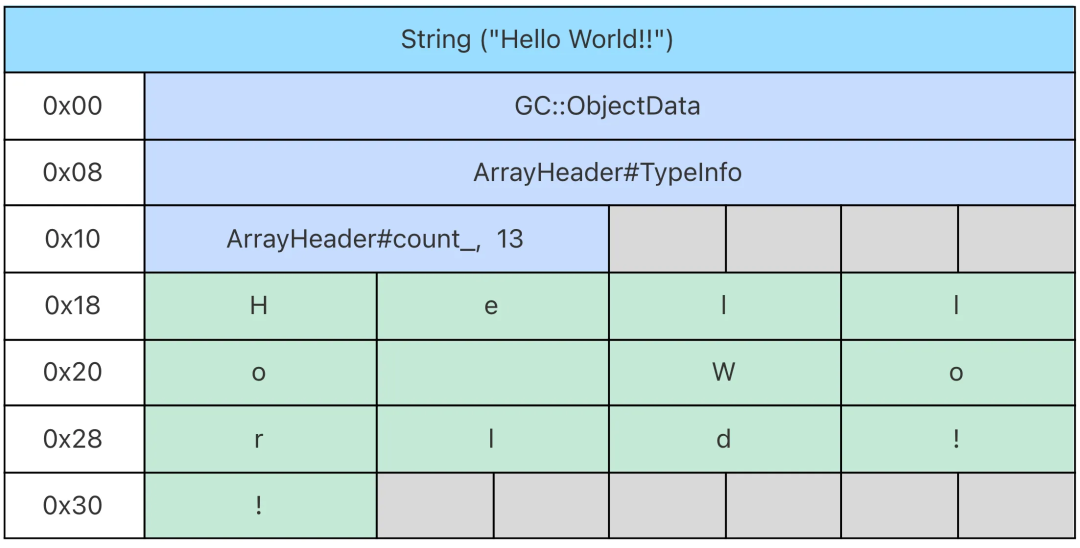
堆内存中开辟的对象主要包含三个部分,即堆对象链表节点 GC::ObjectData,对象头 ObjHeader,对象体。其中:
堆对象链表节点 GC::ObjectData 用于内存回收时的标记阶段,包含一个指向下一个对象的 GC::ObjectData 的指针,占 8 字节。
对象头 ObjHeader 包含了对象的类型信息 TypeInfo 的指针,占 8 字节,它的定义如下:
struct ObjHeader {
TypeInfo* typeInfoOrMeta_;
...
}对象体就是对象的值本身,包含对象的所有字段的值。
示例中 Double 对象的对象体就是 Double 数值 4.0,占 8 字节。Double 在堆内存中的内存布局示意如下:

接下来我们再来看一个稍微复杂一点儿的例子。
data class User(val id: Int, val name: String)
data class Repository(val id: Long, val name: String, val owner: User)
---
val user = User(1, "bennyhuo")
val repository = Repository(42, "kotlin-ir-printer", user)
println(repository)这段代码主要涉及到 repository、user 以及两个字符串,运行时的内存如下图所示:
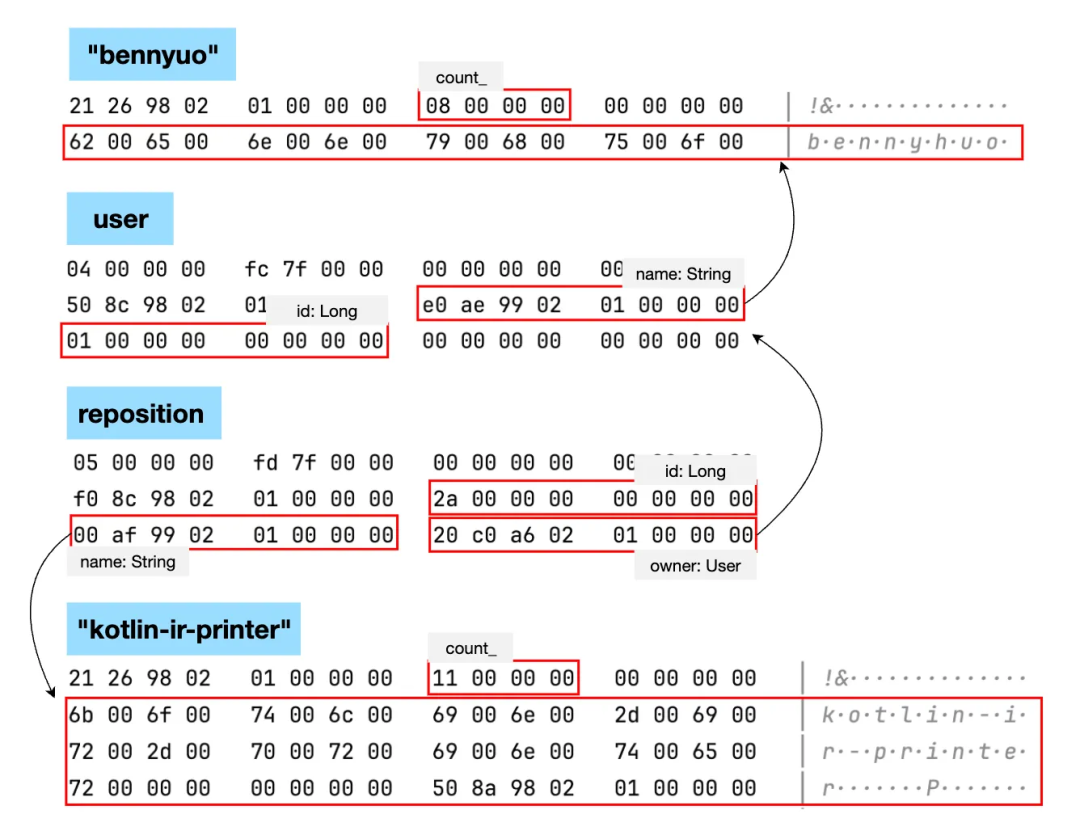
不难看出,对象的字段是在对象体部分依次分配的。
%"kclassbody:User#internal" = type <{ %struct.ObjHeader, %struct.ObjHeader*, i32 }>
%"kclassbody:Repository#internal" = type <{ %struct.ObjHeader, i64, %struct.ObjHeader*, %struct.ObjHeader* }>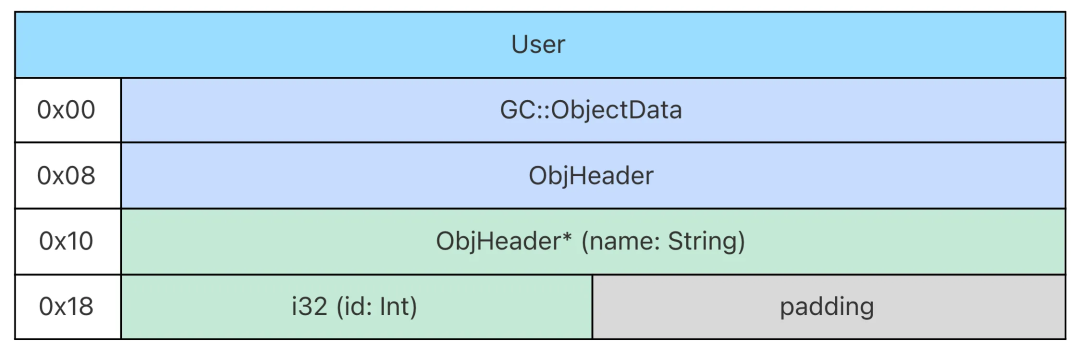
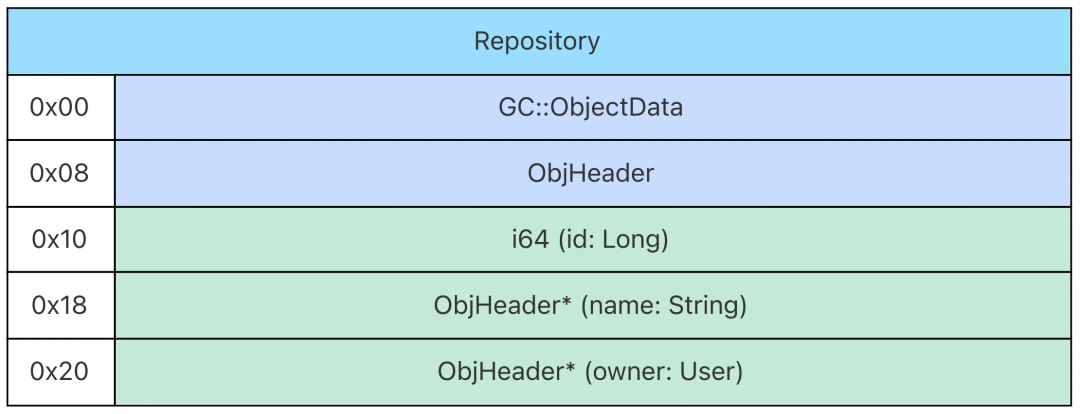
注意,这里只是类型的内存布局定义,因此不包含 GC::ObjectData 字段。
此外,User 类的 id 和 name 字段在编译之后顺序发生了变化,这实际上是编译器针对对象内存布局进行字段对齐优化之后的结果。如果我们想要整体禁止这项优化,可以在编译时传入 -Xbinary=packFields=false;如果想要单独禁止对某个类进行对齐优化,可以使用 @NoReorderFields 注解对这个类进行标注。不过,由于 @NoReorderFields 是 internal 的注解,因此使用时还需要压制相应的可见性报错,例如:
@file:Suppress("INVISIBLE_REFERENCE", "INVISIBLE_MEMBER")
import kotlin.native.internal.NoReorderFields
@NoReorderFields
data class User(val id: Int, val name: String) 3.3 数组的内存布局
数组也是对象,它的对象体其实就是数组的值,它的对象头除了类型信息以外,还包含数组元素的个数。即:
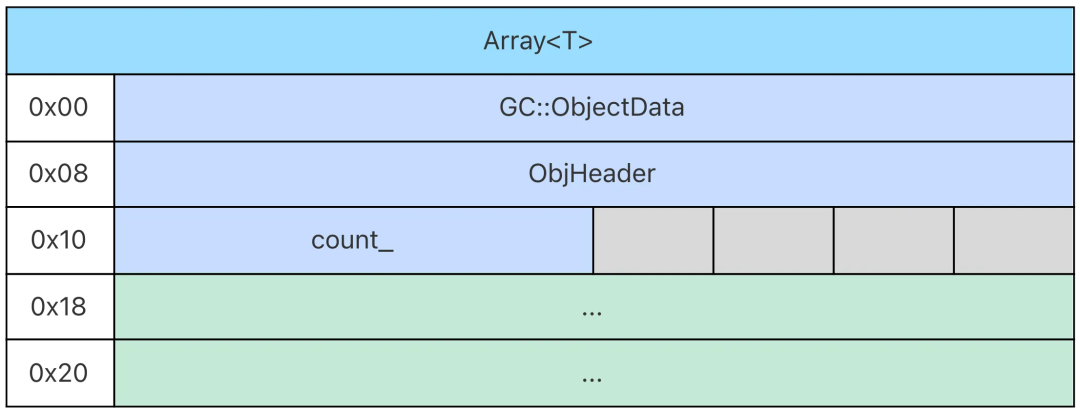
数组元素的大小由数组元素的类型决定,因此数组的对象体的大小其实就是 sizeof(T) * count_,其中,sizeof(T) 定义在数组元素的类型信息当中。ObjHeader 和 count_ 合起来构成了 ArrayHeader,它的定义如下:
struct ArrayHeader {
TypeInfo* typeInfoOrMeta_;
uint32_t count_;
...
};字符串也是数组类型,我们可以把字符串类型理解为 Array<Char>。接下来我们以字符串为例详细介绍数组的内存布局。
在编译与产物一节中我们已经见识到了 Kotlin 字符串常量的 LLVM IR,字符串常量 "Hello World!!" 编译后生成的完整 LLVM IR 如下:
@1012 = internal unnamed_addr constant {
%struct.ArrayHeader, [13 x i16]
} {
%struct.ArrayHeader {
%struct.TypeInfo* bitcast (
i8* getelementptr (i8, i8* bitcast ({ %struct.TypeInfo, [3 x i8*] }* @"kclass:kotlin.String" to i8*), i32 1) to %struct.TypeInfo*
),
i32 13
},
[13 x i16] [
i16 72, i16 101, i16 108, i16 108, i16 111, i16 32, i16 87,
i16 111, i16 114, i16 108, i16 100, i16 33, i16 33
]
}为了方便阅读,我们在这里添加了换行和缩进。可以看到,字符串对象的内存主要包含 ArrayHeader 和一个 i16 整型的数组,这里的 i16 实际上就对应于 Kotlin 的 Char 类型。它的内存布局如下表所示:
运行时的内存信息如下图所示:

3.4 类型信息 TypeInfo
编译器在编译时根据 Kotlin IR 中的类型信息生成 TypeInfo 。
TypeInfo 的定义如下,其中 writableInfo_ 用于支持与 Objective-C 的互调用:
struct TypeInfo {
const TypeInfo* typeInfo_;
const ExtendedTypeInfo* extendedInfo_;
uint32_t unused_;
int32_t instanceSize_;
const TypeInfo* superType_;
const int32_t* objOffsets_;
int32_t objOffsetsCount_;
const TypeInfo* const* implementedInterfaces_;
int32_t implementedInterfacesCount_;
int32_t interfaceTableSize_;
InterfaceTableRecord const* interfaceTable_;
ObjHeader* packageName_;
ObjHeader* relativeName_;
int32_t flags_;
ClassId classId_;
#if KONAN_TYPE_INFO_HAS_WRITABLE_PART
WritableTypeInfo* writableInfo_;
#endif
const AssociatedObjectTableRecord* associatedObjects;
void (*processObjectInMark)(void* state, ObjHeader* object);
uint32_t instanceAlignment_;
...
