








CVPR 2021
0.摘要
在本文中,我们研究了不完全多视图聚类分析中的两个具有挑战性的问题,即i)如何在没有标签的帮助下学习不同视图之间的信息性和一致性表示,以及ii)如何从数据中恢复缺失的视图。为此,我们提出了一个新的目标,从信息论的角度将表征学习和数据恢复结合到一个统一的框架中。具体来说,通过对比学习最大化不同视图之间的互信息来学习信息一致的表示,通过双重预测最小化不同视图的条件熵来恢复缺失的视图。据我们所知,这可能是第一个提供统一一致表示学习和交叉视图数据恢复的理论框架的工作。大量的实验结果表明,该方法在四个具有挑战性的数据集上显著优于10种有竞争力的多视图聚类方法。
1.研究背景
在现实世界中,通常表现出异构属性的多视图数据是从不同的传感器收集的,或者是从各种特征提取器获得的。作为最重要的无监督多视图方法之一,多视图聚类(MVC)旨在以无监督的方式将数据点分成不同的聚类[11,17,20,29,40,54]。为了实现这一目标,关键是探索不同视图之间的一致性,以便学习一个公共/共享的表示[5,12,14,21,33,47]。在一致性学习的背后,隐含的假设是视图是完整的,即所有数据点将出现在所有可能的视图中。
然而,在实际应用中,由于数据采集和传输的复杂性,数据点的某些视图可能会丢失,从而导致所谓的不完全多视图问题。例如,在在线会议中,由于传感器故障,一些视频帧可能会丢失视觉或音频信号。为了解决IMP,已经提出了一些不完全多视图聚类算法(IMC),通过采用许多数据恢复方法来完成缺失的数据,例如基于矩阵分解的方法[10,22,35,46,53]和基于生成对抗网络的方法[16,41,45]。这些作品试图克服以下两个挑战:i)如何学习跨不同视图的信息丰富和一致的表示?以及ii)如何消除缺失视图的影响?虽然已经取得了一些有希望的结果,但几乎所有现有的工作都将这两个挑战视为两个独立的问题,仍然缺乏统一的理论理解。
与现有的IMC研究不同,我们从理论上表明,跨视图一致性学习和数据恢复可以被视为一枚硬币的两面,这两个具有挑战性的任务可以相互促进。我们的动机来自[38],如图1所示。应该指出的是,[38]利用预测学习来增强对比学习的性能,而我们的目标是通过双重预测来恢复缺失的数据。此外,另一个不同之处在于我们的理论结果,即数据恢复和一致性学习可以通过对比学习和双重预测相互促进。
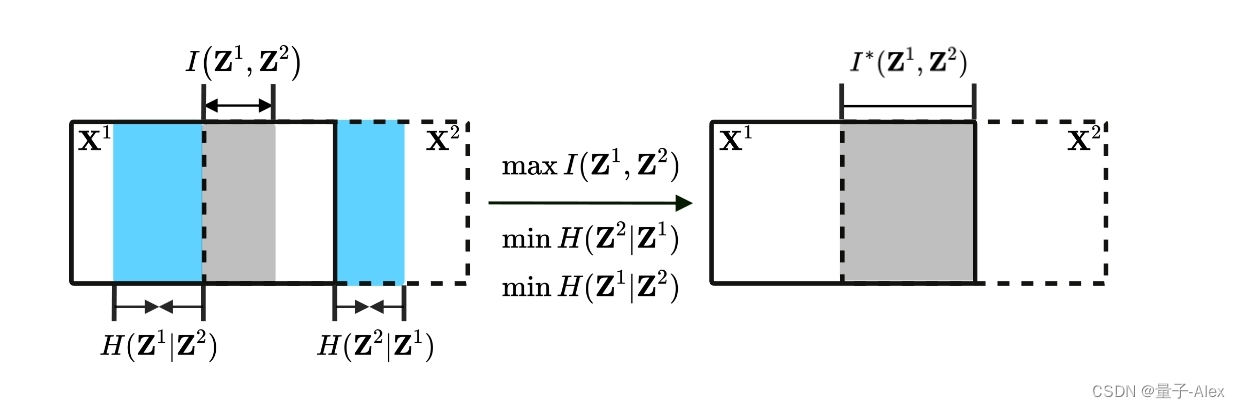
图一。我们的基本观察和理论结果是从信息论的角度出发的。在该图中,实心矩形和虚线矩形分别表示包含在视图1( X 1 \mathbf{X}^1 X1)和视图2( X 2 \mathbf{X}^2 X2)中的信息。在数学中,互信息 I ( Z 1 , Z 2 ) I(\mathbf{Z}^1, \mathbf{Z}^2) I(Z1,Z2)(灰色区域)量化由 Z 1 \mathbf{Z}^1 Z1和 Z 2 \mathbf{Z}^2 Z2共享的信息量,其中 Z 1 \mathbf{Z}^1 Z1和 Z 2 \mathbf{Z}^2 Z2分别是 X 1 \mathbf{X}^1 X1和 X 2 \mathbf{X}^2 X2的表示。为了学习一致的表示,鼓励最大化 I ( Z 1 , Z 2 ) I(\mathbf{Z}^1, \mathbf{Z}^2) I(Z1,Z2)。此外,最小化条件熵 H ( Z i ∣ Z j ) H(\mathbf{Z}^i|\mathbf{Z}^j) H(Zi∣Zj)(蓝色区域)将鼓励丢失视图的恢复,因为当且仅当条件熵 H ( Z i ∣ Z j ) H(\mathbf{Z}^i|\mathbf{Z}^j) H(Zi∣Zj)=0时, Z i \mathbf{Z}^i Zi完全由 Z j \mathbf{Z}^j Zj确定,其中i=1,j=2或i=2,j=1。微妙地,一方面, I ( Z 1 , Z 2 ) I(\mathbf{Z}^1, \mathbf{Z}^2) I(Z1,Z2)的最大化可以增加共享信息量,因此可以受益于数据可恢复性,即,更容易从一个视图恢复另一个视图。另一方面,由于 H ( Z i ∣ Z j ) H(\mathbf{Z}^i|\mathbf{Z}^j) H(Zi∣Zj)量化了基于 Z j \mathbf{Z}^j Zj的 Z i \mathbf{Z}^i Zi的信息量,因此 H ( Z i ∣ Z j ) H(\mathbf{Z}^i|\mathbf{Z}^j) H(Zi∣Zj)的最小化将鼓励丢弃跨视图的不一致信息,从而可以进一步提高一致性。通过上述观察,在上述统一信息论框架下,交叉视图一致性和数据恢复被视为一枚硬币的两面。
