







👉目录
1 Prompt 万能框架
2 框架细化
3 RAG
4 附加技巧
5 总结
程序员工作的终极意义,就是干掉复杂度,用一套通用的方法解决大部分问题。在大模型时代,这个通用的方法就是——Prompt 工程。作为用好大模型最重要的武器,Prompt 的好坏对模型效果有着决定性的影响。
然而,网络上大量相关文章多是罗列“Prompt 工程” 中的若干技巧,少有体系化的总结,让人看完依然不知道该如何入手。本文希望结合腾讯工程师在 “Prompt 工程” 中的实践经验,更加体系化地对 “Prompt 工程” 进行梳理,希望可以一步步地帮助大家用好大模型,人人都是 Prompt 工程师。
关注腾讯云开发者,一手技术干货提前解锁👇
01
Prompt 万能框架

在编写 Prompt 时,从0到1地编写出第一版 Prompt 往往是最难的,而基于已有 Prompt 利用各种技巧进行优化则相对简单。如上图所示,我们使用了一套 “万能模版”,把一个 Prompt 拆分成了 “立角色 + 述问题 + 定目标 + 补要求” 这四个部分,利用这个模版可以得到一个“及格”的 Prompt。下面我就具体和大家阐述一下这个模版是如何得到的,为什么他是有效的。
Prompt 的作用就是根据我们的问题调用模型的能力,我们要通过提问的方式,明确的让模型知道我们想要什么,我们的目标是什么,从这个基本思想出发,Prompt 应该包含以下几点:

问题是什么:首先你要告诉模型你的问题是什么,你的任务是什么,要尽量描述清楚你的需求。
你要做什么:下面你需要告诉大模型具体要做什么,比如做一份攻略,写一段代码,对文章进行优化,等等。
有什么要求:最后我们往往还需求对任务补充一些要求,比如按特定格式输出,规定长度限制,只输出某些内容,等等。
通这 3 部分的描述我们就把 “要大模型做什么” 描述清楚了,这个想法十分自然,即便不是大模型,而是希望其他人为你完成某项任务,往往也需要通过这 3 部分把问题描述清楚。由于这仅仅是第一版 Prompt,你不需要描述的过于详细,也不需要使用技巧,只需要用简练的语言把这几部分描述清晰即可。以下是几个示例:
例1:生成代码注释
问题是什么:你的任务是帮我的代码生成注释。
你要做什么:我有一段 python 代码,需要你对代码的内容进行分析,并为代码添加注释。
有什么要求:请结合代码内容,尽量详细的补充注释,不要遗漏,每条注释请以 “comment:” 作为前缀。
例2:生成测试用例
问题是什么:你的任务是帮我设计一款产品的测试用例。
你要做什么:我会提供给你产品的需求文档,需要你结合需求的功能描述进行测试用例的编写。
有什么要求:请结合需求中功能的结构,对测试点进行梳理,并有层级的输出测试用例,请保证每一个功能的测试点没有遗漏。
在描述清楚任务后,我们就需要调度模型的能力去完成我们的任务,不同的任务需要用到不同的能力,这往往依赖认为的拆分。我们可以想像,当我们让一个小白帮我们完成一项任务时,我们需要对任务进行分解,并告诉他每一步需要怎么做,以此来让他完成一项复杂的任务。对于大模型而言,这当然也是试用的,甚至十分好用,这在第5章的 “CoT” 中还会再次提到。
你当然可以人为的完成这种拆分,再一条条的解释给大模型,但这种做法并不通用,每个领域都有自己独特的专项能力,每个任务都有自己的工作流程,因此这种方案并不适合放到一个通用的框架当中。好在大模型能力的调用还存在一条捷径,那就是“角色”,他就像大模型里自带一个“能力包”,可以很容易的对模型能力进行调用。每一个角色,都对应着该角色包含的若干能力,我们可以通过设定角色,“提示”大模型使用该角色对应的能力,这与前文“Prompt 到底是什么” 中介绍的想法极其匹配,充分说明是“Prompt” 提示的作用,通过简单的“提示”调用出大模型预先训练的能力,这也就是“角色”如此有用的原因。
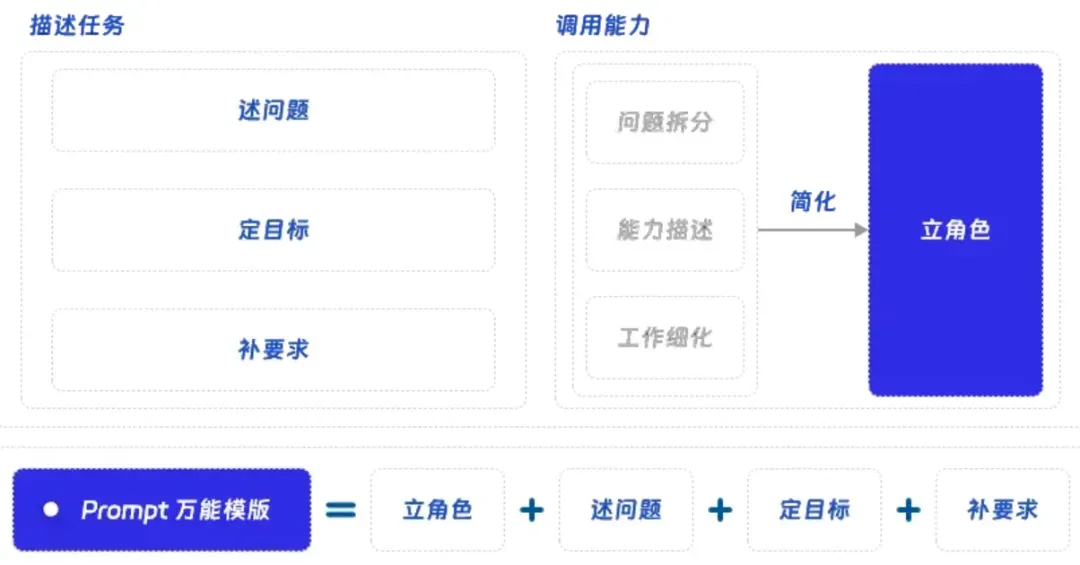
由此我们就最终得到了我们的 “Prompt 模版”,通过这个统一的框架我们可以完成绝大多数 Prompt 初版的编写,让大家在面对各类任务时可以高效的完成从0到1的尝试,而不必陷入无从下笔的困境。
除了效果之外,对 Prompt 结构化的拆分也对 Prompt 管理提供了很大帮助,我们的 Prompt 库不再是大段的文本,而是拆分成了4张表“角色表”,“问题表”,“目标表”,“要求表”。通过这种方式我们可以很大的提升 Prompt 的灵活性,并通过动态组合4个元素的方式完成各类任务,这在面对复杂任务,或通过多模型解决问题时,会提供稳定有效的支撑。
02
框架细化
2.1 立角色
与前文中对 “角色” 的理解一致,“角色” 可以被当作大模型的“能力包”或“语法糖”,我们不再需要对每一项能力进行详细的描述,对任务进行更细节的分解,而是可以通过 import “角色” 的方式,使用这个 “角色” 背后对应的各项能力。那我们该如何设立角色,才是这个“能力包”的正确使用方式呢?