};以 String 为例,运行时 String 的 TypeInfo 的内存信息如下:
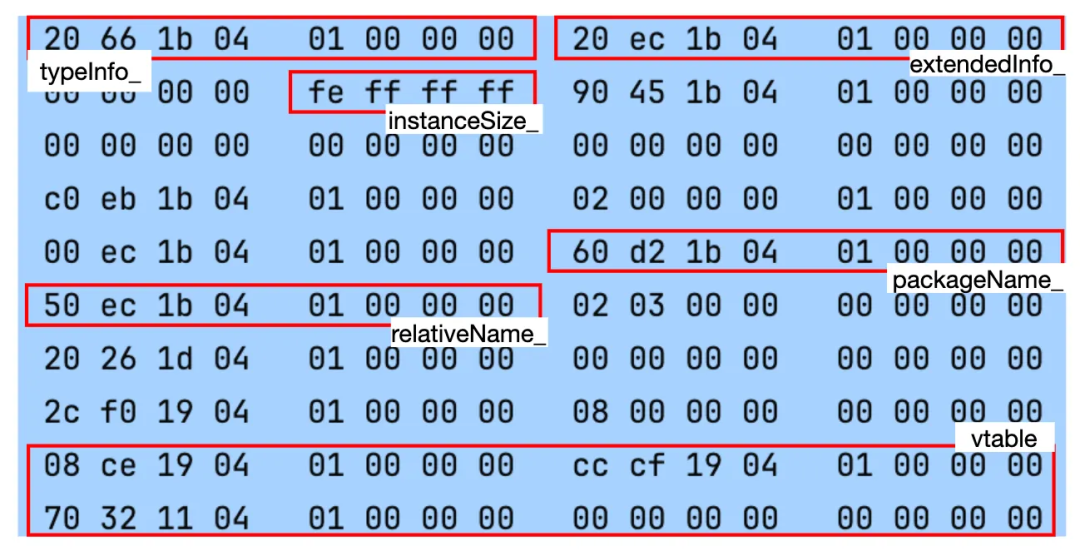
注意,数组和字符串的 instanceSize_ 字段是元素大小的相反数,例如这里字符串的元素大小为 2 字节,instanceSize_ 的值就是 0xFFFFFFFE,也就是 -2。
packageName_ 是类的包名,这里是 kotlin;relativeName_ 是类型的类名,这里是 String。在调试 Kotlin Native 的源码时,我们可以通过打印这两个字段来确认 TypeInfo 对应的实际类型。顺便提一句,KClass 的 simpleName 和 qualifiedName 就是基于这两个字段实现的:
internal class KClassImpl<T : Any>(private val typeInfo: NativePtr) : KClass<T> {
override val simpleName: String?
get() = getRelativeName(typeInfo, true)?.substringAfterLast('.')?.substringAfterLast('$')
override val qualifiedName: String?
get() {
val packageName = getPackageName(typeInfo, true) ?: return null
val relativeName = getRelativeName(typeInfo, true) ?: return null
return if (packageName.isEmpty()) relativeName else "$packageName.$relativeName"
}
...
}vtable 的含义与 C++ 相同,用于存储虚函数的地址。与 C++ 的不同之处在于,在 Kotlin 当中,open 的函数都可以理解为虚函数,子类覆写父类的函数地址都需要存储于 vtable 中。接下来我们简单介绍一下虚函数的生成方式。
在 Kotlin 中,只有抽象类和密封类的类型信息不包含 vtable,因为我们无法实例化这些类型。对于可以被实例化的类型,其 vtable 包含以下内容:
父类的 vtable,如果当前类型中覆写了父类的函数,将父类对应的函数替换成覆写的函数。
当前类中可以被覆写的函数。
例如:
class A {
fun a() { }
override fun toString(): String {
return super.toString()
}
}它的 vtable 包含以下函数:
kfun:kotlin.Any#equals(kotlin.Any?){}kotlin.Boolean
kfun:kotlin.Any#hashCode(){}kotlin.Int
kfun:A#toString(){}kotlin.String这三个函数实际上是继承自 Any 的 vtable,注意 toString 被替换成了 A 当中覆写的版本。
再例如:
open class B {
open fun b1() {}
open fun b2() {}
fun b3() {}
}
open class C : B() {
final override fun b1() {}
}
class D : B()
class E : C() {
override fun b2() {}
}类 B 当中 b1、b2 可以被覆写,b3 不可被覆写。B 的 vtable 包含如下函数:
kfun:kotlin.Any#equals(kotlin.Any?){}kotlin.Boolean
kfun:kotlin.Any#hashCode(){}kotlin.Int
kfun:kotlin.Any#toString(){}kotlin.String
kfun:B#b1(){}
kfun:B#b2(){}类 C 中覆写了 b1,其他与 B 一致:
kfun:kotlin.Any#equals(kotlin.Any?){}kotlin.Boolean
kfun:kotlin.Any#hashCode(){}kotlin.Int
kfun:kotlin.Any#toString(){}kotlin.String
kfun:C#b1(){}
kfun:B#b2(){}类 D 没有覆写任何函数,vtable 与 B 一致:
kfun:kotlin.Any#equals(kotlin.Any?){}kotlin.Boolean
kfun:kotlin.Any#hashCode(){}kotlin.Int
kfun:kotlin.Any#toString(){}kotlin.String
kfun:B#b1(){}
kfun:B#b2(){}类 E 覆写了 b2,其他与 C 一致:
kfun:kotlin.Any#equals(kotlin.Any?){}kotlin.Boolean
kfun:kotlin.Any#hashCode(){}kotlin.Int
kfun:kotlin.Any#toString(){}kotlin.String
kfun:C#b1(){}
kfun:E#b2(){}04
内存管理
Kotlin Native 对象的内存管理方式与 Java 对象的类似,也采用垃圾回收机制实现对象内存的自动管理。
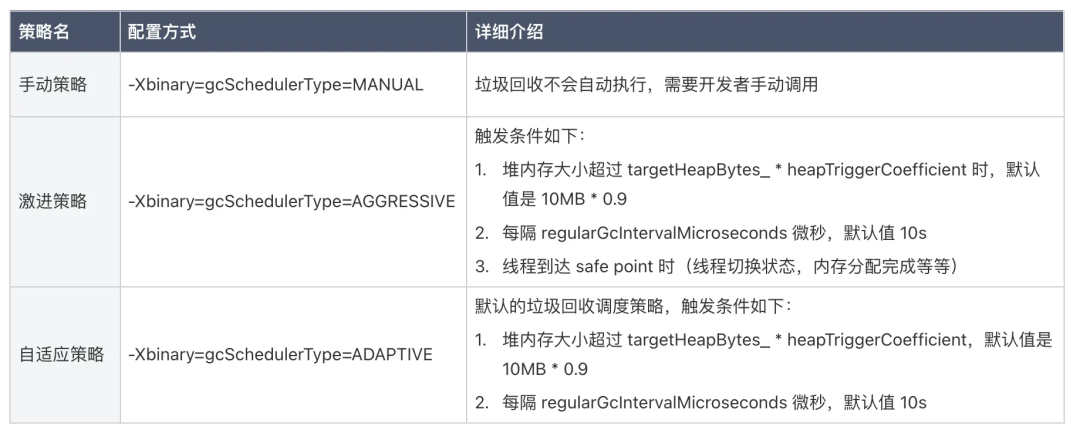
4.1 内存回收调度策略
Kotlin Native 运行时的内存垃圾回收的调度策略一共有三种,如下表:
4.2 内存垃圾回收算法
内存垃圾回收的算法共有四种,如下表:


4.3 内存分配方式
内存的分配方式共有三种,如下表:
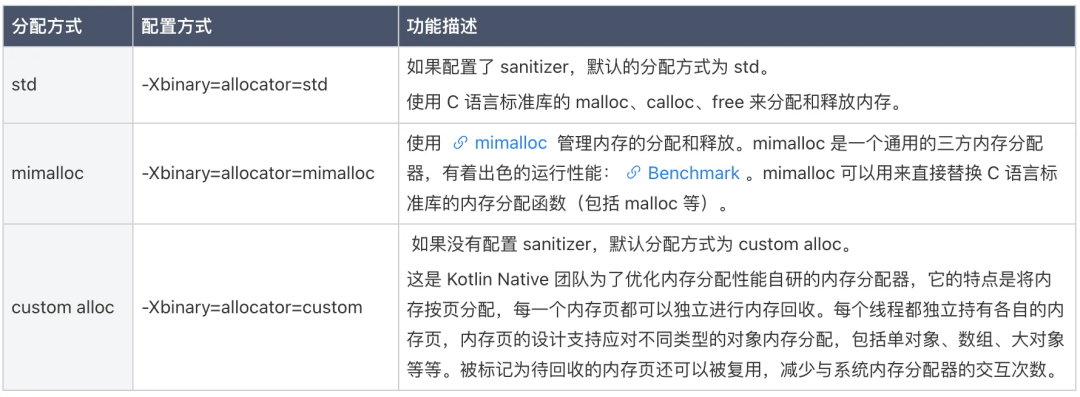
内存的默认分配方式会随着内存回收算法和其他配置发生变化。在 2.0 以前的一段时间里,默认的内存分配方式会优先选择 mimalloc,如果内存回收算法是 ptms,则会选择 custom alloc。如果生产环境中实测某一种分配方式有更高的性能,建议直接在项目配置中显式配置这种分配方式,不要依赖默认配置。
Kotlin Native 内存管理机制仍然有不小的提升空间,减少 GC 带来的程序停顿是内存管理机制提升的重要目标。除了可以持续优化内存分配方式和回收算法以外,Kotlin Native 实际上也可以推出分代内存管理机制,届时 Kotlin Native 在应对大量的浮动内存时将更加游刃有余。
05
跨语言调用
Kotlin Native 提供了与 C 和 Objective-C 的互调用机制,互调用的基本用法可以参见:https://kotlinlang.org/docs/native-c-interop.html和 https://kotlinlang.org/docs/native-objc-interop.html,本节将以此为基础,探讨一下 Kotlin Native 与 C、Objective-C 的互调用的设计细节。
5.1 符号关系
要实现与其他语言的互调用,我们需要解决两个问题:
对象的内存布局。
函数的名字修饰。
前面已经讨论过,Kotlin Native 对象的内存布局与 C 的结构体的内存布局没有概念上的差异,我们完全可以以 C 语言的视角去理解 Kotlin Native 对象的内存。 因此,本节我们将专注于探讨函数的名字修饰。
5.1.1 导出 C 符号
函数的名字修饰,主要是指编译器在编译时对函数名字的处理,经过修饰之后,函数对应的符号名通常与函数名不同。函数的名字修饰主要用于解决符号冲突,除函数名以外,修饰之后的符号名也会包含命名空间的信息,如果支持函数重载,还需要包含参数的类型信息。C++ 的名字修饰就是如此,例如:
namespace NS {
void func() {}
void func(int, float) {}
};使用 GCC 编译之后的符号为:
_ZN2NS4funcEv
_ZN2NS4funcEif修饰规则如下表:
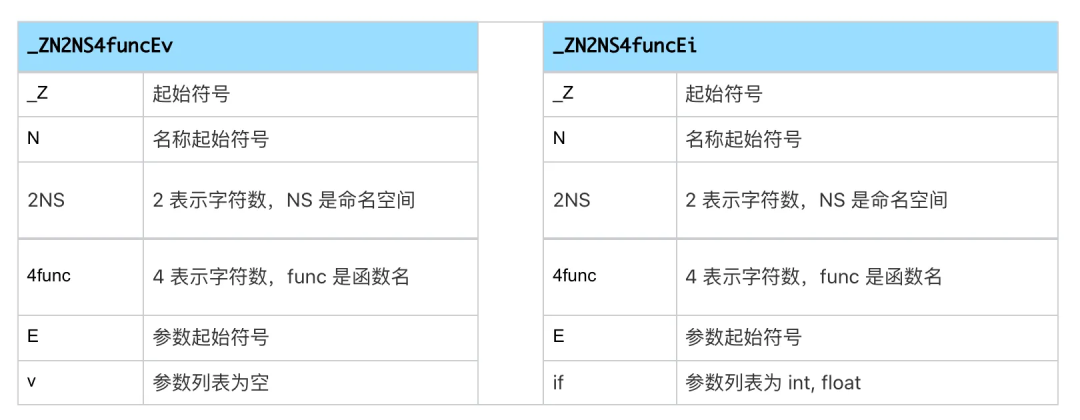
Kotlin 也支持命名空间(包名)和函数重载,因此函数名在编译时也存在名字修饰。例如:
package com.tencent.kotlin.sample
fun func() { }
fun func(i: Int, f: Float) { }编译之后生成的符号如下:
_kfun:com.tencent.kotlin.sample#func(){}
_kfun:com.tencent.kotlin.sample#func(kotlin.Int;kotlin.Float){}与 GCC 编译器为 C++ 实现的名字修饰不同,Kotlin 的修饰规则非常清晰易懂。不过,问题也是很明显的,我们要想与 C 语言互调用,生成的符号必须让 C 语言能够理解。
C++ 通过使用 extern "C" 修饰函数使得函数本身采用 C 语言的方式生成符号,例如:
extern "C" void func() {}这样函数 func 经过编译之后生成的符号名就是 func。
Kotlin 也提供了类似的机制,即 @CName 注解。
@CName("func")
fun func() { }编译时,Kotlin 编译器就会为 @CName 注解标注的 Kotlin 函数 func 生成一个名为 func 的函数,我们可以在 C 语言当中直接调用这个函数。不过需要注意的是,C 语言当中可以直接调用的 func 函数不是我们在 Kotlin 当中定义的 func 函数,因为外部调用 Kotlin 函数意味着代码的执行权转移到了 Kotlin 运行时,而 Kotlin 运行时需要初始化,因此最终生成的 func 函数实际上是对 Kotlin 当中的 func 函数的一层封装,如下代码所示,_konan_function_0 才是 Kotlin 中的 func 函数:
extern "C" void _konan_function_0();
RUNTIME_USED extern "C" void func() {
Kotlin_initRuntimeIfNeeded();
ScopedRunnableState stateGuard;
FrameOverlay* frame = getCurrentFrame();
try {
_konan_function_0();
} catch (...) {
SetCurrentFrame(reinterpret_cast<KObjHeader**>(frame));
HandleCurrentExceptionWhenLeavingKotlinCode();
}
} 5.1.2 导出 Objective-C 符号
Kotlin 与 Objective-C/Swift 互调用时,需要导出 Objective-C/Swift 符号。例如:
Funcs.kt
fun func() { }
fun func(i: Int, f: Float) { }
fun func2(i: Int, f: Float) { }如果模块名是 framework,则编译之后生成的符号如下:
__attribute__((swift_name("FuncsKt")))
@interface FrameworkFuncsKt : FrameworkBase
+ (void)func __attribute__((swift_name("func()")));
+ (void)funcI:(int32_t)i f:(float)f __attribute__((swift_name("func(i:f:)")));
+ (void)func2I:(int32_t)i f:(float)f __attribute__((swift_name("func2(i:f:)")));
@end请注意,这里生成的类名是 FrameworkFuncsKt,其中 Framework 对应于模块名 framework,FuncsKt 对应于文件名 Funcs.kt,__attribute__((swift_name("func(i:f:)"))) 则为函数指定了 Swift 函数名,方便在 Swift 中调用。
这里采用的是默认的映射规则,生成的 Objective-C 函数的函数名为:
Kotlin 函数:func(i: Int, f: Float)
Objective-C 符号:<kotlin function name>[<1st param name#capitalize>:<2nd param name>:...]
