






SPICE: Semantic Pseudo-labeling for Image Clustering(用于图像聚类的语义伪标记)
这篇文章提出了一种用于图像聚类的语义伪标记框架:SPICE(Semantic Pseudo-labeling for Image Clustering)。
The basic idea of SPICE is to synergize the discrepancy among semantic clusters, the similarity among instance samples, and the semantic consistency of local samples in an embedding space to optimize the clustering network in a semantically-driven paradigm.
SPICE的基本思想是:在嵌入空间中协调语义聚类之间的差异、实例样本之间的相似性和局域样本的语义一致性,从而以语义驱动的方式优化聚类网络。
方法
SPICE的结构
SPICE的结构包括三个训练阶段:
- 预训练一个无监督表示学习模型(改编自SCAN中的方法)。
- 对预训练模型的CNN骨架进行冻结,从而通过SPICE-Self输出特征和标签。
- 从SPICE-Self聚类结果中选出可信的标签,用半监督学习的方法重新分类。
SPICE-Self旨在基于无监督预训练模型提取到的特征进行分类,它包括三个分支:
4. 第一个分支以原始图像为输入,输出嵌入特征(embedding features);
5. 第二个分支以弱变换图像为输入,输出语义标签(semantic labels);
6. 第三个分支以强变换图像为输入,输出聚类标签(cluster labels)。
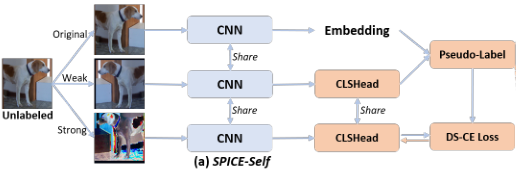
利用基于语义相似度的伪标记(psedo-label)算法,使用前两个分支的输出结果生成伪标签,再用伪标签对第三个分支进行监督。
SPICE-Semi首先基于局部语义一致性原则(local semantic consistency principle)从SPICE-Self的聚类结果中确定一组可靠标记的图像,然后将聚类任务重构为半监督学习问题,重新训练分类模型。

SPICE-Self

从样本集 χ \chi χ中选取batch size= M M M个样本,记为 χ B \chi_B χB。假设总共聚成 k k k类。
第一步:
- 从 χ B \chi_B χB中选取minibatch size= m 1 m_1 m1个样本,记为 χ u \chi_u χu。
- 用预训练的CNN输出嵌入特征 f u = Φ ( χ u ; θ B ) f_u=\Phi(\chi_u;\theta_B) fu=Φ(χu;θB)。
- 对样本作弱变换 α \alpha α,得到 χ w = α ( χ u ) \chi_w=\alpha(\chi_u) χw=α(χu)。
- 在CNN后接一个多层感知机聚类头(CLSHead),预测样本属于某一类的概率 p u = Φ ( χ w ; θ B , θ C L S ) p_u=\Phi(\chi_w;\theta_B,\theta_{CLS}) pu=Φ(χw;θB,θCLS)。
- 重复1~4步,直至对所有minibatch执行。
将嵌入特征 f u f_u fu和概率 p u p_u pu拼接起来,得到矩阵F和P。矩阵F共有M行、D列(D为特征的维数);矩阵P共有M行、k列。
第二步:对于每个聚类,选出样本属于该类的概率在前 n t n_t nt名的样本,以它们的嵌入特征的均值作为聚类中心。然后将聚类中心最近的 n = M / k n=M/k n=M/k个样本作为赋予该类的伪标签。
第三步:对样本作弱强变换
A
\Alpha
A,得到
χ
w
=
A
(
χ
u
)
\chi_w=\Alpha(\chi_u)
χw=A(χu)。定义DSCE损失(a cross-entropy loss function with a double softmax activation function):
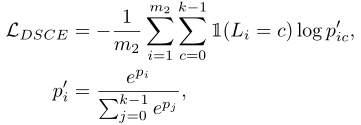
其中
m
2
m_2
m2是minibatch size,
1
\mathbb{1}
1是示性函数,
p
i
c
′
p_{ic}'
pic′是Softmax函数。
用DSCE损失来优化CLSHead,从而让模型输出更有自信的预测。优化完成后,重新预测样本属于某一类的概率,得到聚类结果。
SPICE-Semi
我们从SPICE-Self得到了样本、聚类结果、嵌入特征的三元组
(
x
i
,
l
i
,
f
i
)
(x_i, l_i, f_i)
(xi,li,fi)。对于每个样本
x
i
x_i
xi,根据余弦相似性从嵌入特征空间选取相邻的
n
s
n_s
ns个样本,计算这些样本中与
x
i
x_i
xi属于同一类的比例。比例大于某个阈值时,认为样本
x
i
x_i
xi的类别分配是可信的。
于是无监督聚类转变为半监督学习,这里使用了FixMatch方法。对有标签数据,计算CLS Model预测结果与标签的交叉熵;对于无标签数据,计算使用CLS Model对强变换的预测结果与弱变换预测的伪标签的交叉熵。损失函数是二者之和。

结果

https://arxiv.org/abs/2103.09382
https://github.com/niuchuangnn/SPICE














 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