大家都有招聘的经历,我们可以想象,大模型就是我们要招的人,我们需要设定一个能力模型,来完成我们指定的工作。我们在招聘时通常都会有明确的要求,在JD中要有清晰的描述,这样才能找到最合适的人选。这与大模型的角色设置一样,我们要清晰明确的描述这个角色,才能充分 “提示” 大模型,让大模型知道该调用哪些能力。
我们不妨试想一下在招聘 JD 中,我们会要求哪些内容。通常会包含:工作年份,教育水平,项目经历,工作技能,荣誉奖项等等。我们完全可以按照这个思路,创建一个语言模版,帮助我们创立角色。
以下是我在使用的角色模版,当然 Prompt 的构造十分灵活,展示的示例仅供参考:
角色模版:
现在你是一位优秀的{{你想要的身份}},拥有{{你想要的教育水平}},并且具备{{你想要的工作年份及工作经历}},你的工作内容是{{与问题相关的工作内容}},同时你具备以下能力{{你需要的能力}}
角色的设置往往需要编写者对角色有一定的了解,这可以更好的帮助你补全你的模版,但如果你不了解你要设置的角色,不知道这些信息该如何填写,我们如何可以获取到这部分信息呢?
其实,我们可以沿着 “招聘 JD” 的思路,通过招聘网站上的招聘信息补全我们的数据。例如,我要让大模型帮我完成一个 “财务分析” 相关的任务,而我此前对这个领域毫无了解,此时就可以通过招聘网站的职位信息,完成角色的设置:
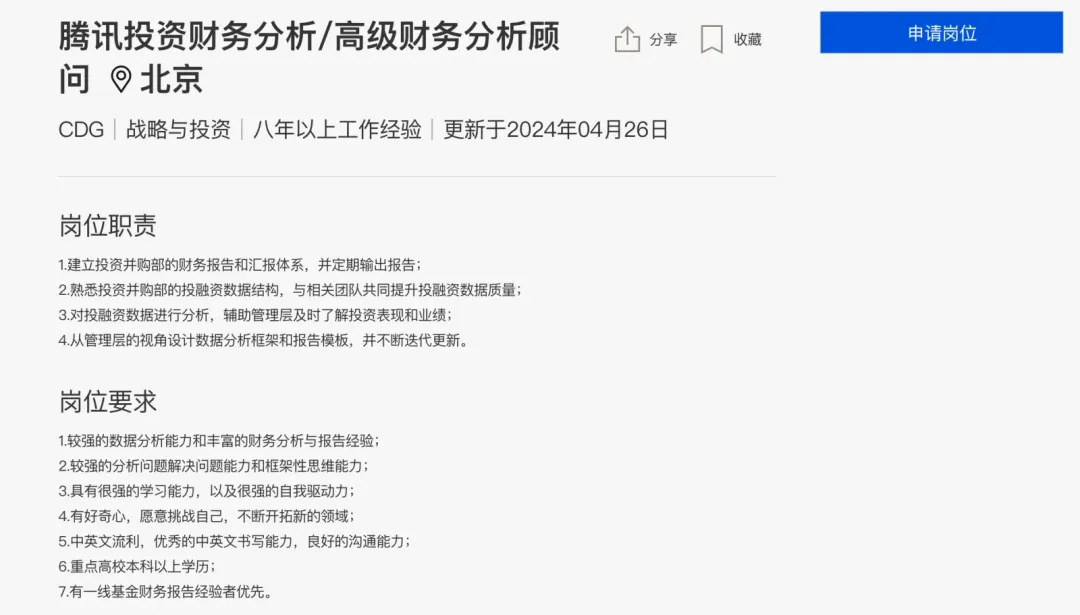
例:财务分析
现在你是一位优秀的{{财务分析顾问}},拥有{{财务学、经济学等专业的硕士或博士学位}},并且具备{{八年以上的财务分析工作经验,在不同类型的公司进行过一线基金财务分析,财务报告产出等工作,积累了丰富的实践经验}},你的工作内容是{{对投融资数据进行分析,从管理层的视角设计数据分析框架和汇报体系}},同时你具备以下能力:{{专业知识:你拥有较强的数据分析能力和丰富的财务分析与报告能力。
较强的分析问题解决问题能力和框架性思维能力。
具有很强的学习能力,以及很强的自我驱动力。
有好奇心,愿意挑战自己,不断开拓新的领域。
中英文流利,优秀的中英文书写能力,良好的沟通能力。
}}
以上,就是借助 “招聘 JD” 完成一个完全陌生领域角色的示例,而通常而言角色与任务的关联性很大,我们对角色的了解越深入,就越能设定出符合预期的角色,即便我们可以采用这种方案进行兜底,但在 “Prompt 工程” 中人的先验经验依然十分重要。
2.2 述问题 & 定目标
对问题的描述由 “述问题” 和 “定目标” 两部分组成,是 Prompt 中信息含量最大的部分,也是和任务最相关的部分,我们要明确的描述我们希望大模型做的工作,才能让大模型输出最符合预期的结果。
除了要描述的清晰明确外,此部分值得强调的就是对任务的分解,这在复杂任务上尤为重要。如果我们需要大模型完成的任务过于复杂,我们则需要先人工对任务进行拆分,并尽量详细的描述任务中包含的各个部分,这与常用的 “CoT” 的优化方式类似,通过把复杂任务拆分成若干个子部分的方式提升模型的效果。
我们也可以把这种拆分当作一个任务维度的对齐,当我们用概括的语言描述一项任务时,隐含了大量的背景知识和预期。例如,当我们希望大模型帮我们 “制作一份旅游攻略” 时,我们希望他能帮我们 “规划行程”,“收集信息”,“预定酒店” 等等,而这些信息往往都被包含在 “旅游攻略” 当中。如果我们不明确的对任务进行拆分,大模型就不知道我们的任务具体需要包含哪些部分,因此这个任务维度的对齐十分重要。下面我举个例子:
例:请根据需求帮我设计测试用例
请根据需求帮助我设计测试用例,测试用例的设计是一个系统化的过程,以下是一些基本步骤和思考方式:
理解需求:首先,你需要深入理解软件的需求和功能。这包括阅读需求文档,理解用户故事,或者与项目经理和开发人员进行讨论。
确定测试范围:确定你需要测试哪些功能和特性。这可能包括正常操作,边缘情况,错误处理等。
设计测试策略:确定你将如何测试这些功能。这可能包括单元测试,集成测试,系统测试,性能测试等。