基于我们的观察和理论结果,我们提出了一种新的不完全多视图聚类方法,称为基于对比预测的不完全多视图聚类(COMPLETER)。具体来说,COMPLETER将给定的数据集投影到特征空间中,其中使用三个联合学习目标来保证信息一致性和数据可恢复性。更具体地说,视图内重建损失用于学习视图特定的表示,从而避免了琐碎的解决方案。在潜在特征空间中,通过最大化互信息 I ( Z 1 , Z 2 ) I(\mathbf{Z}^1, \mathbf{Z}^2) I(Z1,Z2)引入对比损失来学习交叉视图一致性,并通过最小化条件熵 H ( Z 1 ∣ Z 2 ) H(\mathbf{Z}^1|\mathbf{Z}^2) H(Z1∣Z2)和 H ( Z 2 ∣ Z 1 ) H(\mathbf{Z}^2|\mathbf{Z}^1) H(Z2∣Z1)使用双重预测损失来恢复缺失视图。需要指出的是,本文中提到的数据恢复是面向任务的,即只恢复共享信息而不是所有信息,以方便MVC等下游任务。总结一下:
•我们为学界提供了一种新的见解,即不完全多视图聚类的数据恢复和一致性学习具有内在联系,可以优雅地统一到信息论的框架中。这种理论观点与将一致性学习和数据恢复视为两个独立问题的现有工作明显不同。
•所提出的COMPLETER方法具有新的损失函数,该函数使用对比损失和双重预测损失来实现信息一致性和数据可恢复性。大量实验验证了所提损失函数的有效性。
2.相关工作
在这一节中,我们简要回顾了两个相关主题的一些最新进展,即不完全多视图聚类和对比学习。
2.1 缺失多视图聚类
基于利用多视图信息的方式,大多数现有的IMC方法可以大致分为三类,即基于矩阵分解(MF)的IMC[10,22,35,53],基于谱聚类的IMC[39]和基于核学习的IMC[26]。简单地说,基于MF的方法利用低秩将不完全数据投影到一个公共子空间中。例如,DAIMC[10]在 l 2 , 1 \mathcal{l}_{2,1} l2,1范数的帮助下建立了共识基础矩阵,IMG[53]利用 l F \mathcal{l}_{F} lF范数来减少缺失数据的影响。作为一种典型的基于谱聚类的方法,PIC[39]使用从不完全视图构建的一致拉普拉斯图来学习公共表示。EERIMVC[26]提出使用多核方法以迭代优化的方式实现IMC。此外,像[16,41]这样的方法利用cycleGAN[55]从完整的视图中生成缺失的视图,CDIMC-net[44]结合了视图特定的编码器和图形嵌入策略来处理不完整的多视图数据。
这项研究与现有工作之间的差异如下。首先,我们的目标是推断缺失的数据,而不是缺失的相似性,从而享有更高的可解释性[26]。第二,我们的方法是一个深层而非浅层模型[10,19,22,26,35,39,53],因此自然包含了处理复杂和大规模数据集的能力。第三,几乎所有现有的IMC方法[10,16,22,26,35,39,41,53]都将数据恢复和一致性学习视为两个独立的问题/步骤,而缺乏理论上的理解。相比之下,我们提出数据恢复和一致性学习可以统一到信息论的框架中[36]。数据恢复和一致性学习都有利于学习公共表示。
2.2 对比学习
作为最有效的无监督学习范式之一,对比学习[2, 4, 8, 23, 28, 30, 37, 38]在表征学习中取得了最先进的性能。对比学习的基本思想是通过最大化正对之间的相似性同时最小化负对之间的相似性,从原始数据中学习特征空间。最近的一些研究表明,对比学习的成功可以归因于互信息的最大化。例如,MoCo[9]和CPC[30]最小化可被视为最大化互信息下限的InfoNCE损失,即 I ( Z 1 , Z 2 ) ≥ l o g ( N ) − L N C E I(\mathbf{Z}^1, \mathbf{Z}^2) ≥ log(N ) − \mathcal{L}_{NCE} I(Z1,Z2)≥log(N)−LNCE,其中N是负对的数量, Z 1 \mathbf{Z}^1 Z1和 Z 2 \mathbf{Z}^2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