Objective-C 符号:func I : f :
Swift 符号:<kotlin function name>([<1st param name>:<2nd param name>:...])
Swift 符号:func ( i : f : )我们也可以使用 @ObjcName 注解来自定义生成的符号名,以下例子来自官方文档https://kotlinlang.org/docs/native-objc-interop.html#change-declaration-names:
@ObjCName(swiftName = "MySwiftArray")
class MyKotlinArray {
@ObjCName("index")
fun indexOf(@ObjCName("of") element: String): Int = 1
}如果模块名为 framework,则编译生成的符号如下:
__attribute__((objc_subclassing_restricted))
__attribute__((swift_name("MySwiftArray")))
@interface FrameworkMyKotlinArray : FrameworkBase
- (instancetype)init __attribute__((swift_name("init()"))) __attribute__((objc_designated_initializer));
+ (instancetype)new __attribute__((availability(swift, unavailable, message="use object initializers instead")));
- (int32_t)indexOf:(NSString *)of __attribute__((swift_name("index(of:)")));
@end
这里类名的 @ObjCName 注解只指定了 swiftName,因此它只会对生成的 Swift 符号产生影响。我们稍作调整:
@ObjCName( "MySwiftArray")
class MyKotlinArray {
@ObjCName("index")
fun indexOf(@ObjCName("of") element: String): Int = 1
}则编译结果如下:
__attribute__((objc_subclassing_restricted))
__attribute__((swift_name("MySwiftArray")))
@interface FrameworkMySwiftArray : FrameworkBase
- (instancetype)init __attribute__((swift_name("init()"))) __attribute__((objc_designated_initializer));
+ (instancetype)new __attribute__((availability(swift, unavailable, message="use object initializers instead")));
- (int32_t)indexOf:(NSString *)of __attribute__((swift_name("index(of:)")));
@end注意此时 Objective-C 的类名也发生了变化:

注解中还有一个 exact 参数,我们试着再调整一下代码:
@ObjCName("MySwiftArray", exact = true)
class MyKotlinArray {
@ObjCName("index")
fun indexOf(@ObjCName("of") element: String): Int = 1
}最终生成的符号如下:
__attribute__((objc_subclassing_restricted))
@interface MySwiftArray : FrameworkBase
- (instancetype)init __attribute__((swift_name("init()"))) __attribute__((objc_designated_initializer));
+ (instancetype)new __attribute__((availability(swift, unavailable, message="use object initializers instead")));
- (int32_t)indexOf:(NSString *)of __attribute__((swift_name("index(of:)")));
@end注意此时 Objective-C 的类名不再添加模块名前缀:

事实上, exact 参数会强制生成的符号名为注解中声明的名字,否则最终生成的类名前会增加模块名和外部类的前缀。
作为对比,如果不加注解,默认情况下生成的符号如下:
__attribute__((objc_subclassing_restricted))
__attribute__((swift_name("MyKotlinArray")))
@interface FrameworkMyKotlinArray : FrameworkBase
- (instancetype)init __attribute__((swift_name("init()"))) __attribute__((objc_designated_initializer));
+ (instancetype)new __attribute__((availability(swift, unavailable, message="use object initializers instead")));
- (int32_t)indexOfElement:(NSString *)element __attribute__((swift_name("indexOf(element:)")));
@end
5.1.3 Objective-C 的符号冲突
在前面的分析中,我们看到了 C++ 的命名空间和 Kotlin 的包名对符号名字修饰的影响。现代编程语言大多数有命名空间的概念,命名空间一方面可以提供可见性约束,另一方面也能有效地解决符号冲突的问题。
不过,Objective-C 没有命名空间的概念,因此 Kotlin 类、函数在导出 Objective-C 符号时就会面临符号冲突的问题。
例如在模块 frameowork 中定义以下类和函数:
// com/bennyhuo/kotlin/A.kt
package com.bennyhuo.kotlin
class A
fun a() {}
----
// com/bennyhuo/kotlin/native/A.kt
package com.bennyhuo.kotlin.native
class A
fun a() {}尽管两个同名的类 A 和两个同名的顶级函数 a 分别属于不同的包,但编译之后导出的 Objective-C 符号却会面临冲突的问题。Kotlin 编译器为了解决这个问题,默认会为编译时后处理的符号名添加下划线来避免冲突,因此上述类和函数编译之后的符号为:
__attribute__((swift_name("AKt")))
@interface FrameworkAKt : FrameworkBase
+ (void)a __attribute__((swift_name("a()")));
+ (void)a_ __attribute__((swift_name("a_()")));
@end
__attribute__((objc_subclassing_restricted))
__attribute__((swift_name("A")))
@interface FrameworkA : FrameworkBase
...
@end
__attribute__((objc_subclassing_restricted))
__attribute__((swift_name("A_")))
@interface FrameworkA_ : FrameworkBase
...
@end在这里,Kotlin 通过为其中一个类的类名添加下划线以实现符号冲突的避让。
除了全局符号冲突以外,还有同名属性和函数的冲突。这类符号冲突事实上也存在于 Kotlin 与 Java 互调用的情况,例如:
// A.kt
interface A {
fun a()
}
interface B {
fun a(): String
}我们用一个 Java 类实现这两个接口,就会出现下面的编译错误:
// Main.java
public class Main implements A, B {
@Override
public void a() {}
^^^^
e: 'a()' in 'Main' clashes with 'a()' in 'B'; attempting to use incompatible return type
}Java 编译器有能力对符号冲突做出判断,因此 Kotlin 编译器无需担心定义了同名函数的类或接口被同一个 Java 类实现或者继承。
而在 Objective-C 中,情况就变得有一些微妙了:
@protocol A <NSObject>
@required
-(void) a;
@end
@protocol B <NSObject>
@required
-(int) a;
@end我们定义了两个协议 A 和 B,并在其中定义了同名函数 a,两个函数的返回值类型不同。接下来我们定义一个类实现这两个协议,这两个函数 a 就会出现冲突:
@interface Main : NSObject<A, B>
@end
@implementation Main
- (void) a {
}
- (int) a {
^^^^^^^^^
e: Duplicate declaration of method 'a'
return 1;
}
@end删掉第二个函数 a,以下程序可以通过编译:
@implementation Main
- (void) a {
}
@end如果我们用 B 的指针指向 Main 的实例,程序就会在运行时出现未定义的行为:
Main* main = [[Main alloc] init];
id<B> b = main;
int value = [b a];
NSLog(@"%d\n", value);因此,Kotlin 在编译阶段对不同类和接口中可继承和覆写的同名函数进行了冲突检测,冲突的判断条件比较复杂,接下来我们用例子加以说明。
interface A {
fun a()
fun b(i: Int)
fun c(f: Float)
fun d(d: Double)
fun e(): Boolean
}
interface B {
fun a(): String
fun b(i: Int)
fun c(i: Int)
@ObjCName("d")
fun d0(d: Double)
val e: Boolean
}
open class C {
fun a(): Int = 1
open fun b(i: Int): String = "b"
fun c(i: Float) {}
private fun d(d: String) {}
}
class D {
fun a(): Int = 1
fun b(i: Int): String = "b"
fun c(f: Float) {}
fun d(d: Double) {}
}
fun A.b(i: Int) {}
fun B.b(i: Int) {}其中:
A#a、B#a 和 C#a 冲突,因为三者的返回值类型不同。需要说明的是,尽管在 Kotlin 中,C#a 是 final 函数,不能够被覆写,但导出到 Objective-C 符号之后,函数的 final 信息会丢失,因此 C#a 也是会存在符号冲突问题的,而 D#a 不会冲突,因为 D 不可以被继承。
A#b 和 B#b 不会冲突,因为它们的函数名、参数类型、返回值类型完全相同。C#b 与前面二者会产生冲突,因为 C#b 的返回值类型与它们不同。
A#c 的符号名为 cF:,B#c 的符号名为 cI:,符号名不同,因此二者不会冲突。不过,C#c 的符号名也为 cI:,但参数类型与 B#c 不同,因此会产生冲突。
A#d 和 B#d0 也会产生冲突,尽管二者对应的 Kotlin 函数名不同,但最终的符号名相同,这是一个非常微妙的 case,我们在稍后进一步展开讨论。C#d 是私有函数,不会导出符号,因此不会产生冲突。
A#e 和 B#e、C#e 的 getter 会产生冲突,导致属性的 getter 被隐藏。B#e 和 C#e 两个属性也会冲突,因为类型不同。
最后的两个扩展函数 A#b 和 B#b 也会产生冲突,因为它们会被导出为基于 Kotlin 文件生成的类的两个静态函数。
接下来我们再举一个例子对前面提到的 A#d 与 B#d0 的冲突产生的原因进行进一步分析:
interface A {
fun a()
}
interface B {
@ObjCName("a")
fun b()
}在这个例子中,尽管 A#a 与 B#b 的参数列表和返回值类型完全相同,但由于 B#b 通过 @ObjcName 修改符号名为 a,因此产生了冲突。导出的符号如下:
__attribute__((swift_name("A")))
@protocol FrameworkA
@required
- (void)a __attribute__((swift_name("a()")));
@end
__attribute__((swift_name("B")))
@protocol FrameworkB
@required
- (void)a_ __attribute__((swift_name("a_()")));
@end这个冲突判断的条件确实有些令人费解,因为导出的 Objective-C 符号已经通过 @ObjcName 指定,Kotlin 函数名对于 Objective-C 是不可见的。不过情况并没有想象中的简单,如果我们在 Kotlin 中用一个类 C 去实现这两个接口,就会出现下面的情况:
open class C : A, B {
override fun b() {}
override fun a() {}
}C#a 和 C#b 显然是两个不同的函数,但导出的 Objective-C 符号却会产生冲突,因为函数 b 已经在 B 中用 @ObjcName 修改为 a 了。类 C 导出的符号如下:
@interface FrameworkC : FrameworkBase <FrameworkA, FrameworkB>
...