编写测试用例:对于每个测试,编写一个详细的测试用例。这应该包括预期的输入,预期的输出,以及如何执行测试。
评审测试用例:对测试用例进行评审,以确保它们完整,准确,并且易于理解。
复杂任务的拆解往往十分有效,不仅可以提升大模型的推理能力,也可以让大模型的输出更加贴合你的要求(对齐),但这需要你对当前任务有一定的理解,才可以完成这样的拆分。但如果你并不熟悉你要处理的任务,如何完成这一步呢。正如前文中表达的观念,我们希望得出一套通用的方法,让每个人在面对每个任务时都可以完成 Prompt 的编写,因此一定需要找到更加通用的方法。
其实,这个步骤你完全可以让大模型帮助你完成,这类似 Agent 中的 Planning 的思想,让大模型帮助你拆分一项复杂任务。你可以使用这样简单的 Prompt 完成这个任务:
任务拆分 Prompt:
{{你要做的任务}},需要哪些步骤,该如何思考?
例:希望大模型帮我写一份基金财务分析报告
输入:
制作一份基金财务分析报告,需要哪些步骤,该如何思考?
此时大模型会给你返回一个详细的步骤,这就是我们可以抽象出来的 Prompt 步骤输入了。
2.3 补要求
让大模型遵循我们的要求,尤其是在“格式”层面让大模型的输出符合我们的规定,对大模型的工业应用十分重要。如何让大模型更听话,让其遵循我们的要求呢?
首先,我们可以把要求放在 Prompt 的最后。大语言模型的本质是在做文本补全,后文的输出会更倾向于依据距离更近的语境,如果利用 "LIME" 这样的模型解释算法分析,距离更近的文本间权重往往更大,这在 Transofrmer 中的 Attention 权重 上也可以清晰的看到。同时,这与大模型在预训练阶段中完成的任务也更加匹配,虽然现在的大模型在 SFT 阶段会进行多种任务的训练,但其本质上还是建立在自监督“文本补全”任务上被训练出来的,因此其天然的更加遵从离得更近的文本。因此,把要求放在 Prompt 的最后可以很有效的帮助大模型变得更“听话”。
其次,我们还可以利用大模型的“编程”能力巧妙的让他更“听话”。在“立角色”的部分中,我们说“角色”时大模型的能力包,我们可以通过设定角色调用大模型的能力,那有什么能力可以让大模型更“听话”呢?我们都知道“大模型”在“编程”方面也展现出了惊人的能力,而这个能力恰好可以将“模糊的文理问题”变成“准确的数理问题”,以此让大模型更加遵守我们的要求。
具体而言,就是把我们的要求转换为一个 “编码” 任务,例如:
请为我输出一份产品摘要,字数不要超过50个字。
请为我输出一份产品摘要。我需要将这个摘要引入到 python 代码中,该变量的大小为50,因此摘要内容不要超过50个字符通过这样引入大模型“编程”能力的方式,我们可以对模型提出更加精准的要求,并通过将我们的任务转换为更加准确的编程问题的方式,让大模型更 “听话”。
2.4 (补充)格式很重要
除了输入的内容外,输入的格式也很重要,清晰的结构对大模型的效果有很大的影响。除了增加合适的 “空行” 让结构变的清晰外,我们还可以增加一些“标识符”来区分各个部分,例如:#,<>,```,[],- 。同时大模型也具备 MarkDown 解析的能力,我们也可以借助 MarkDown 语法进行 Prompt 结构的整理。
由于“格式”对模型效果的影响,越来越多研究聚焦在了这个方向上,其中 “LangGPT” 得到了广泛的应用。LangGPT 提出了一种结构化的 Prompt 模式,可以通过一套结构化的模版构造出格式清晰的 Prompt。
至此,我们已经完成了 Prompt 主体部分的编写,面对任何一个任务都可以通过这套统一的方法完成一个还不错的 Prompt,并且通过我们对 Prompt 结构化的拆分,我们现在也可以更好的管理我们的 Prompt,并为上层应用提供更好的支撑。
03
在框架上增加更多信息(RAG)
上文中我们已经通过 “Prompt 框架” 和 “框架的细化” 完成了 Prompt 主体部分的编写,如果我们要在这基础上进一步优化我们的 Prompt,我们还能怎么做呢?
大模型的推理,根本上还是基于用户输入的信息进行推理,我们提供的信息越充分,大模型就能越好的完成推进。因此,要想让模型的效果更好,我们就需要提供更多的输入信息。前两章介绍的“框架”,仅仅包含了 Prompt 中“静态”的信息,再进一步扩充这部分信息的同时,我们还需要增加因任务而异的“动态”信息,这两部分信息的补充就是进一步优化 Prompt 的核心思想。
“增加更多信息,让效果变得更好” 这个想法十分自然,但我们要增加什么信息?如何增加这些信息呢?
为了能在合适的场景下增加合适的信息,势必要包含 “检索” 的工作,来根据需要找到合适的信息,而说到 “检索” 就不得不提名声大噪的 “RAG” 了。
3.1 RAG
RAG 技术在近期得到了大量的关注,也渐渐的在各种实际场景中得到了应用。早在 ChatGPT 爆发之初,RAG 就已经得到了不少的关注,大家很早就意识到,想要依赖模型参数注入知识不是可行的做法,要让模型拥有动态获取知识的能力,不光对大模型在专业领域中的应用十分重要,对知识的扩展性和时效性在通用领域中也同样重要。
与人类智能类比,人脑也并不需要把所有知识都放在大脑中,而是可以通过检索的方式获取知识,再利用自身的智能进行推理,最终得到结论。当你使用各大厂商的大模型时,你都会发现其包含检索的步骤,通过检索获取的知识对大模型效果十分重要。
而这个检索背后的技术就是 “RAG”,他可以利用大模型能力通过语义相似度的方式,高效的在文本数据上完成检索,并把其增加到大模型的输入当中。
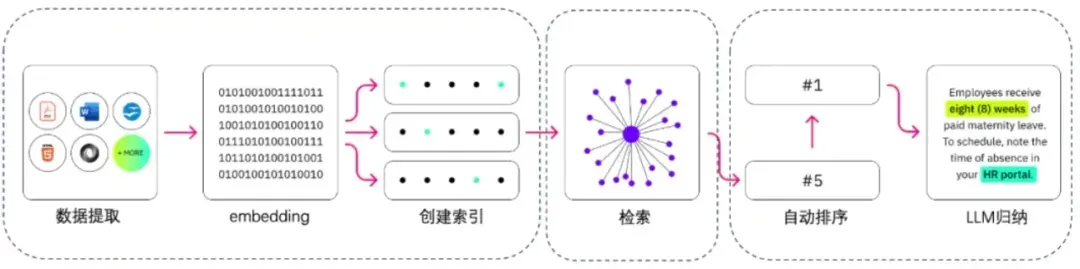
从技术角度看,上图是 RAG 最原始的结构,也是 RAG 最核心的部分,通过 “Embedding+向量数据库” 的方式,RAG 可以无监督的对文本数据进行语义维度的匹配,这个思想早在 Word2Vec 时代就已经得到了应用,词向量就已经可以进行“词”维度的匹配,而如今大模型则是把这个维度提升到了所有文本数据。
现在已经有了许多可以直接使用的RAG框架,如:LangChain, Milvus, LlamaIndex, Pincone 都提供了开箱即用的方案。而真的要让 RAG 变得准确好用,还是有很多值得优化的地方,RAG 框架也已经有了多种优化版本。
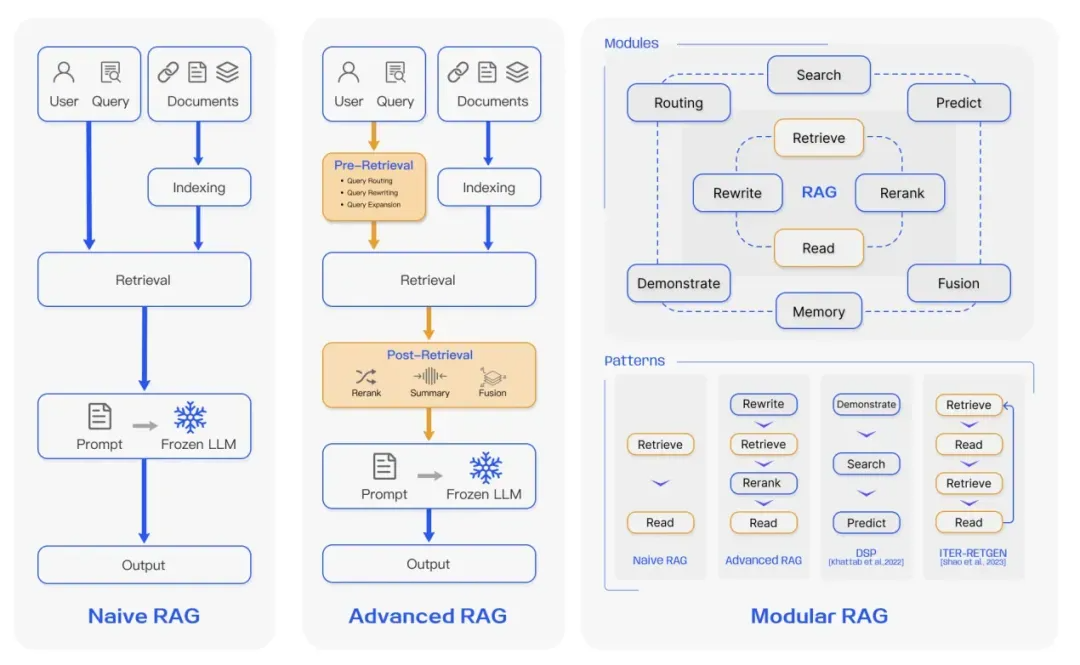
如今的 RAG 技术已经得到了充分的发展,已经不仅仅局限于语义匹配本身,而诞生出了多种优化版本,也增加了例如 “Rewrite”, "Memory" 这样的模块,对于 RAG 技术感兴趣的同学可以阅读此篇survey:https://arxiv.org/pdf/2312.10997
如果我们从应用角度重新看看 RAG ,不难发现其本质就是检索技术,只是 RAG 利用大模型能力实现了更强的语义维度的检索。而如果我们不知道怎么做 Embedding,也没有向量数据库,不会使用 RAG,我们还可以完成检索吗?