- (void)a __attribute__((swift_name("a()")));
- (void)a_ __attribute__((swift_name("a_()")));
@end与类名相同,Kotlin 编译器在遇到属性、函数符号冲突时会默认通过为后参与编译的属性、函数的符号名添加下划线的方式来进行冲突避让。这样做的好处就是我们很少需要关心 Kotlin 符号的冲突问题,坏处就是我们在 Objective-C 中调用 Kotlin 导出的符号时总是需要小心因为冲突避让而产生的 Kotlin 模块的 ABI 变化。
我们可以通过配置编译参数 -Xbinary=objcExportIgnoreInterfaceMethodCollisions=true 来忽略定义在不同类和接口的同名属性和函数所产生的冲突,这样上述示例中 1~5 的冲突 case 可以被忽略。不过,忽略问题只会为项目的稳定性带来风险,Kotlin 编译器在 2.0 版本中新增了两个编译参数 -Xbinary=objcExportReportNameCollisions=true 和 -Xbinary=objcExportReportNameCollisions=true,可以对分别启用对符号冲突的 case 报警或者报错,方便我们在项目中尽早发现符号冲突的问题。以下是报警信息示例:
w: name is mangled when generating Objective-C header
(at fun a(): String defined in com.bennyhuo.kotlin.sample.B)
w: name is mangled when generating Objective-C header
(at fun d0(d: Double): Unit defined in com.bennyhuo.kotlin.sample.B)
w: name is mangled when generating Objective-C header
(at fun `<get-e>`(): Boolean defined in com.bennyhuo.kotlin.sample.B)导出的 Swift 符号的冲突判断条件与 Objective-C 符号类似,我们可以通过编译器参数 -Xbinary=objcExportDisableSwiftMemberNameMangling=true 来忽略 Swift 符号冲突。
事实上,Kotlin 在与 Java 的互调用时也会经常产生符号冲突,不过由于 Java 与 C、C++ 和Objective-C 的抽象层次不同,Java 编译器能够在编译时把绝大多数的冲突问题暴露出来,因此 Kotlin 没有提供相应的冲突避让策略。Swift 的编译器同样能有效地识别符号冲突的能力,因此理论上在生产环境中可以直接忽略 Swift 的符号冲突,依赖 Swift 编译器对冲突的符号进行检查。我们同样以前面提到的 Objective-C 协议为例:
@protocol A <NSObject>
@required
-(void) a;
@end
@protocol B <NSObject>
@required
-(int) a;
@end之前使用 Objective-C 类实现这两个协议时,按照声明顺序,只实现第一个协议的函数就可以通过编译,运行时调用第二个协议的函数会出现未定义行为。而在 Swift 中实现这两个协议,结果如下:
class SwiftMain: NSObject, A, B {
func a() { }
func a() -> Int32 { 0 }
^^
e: Method 'a()' with Objective-C selector 'a' conflicts with previous declaration with the same Objective-C selector
}这个报错与 Objective-C 类似,那如果我们删掉第二个协议的函数,编译器同样会报错:
class SwiftMain: NSObject, A, B {
^^^^^^^^^
e: type 'SwiftMain' does not conform to protocol 'B'
func a() { }
}相比之下,Swift 编译器比 Objective-C 编译器的检查更加严格了。
当然,从生产实践的角度而言,我们应该尽可能避免和减少导出 Kotlin 模块的符号,同时对于导出的符号进行严格的版本控制,以避免因符号冲突避让或者符号的其他变更导致 Objective-C 和 Swift 的调用处出现异常。
5.2 类型的映射
跨语言调用就是解决两个问题:数据和函数的映射。数据类型又分为语言提供的基本类型(数值类型、字符串等)和自定义类型(例如自定义的 struct、union 类型等)
5.2.1 数值类型
我们在内存布局一节曾经提到,Kotlin 的基本数值类型的内存布局与 C 语言的数值类型完全相同,因此映射关系也非常简单直接:
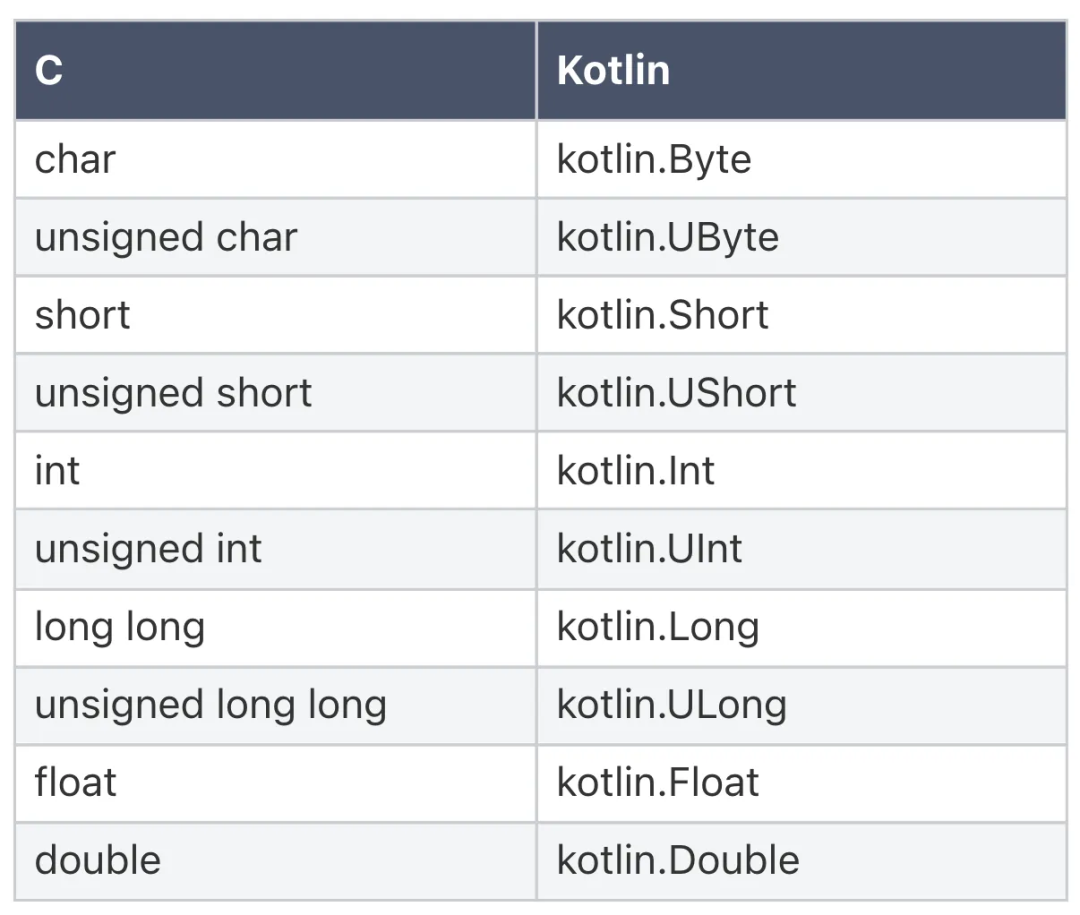
5.2.2 字符串类型
字符串类型的映射稍微有些复杂,C 语言中的字符串其实就是以字符 \0 结尾的字符数组,由于一个字符的只占用 1 字节,因此可以表示的范围实际上是 0~255,即 ASCII 字符集及其扩展字符集。C 语言标准中没有规定字符串采用什么编码,字符串字面量的编码取决于代码文件的字符编码,字符串的编码则取决于它的来源。通常我们在 Windows 开发环境中使用 MSVC 编译器,字符串字面量采用 GBK 编码,而在 macOS 和 Linux 环境中使用 GCC 和 Clang 编译器,字符串字面量采用 UTF-8 编码。
Kotlin 的字符串 String 采用了类似于 Java 的设计思路,字符编码采用 UTF-16,一个常见字符占用 2 字节;一个增补 Unicode 字符则采用 Surrogate Pairs 存储,占用 4 字节。
由此可见,Kotlin 与 C 语言的字符串之间想要转换,还涉及字符串的编码转换。为了降低复杂度,Kotlin 在设计时约定互调用的 C 语言字符串采用 UTF-8 编码。如果读者熟悉 C/C++ 中的宽字符 wchar_t 类型,我们可以将 Kotlin 字符串转换成 C 语言字符串的过程类比成宽字符串(wchar_t *)转换成窄字符串(char *)的过程(调用 C 标准库的 wcstombs 函数)。

这个转换过程通常是隐式的,我们在 C 语言中调用 Kotlin 函数,可以直接传入一个 char *,Kotlin 运行时会自动将这个 char * 转换为 Kotlin 的 String。例如:
fun kFunc(s: String) {}编译之后会生成下面的包装函数:
extern "C" void _konan_function_3(KObjHeader*);
static void _konan_function_3_impl(const char* arg0) {
Kotlin_initRuntimeIfNeeded();
ScopedRunnableState stateGuard;
FrameOverlay* frame = getCurrentFrame();
KObjHolder arg0_holder;
try {
_konan_function_3(CreateStringFromCString(arg0, arg0_holder.slot()));
} catch (...) {
SetCurrentFrame(reinterpret_cast<KObjHeader**>(frame));
HandleCurrentExceptionWhenLeavingKotlinCode();
}
}_konan_function_3 就是 kFunc 函数编译之后的符号,而导出给 C 语言的实际上是 _konan_function_3_impl,CreateStringFromCString 是定义在 Kotlin Native 运行时的函数,它的功能就是对字符串做编码转换。反之亦然。
在与 Objective-C 互调用时,Objective-C 的 NString 与 Kotlin 的 String 也存在隐式地转换逻辑。NSString 提供了相应的 API 实现编码的转换,因此,NString 与 Kotlin String 的转换逻辑相对简单一些,参见:Kotlin_Interop_CreateKStringFromNSString 和 Kotlin_ObjCExport_CreateRetainedNSStringFromKString。
5.2.3 自定义类型
C 语言的 struct 和 union 会被映射成 Kotlin 的 class。例如:
typedef union {
int i;
char cs[16];
} Tag;
typedef struct {
int id;
const char* name;
} User;
typedef struct {
int id;
User owner;
} Repository;映射之后的结果如下:
class Tag (rawPtr: NativePtr) : CStructVar {
companion object : CStructVar.Type
val cs: CArrayPointer<ByteVar>
var i: Int
}
class User(rawPtr: NativePtr) : CStructVar {
companion object : CStructVar.Type
var id: Int
var name: CPointer<ByteVar>?
val tag: Tag
}
class Repository(rawPtr: NativePtr) : CStructVar {
companion object : CStructVar.Type
var id: Int
val owner: User
}从这个映射关系中,我们可以发现几个细节:
struct和union都可以认为是值类型,在 C 语言中,实例既可以在栈内存上创建,也可以在堆内存上创建。映射到 Kotlin 之后,实例的内存分配逻辑将交给 Kotlin 管理,因此我们看到这些类型的主构造器都有一个 NativePtr 类型的参数。数值类型和指针类型的成员映射成了可变属性(
var),而struct、union类型成员则映射成了只读属性(val)。以Repository#owner为例,从 Kotlin 的语法角度来理解,owner应该上是 User 类型的实例的引用,Repository的实例中并不会直接包含 User 实例的数据;而从 C 语言的角度来看,owner字段的内存是 Repository 的实例的一部分。对owner进行赋值,在 C 语言看来是将另一个 User 实例的数据复制过来,而在 Kotlin 看来,这仅仅是将owner指向的对象做修改。基于这个原因,owner被映射成只读属性主要是为了避免语义上出现歧义。我们可以通过CValue<T>#write(NativePtr)来实现数据的复制,这部分内容我们将在指针一节进行进一步讨论。companion object继承了CStructVar.Type,包含了类型需要的内存大小和对齐信息。在 Kotlin 代码中创建这些类型的实例时将会用到这些信息。
Objective-C 的 @protocol 则会被映射为 Kotlin 的 interface,@interface 的会被映射成 Kotlin 的 class。例如:
#import <Foundation/Foundation.h>
@interface TouchEvent
@end
@protocol OnTouchDelegate
-(void) onTouch:(TouchEvent*) event;
@end
@interface ObjcUser : NSObject
@property (readonly) int id;
@property NSString *name;
-(void) nameWithFirstName: (NSString *) firstName lastName:(NSString *) lastName;
+(NSString *) typeName;
@end映射之后的结果如下:
interface OnTouchDelegateProtocolMeta : ObjCClass
interface OnTouchDelegateProtocol : ObjCObject {
abstract fun onTouch(event: TouchEvent?)
}
open class TouchEventMeta : ObjCObjectBaseMeta {
protected constructor()
}
open class TouchEvent : ObjCObjectBase {
companion object : TouchEventMeta, ObjCClassOf<TouchEvent>
protected constructor()
}
open class ObjcUserMeta : NSObjectMeta {
protected constructor()
open external fun alloc(): ObjcUser?
open external fun allocWithZone(zone: CPointer<cnames.structs._NSZone>?): ObjcUser?
open external fun new(): ObjcUser?
open external fun typeName(): String?
}
open class ObjcUser : NSObject {
companion object : ObjcUserMeta, ObjCClassOf<ObjcUser>
constructor()
val id: Int
var name: String?
open external fun id(): Int
open external fun init(): ObjcUser?
open external fun name(): String?
open external fun nameWithFirstName(firstName: String?, lastName: String?)
open external fun setId(id: Int)
open external fun setName(name: String?)