答案显然是肯定的 ,检索依然是十分成熟的技术模块了,即便利用最传统的 “关键词匹配” 也可以计算文本间的相似度,实现检索的效果。因此,RAG 并不是唯一的技术方案,我们不必困在此处,在条件不足的情况下,我们可以结合场景找到最合适的检索模式,践行 RAG 的思想,在输入中增加更多信息才是最核心的思想。
以上,我结合 RAG 介绍了 “如何增加信息?”,下面我就具体展开 “我们要增加什么信息?”。
3.2 示例(Few-shot)

Few-shot 是无监督学习的一种基本范式,相较于直接提问的方式,One-shot 会提供一条示例,Few-shot 会提供多条量示例再进行提问,以此提升模型的效果。这种提供示例的方法,在不进行专项训练的情况下可以很好的提升模型的准确性和稳定性,在各类大模型的论文中也可以看到这样的对比,在各类任务中均可以表现出更好的效果。
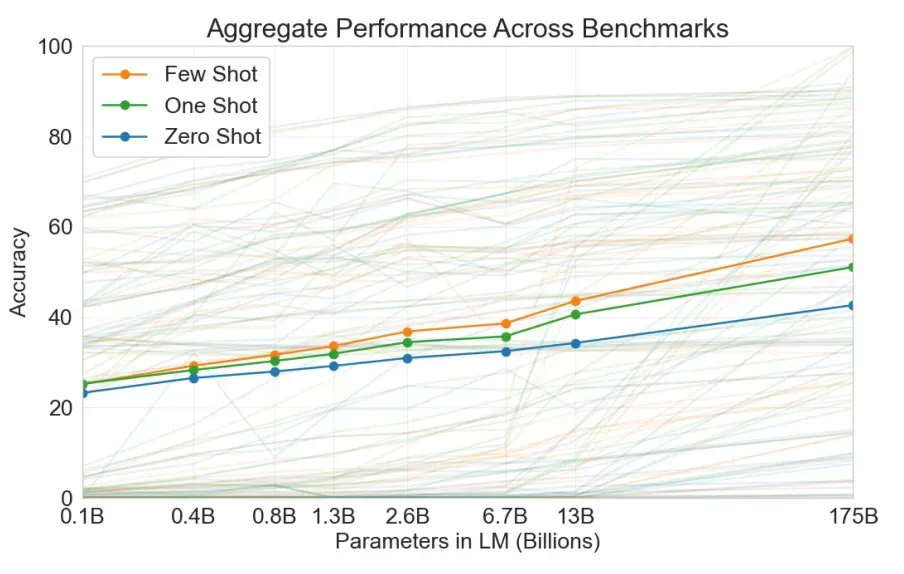
对于 Few-shot 而言,最为人诟病的一点就是,当你提供示例后,模型会更多的参照示例回答,而在某种程度上降低了模型本身的思考能力。Few-shot中的示例很大程度提升了模型结果的确定性,而确定性会影响模型展现出的智能水平,特别是对于基于表征学习的大语言模型(Certainty or Intelligence: Pick One!,Yann Le Cun)。
我们应该如何缓解这个弊端呢?除了通过Prompt对模型进行引导外,让示例变得 “少而有效” 也是很好的方式,通过提供更具参考性的示例,提升每条示例的价值,同时降低示例的数量,可以有效的减少大模型的确定性,并通过这种方式尽量减少示例带来的负面影响。
为了达到 “少而有效” 的效果就需要借助 “RAG” 的方式完成。通过提升检索的效果,我们可以更精准的找到与当前任务最相近的示例(或反例),相比静态的示例而言,这可以很大的增强模型对当前任务的理解,以此提升模型在专项任务中的效果。
3.3 记忆(Memory)
除了在输入中增加 “示例” 外,我们还可以增加“历史记录”,为大模型增加 “记忆(memory)” 。“记忆” 可以弥补大模型在知识整合和长期记忆方面存在的明显短板,而这恰恰是人脑的强项。人脑能持续不断地整合知识,形成强大的长期记忆,为我们的思考和决策提供支持。
在一次对话内的上下为可以被称作“短期记忆”,而对于历史的对话内容则可以被称为“长期记忆”,在适当的场景调用这些记忆,可以为当前的对话补充必要的上下文,让模型了解更多必要的背景信息,已在当前任务中表现的更好。这种打破 “上下文长度限制” 的方式,不光在专项任务中发挥效果,在更长的生命周期上,让模型可以调度历史的“对话内容”也被认为是模型不断进化的方式之一。
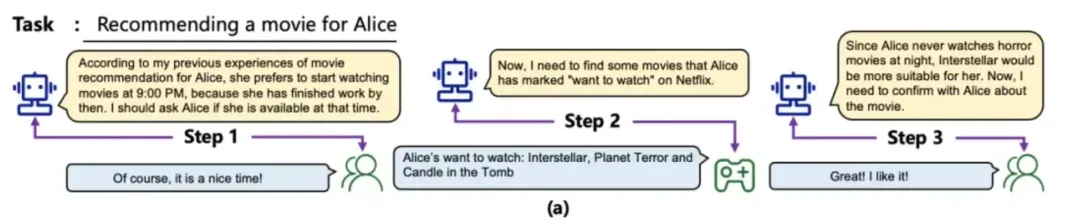
例如,在上图的例子中,当大模型进行电影推荐任务时,会调取历史记忆,确定用户倾向的电影类型和看电影的时间,这些信息会在模型推理的过程中被加入到输入中,以此推荐出更符合预期的结果。
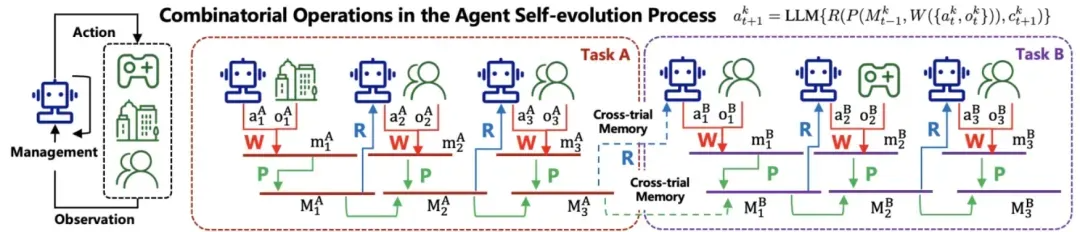
我们可以根据每一轮对话的输入,利用“RAG”技术,动态的从记忆库中获取合适的内容加入到输入中,让大模型可以跨任务,跨周期的进行历史数据的获取。这在通用领域可以进行知识的打通,建立知识间的关联,在专业领域中面对 “专业概念/专业词汇” 时,除了依赖人工对专业知识的整理,历史数据中沉淀的专业知识也是十分有效的信息,通过历史数据的引入排除对人工的依赖,在使用过程中不断提升模型对专业知识的理解,这也是很多论文中提到的“通过长期记忆让模型自我进化”的思想。
“记忆” 是十分重要的大模型推理模块之一,在 Agent 建设中也扮演了重要的角色,相关的研究还在不断发展,记忆管理框架(MemGPT)也在工业中得到了越来越广泛的应用,诞生了许多令人印象深刻的记忆框架。
3.4 应对专业领域
大模型擅长回答通用的知识,但对于专业领域内的知识就显得没那么擅长,而对于大模型的工业应用而言,我们往往要处理某个专业领域内的专项任务,这需要大模型理解必要的专业知识和专业方法,并在合适的时候调度它们,以此在工业应用中取得稳定的效果,这也成为了大模型应用最大的问题之一。
专业领域知识的增加对大模型在专业领域上的应用效果至关重要,以我们近一年应用大模型在“测试领域”的实践为例,我们希望大模型帮助测试同学完成测试工作,例如 “编写/检查” 测试用例。
要完成这样一个相对专业的领域任务,就需要大模型了解足够的领域知识,例如测试用例的检查标准,常用的测试方法,各类用例设计方法,以及必要的业务背景知识。为了能让大模型具备这些支持,我们首先需要与领域专家协作,对测试域相关的知识进行整理,管理好这些知识是大模型应用的基础。

同时,专业领域的知识与具体任务息息相关。例如,对 “用例检查” 任务而言,我们的目的是通过用例检查发现用例中存在的问题,以此减少用例原因导致的漏测问题。因此,我们从目的出发,对漏测问题进行分析,在确定检查点的同时,结合用例现状和专业知识进行了问题定义的梳理,通过明确问题定义让大模型更好的贴合我们的专业领域。
除了上述这些对专业知识的整理,我们还希望动态的增加这些信息,利用 RAG 的方法,结合具体任务动态的从知识库中引入必要的知识。例如,当用户的输入中包含某些专业词汇或业务概念时,我们需要动态的识别到他们,并对他们进行解释和补充,这可能需要利用 “插件” 完成,关于“插件”的相关内容我会在“Agent”相关的文章中具体展开,此处不再赘。
无论是 “静态知识” 还是 “动态知识”,都是通过对专业知识的整理,弥补大模型在专业领域上的不足,我们要将”专业知识“翻译成”通用知识“ 告诉模型大模型,让大模型更好的应对专业领域。这一步往往需要领域专家的介入以及对知识的人工整理,这往往是决定大模型效果上限最重要的因素之一。
04
附加技巧
前文中,我们已经介绍了 Prompt 调试的主要步骤,也是一条标准的工作流,可以帮助我们从 0 到 1 的完成 Prompt 的编写和调试:“Prompt 框架” - “细化框架” - “增加更多信息” 。“Prompt 工程” 之上,还有不少技巧可以进行进一步的优化,下面我选择其中最重要的几点展开聊聊。