}通过这个映射关系,我们可以发现:
Objective-C 的只读属性、可变属性分别映射成 Kotlin 的只读属性、可变属性。
Objective-C 类的非静态成员会被映射成 Kotlin 的属性和函数,静态成员则映射成对应 class 的 companion object 的属性和函数。
Objective-C 协议映射成 Kotlin 接口后,接口名会增加 Protocol 后缀。
此外,Objective-C 的 Category 成员会映射成 Kotlin 扩展函数,Kotlin 的扩展函数导出到 Objective-C 之后会映射成扩展函数所在文件生成的类的静态函数(类似于与 Java 互调用的情况)。事实上,Objective-C 和 Swift 的类在扩展时可以实现协议,这一点在 Kotlin 中无法做到。
Kotlin 的类和接口与 Objective-C 类和协议在一起使用时有一些限制,常见的限制列举如下:
Kotlin 接口不能继承 Objective-C 协议。
Kotlin 类或者对象(object)可以实现 Objective-C 协议或者继承 Objective-C 类,但该 Kotlin 类必须是 final 的。
实现了 Objective-C 协议或者继承了 Objective-C 类的 Kotlin 类的伴生对象不能有字段(Field),即不允许定义有幕后字段(backing-field)的属性。
实现了 Objective-C 协议或者继承了 Objective-C 类的 Kotlin 类不能同时继承 Kotlin 类或者实现 Kotlin 接口。
实现了 Objective-C 协议的 Kotlin 类必须继承自 Objective-C 类(例如 NSObject)。
实现了 Objective-C 协议或者继承了 Objective-C 类的 Kotlin 类不能导出 Objective-C 符号,即只能在 Kotlin 模块内部访问。
由于当前版本 Kotlin 与 Objective-C 的互调用存在较多限制,开发者需要结合具体的 Kotlin 版本做好类结构设计。当然,这些限制很有可能随着 Kotlin 与 Objective-C 的互调用能力的提升而逐步移除。
5.2.4 指针类型
C 语言中的指针类型可以用于访问对应地址的内存,它为开发者提供了更为底层的内存访问能力。Kotlin Native 设计了一整套类型来对应 C 语言的指针相关的类型。
我们先来看一下 CValuesRef 及其子类。
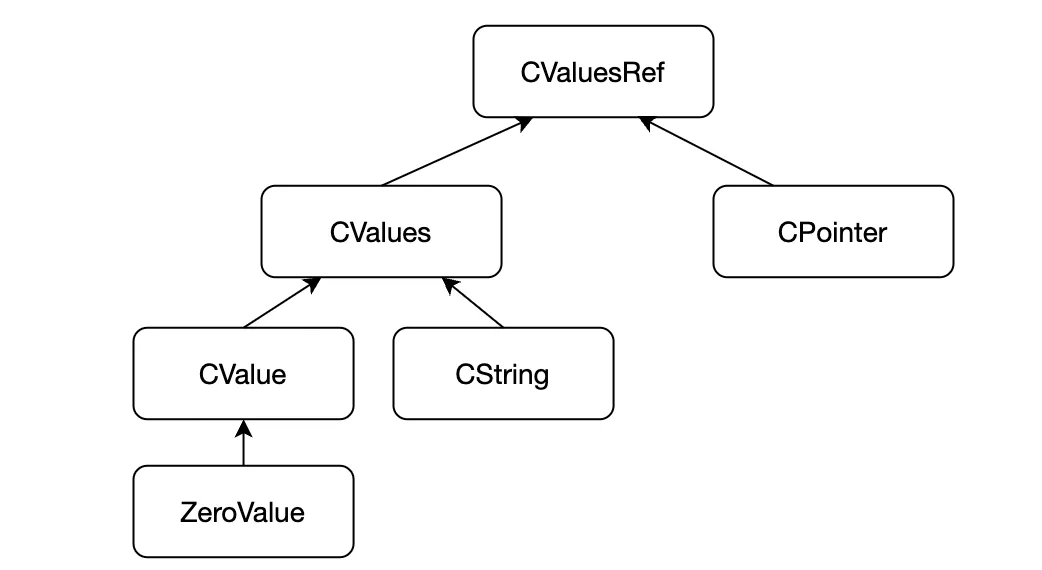
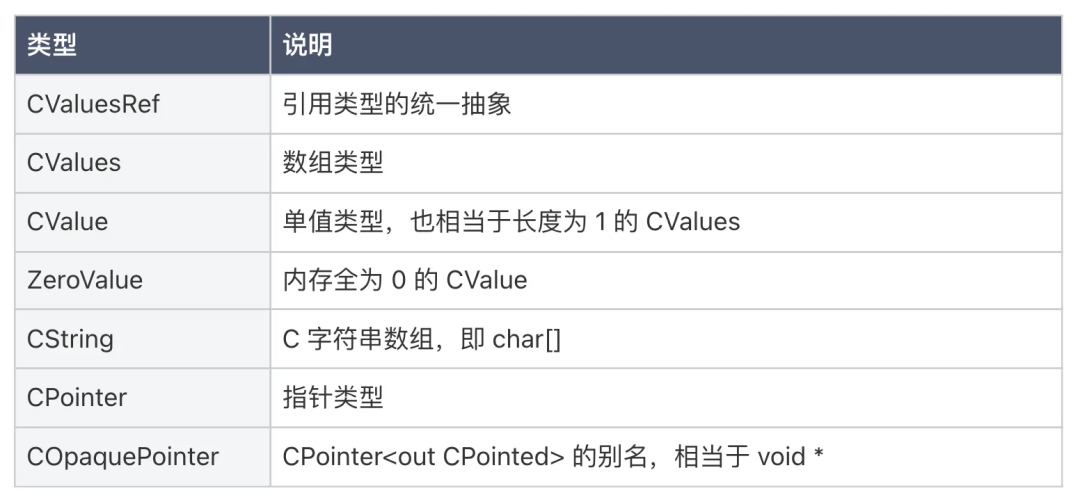
从命名上来看,CValuesRef 表示 C 语言的值的引用。我们在 C 语言中不会使用“引用”这样的术语,这里之所以有这样的类型结构,主要是为了统一数组和指针在概念上的抽象。各类型的详细说明如下:
其中,CValues 类型的值是不可修改的,因为 CValues 类型的值是分配在 Kotlin 堆内存上的,只有在做为 C 函数的实参时才会将值复制到 C 语言的堆内存上。
例如:
void set_ints(int *ints, int count) { ... }在 Kotlin 中调用 set_ints 的方法如下:
// 相当于 C 中定义 int 数组:int ints[] = {1, 2, 3};
val ints = cValuesOf(1,2,3)
// 相当于 C 中 set_ints(ints, sizeof(ints));
// ints.size 是开辟的内存大小,不是值的个数
set_ints(ints, ints.size / sizeOf<IntVar>().toInt())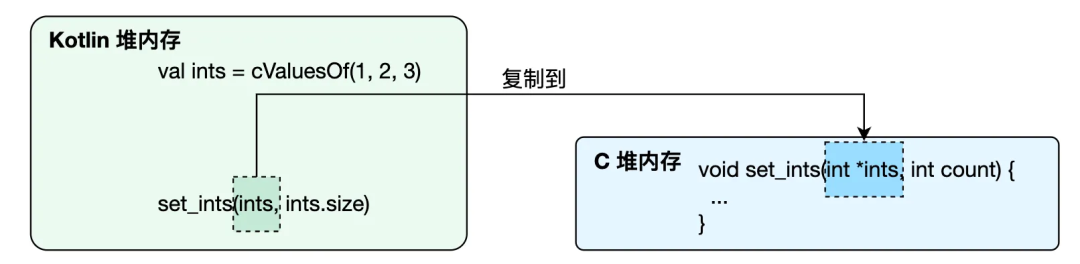
CValue 主要用于读写结构体类型,例如:
typedef struct {
int id;
const char* name;
} User;
static User default_user = {
.id = 0,
.name = "admin",
};在 Kotlin 中我们可以使用 CValue 来创建 User 的实例:
// user 的内存值为 0
val user: CValue<User> = cValue<User>()
// 相当于 User user2 = {.id = 1, .name="bennyhuo"};
val user2: CValue<User> = cValue<User> {
id = 1
"bennyhuo".cstr.place(name)
}
// 注意 default_user 是 C 中定义的静态变量
val user3: User = default_user
// 使用 default_user 初始化 user4
// 相当于 User user4 = default_user;
val user4: CValue<User> = default_user.readValue()
// 将 user2 的值写入到 default_user 的地址上,
// 相当于 default_user = user2;
user2.write(default_user.rawPtr)
// 获取 user4 的 id
// 相当于 int id4 = user4.id;
val id4 = user4.useContents { id }
// 获取 user4 的 name 的错误做法
// 不能在 useContents 中返回临时对象的指针
val name4 = user4.useContents { name } // ×
// 获取 user4 的 name 的正确做法
// 必须在 useContents 内部完整数据的复制和转换
val name4 = user4.useContents { name.toKString() } // √请注意,示例中提供的 C 代码仅供对照参考,方便理解代码的逻辑,二者实际的内存分配过程并不相同。CValue 类型的对象是创建在 Kotlin 堆内存上的,只有使用时才会临时分配到 C 的堆内存上,这也意味着在 Kotlin 中频繁访问 CValue 对象总是会存在内存复制的开销。
需要强调的是,示例中的 useContents 函数在调用时会将 user4 的值复制到 C 的堆内存上,并且会在函数返回之后释放这部分内存,返回指向这部分临时内存的指针的行为是不安全的。因此在 useContents 中直接返回 name 相当于返回了临时对象的指针,正确的做法是在 useContents 内部完成数据的复制和转换。因此在 useContents 中直接返回 name 相当于返回了临时对象的指针,正确的做法是在 useContents 内部完成数据的复制和转换,然后再返回。
CValuesRef 引用的类型是 CPointed,它也有一整套继承结构如图所示:
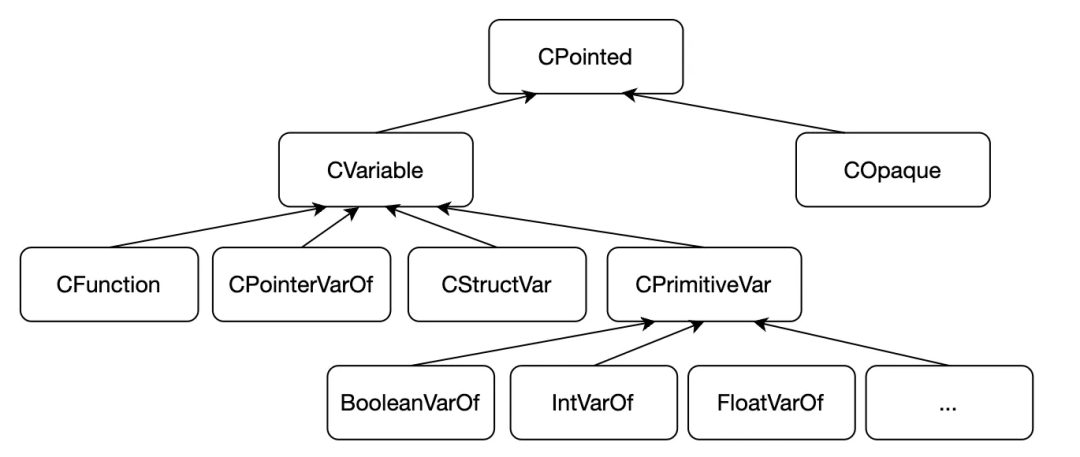
CPointed 及其子类型用于描述引用或者指针解引用之后的变量类型,例如 int * 解引用之后的变量类型就是 int。
请注意,指针解引用之后的表达式是个左值。以 IntVar 为例,IntVar 类型的变量背后一定有一块存储 Int 的内存,因此 Kotlin 中的 Int 无法作为指针解引用之后的变量类型。我们可以通过 IntVar 的 value 属性来访问对应的内存空间:
val intVar: IntVar = ...
intVar.value = 10CPointer 和 CPointed 之间可以相互转换,方法如下:
val intPtr: CPointer<IntVar> = ...
// 解引用,IntVar 是 IntVarOf<Int> 的别名
// 相当于 C 中的 int intVar = *intPtr;
val intVar: IntVar = intPtr.pointed
---
val intVar: IntVar = ...
// 取地址并创建指针变量
// 相当于 C 中的 int *intPtr = &intVar;
val intPtr: CPointer<IntVar> = intVar.ptr 5.2.5 函数类型
C 语言的函数可以直接导出符号,映射成 Kotlin 函数声明,例如:
int add(int a, int b) {
return a + b;
}映射之后的结果是:
external fun add(a: Int, b: Int): Int反之亦然,我们在符号导出一节已经做过很多讨论,这里不再赘述。
接下来我们通过例子探讨一下函数类型的映射。
int add(int a, int b) { ... }
typedef int (*OpFuncPtr)(int, int);
typedef int OpFunc(int, int);OpFuncPtr 和 OpFunc 映射到 Kotlin 之后的类型如下:
external fun add(a: Int, b: Int): Int
typealias OpFuncPtrVar = CPointerVarOf<OpFuncPtr>
typealias OpFuncPtr = CPointer<CFunction<(Int, Int) -> Int>>
typealias OpFunc = CFunction<(Int, Int) -> Int>由此可见,Kotlin 使用 CFunction 类型来表示 C 语言中的函数类型,这与 KFunction 类型表示 Kotlin 函数类型的设计相对应。结合前面对指针类型的讨论,函数指针的类型自然就是 CPointer<CFunction<...>> 了。OpFuncPtrVar 用来描述 OpFuncPtr 解引用之后的类型,这个符合指针类型的整体设计。
在 C 语言中,我们提到函数的类型通常就是指函数指针的类型,这主要是因为函数名总是会在表达式中隐式转换为指向自己的函数指针。例如:
OpFuncPtr op = add; // OK
OpFuncPtr op2 = &add; // OK
OpFuncPtr op3 = *add; // OK
OpFunc* op = add; // OK
OpFunc* op2 = &add; // OK
OpFunc* op3 = *add; // OK函数 add 的类型是 int(int, int),不过我们总是可以把 add 当成 int (*)(int, int) 类型的函数指针来使用。
然而在 Kotlin 中,函数名和函数引用的转换是显式的行为,函数名只能用来调用函数,用作表达式时只能使用函数引用。
val opFunc: KFunction2<Int, Int, Int> = ::add // OK
val opFunc2: KFunction2<Int, Int, Int> = add // Error
val opFuncPtr: OpFuncPtr = ::add // Error需要注意的是,C 函数映射成 Kotlin 函数声明之后,它的类型自然也就映射为 KFunction 了,因此我们不可以使用映射之后的 add 的函数引用来初始化 OpFuncPtr 类型的变量。如果想要在 Kotlin 中实例化 C 函数指针,需要使用 staticCFunction,这主要用于从 Kotlin 向 C 函数中传入函数指针参数的场景。例如:
int op(OpFuncPtr func, int a, int b) {
return func(a, b);
}op 函数需要一个 OpFuncPtr 的函数指针,这个函数映射成 Kotlin 函数之后的声明如下:
external fun op(func: OpFuncPtr?, a: Int, b: Int): Int在 Kotlin 调用这个函数的方法示例如下:
op(staticCFunction { a, b -> a + b }, 1, 2)请注意 staticCFunction 的参数必须是 Kotlin 顶级函数或者没有捕获外部状态的 Lambda 表达式。
更多的情况下,我们可能需要在 C 中调用 Kotlin 类的成员函数,这时我们需要将 receiver 通过函数参数传递,这也是 C 函数回调常用的方式,例如:
typedef void (*Callback)(void* data, int value);
void set_callback(Callback callback, void* data) {
...