4.1 用参数控制模型确定性
除了调整模型的输入外,大家一定注意到了大模型还有2个参数可以调节:温度(Temperature),Top-P。这两个参数也与大模型效果息息相关,控制着大模型输出的确定性。大模型的本质是在 Token 的概率空间中进行选择,依据概率选择接下来要输出的 Token,而这 2 个参数就是在控制这个过程。
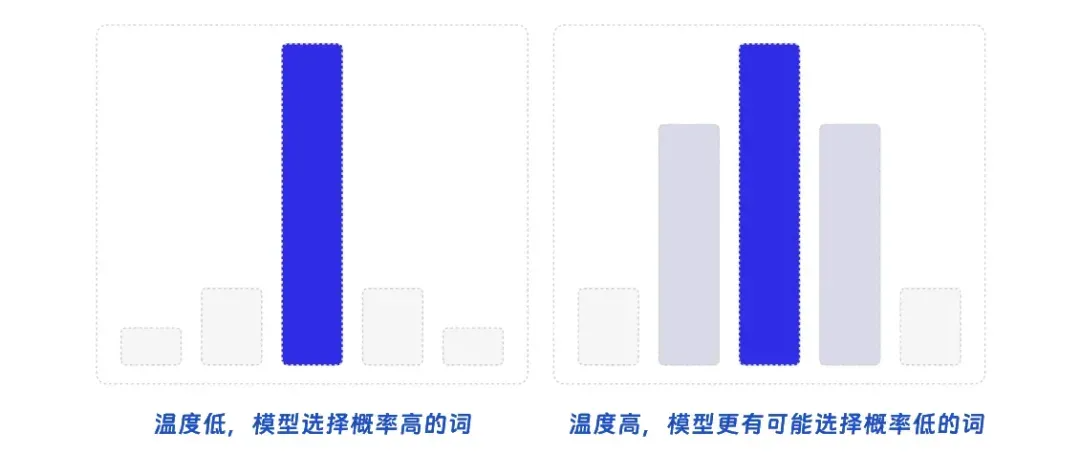
Temperature(温度)是一个正实数,用于控制生成文本的随机性和多样性。在生成过程中,模型会为每个可能的下一个词分配一个概率,而调整温度,则可以影响这些概率分布的形状。当温度接近 0 时,输出文本会变得更加确定,模型更倾向于选择具有较高概率的词,这可能导致生成的文本质量较高,但多样性较低。当温度接近 1 时,输出文本的随机性增加,模型会更平衡地从概率分布中选择词汇,这可能使生成的文本具有更高的多样性,但质量可能不如较低温度时的输出。温度大于 1 时,输出文本的随机性会进一步增加,模型更可能选择具有较低概率的词。
我们可以举一个抽象的例子,帮助大家理解。假设我们有一个语言模型,它正在预测句子中的下一个单词。我们输入的句子是我喜欢吃苹果和____,那么模型可能会为香蕉分配 0.4 的概率,为橙子分配 0.2 的概率,为鸭梨分配 0.2 的概率,为白菜分配 0.1 的概率,为萝卜分配 0.1 的概率。
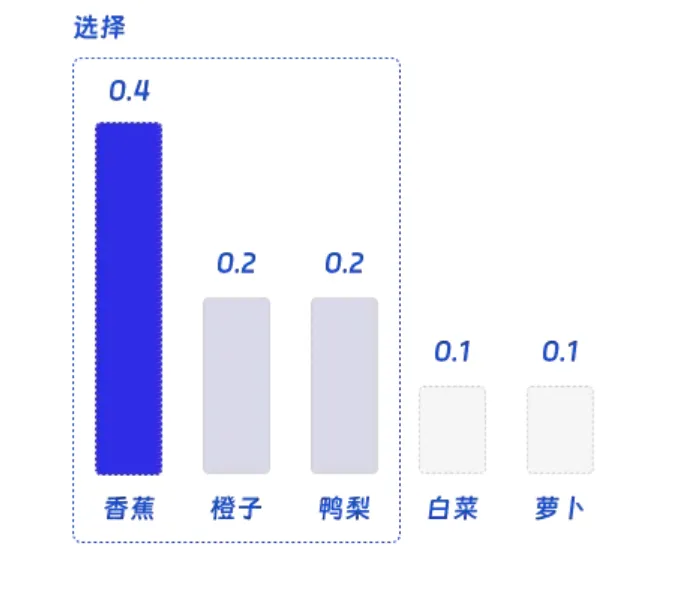
假如我们设定Top-P = 0.8,则我们会按照概率大小选择尽可能多的词,并让概率的总和小于0.8。因此我们会选择 “香蕉”,“橙子”,“鸭梨”,而如果再加上 “白菜” 则累计概率会超过阈值 0.8。
最后模型会在 “香蕉”,“橙子”,“鸭梨” 中随机选择一个单词。在这个例子中,我们有 50% 的几率会选择 “香蕉”,25% 的几率选择 “橙子”,25% 的几率选择 “鸭梨”。这一步中的概率还会被 “Temperature(温度)” 所影响。
总结而言,温度(Temperature)和 Top-p 是对模型输出确定性的控制,我们可以根据具体的应用场景进行调试,当我们需要模型确定稳定的产出结果是,我们可以设置更高的确定性,以提升模型应用的稳定性。但当我们需要模型提供多种结果,或希望让模型更具想象力时,我们则需要设置更高的多样性。
4.2 让大模型帮你优化 Prompt
我们可以使用各种技巧优化我们的 Prompt,那大模型可不可以帮我们自动优化我们的 Prompt 呢?这个研究方向自 ChatGPT 以来就一直得到大量关注,且在大模型时代得到了越来越多的应用,他不光可以对已有的 Prompt 进行优化,还可以自动找到一些 Prompt 语句,神奇的产生通用的效果。例如,在 “Zero-Shot COT” 里的那句 “Let's think step by step”,谷歌就曾通过这种方式找到了更好的一句:“Take a deep breath and work on this problem step-by-step”,让GSM8K的结果直接从 71.8% 上升到了 80.2%。这个研究方向还在快速的发展当中,已经诞生了多种算法,下文将挑选其中最经典的几个算法,希望可以让大家更好的了解这个领域。
APE 是其中最经典的算法,核心思路是:从候选集中选出若干较好的 Prompt,再在这些 Prompt 附近进行 “试探性搜索”。其过程为,先通过大模型生成若干 Prompt,再在训练集上打分,保留较好若干条的 Prompt,最后在这些高分 Prompt 附近进行采样,模拟 “Monte-Carlo Search” 的过程,优化得到最理想的 Prompt。
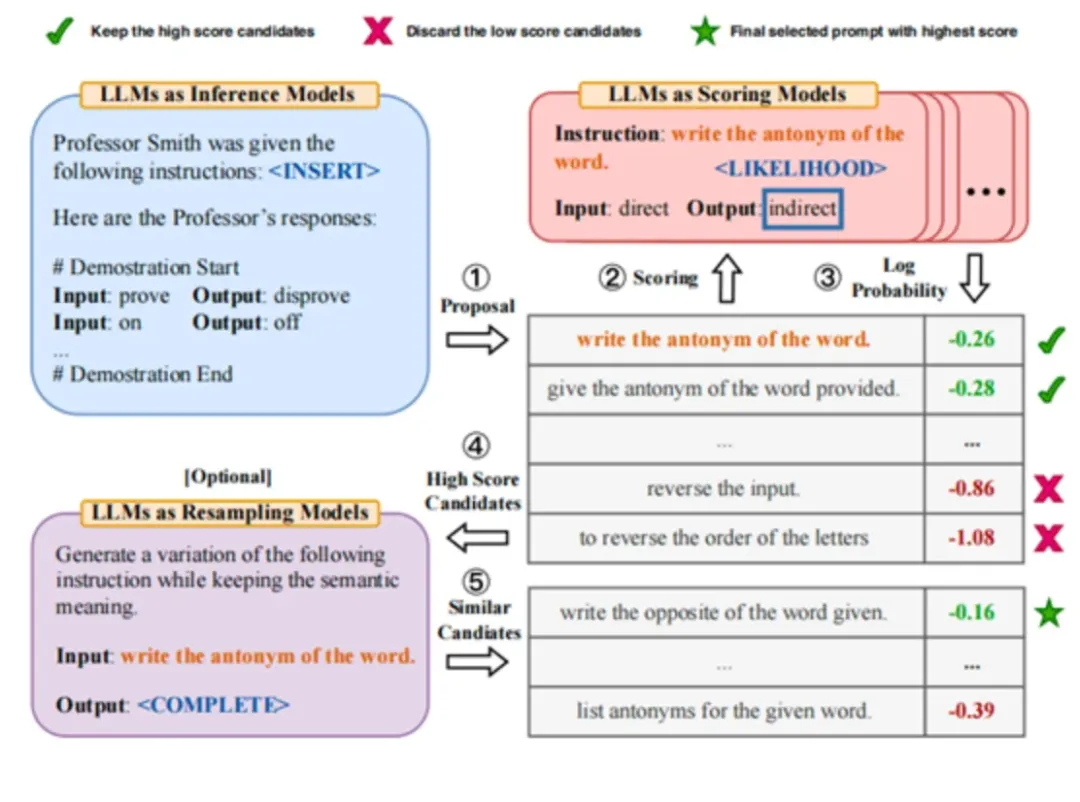
APO 算法则是引入了 “梯度下降” 的方法,通过训练集得到当前 Prompt 的梯度,在应用“梯度下降”的方式得到新的 Prompt,最后与 APE 一样进行采样,得到最终的 Prompt。

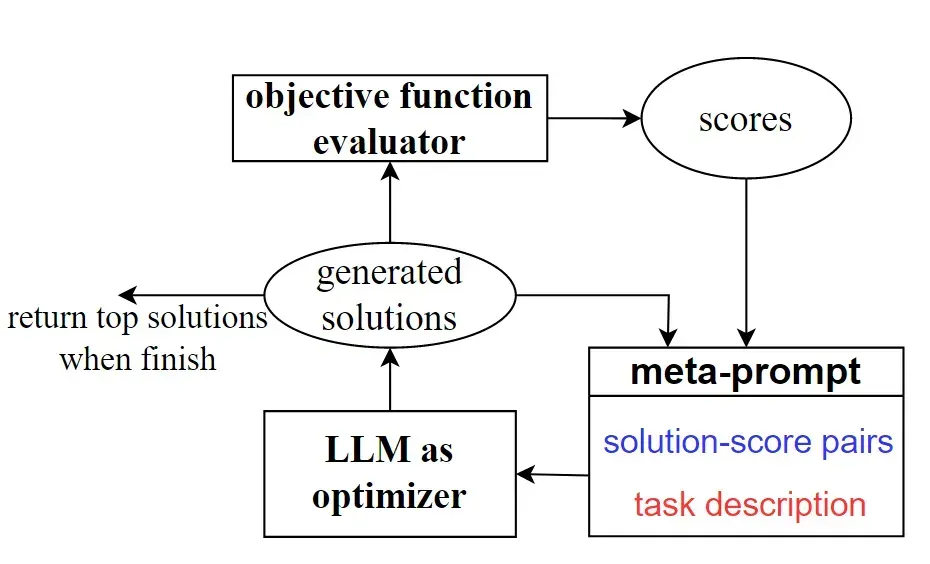
OPRO 算法则是更复杂的利用 LLMs 作为优化器。与传统的迭代优化技术不同,OPRO 采用自然语言描述和指引优化任务,通过 LLMs 的指导,结合先前找到的解决方案,不断生成更新的策略。
本文尝试结合我们的研发经验,体系化的对 “Prompt 工程” 的相关工作进行了梳理,得到了一个标准化的工作流,帮助大家可以从0到1的完成一个 Prompt 的书写和调试,并通过这样结构化的拆分,增强对 Prompt 的管理。
我们认为在一个大模型工程中,“Prompt”应该起到基石般的作用,有效稳定可扩展。对于一个大模型工程师而言,“Prompt” 也是必备的基础技能,希望可以通过这篇文章帮助大家更简单的上手 Prompt 的相关工作,让每个人都能编写 Prompt,人人都能成为 Prompt 工程师。
本文中提到的一大核心 RAG 技术与向量数据库技术密不可分,二者的结合可以提高信息检索和生成的效率与准确性,解决大模型知识更新难题,共同推动了信息处理和文本生成领域的创新,为各种应用场景提供了更加智能和高效的服务。
-End-
原创作者|刘琮玮
感谢你读到这里,不如关注一下?👇

这里推荐由腾讯云向量数据库负责人罗云撰写的新书《从零构建向量数据库》,这本实战类图书,教你快速构建自己的向量数据库!参与互动问题:你是如何训练大模型为自己工作提效的?我们将为点赞本文并且留言评论的5位读者,各送出一本《从零构建向量数据库》。10月8日中午12点开奖。

📢📢欢迎加入腾讯云开发者社群,享前沿资讯、大咖干货,找兴趣搭子,交同城好友,更有鹅厂招聘机会、限量周边好礼等你来~

(长按图片立即扫码)





















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