}在 C 中,set_callback 可以用来设置回调,通常我们会把 callback 和 data 存起来,回调时将 data 透传给 callback 即可。而这个 data 就可以用来存储 Kotlin 函数的 receiver 信息。
class NativeEventCallback {
fun onEvent(value: Int) { ... }
}
---
val callback = NativeEventCallback()
val callbackRef = StableRef.create(callback)
set_callback(staticCFunction { data, value ->
data?.asStableRef<NativeEventCallback>()?.get()?.onEvent(value)
}, callbackRef.asCPointer())在 Kotlin 中,我们可以为任意 Kotlin 对象创建一个 StableRef,顾名思义,通过 StableRef 我们可以获得一个稳定指针,通过这个指针我们可以总是在 StableRef 的生命周期范围内获取到对应的 Kotlin 对象。
在这里,data 就是通过 callbackRef 获取到的稳定指针,通过 asStableRef 函数转回 StableRef 进而获取到 callback 对象,完成 onEvent 的调用。
需要注意的是,StableRef 需要在使用完毕之后通过 dispose 函数显式释放,避免造成内存泄露。
5.3 原生对象的内存
5.3.1 内存作用域
Kotlin 的堆内存依赖于垃圾回收机制进行管理,通常情况下我们不需要过多关心内存管理的问题。不过,在 Kotlin 中调用 C 函数,涉及到参数的传递和返回值的读取,这时就会涉及到在 C 语言的堆内存上分配内存的问题了。
例如:
void set_ints(int *ints, int count) { ... }在 Kotlin 中调用 set_ints 函数,需要在 C 语言堆内存上开辟内存,我们之前在介绍指针类型的时候提到可以通过 CValues 来创建 C 数组作为 set_ints 的参数:
val ints = cValuesOf(1,2,3)
set_ints(ints, ints.size / sizeOf<IntVar>().toInt())实际上,这段代码相当于:
memScoped {
val kArray = arrayOf(1, 2, 3)
val cArray = allocArray<IntVar>(3)
for (index in kArray.indices) {
cArray[index] = kArray[index]
}
set_ints(cArray, 3)
}我们完全可以把 memScope 理解成一个 C 的作用域,在作用域内通过 alloc* 函数分配的内存都会在退出作用域时释放。这段代码从逻辑上可以类比下面的 C 代码来理解(请注意二者的内存的分配行为不同):
{
int array[] = {1, 2, 3};
set_ints(array, 3);
}接下来我们再看一个非常经典的场景。C 语言中随处可见将外部指针传入函数内部以获取数据的做法,例如:
void get_result(int *result) {
*result = 100;
}在 C 语言当中,调用 get_result 是一件非常自然的事:
int result;
get_result(&result);
// result: 100在 Kotlin 中调用 get_result 就不是那么直接了。我们需要先创建一个作用域,接下来再创建一个 Int 类型的变量,注意这个变量是一个左值,我们需要把它的地址传给 get_result。完整的做法如下:
memScoped {
val result = alloc<IntVar>()
get_result(result.ptr)
println(result.value) // 100
} 5.3.2 稳定的内存地址
在内存垃圾回收过程中,堆内存可能会被移动和整理,Kotlin Native 运行时不会保证存活的对象在内存中的位置是不变的,因此理论上我们不能直接把 Kotlin 对象的地址传给 C 函数。
我们在函数指针一节已经接触过 StableRef 类型。StableRef 可以确保 Kotlin 对象不会被回收,同时也可以用于创建稳定指针,这个指针可以作为参数传给 C 函数。需要注意的是,这个指针指向的实际上是 StableRef 背后的一个 C++ 对象,因此在 C 函数中,我们不能直接使用这个指针来获取对应的 Kotlin 对象,而只能把它当成一个透明指针来使用。
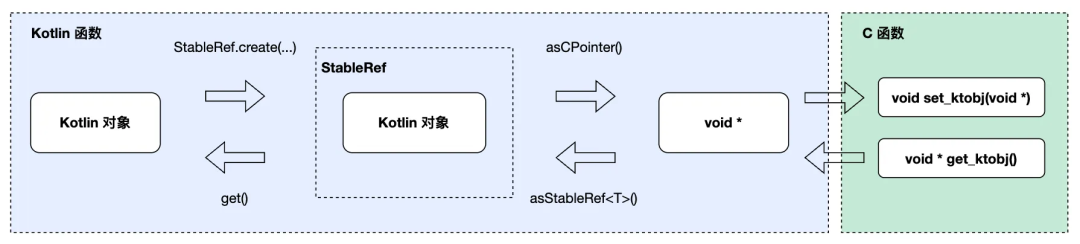
在 StableRef 的帮助下,我们可以轻松地设计出与下面示例类似的 API:
FILE *fopen(const char *, const char *);
void clearerr(FILE *);
int fclose(FILE *);
int feof(FILE *);
int ferror(FILE *);C 语言标准没有明确规定 FILE 的类型,使用者也无需关心 FILE 究竟是什么,只需要在调用相应的 API 时将 fopen 返回的 FILE 指针传进去即可。通过 StableRef 创建的稳定指针也是一个透明指针,与 FILE 指针的作用完全相同,使用者也无需关心它的内部实现。
下面我们通过例子来进一步展示 StableRef 的用法:
class File(val path: String) {
fun readText(): String { ... }
fun close() {}
}
@CName("File_create")
fun createFile(path: String): COpaquePointer {
val file = File(path)
val stableRef = StableRef.create(file)
return stableRef.asCPointer()
}
@CName("File_readText")
fun readFileText(filePtr: COpaquePointer): String {
val fileRef = filePtr.asStableRef<File>()
return fileRef.get().readText()
}
@CName("File_close")
fun closeFile(filePtr: COpaquePointer) {
val fileRef = filePtr.asStableRef<File>()
fileRef.get().close()
fileRef.dispose()
}上述 Kotlin 代码导出的符号如下:
extern void* File_create(const char* path);
extern const char* File_readText(void* filePtr);
extern void File_close(void* filePtr);StableRef 非常适合用于设计类似的 API,我们在鸿蒙适配的过程中也大量应用了这种方法来导出 Kotlin API。
StableRef 适用于生命周期较长的 Kotlin 对象,对于生命周期较短的对象,我们也可以使用 usePinned 函数。以下示例代码来自 Kotlin 官方文档 https://kotlinlang.org/docs/native-c-interop.html#object-pinning
fun readData(fd: Int) {
val buffer = ByteArray(1024)
buffer.usePinned { pinned ->
while (true) {
val length = recv(fd, pinned.addressOf(0), buffer.size.convert(), 0).toInt()
if (length <= 0) {
break
}
// Now `buffer` has raw data obtained from the `recv()` call.
}
}
}在 usePinned { ... } 的作用域内,buffer 对象不会被回收,因此我们可以直接在 C 函数中访问 buffer 的内存来完成数据的读写。
需要说明一下的是,我们经过反复阅读 Kotlin Native 的运行时源码发现,Kotlin Native 的内存回收目前不会进行内存整理,也就是说 Kotlin Native 对象的内存地址是稳定的。不过,随着 Kotlin 团队对 Kotlin Native 的内存回收算法的优化和迭代,Kotlin Native 对象的内存布局也很有可能发生变化,我们不应该对 Kotlin Native 对象的内存地址做任何假定,也不能够在在生产环境中依赖这一现状。
5.3.3 深入理解 CValues
我们在介绍 CValues 的时候提到,CValues 的内存是开辟在 Kotlin 堆内存中的,只有在需要的时候才会复制到 C 语言的堆内存中。
接下来我们再看一下使用 cValuesOf(...) 创建数组的代码:
val ints = cValuesOf(1,2,3)我们之前提到它相当于下面的 C 代码:
int ints[] = {1, 2, 3};不过我们也一直强调,这二者只是逻辑上的相当,在内存分配上有着完全不同的逻辑。接下来我们拆解一下通过 cValuesOf(...) 创建数组的过程。
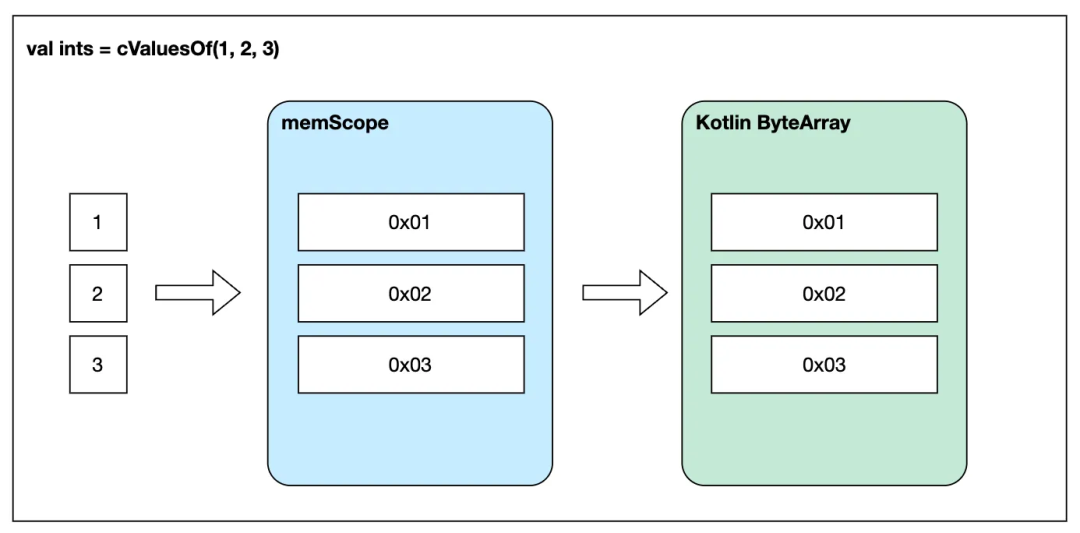
可以看到,这里实际上发生了两次复制,第一次是将 1,2,3 复制到 memScope 中创建的临时内存中,第二次则是将临时内存完整地复制到 Kotlin 的 ByteArray 中。这里可能有些奇怪,我们既然已经知道了值,可以直接创建 Kotlin ByteArray 来写入这些值,为什么一定要使用 memScope 背后的 C 语言堆内存中转一下呢?因为 C 语言堆内存的存储方式与平台有关,不同平台的字节序、内存对齐方式也不一定相同,如果想要直接在 Kotlin 中直接计算出 C 语言堆内存的结果,必然需要在 Kotlin 标准库中对各个平台进行相关的适配,这样做反而更加复杂。
在使用时,我们需要先将 CValues 的值复制到 C 语言堆内存中,例如:
set_ints(ints, ints.size / sizeOf<IntVar>().toInt())set_ints 的第一个参数是 int *,Kotlin 编译器会将 CValues<IntVar> 类型的 ints 转换为 CPointer<IntVar>,转换的方式就是调用 CValuesRef<IntVar>#getPointer(),也就是说,上述代码与下面的代码等价:
memScoped {
set_ints(ints.getPointer(this), ints.size / sizeOf<IntVar>().toInt())
}这也就能够解释我们为什么总是说 CValues 的值只有在用到的时候才会复制到 C 语言的堆内存中。
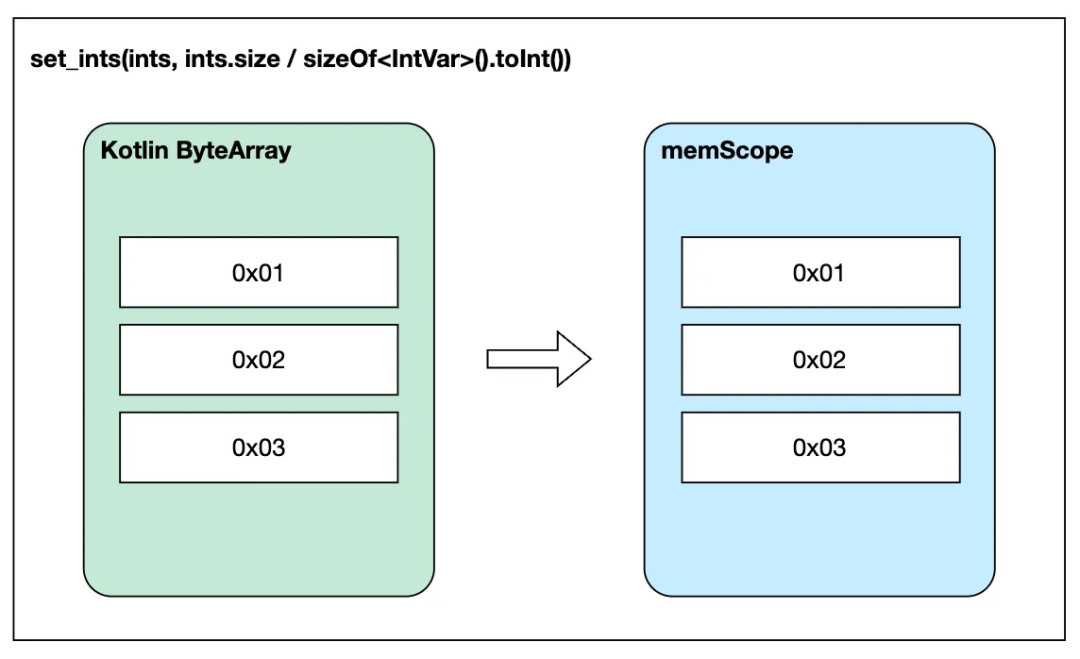
顺带提一句,CPointer 也是 CValuesRef 的子类,由于 CPointer 本身已经是指针类型了,因此 CPointer#getPointer() 就只会返回自身,而不存在内存复制。
useContents 则是另外的一个用时复制例子(注意 CValue 是 CValues 的子类):
inline fun <reified T : CStructVar, R> CValue<T>.useContents(block: T.() -> R): R = memScoped {
this@useContents.placeTo(memScope).pointed.block()
}useContents 函数在其内部创建了一个内存作用域,并将结构体 T 的实例复制到内存作用域中。显然,block 的 receiver 是分配在内存作用域中的实例,离开作用域之后就失效了。
5.3.4 Objective-C 对象
Objective-C 对象采用 ARC(即 Automatic Reference Counting,自动引用计数)实现对象内存的自动管理。当 Kotlin 对象持有一个 Objective-C 对象时,后者的引用计数加 1;当该 Kotlin 对象被回收时,它引用的 Objective-C 对象的引用技术随之减 1。当 Objective-C 对象持有 Kotlin 对象的强引用时,这个 Kotlin 对象的不会被回收;而当 Objective-C 对象持有 Kotlin 对象的弱引用时,Kotlin 对象的内存回收不会受到影响。
有一种情况需要注意,Kotlin Native 中调用 Objective-C 函数时,参数会从 Kotlin 对象转换成 Objective-C 对象,例如:
repeat(Int.MAX_VALUE) {
NSLog("$it\n")
}(案例出自:https://kotlinlang.org/docs/native-ios-integration.html#objective-c-objects-lifecycle)
在这个案例中,NSLog 是一个 Objective-C 函数,参数需要从 Kotlin 字符串转换成 Objective-C 字符串,转换之后对得到的 Objective-C 对象调用 objc_autorelease 并返回,大致相当于:
repeat(Int.MAX_VALUE) {
val kString = "$it\n"
val nsString = convertKStringToNSString(kString)
objc_autorelease(nsString)
NSLog(nsString)
}nsString 这个中间对象的释放取决于离开当前所在的 auto release pool 作用域的时机,这意味着在高频次的循环中调用 Objective-C 所产生的临时对象并不会用完之后立即释放。为了解决这个问题,我们需要缩小 auto release pool 的作用域:
repeat(Int.MAX_VALUE) {
autoreleasepool {
NSLog("$it\n")
}
}5.3.5 模拟 RAII
C++ 中有一个非常著名的资源管理机制叫做 RAII(Resource Acquisition Is Initialization),它将资源的生命周期绑定到一个对象上,在这个对象的构造函数中进行资源的获取(例如打开文件流、创建 socket 、加锁等),并在对象的析构函数中进行资源的释放(例如关闭文件流、销毁 socket、解锁等)。
例如:
{
std::ifstream ifs("main.cpp");
if (ifs) {
std::string line;
while (std::getline(ifs, line)) {
std::cout << line << std::endl;
}
}
}ifs 在构造的时候会尝试打开文件 main.cpp,在析构的时候会关闭输入流,这也就意味着离开当前作用域可以确保文件输入流可以被正确关闭。
还有一个非常经典的使用场景:内存管理。C++ 的内存是需要手动管理的,通常情况下我们需要手动调用 delete 来释放之前 new 出来的对象,这样就很容易出现内存泄露(忘了 delete)或者野指针(过早 delete)的问题。C++ 提供了 std::shared_ptr 等一系列智能指针来解决对象的内存管理的问题。例如:
void need_int(std::shared_ptr<int> int_ptr) {
...
}
---
// 在堆内存上创建 int 对象,值为 5,引用计数为 1
std::shared_ptr<int> int_ptr(new int(5));
// 复制智能指针,引用计数为 2
std::shared_ptr<int> int_ptr2 = int_ptr;
// 复制智能指针到函数 need_int 中,引用计数为 3
need_int(int_ptr);
// 函数调用完成,引用计数为 2
// 离开作用域,引用计数减到 0,释放内存在所有支持的平台上,Kotlin 对象的内存都不需要手动管理,对象内存的回收依赖内存垃圾回收机制,因而对象的销毁通常不是很及时。Kotlin 没有提供类似 C++ 的析构函数,Kotlin 类通常需要实现 AutoCloseable 接口来提供资源管理能力,使用者则需要在资源使用完毕时主动调用 close 函数释放资源。对于常见的资源,开发者可以配合 use 函数简化使用复杂度,例如:
// Kotlin JVM 示例
File("build.gradle.kts").inputStream().reader().use {
...
// 离开作用域后,use 函数内部会关闭输入流
}不过,有些场景下,我们希望在 Kotlin 对象被回收的时候可以执行某些资源释放的操作,将资源的管理绑定到对象的生命周期上可以极大的降低某些特定资源的管理复杂度。例如一张图片可能被很多 UI 控件共享,还会被图片池缓存,手动管理这张图片的内存会是一个非常大的难题。Kotlin Native 提供了 Cleaner 机制,可以用于对象垃圾回收时释放资源。Cleaner 的使用方法如下:
// 1. 定义一个类来包装需要管理的资源
class ResourceHolder {
// 2. 创建资源对象
val resource: Resource = ...
// 3. 创建 cleaner,注意参数传入需要释放的资源对象
val cleaner = createCleaner(resource) {
// 4. 关闭资源,在 ResourceHolder 实例被回收时执行
it.close()
}
}下面是 Skiko 中使用 Cleaner 机制实现自动资源管理的代码:
actual abstract class Managed actual (...) : Native(ptr) {
private val thunk: FinalizationThunk? = if (managed) { ... } else null
private val cleaner = if (managed) {
createCleaner(thunk) {
it?.clean()
}
} else null
...
}Managed 是所有需要自动管理资源的类的父类,它提供了 thunk 和 cleaner 两个属性,thunk 中包含了开辟的内存资源,cleaner 则提供对象销毁时的回调。当 Managed 的实例即将销毁时,createCleaner 的参数 Lambda 表达式会被调用,thunk.clean() 就会被调用,以实现资源的自动管理。
顺便提一句,Java 也有类似的 Cleaner 的设计,与之前的 finalize 相比,Cleaner 只需要访问需要释放的资源,能更好的避免即将被回收的对象被修改的问题。
06
当前的主要问题
尽管 Kotlin Native 在设计和实现上尽可能保持了与 JVM 平台的一致性,但想要适配所有 Native 平台并不是一件容易的事情。与 Kotlin JVM 相比,Kotlin Native 在开发体验和运行性能上仍然存在不少问题。
6.1 调试工具不完善
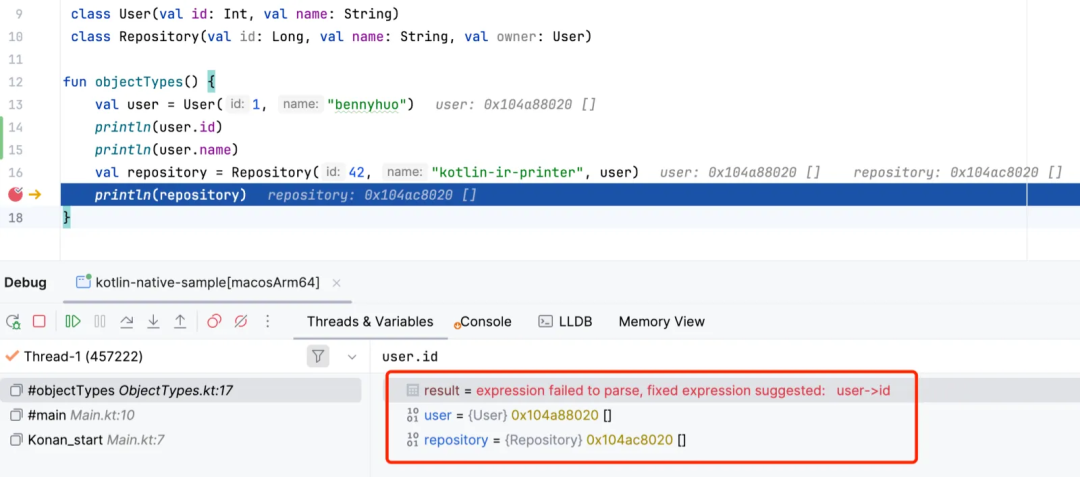
IntelliJ IDEA 安装 Native Debugging Support 插件之后可以用来调试 Kotlin Native 程序,但调试器本质上是将 Kotlin Native 程序当做 C/C++ 程序进行求值,因此不支持动态访问特定变量或属性的值。
如图所示,类 User 有两个属性 id 和 name,在调试时,我们通过 user.id 访问 id 属性,结果表达式返回错误,认为 user->id 不是合法的表达式。
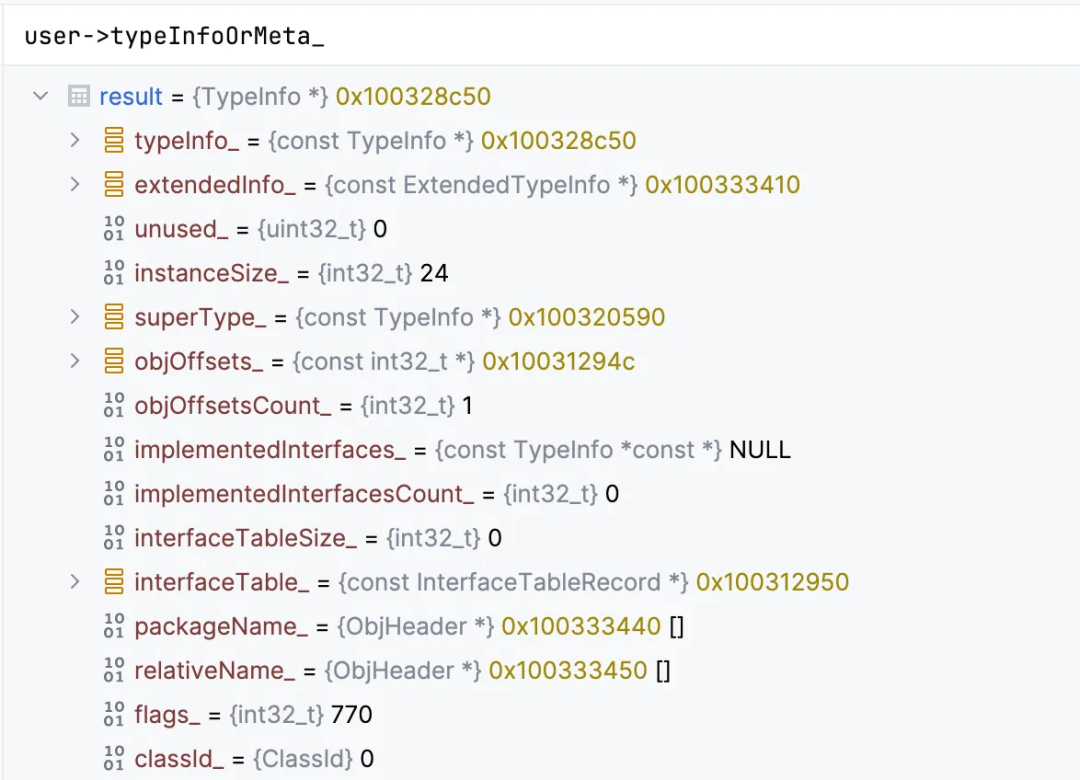
我们知道 user 事实上是 ObjHeader * 类型,因此可以按照 C++ 的方式直接访问它的类型信息:
6.2 基础库无法动态共享
Kotlin Native 模块的构建产物包括可执行程序、动态库、静态库或者 klib。其中前三种产物是 Native 产物,可以通过导出 C 或者 objc 符号的方式被 Native 项目调用;klib 是 Kotlin 的专属产物格式,包含序列化之后的 Kotlin IR 和模块元数据,只能用于被其他 Kotlin 模块依赖。
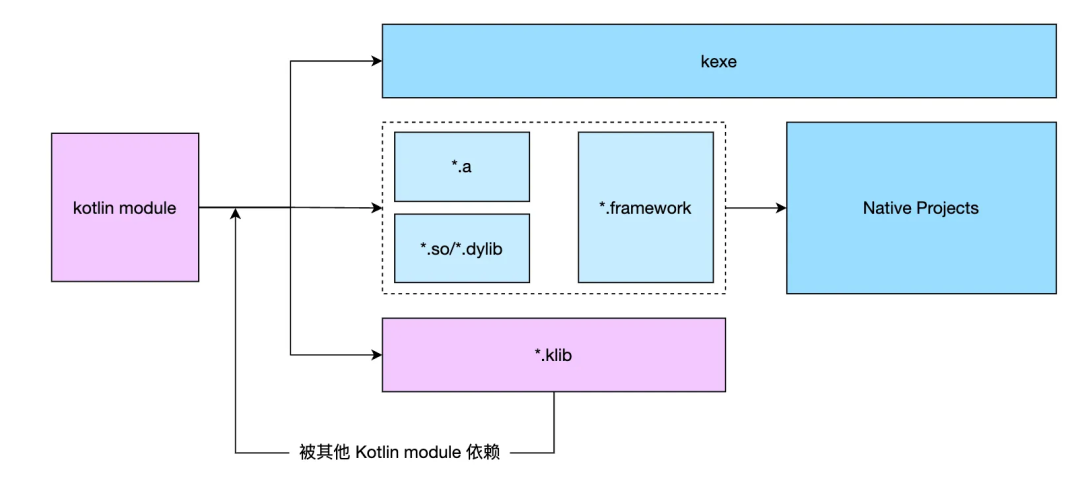
这里最关键的问题在于,编译成 Native 产物的 Kotlin 模块相互独立,并且各自包含一份基础库,包括标准库、协程库、UI 库等等,这导致最终的编译产物体积存在冗余。
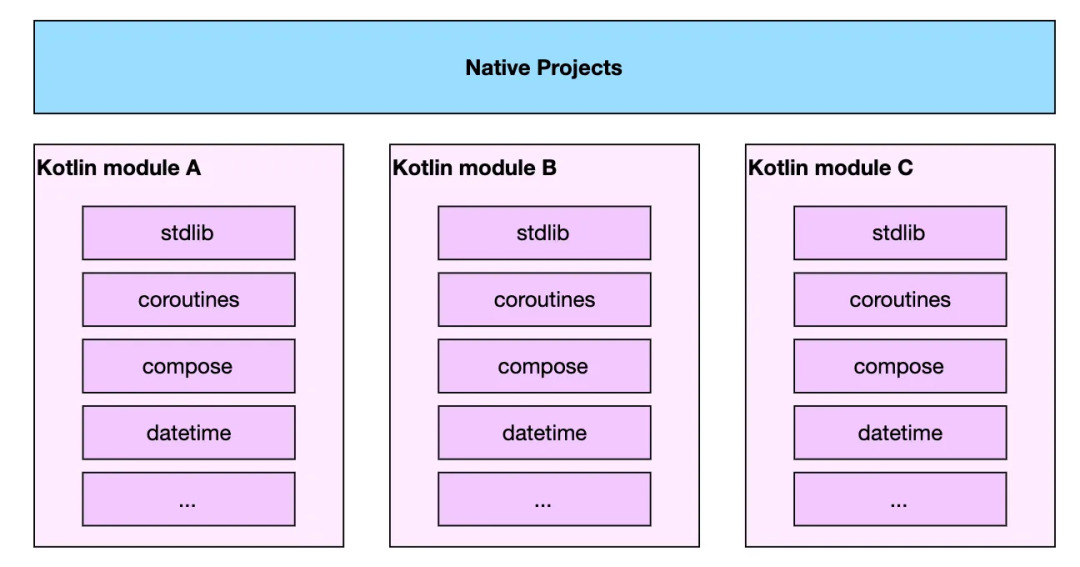
因此目前推荐的做法是在一个 Native 项目中,Kotlin Native 编写的库需要尽量作为一个整体,保持唯一入口,以减少基础库的冗余。
6.3 运行性能仍有空间
6.3.1 值类型的支持
值类型可以在栈内存上创建实例,相比在堆内存上创建实例有更高的性能表现;同时由于实例可以跟随栈内存的弹栈而销毁,不需要额外的对象头,内存占用也更小。而作为 Native 语言,Kotlin 没有提供类似于 C/C++ 的 struct/class 的值类型。
C/C++ 的 struct/class 的实例可以在栈上分配内存,也可以在堆上分配内存,这有利于开发者写出更高效的程序。
struct User {
int id;
const char* name;
};
// 在栈内存上创建实例
User user_stack{.id=0, .name="bennyhuo"};
// 在堆内存上创建实例
User *user_heap = new User{.id=0, .name="bennyhuo"};C# 也支持 struct 类型,struct 类型的实例默认在栈内存上创建。
struct User
{
public int id;
public string name;
}
// struct 类型,默认在栈内存上创建实例
User user = new User{ id = 0, name = "bennyhuo"};此外,在常见的 Native 语言中,Go、Rust、Swift 也都提供了对值类型的支持。相比之下,这些语言在运行时有更好的性能表现,值类型也贡献了自己的力量。
当然,Kotlin 目前对值类型的支持,受到了很多因素的影响。作为一门多平台语言,Kotlin 的语法特性的设计和实现需要考虑它支持的所有平台。Java 对值类型的支持仍然在预览阶段:JEP 401: Value Classes and Objects (Preview) https://openjdk.org/jeps/401,JavaScript 显然是不可能也没有必要支持值类型的,这为 Kotlin 支持值类型带来了不少的麻烦。
事实上,Kotlin 有 value class 的概念。只不过,现阶段 value class 的作用仍然比较有限,它的作用主要是与 @JvmInline 注解配合使用,在 Kotlin JVM 中作为另一个类型的包装。例如,在 Jetpack Compose 中,Color 就是一个 value class,它本质上就是对 ULong 类型的包装:
@JvmInline
value class Color(val value: ULong) {
@Stable
val red: Float
get() { ... }
...
}如果我们进一步深入分析,就会发现 ULong 也是一个 value class,它本质上是对 Long 类型的包装:
@JvmInline
value class ULong(val data: Long) : Comparable<ULong> {
...
}从长远的角度来看,Kotlin 的 value class 有机会做到与 C# 的 struct 类似的效果,即尽可能在栈内存上创建实例,需要时可以装箱并存储于堆内存中。有关 Kotlin value class 的讨论,参见:https://github.com/Kotlin/KEEP/blob/master/notes/value-classes.md
6.3.2 持续优化中的 GC 性能
前面已经做过分析,目前 Kotlin Native 的 GC 算法和调度策略与 Java 虚拟机相比仍然比较简单,并发标记和清除的性能仍有待提升。不过,随着内存模型的全面更新和内存分配器的不断优化,Kotlin Native 堆内存的分配和释放效率已经相比之前得到了很大的提升。
Kotlin Native 将在 2.0.20 版本中开始实验并发标记算法,即我们以往熟知的 Concurrent Mark。在之前的版本中,Kotlin Native 会在 GC 时暂停线程并对对象进行标记,这次更新将极大的缩短 GC 时的线程暂停耗时,对于提升应用程序性能、减少 UI 卡顿有着重要的意义。
6.4 扩展平台的成本相对较高
虽然 Kotlin Native 的后端编译器采用了 LLVM 来生成目标平台的二进制产物,但是 Kotlin Native 在扩展平台时仍然需要专门对目标平台进行适配。主要包括:
LLVM 编译器的编译参数。不同的目标平台的 CPU 架构、指令集、型号都会影响生成的二进制产物的执行效率;不同平台对于同一功能也会有不同的实现可以通过编译参数来选择。
系统 API 的导出。不同平台的系统 API 有很大的差异,尽管 Kotlin Native 在实现时尽可能基于 POSIX 标准 API 实现其标准库,但平台特色的能力往往也需要专门提供 API 的导出支持。
平台互调用的适配。除了支持与 C API 的互调用以外,还需要考虑对平台特有能力的适配。例如:
在适配 iOS 时,需要提供与 Objective-C/Swift 的互调用支持;
在适配鸿蒙时,需要提供与 ArkTS 互调用的支持(即对 napi 调用的简化和封装)
不过,通常情况下我们不需要考虑扩展平台的问题,因为这是 Kotlin 团队需要解决的问题。但考虑到 Kotlin 团队的精力有限,平台适配的成本过高会导致 Kotlin 团队在其他方面的投入不足,可能成为影响 Kotlin Native 的生态快速完善的一个重要原因。
07
未来与展望
Kotlin Native 是 Kotlin 多平台愿景中最为关键的一环。尽管当下还存在很多问题,但 Kotlin 多平台的发展方向受到了很多公司技术团队和个人开发者的认可和支持。
7.1 快速发展的社区
近几年,随着 JetBrains 和 Google 的不断努力,Kotlin 社区的规模日益壮大,支持和热爱这门编程语言的开发者也越来越多。
目前,官方每年会召开 Kotlin Conf,这是全球 Kotlin 开发者的盛会,我们会在会议中看到来自全球各国的开发者分享自己使用 Kotlin 开发各类应用程序的经验和故事。

如果想要了解更多国内 Kotlin 社区的发展,建议大家订阅“Kotlin 炉边漫谈”(https://space.bilibili.com/414846001/channel/collectiondetail?sid=455051),这是一档由 Kotlin 官方布道师和社区组织者共同主办的谈论 Kotlin 相关信息的中文节目,节目介绍除了中文 Kotlin User Group 技术社区资讯外,还会邀请各地 Kotlin 大佬一起来聊聊 Kotlin 的应用场景。

7.2 逐步完善的生态
Kotlin 在设计之初就坚持优先复用,不重复造轮子的设计思路,在 JVM 上直接复用了 Java 生态的所有能力。这样的结果有两个直接的好处:
Kotlin 标准库非常小,Kotlin 1.0 的标准库只有 6000 多个方法,开发者可以以极低的空间成本将 Kotlin 集成到项目中。
Kotlin 可以实现与 Java 无缝互调用,项目可以从 Java 平稳过渡到 Kotlin 。
相比之下,Scala 重新设计实现了很多 Java 标准库中已经提供的能力。这样做的好处是 Scala 可以更好的贯彻自己的理念和风格,让 Scala 成为 JVM 平台上独立于 Java 之外的一门别具一格的编程语言。缺点就是 Scala 标准库有近 50000 个方法,Java 项目迁移至 Scala 会面对较大的技术挑战和思想冲击。
早期 Android 应用安装包存在 dex 方法数限制的问题,很多项目对于方法数都有严格的增量限制。引入 Kotlin 比引入其他编程语言(例如 Scala、Groovy)更加轻量,这实际上也是 Kotlin 能够成功成为 Android 首选开发语言的一个必要条件。
随着时间的推移,Kotlin 已经成为一门多平台语言,标准库也由最初的 kotlin-stdlib 演变成标准库矩阵:
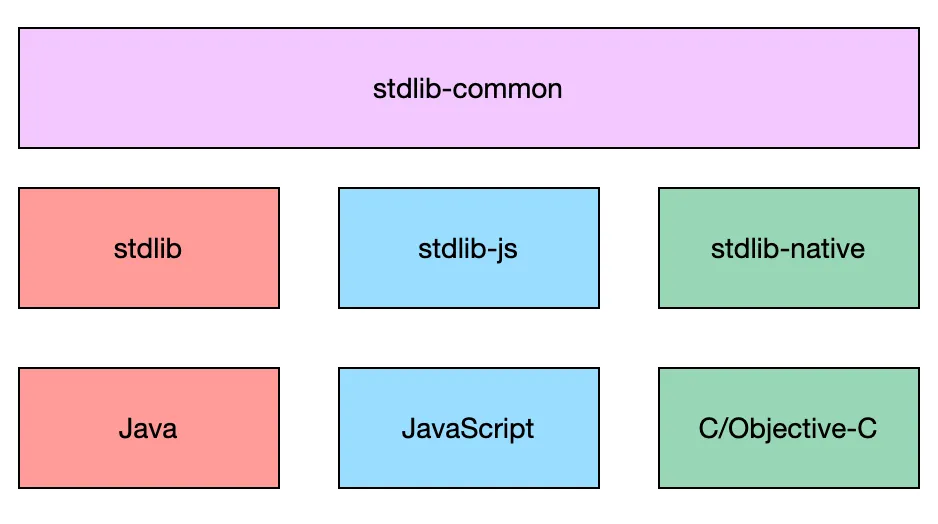
Kotlin 团队在规划标准库和扩展库的能力时,会尽可能把与编译器实现相关的部分放入标准库,只依赖 Kotlin 语法就可以实现的扩展能力则单独拆分到扩展库中。Kotlin 协程就是一个非常典型的例子,suspend 函数依赖于编译器提供的能力,因此协程相关的基础能力都划分到标准库中,而基于这些基础能力搭建的上层封装则划分到单独的 kotlinx.coroutines 库中。Kotlin 团队将官方扩展库的源码维护在 Kotlin 组织下,常用的官方扩展库还包括:

除了官方提供的扩展库以外,我们还可以在 https://github.com/terrakok/kmp-awesome 这个项目中看到社区贡献的扩展库。
7.3 值得期待的未来
虽然目前 Kotlin Native 在一些方面存在问题,不过 Kotlin 的宏观愿景和发展方向日益受到广大开发者的认可和支持。相比其他同类型的编程语言,Kotlin 有非常多令人羡慕的优势。
Kotlin 脱胎于 JetBrains 公司。这是一家最懂开发者的公司,他们知道开发者喜欢什么样的编程语言,也知道如何设计好的编程语言。Kotlin 优秀的语法设计已经足以证明这一点。JetBrains 很早就将 Kotlin 应用于 IntelliJ IDEA 的开发中,全球各地各行各业的开发者在从事自己的开发工作的同时也验证了 Kotlin 的可用性和稳定性,为后来 Kotlin 的风靡全球奠定了坚实的基础。随后,Google 的强势加入也使得 Kotlin 如虎添翼,让 Kotlin 在 Android 应用开发领域毫无疑问的站稳了脚跟。

(图片来自:[Kotlin 基金会官方网站](https://kotlinfoundation.org/))
Kotlin 的愿景又充满了挑战和机遇。在常见的编程语言中,我们很难找到第二个同时支持 JVM、JavaScript、Native、WebAssembly 等多个平台的编程语言。在将来,我们有机会在几乎所有常见的领域和平台上运用 Kotlin 进行程序开发,包括服务端、前端甚至科学计算。不仅如此,这些程序的源码还可以非常方便地实现全平台共享,在降低程序开发的成本的同时,也能保持团队技术风格的高度统一。
(图片来自:[Kotlin/Everywhere 活动网站](https://events.withgoogle.com/kotlin-everywhere/))
随着 Kotlin 2.0 的发布,Kotlin 团队的工作重心将会从编译器的架构优化转移到 Kotlin Native 性能的提升以及 Kotlin 多平台的生态建设上。相信在不久的未来,我们将会持续看到 Kotlin 在相关方向上不断取得进展。
08
小结
本文我们从编译流程、运行机制等角度对 Kotlin Native 进行了详细地介绍。作为 Kotlin 多平台生态的重要一环,Kotlin Native 不再依赖其他运行环境,同时也能保持与其他平台一致的开发体验,为 Kotlin 的未来提供了无限的可能。
-End-
原创作者|霍丙乾
感谢你读到这里,不如关注一下?👇

你有在使用 Kotlin Native 吗?你觉得它目前与 JVM 最大的差距是什么?欢迎评论分享。我们将选取点赞本文并且留言评论的一位读者,送出腾讯云开发者定制发财按键1个(见下图)。9月5日中午12点开奖。

📢📢欢迎加入腾讯云开发者社群,享前沿资讯、大咖干货,找兴趣搭子,交同城好友,更有鹅厂招聘机会、限量周边好礼等你来~

(长按图片立即扫码)























 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









